







目录
多层汉诺塔
【题目描述】汉诺塔是一个有意思的游戏,每个柱子上套上多个中心有洞的圆盘,每次只能移动一个圆盘,并且每个圆盘不能放在比它面积小的圆盘的上面。现在有三套圆盘并叠加放在一个柱子上了,请移动圆盘,使每个柱子上的圆盘都按照相同的顺序从大到小的摆放好,也就是把三份盘子平均分开。请问对于n个不同数量的圆盘(也就是共有3*n个盘子),分别在每个柱子上分好n个盘子,最少需要移动多少步?示意图如下图。
【输入格式】
输入共1行,包括一个正整数n
【输出格式】输出共1行,一个整数,表示需要移动圆盘的最少的步骤数,
【样例输入】
1
【样例输出】
2

解析:使用数学解析法,经典的汉络塔递推
在传统的汉诺塔问题中,我们有3个位置(A,B,C),从A移动 N个圆盘到C的步数是 2^N-1。对于这个变种汉诺塔问题,我们有三套圆盘并叠加地放在一个柱子上,我们可以考虑将这个问题转化为三次传统汉诺塔问题。三套圆盘的初始堆叠状态可以类比成有三个大小相等的"巨大圆盘"。我们的目标是将这三个“巨大圆盘“平均分散到三个柱子上。对于每个“巨大圆盘”,我们要执行传统的汉诺塔移动。那么解决这个问题的步骤如下:
将最底下的“巨大圆盘"(实际上包含了 n 个最大的圆盘)移动到柱子 C。
将中间的“巨大圆盘"(中等大小的 n 个圆盘)移动到柱子 B。
将最上面的“巨大圆盘"(n 个最小的圆盘)移动到柱子 C,放在第一步中的最大圆盘上。
再次将柱子 B(中等大小的圆盘)的圆盘移动到柱子 A。
最后,将柱子C(最小的圆盘)的圆盘移动到柱子 B。每次移动一个“巨大圆盘”(即一套 n 个圆盘)的步数都是 2^n-1,因为我们实际上在执行传统汉诺塔移动。
假设 M(n)是移动 n 个不同大小的圆盘需要的步数,那么我们需要的总步数是: M(n)+ M(n)+ M(n)+M(n)+M(n)+M(n),也就是3x(2^n-1)。
以提供的样例输入为例,n=1,每次移动一个“巨大圆盘"需要 2^1-1=1步,总共需要 3x1=3步。不过要注意,题目的意思可能是,我们最终想要每个柱子上都有三个正序排列的盘子。 如果是这个理解,那么我们执行最后一步移动的时候,实际上只需要移动两个最小的盘子(不需要移动最后一个,因为它已经在目的地了),所以是2^1-1=1 加上2^1-1=1,最后一步只移动1个盘子。
对于输入的 1,实际上需要的步数是 2 而不是 3,因为当把最上面的一个"巨大圆盘"(也就是一个盘子)移动到柱子C的时候,它已经在正确的位置上了,我们不需要再次移动。
#include <bits/stdc++.h>
using namespace std;
//计算移动 n 个不同大小的圆盘到不同柱子的最少步数
unsigned long long minimumMoves(int n) {// 由于每次处理一个巨大圆盘需要 2^n-1 步
// 总共需要 3n 个圆盘,也就是 3 个巨大圆盘,所以这里需要计算 3 次
// 最后一次移动我们移动 2个最小的圆盘,并在目的地保持第一个圆盘
//因此,最后一次移动减少一步
return 3* (pow(2, n)- 1)-(1);
}
int main() {
int n;
cin >> n;
cout << minimumMoves(n) << endl;
return 0;
}
汉诺塔问题有一个经典的递归解法。对于有n个盘子的问题,可以分解为:将上面的 n-1 个盘子从起始柱子A移动到辅助柱子 B。将最大的盘子(第n个盘子)从起始柱子A移动到目标柱子C。将那 n-1个盘子从辅助柱子B移动到目标柱子C。在这种情况下,递归的解决方案中的基本步骤数是 2^n-1。
#include <bits/stdc++.h>
using namespace std;
int main() {
int n;
cin >> n;
long long steps = 2;
for (int i = 2; i <= n; i++) {
steps=2*steps+pow(2,i)+1;
}
cout << steps << endl;
return 0;
}
过河问题
【题目描述】有n个人要渡河,但只有一条小船,这条小船一次只能坐下最多两个人,并且只有一副船桨。每个人划船的速度不一样,如果两个人一起上船,由于重量变大,划船的速度基本上相当于是划船速度最慢的那个人速度。假设给出每个人单独划船过河所花费的时间T,请问所有人都过河的总时间最短的时间?
