






第一部分:Windows本地运行时
(一)配置环境
(1)准备的东西(版本可以以自己的为准)
可以将以下内容下载到同一个文件夹,容易找到并方便配置环境变量。
①jdk1.8.0_141
②maven3.8.6 链接:maven官网
③hadoop2.7.7 链接:hadoop下载
④hadoop.dll和winutils.exe 提取码:2222 网盘链接:https://pan.baidu.com/s/19IupLMvcDM2R51oKOvBmhQ
⑤IDEA2020.1.2
1.1环境变量的配置
1.1.1:找到环境变量设置,在系统变量中新建以下内容(注意使用自己的路径)



1.1.2 在系统变量的path中添加如下内容:

1.1.3 在cmd中确认安装成功,每个命令都出现相应版本内容即成功:
java -version
mvn -version
hadoop -version
1.1.4 将hadoop.dll和winutils.exe复制到hadoop的bin文件夹下,并将hadoop.dll复制到C:\Windows\System32目录下
1.1.5 修改Maven仓库下载镜像及修改仓库位置
1.1.5.1可以在Maven路径下新建一个叫repository的文件夹,用来存放相关配置
1.1.5.2打开Maven的安装目录–>conf文件夹–>setting.xml,用记事本打开就行,并修改代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<!-- 本地仓库的位置 ,==注意这里的路径改成自己的==-->
<localRepository>D:\Linux\apache-maven\repository</localRepository>
<!-- Apache Maven 配置 -->
<pluginGroups/>
<proxies/>
<!-- 私服发布的用户名密码 -->
<servers>
<server>
<id>releases</id>
<username>deployment</username>
<password>He2019</password>
</server>
<server>
<id>snapshots</id>