【输入格式】输入两行,第一行是一个整数,表示要过河的几个人。第二行,是n个整数,按速度从快到慢排序好的每个人划船过河的时间。
【输出格式】输出一行,给出所有人过河所花费最短的时间。
【样例输入1】(测试数据不包含本样例)
3
1 2 3
【样例输出1】6
【样例输入2】(测试数据不包含本样例)
4
1 2 5 10
#include <bits/stdc++.h>
using namespace std;
//模拟算法
// 主函数
int main() {
int n, sum = 0; // 定义人数 `n`,以及用于存储总时间的 `sum` 初始化为 0
cin >> n; // 输入人数
vector<int> v(n, 0); // 创建一个整数向量 `v` 用于存储每个人的过河时间
for (int i = 0; i < n; i++) { // 循环输入每个人的过河时间
cin >> v[i];
}
sort(v.begin(), v.end()); // 对过河时间进行升序排序
int i;
for (i = n - 1; i > 2; i -= 2) {
// 如果次快的人和最快的人一起过河再最快的人回来的时间,大于最快和次快的人分别两次过河的时间
if (v[i - 1] + v[0] > v[1] * 2) {
sum += v[1] * 2 + v[0] + v[i]; // 按照最快和次快的人分别两次过河的方式计算总时间
}else {
sum += v[i - 1] + v[0] * 2 + v[i]; // 按照次快的人和最快的人一起过河再最快的人回来的方式计算总时间
}
}
// 处理剩余人数为 2、1、0 的情况
if (i == 2) {
sum += v[2] + v[0] + v[1]; // 三个人过河,最快和次快过去,最快回来,最快和最慢过去
} else if (i == 1) {
sum += v[1]; // 只有两个人,次快的人过河
} else {
sum += v[0]; // 只有一个人,这个人过河
}
cout << sum << endl; // 输出所有人过河的最短总时间
return 0;
}删除k位数字,得到最小的数
【题目描述】输入一个数字串N,长度不超过 250位,去掉其中任意k个数字后剩下的数字按原左右次序将组成一个新的整数,要求组成新的整数最小。
【输入格式】输入两行正整数。第一行输入一个高精度的正整数n。第二行输入一个正整数k,表示需要删除的数字个数。【输出格式】输出一个整数,最后剩下的最小数。【样例输入】(测试数据不包含本样例)
175438
4
【样例输出】
13
解析:贪心算法,熟练掌握string各种操作api,贪心 + 单调栈对于两个相同长度的数字序列,最左边不同的数字决定了这两个数字的大小,例如,对于 A=1axxx,B=1bxx如果 a>b 则 A>B。基于此,我们可以知道,若要使得剩下的数字最小,需要保证靠前的数字尽可能小。
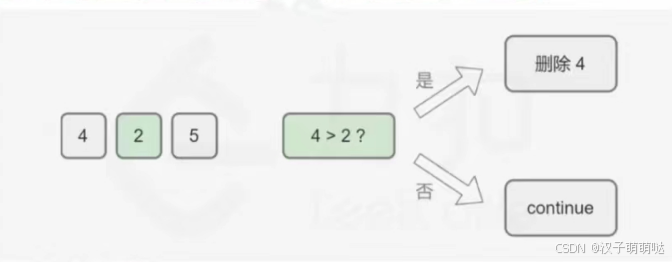
让我们从一个简单的例子开始。给定一个数字序列,例如 425,如果要求我们只删除一个数字,那么从左到右我们有 4、2 和 5 三个选择。我们将每一个数字和它的左邻居进行比较。从 2 开始,2 小于它的左邻居 4。假设我们保留数字 4,那么所有可能的组合都是以数字 4(即 42,45)开头的。相反,如果移掉 4,留下 2,我们得到的是以 2 开头的组合(即 25),这明显小于任何留下数字 4 的组合。因此我们应该移掉数字 4。如果不移掉数字 4,则之后无论移掉什么数字,都不会得到最小数。
基于上述分析,我们可以得出「删除一个数字」的贪心策略:
给定一个长度为n的数字序列[D0 D1 D2 D3…………Dn-1],从左往右找到第一个位置i(i>0)使得 Di <Di-1 ,并删去 Di-1 :如果不存在,说明整个数字序列单调不降,删去最后一个数字即可。
基于此,我们可以每次对整个数字序列执行一次这个策略;删去一个字符后,剩下的 n-1 长度的数字序列就形成了新的子问题,可以继续使用同样的策略,直至删除 k 次。