<username>deployment</username>
<password>He2019</password>
</server>
</servers>
<!-- 阿里云镜像 -->
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<!-- https://maven.aliyun.com/repository/public/ -->
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
<!-- 配置: java8, 先从阿里云下载, 没有再去私服下载 -->
<!-- 20190929 hepengju 测试结果: 影响下载顺序的是profiles标签的配置顺序(后面配置的ali仓库先下载), 而不是activeProfiles的顺序 -->
<profiles>
<!-- 全局JDK1.8配置 -->
<profile>
<id>jdk1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>
<!-- Nexus私服配置: 第三方jar包下载, 比如oracle的jdbc驱动等 -->
<profile>
<id>dev</id>
<repositories>
<repository>
<id>nexus</id>
<url>http://nexus.hepengju.cn:8081/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>public</id>
<name>Public Repositories</name>
<url>http://nexus.hepengju.cn:8081/nexus/content/groups/public/</url>
</pluginRepository>
</pluginRepositories>
</profile>
<!-- 阿里云配置: 提高国内的jar包下载速度 -->
<profile>
<id>ali</id>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
<!-- 激活配置 -->
<activeProfiles>
<activeProfile>jdk1.8</activeProfile>
<activeProfile>dev</activeProfile>
<activeProfile>ali</activeProfile>
</activeProfiles>
</settings>
1.1.6 在hadoop-.7.7目录下创建data文件夹,并在data下再创建datanode和namenode文件夹,并在etc/hadoop目录下修改以下文件
1.1.6.1 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
1.1.6.2 修改mapred-site.xml.template
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
1.1.6.3 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/Linux/hadoop-2.7.7/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/Linux/hadoop-2.7.7/data/datanode</value>
</property>
</configuration>
1.1.6.4 修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
</configuration>
1.1.6.5 双击打开hadoop-env.cmd,如果打不开就用记事本打开,注意:如果你的JAVA_HOME路径中含有空格,如你放在了Program Files文件夹下,需要把空格替换成PROGRA~1
set JAVA_HOME=D:\Java\jdk1.8.0_212 //没有空格时
set JAVA_HOME=D:\PROGRA~1\jdk1.8.0_212 //有空格时
1.1.7 打开cmd,格式化hdfs
hdfs namenode -format
1.1.8 启动hadoop。弹出四个页面,并出现如下进程才算成功
>d:
>cd %HADOOP_HOME%\sbin
>start-all //此时会弹出四个命令框
>jps
18096 DataNode