然而暴力的实现复杂度最差会达到 O(nk)(考虑整个数字序列是单调不降的),因此我们需要加速这个过程。考虑从左往右增量的构造最后的答案。我们可以用一个栈维护当前的答案序列,栈中的元素代表截止到当前位置,删除不超过 k 次个数字后,所能得到的最小整数。根据之前的讨论:在使用 k 个剧除次数之前,栈中的从栈底到栈顶单调不降。
因此,对于每个数字,如果该数字小于栈顶元素,我们就不断地弹出栈顶元素,直到
- 栈为空
- 新的栈顶元素不大于当前数字
- 我们已经删除了 k 位数字
上述步骤结束后我们还需要针对一些情况做额外的处理:
如果我们删除了 m 个数字且 m<k,这种情况下我们需要从序列尾部除额外的 k-m 个数字。
如果最终的数字序列存在前导零,我们要删去前导零。
如果最终数字序列为空,我们应该返回 0。
最终,从栈底到栈顶的答案序列即为最小数。
#include <bits/stdc++.h>
using namespace std;
// 功能:删除字符串中的k个数字,使得剩余的数字组成的新整数最小
// 参数:num-原始数字字符串;k- 需要删除的数字个数
//返回:剩余数字组成的最小整数的字符串表示
string f(string num, int k) {
//创建一个字符指针 result ,并为其分配足够的内存空间,
//以存储一个长度为 num.size() + 1 的字符数组。
char* result = new char[num.size() + 1];
int r = 0;
for (size_t i = 0; i < num.size(); ++i) {
// 尝试从结果中移除最后一个数字,如果那样可以得到更小的数
while (k > 0 && r > 0 && result[r - 1] > num[i]) {
r--;
k--;
}
// 避免数字字符串开头的 0
if (r > 0 || num[i]!= '0') {
result[r++] = num[i];
}
}
// 如果还未删除足够的数字,则继续从结果末尾删除
while (k > 0 && r > 0) {
r--;
k--;
}
result[r] = '\0';
string resultString(result);
delete[] result;
// 如果最终结果为空字符串,那么最小的数字是0
return resultString.empty()? "0" : resultString;
//如果变量 resultString 为空(即调用 empty() 方法返回 true),
//则返回字符串 "0";否则,返回变量 resultString 本身。
}
int main() {
string num;
// 存储要删除的数字数量
int k;
// 输入数字字符串和要删除的数字数量
std::cin >> num >> k;
// 计算并输出删除k个数字后得到的最小整数
string newNumber = f(num, k);
cout << newNumber << endl;
return 0;
}#include <bits/stdc++.h>
using namespace std;
/*获取长度str.length();
替换部分字符串:str.replace
append() 和 insert() 方法分别用于追加和在指定位置插入内容
str.erase(i, j); 删除从位置 i 到 j (不包括 j)的所有字符
如果仅需删除最后一个字符,可以直接 str.pop_back() 或者 str[str.length()] = '\0';
查找特定字符或子串:size_t pos = str.find("search");
分割字符串:vector<string> parts = split(str, delimiter);(自定义函数)
检查是否相等:if(str == "another string")...