15012 ResourceManager
15268 NodeManager
11944 Jps
15564 NameNode
(二)Windows环境下,IDEA中创建maven工程,以各部门员工工资总和为例
2.1配置IDEA的maven
2.1.1点击File—>settings—>Maven,注意使用自己的路径

2.2创建项目
2.2.1数据准备
2.2.1.1可以在hadoop-2.7.7的目录下创建data—>input文件夹,用来保存数据源
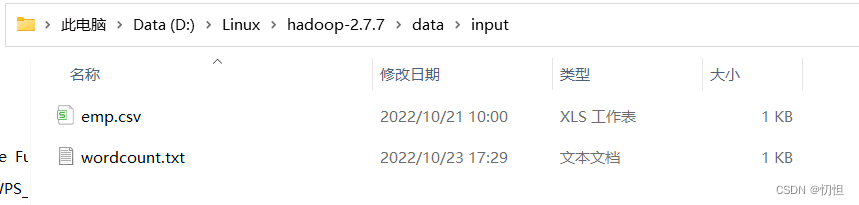
2.2.2创建项目,选择maven
2.2.3修改pom.xml,添加相关依赖,可以在 maven相关配置中搜索自己需要的,如下图所示:
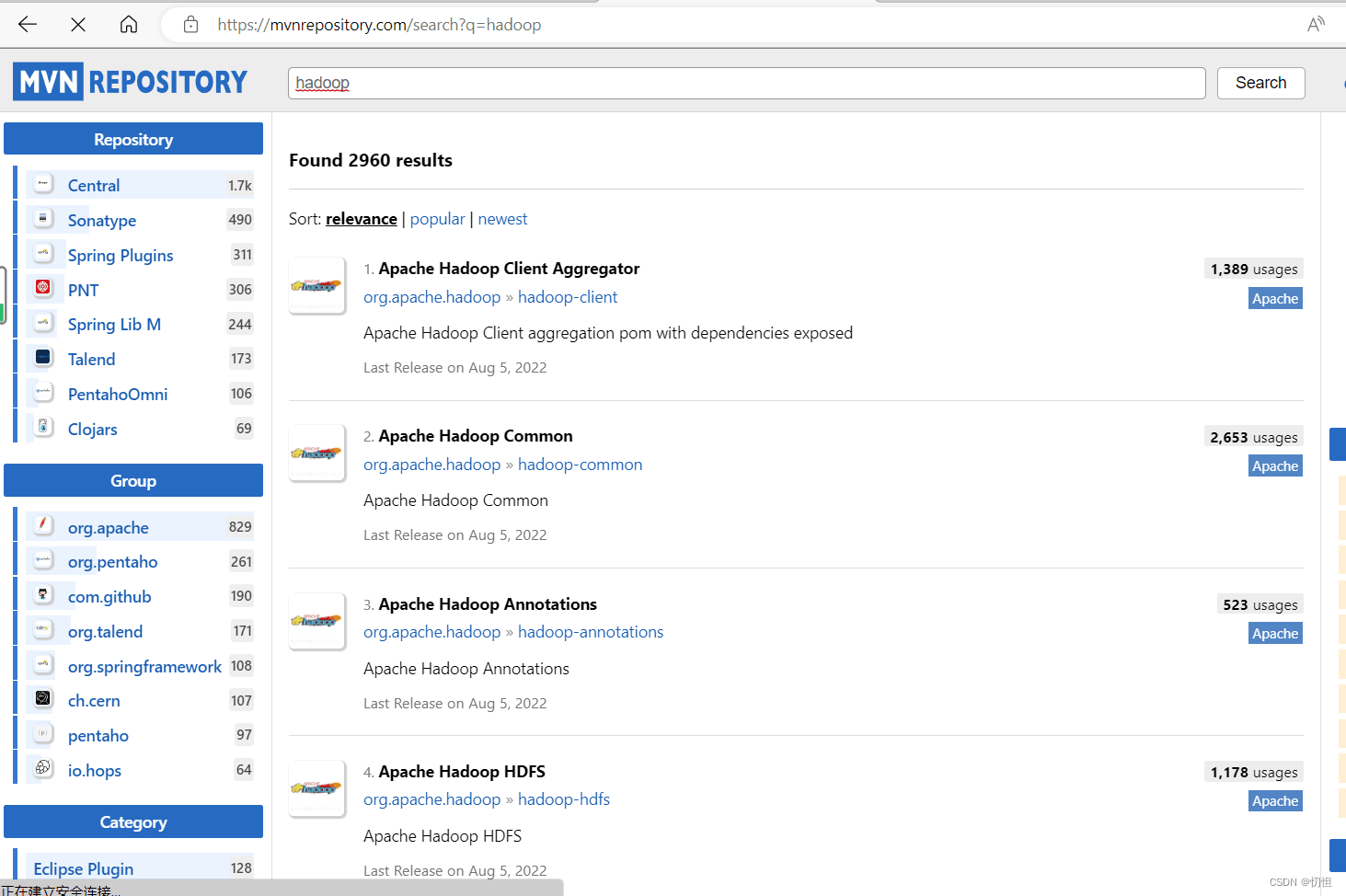
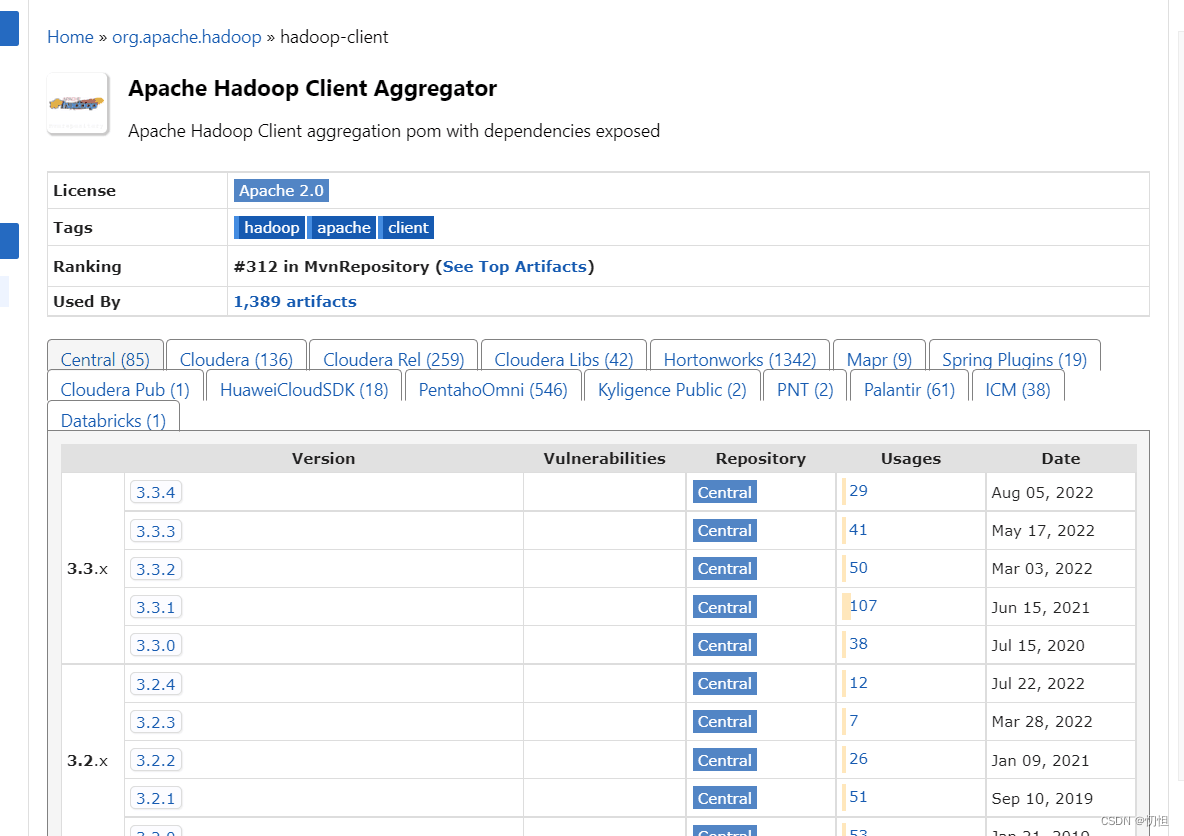
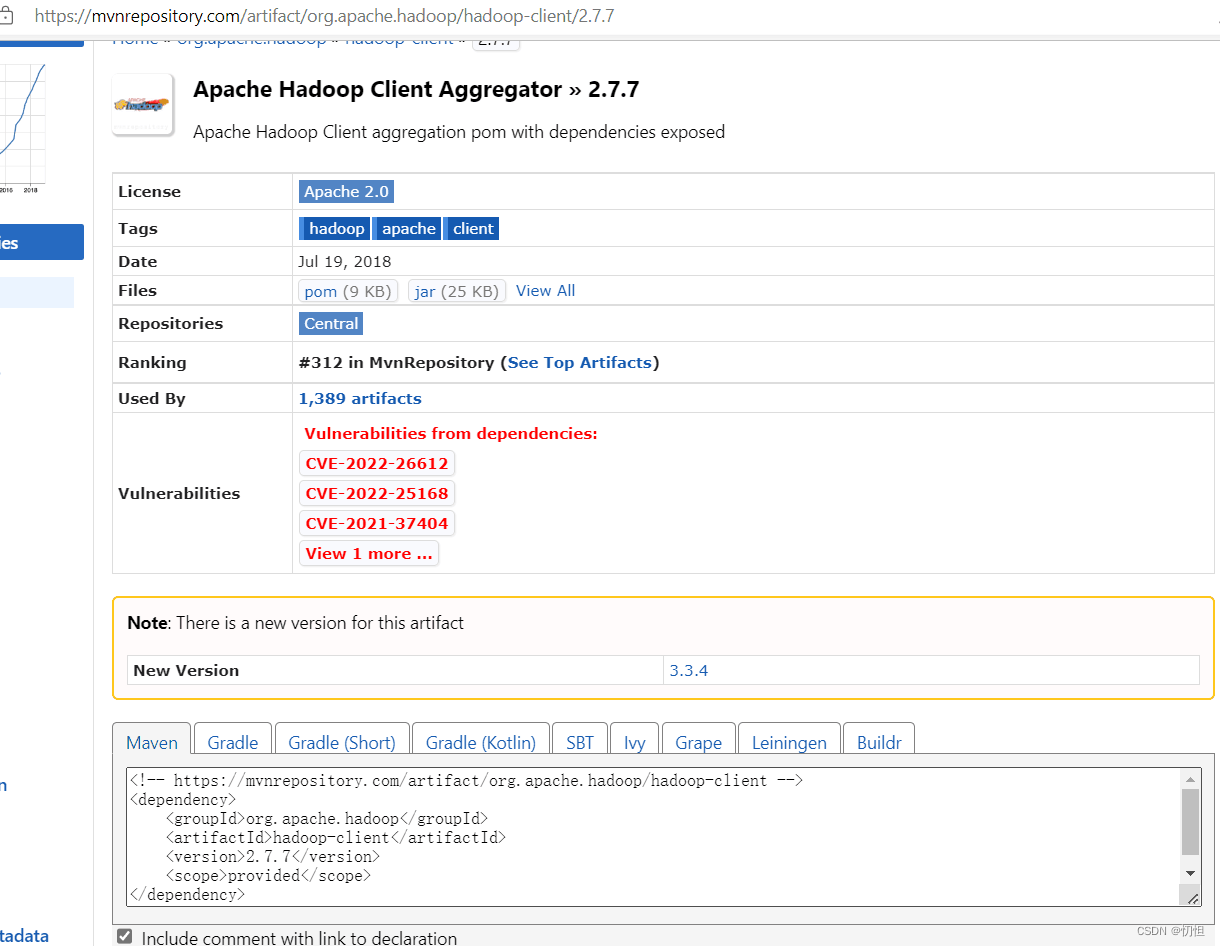
2.2.4目录创建,代码运行
2.2.4.1 创建Employee类:
package cn.zf.mapreduce;
import org.apache.hadoop.io.Writable;
import javax.jnlp.JNLPRandomAccessFile;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Employee implements Writable {
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;
@Override
public void readFields(DataInput input) throws IOException {
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
}
@Override
public void write(DataOutput output) throws IOException {
output.writeInt(this.empno);
output.writeUTF(this.ename);
output.writeUTF(this.job);
output.writeInt(this.mgr);
output.writeUTF(this.hiredate);
output.writeInt(this.sal);
output.writeInt(this.comm);
output.writeInt(this.deptno);
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
2.2.4.2 创建EmployeeMapper类:
package cn.zf.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class EmployeeMapper extends Mapper<LongWritable, Text, IntWritable, Employee> {
@Override
protected void map(LongWritable key1, Text value1,Context context)
throws IOException, InterruptedException {
String data = value1.toString();
String[] words = data.split(",");
Employee e = new Employee();
e.setEmpno(Integer.parseInt(words[0]));
e.setEname(words[1]);
e.setJob(words[2]);
try{
e.setMgr(Integer.parseInt(words[3]));
}catch(Exception ex){
e.setMgr(-1);
}
e.setHiredate(words[4]);
e.setSal(Integer.parseInt(words[5]));
try{
e.setComm(Integer.parseInt(words[6]));
}catch(Exception ex){
e.setComm(0);
}
e.setDeptno(Integer.parseInt(words[7]));
context.write(new IntWritable(e.getDeptno()),
e);
}
}
2.2.4.3 创建EmployeeReducer类:
package cn.zf.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class EmployeeReducer extends Reducer<IntWritable, Employee, IntWritable, IntWritable> {
@Override
protected void reduce(IntWritable k3, Iterable<Employee> v3,Context context)
throws IOException, InterruptedException {
//取出v3中的每个员工 进行工资求和
int total = 0;
for(Employee e:v3){
total = total + e.getSal();
}
//输出
context.write(k3, new IntWritable(total));
}
}
2.2.4.4 创建EmployeeMain类:
package cn.zf.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EmployeeMain {
public static void main(String[] args) throws Exception {
// 创建一个job
Job job = Job.getInstance(new Configuration());
job.setJarByClass(EmployeeMain.class);
//指定job的mapper和输出的类型 k2 v2
job.setMapperClass(EmployeeMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Employee.class);
//指定job的reducer和输出的类型 k4 v4
job.setReducerClass(EmployeeReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//Windows本地运行下,指定job的输入和输出的路径