字符串大小写转换:transform(str.begin(), str.end(), str.begin(), ::tolower);*/
// 定义函数 dk,用于从输入字符串中删除 k 个数字以得到最小的数
string dk(string &s1, int k) {
// flag 用于标记在一次循环中是否进行了数字删除操作
bool flag = false;
// 从要删除的数字个数开始循环
for (int i = k; i > 0; i--) {
flag = false;
// 遍历字符串中的每个数字(除了最后一个数字)
for (int j = 0; j < s1.size() - 1; j++) {
// 如果当前数字大于下一个数字
if (s1[j] > s1[j + 1]) {
// 从字符串中删除当前数字
s1.erase(j, 1);
flag = true;
break;
}
}
// 如果在这次循环中没有进行数字删除
if (!flag) {
// 从字符串末尾删除指定数量的数字
s1.erase(s1.end() - i, s1.end());
break;
}
}
return s1;
}
int main() {
string s1;
int k;
cin >> s1 >> k;
// 调用 dk 函数处理输入的字符串和要删除的数字个数,并输出结果
cout << dk(s1, k) << endl;
return 0;
}大数比较大小
【题目描述】输入两个很大的十进制正实数(长度超过20位),输出代表数值较大的数。说明:
1)两个数都大于 10000000000000000000;
2)实数包含有小数点的数,一个数里只可能有一个小数点,且不在数的最前或
最后。
【输入格式】输入两行,每行一个数字。
【输出格式】
数值较大的数。如果两数相等,则输出“equation”
如果输入的数不符合数字规则,则输出“error”。
【样例输入】(测试数据不包含本样例)
11111111111111111111111111111111111111
2222222222222222222222222222222222222222
【样例输出】
2222222222222222222222222222222222222222
一、整体思路
-
首先,定义了一个函数
checkValid用于检查输入的数字字符串是否符合题目要求,即数字长度大于 20,并且小数点不在字符串的开头或结尾,且整个字符串中至多有一个小数点。 -
接着,定义了
splitNum函数,用于将输入的数字字符串拆分成整数部分和小数部分,以便后续分别进行比较。 -
在
main函数中,首先读取输入的两个数字字符串num1和num2。 -
通过调用
checkValid函数检查输入的两个数字字符串的有效性,如果有一个不符合规则,直接输出error并结束程序。 -
如果输入的两个数字字符串都有效,通过
splitNum函数分别拆分出它们的整数部分和小数部分。 -
首先比较两个数字的整数部分,如果整数部分不同,那么整数部分较大的整个数字也较大,输出对应的数字字符串。
-
如果整数部分相同,接着比较小数部分,小数部分较大的整个数字也较大,输出对应的数字字符串。
-
如果整数部分和小数部分都相同,输出
equation表示两个数字相等。
二、代码细节思路
(一)checkValid 函数
-
首先检查输入的数字字符串的长度是否小于等于 20 或者小数点出现在字符串的开头或结尾,如果是,那么该字符串不符合要求,返回
false。 -
然后通过循环统计字符串中小数点的个数,如果小数点的个数为 0 或 1,那么该字符串符合要求,返回
true;否则返回false。
(二)splitNum 函数
-
使用
find函数查找输入字符串中小数点的位置。 -
使用
substr函数分别截取小数点之前的部分作为整数部分,小数点之后的部分作为小数部分,并将它们组成一个pair进行返回。
(三)main 函数
-
读入两个数字字符串后,调用
checkValid函数检查其有效性。 -
如果有效,调用
splitNum函数拆分数字字符串,得到整数部分和小数部分。 -
按照整数部分、小数部分、整体相等的顺序依次进行比较和输出。
#include <bits/stdc++.h>
using namespace std;
// 检查输入的数字字符串是否有效
bool checkValid(const string& num) {
// 如果字符串的第一个或最后一个字符是'.',或者字符串长度小于等于 20,返回false
if (num[0] == '.' || num[num.size() - 1] == '.' || num.size() <= 20) {
return false;
}
int cnt = 0;
// 遍历字符串,统计 '.' 的个数
for (int i = 1; i < num.size() - 2; i++) {
if (num[i] == '.') {
cnt++;
}
}
// 如果 '.' 的个数为 0 或 1,返回true,否则返回false
if (cnt == 1 || cnt == 0) return true;
return false;
}
// 将输入的数字字符串拆分为整数部分和小数部分
pair<string, string> splitNum(const string& num) {
int pos = num.find("."); // 找到小数点的位置
return make_pair(num.substr(0, pos), num.substr(pos + 1)); // 返回整数部分和小数部分
}
int main() {
string num1, num2; // 用于存储输入的两个数字字符串
cin >> num1 >> num2; // 输入两个数字字符串
// 如果两个数字字符串中有一个不符合规则
if (!checkValid(num1) ||!checkValid(num2)) {
cout << "error" << endl; // 输出"error"
return 0;
}
pair<string, string> p1 = splitNum(num1); // 将第一个数字字符串拆分
pair<string, string> p2 = splitNum(num2); // 将第二个数字字符串拆分
string int1 = p1.first; // 第一个数字的整数部分
string int2 = p2.first; // 第二个数字的整数部分
string dec1 = p1.second; // 第一个数字的小数部分
string dec2 = p2.second; // 第二个数字的小数部分
// 如果整数部分不同,比较整数部分大小并输出较大的数字
if (int1!= int2) {
cout << (int1 > int2? num1 : num2) << endl;
}
// 如果整数部分相同,比较小数部分大小并输出较大的数字
else if (dec1!= dec2) {
cout << (dec1 > dec2? num1 : num2) << endl;
}
// 如果整数部分和小数部分都相同,输出"equation"
else {
cout << "equation" << endl;
}
return 0;
}摘葡萄
【题目描述】葡萄架上的葡萄熟了,小明要去摘葡萄,已知葡萄架上每串葡萄的高度和小明伸手可以够到的高度(高度值均为厘米),只要手能够到就可以摘下。另外,小明还带了一个 30厘米高的小凳子,可以站在凳子上摘葡萄。小明的力气有限,已知小明最初的力气值n,站在地上摘一串葡萄耗费1个力气值,站在小凳上摘葡萄耗费2个力气值,力气值不够就不能摘了。请帮助计算一下小明在力气值耗尽前最多可以摘下多少串葡萄。
【输入格式】
第一行由空格隔开的三个整数h,n,m,0<h<256,0<n<256,0<m<256,为小明站在地面伸手可够到的高度、初始力气值和架上葡萄的总串数。
第二行由空格隔开的每串葡萄的高度值,为1到255间的整数。
【输出格式】一个整数,为可以摘到葡萄的串数。
【样例输入】(测试数据不包含本样例)
140 10 13
130 135 120 155 190 140 130 180 170 150 110 200 130
【样例输出】
8
解析:贪心,01背包都可以搞定
这个题目可以采用含心算法的思想来解决。贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。
具体到这个葡萄摘取的问题,应用贪心算法的思路如下
1)最低成本的摘取优先:由于在地面上摘葡萄消耗的力气值最少(1 个),所以优先摘取无需凳子且在小明够得着的葡萄串。
2)次低成本的摘取其次:当地面上的葡萄都摘完之后,使用剩余的力气去尝试摘搭凳子才能够到的葡萄串这些葡萄每摘一串消耗的力气值为2个。
3)能够摘取的最大数量:在保证力气值允许的情况下,尽可能多地摘取葡萄串,直到力气值耗尽。
实现这个含心策略的关键步骤是先将葡萄高度进行排序,然后从低到高去判断每一串葡萄是否能被摘到。排序是为了保证我们能够按照先地面后凳子的顺序尽可能地摘取更多葡萄。
如何去实现排序是一个实现细节问题,在代码示例中,我们使用了冒泡排序。在实践中,可以直接sont 简洁且高效。
#include <bits/stdc++.h>
using namespace std;
int main() {
int h, n, m;
cin >> h >> n >> m;// 葡萄的总串数不会超过 256
int grapes[256];
for (int i = 0; i < m; i++) {
cin >> grapes[i];
}
// 使用冒泡排序对葡萄的高度进行升序排序
for (int i = 0; i< m - 1; i++) {
for (int j= 0; j<m -i- 1; j++) {
if (grapes[j] > grapes[j + 1]) {
swap(grapes[j], grapes[j + 1]);
}
}
}
// 计数已摘的葡萄
int count = 0;
for (int i = 0; i< m; i++) {
if (grapes[i]<= h &&n >= 1) {
// 如果葡萄在小明的直接够得到的高度内
// 摘一串葡萄消耗 1 点力气
n--;
// 增加摘到的葡萄串数
count++;
} else if (grapes[i] <= h+30 && n >= 2) {
// 如果葡萄的高度需要用小凳子达到
// 站在小凳子上摘一串葡萄消耗2点力气
n -= 2;
count++;
}
if(n < 1) {
// 力气耗尽则退出
break;
}
}
// 输出小明能够摘到的葡萄串数
cout << count << endl;
return 0;
}01背包
#include <bits/stdc++.h>
using namespace std;
//01背包
// 定义最大葡萄串数量
const int MAXN = 256;
// 存储每串葡萄的高度
int grapes[MAXN];
// 动态规划数组,dp[j] 表示力气值为 j 时可以摘下的最多葡萄串数
int dp[MAXN];
int main() {
int h, n, m;
cin >> h >> n >> m; // 输入小明伸手可够到的高度、初始力气值和葡萄串总数
for (int i = 0; i < m; i++) {
cin >> grapes[i]; // 输入每串葡萄的高度
}
for (int i = 0; i < m; i++) {
for (int j = n; j >= 0; j--) {
if (grapes[i] <= h) {
// 如果小明能够直接摘到这串葡萄
if (i >= 2) {
// 比较当前状态下摘到的葡萄串数和之前状态摘到葡萄串数 + 2 的大小
dp[j] = max(dp[j], dp[j - 1] + 2);
}
}
// 如果小明站在凳子上能够摘到这串葡萄,或者考虑是否摘下来
if (grapes[i] <= h + 30) {
if (j >= 2) {
// 比较当前状态下摘到的葡萄串数和之前状态摘到葡萄串数 + 1 的大小
dp[j] = max(dp[j], dp[j - 2] + 1);
}
}
}
}
cout << dp[n] << endl; // 输出力气值为 n 时可以摘下的最多葡萄串数
return 0;
}自动驾驶汽车的路径规划问题
【题目描述】一个自动驾驶的汽车,其只能按照调度系统到指定的景点停车场进行充电,每个景点中间的路上,都会有一些游客上车前往下一个景点。调度系统会告诉自动驾驶汽车,到哪个景点的停车场上充电,但具体走那条路到该停车场充电没有限制,但是自动驾驶汽车在每次行进过程中,不能重复到达同一个景点。请设计算法,给出从景点a到景点b进行充电,再返还景点a,这个自动驾驶汽车如何规划行进线路(线路上不能到达同一个景点多次),使得沿途接上的游客数量是最多的,并输出最多的上车的游客数量。
【输入格式】
第一行有两个数:n和m,其中n表示景点的数量,m是景点间的单行道数量。
第二行到第 m+1行,有三个整数:第一个数是起始景点的编号,第二个数是该路径终点景点的编号,第三个数是从起点到终点,需要乘车的人数。
第m+2行,有两个数字,第一个数字是自动驾驶汽车的出发景点,第二数字是中间进行充电的景点编号。
【输出格式】
一个数,表示该自动驾驶汽车往返一次,可以接送最多多少人。
【样例输入】(测试数据不包含本样例)
3 5
1 2 4
2 1 6
1 3 11
3 1 3
2 3 2
1 2
【样例输出】
10
一、整体思路
-
首先,通过输入获取景点数量
n、单行道数量m以及各条道路的起点、终点和乘客数量,构建景点之间的有向图。 -
然后,使用深度优先搜索(DFS)算法,分两步进行搜索:
-
第一步,从起始景点出发,在不重复访问景点的前提下,寻找到达充电景点的路径,并计算沿途搭载的乘客数量,更新最大乘客数量
maxPassengers。 -
第二步,从充电景点出发,同样在不重复访问景点的前提下,寻找返回起始景点的路径,并计算沿途搭载的乘客数量,再次更新
maxPassengers。
-
-
最后,输出
maxPassengers,即为自动驾驶汽车往返一次最多可以接送的乘客数量。
二、详细步骤
(一)数据输入与图构建
-
在
main函数中,首先通过cin >> n >> m读取景点数量n和单行道数量m。 -
接着通过一个循环,每次读入一条道路的起点
u、终点v和乘客数量w,并使用edges[u].push_back({v, w})将这条道路信息添加到edges数组中,构建起有向图,其中edges[u]存储了从景点u出发可以到达的景点以及对应的乘客数量。
(二)深度优先搜索(DFS)
-
dfs函数用于进行深度优先搜索。函数接受当前景点u、当前搭载的乘客数量passengers和一个布尔值isReturn作为参数。如果isReturn为false,表示是去程;为true,表示是回程。 -
当当前景点
u是目标景点(如果是去程,目标景点是充电景点;如果是回程,目标景点是起始景点)时,更新maxPassengers为当前乘客数量和已有最大乘客数量中的最大值,然后返回。 -
否则,将当前景点
u标记为已访问visited[u] = true,然后遍历从u出发的所有边(通过for (vector<Edge>::iterator it = edges[u].begin(); it!= edges[u].end(); ++it)实现)。 -
对于每条边,如果对应的终点景点未被访问(
if (!visited[it->to])),则递归调用dfs函数,将终点景点作为新的当前景点,乘客数量增加为当前乘客数量加上当前边的乘客数量(passengers + it->w),并保持isReturn的值不变,继续搜索。 -
搜索完从当前景点出发的所有可能路径后,将当前景点标记为未访问
visited[u] = false,进行回溯,以便其他路径的搜索。
(三)结果输出
-
先从起始景点进行去程的深度优先搜索
dfs(start, 0, false)。 -
然后重置访问标记
fill(visited, visited + MAXN, false),为回程搜索做准备。 -
从充电景点进行回程的深度优先搜索
dfs(ending, maxPassengers, true)。 -
最后输出最大乘客数量
maxPassengers。#include <bits/stdc++.h> using namespace std; const int MAXN = 1e5 + 10; struct Edge { int to, w; }; vector<Edge> edges[MAXN]; // 存储图的边 bool visited[MAXN] = {false}; // 初始化 visited 数组 int n, m; // n 表示景点数量,m 表示单行道数量 int start, ending; // 起始景点和充电景点 int maxPassengers = 0; // 最大乘客数量 // 深度优先搜索函数 void dfs(int u, int passengers, bool isReturn) { if (u == (isReturn? start : ending)) { // 如果到达目标景点 maxPassengers = max(maxPassengers, passengers); // 更新最大乘客数量 return; } visited[u] = true; // 标记当前景点已访问 /*“for”是循环结构的关键字,用于创建一个循环。 “vector<Edge>::iterator”表示一个指向向量(vector)中“Edge”类型元素的迭代器(iterator)。“edges[u]”可能是一个与“u”相关的向量对象。“begin()”和“end()”是用于获取向量起始和结束迭代器的方法。 整个循环的目的是遍历“edges[u]”这个向量中的元素。*/ for (vector<Edge>::iterator it = edges[u].begin(); it!= edges[u].end(); ++it) { /*如果变量 visited 中对应 it->to 的元素值为假(未被访问), 那么就会执行 dfs 函数,向其传递 it->to 、 passengers + it->w 以及 isReturn 这几个参数。 通常出现在与深度优先搜索算法或类似的程序逻辑中。*/ if (!visited[it->to]) { dfs(it->to, passengers + it->w, isReturn); } } visited[u] = false; // 回溯时取消访问标记 } int main() { cin >> n >> m; for (int i = 0; i < m; i++) { int u, v, w; cin >> u >> v >> w; /*edges[u].push_back({v, w})” 表示将一个包含节点 v 和权重 w 的元素添加到节点 u 的邻接表 edges 中*/ edges[u].push_back({v, w}); // 构建图 } cin >> start >> ending; dfs(start, 0, false); // 去程搜索 fill(visited, visited + MAXN, false); // 重置访问标记 dfs(ending, maxPassengers, true); // 回程搜索 cout << maxPassengers << endl; // 输出最大乘客数量 return 0; }



















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