FileInputFormat.setInputPaths(job, new Path("D:\\Linux\\hadoop-2.7.7\\data\\input\\emp.csv"));
FileOutputFormat.setOutputPath(job, new Path("D:\\Linux\\hadoop-2.7.7\\data\\out\\salary_out3"));
/** 上传到Ubuntu时用如下代码
FileInputFormat.setInputPaths(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
*/
//执行任务
job.waitForCompletion(true);
}
}
2.2.5运行结果

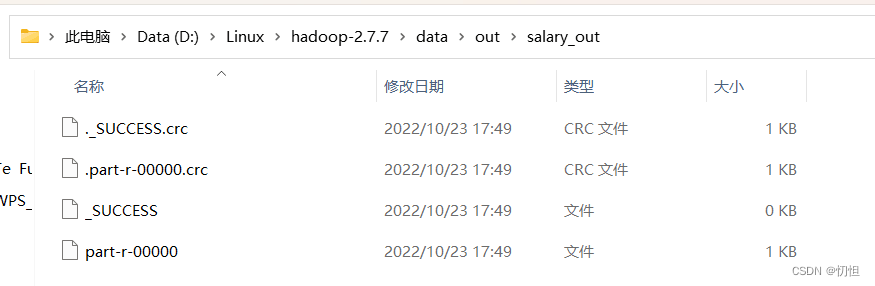
第二部分:将在Windows的IDEA中写的代码,上传到Linux环境中运行
(一)准备工作和思路
1.1 上传时需要的工具:Xshell5、Xftp5
1.2 思路:在Windows的IDEA中开发,写代码,然后打成jar包上传的你的Linux中
(二)在IDEA中完成项目代码后,打成jar包并上传。 注意:主类的文件输入输出路径的改变,在第一部分的2.2.4.4创建EmployeeMain时,代码注释中有写
1.在IDEA中依次点击如下内容,生成jar包
1.1.1点击File–>Project Structure–>Artifacts,接下来根据图片依次点击
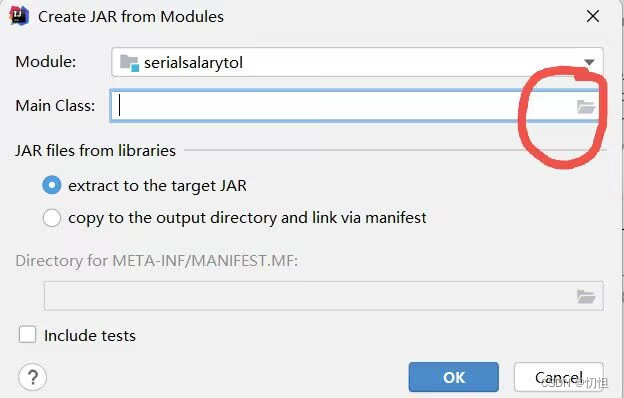
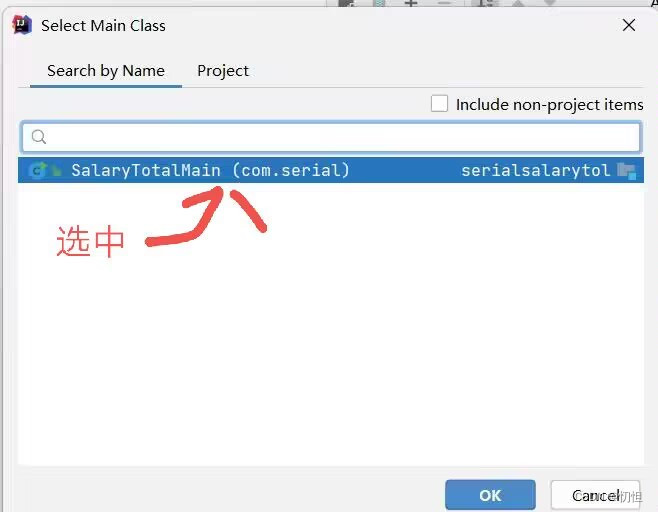
1.1.2 根据1.1.1步骤生成的结果形式如下图,点击Apply
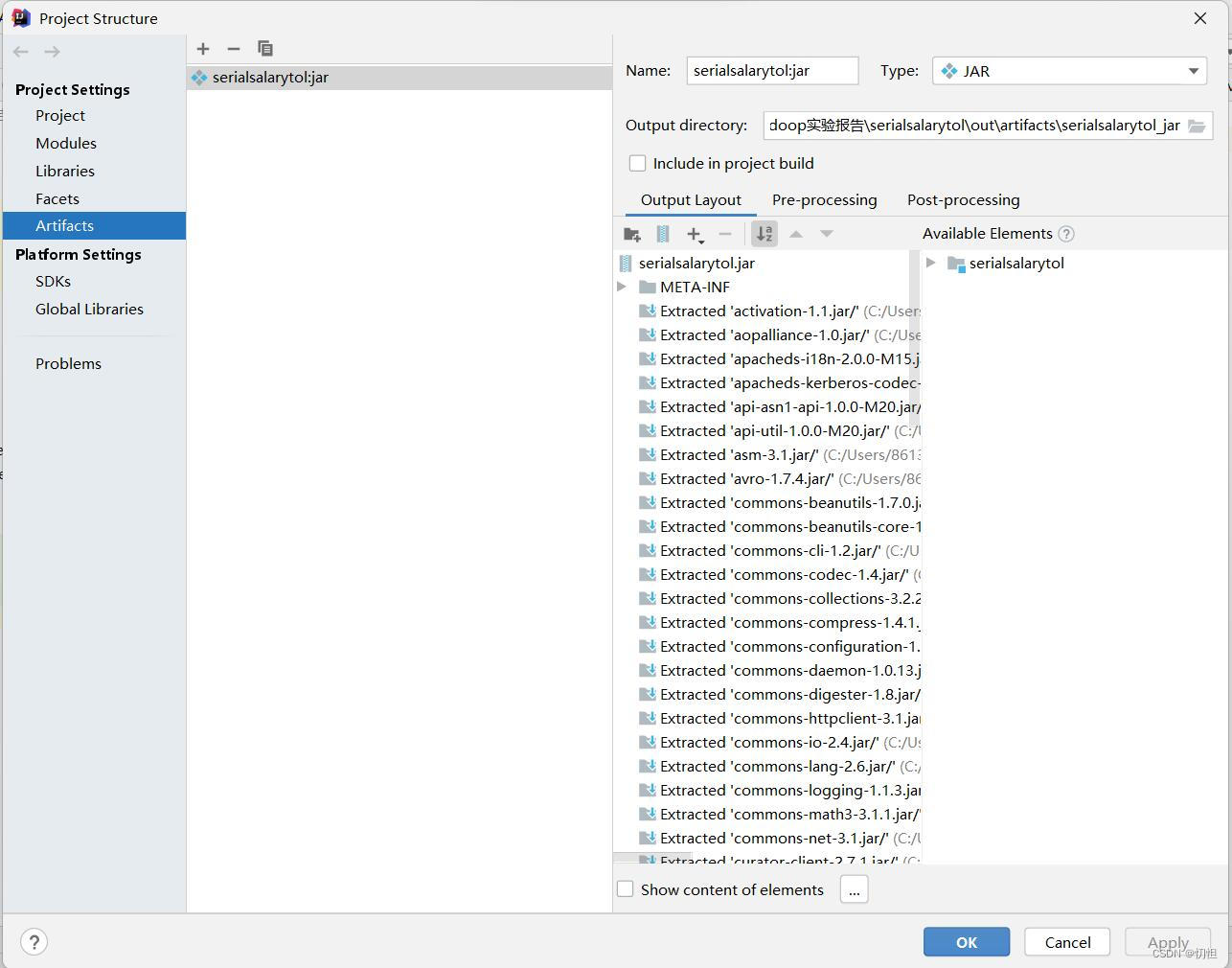
1.1.3如图位置,点击Rebuild Project,然后在IDEA的左下角会出现第二张图所示内容
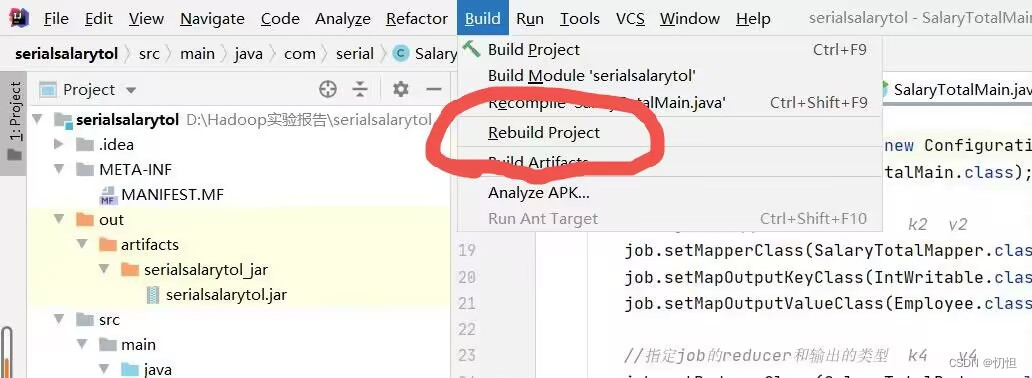
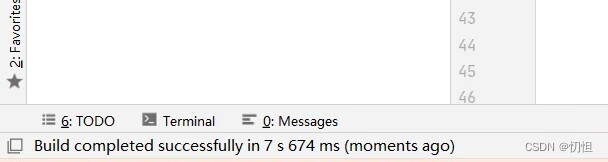
1.1.4 点击Build Artifacts,会弹出如第二张图所示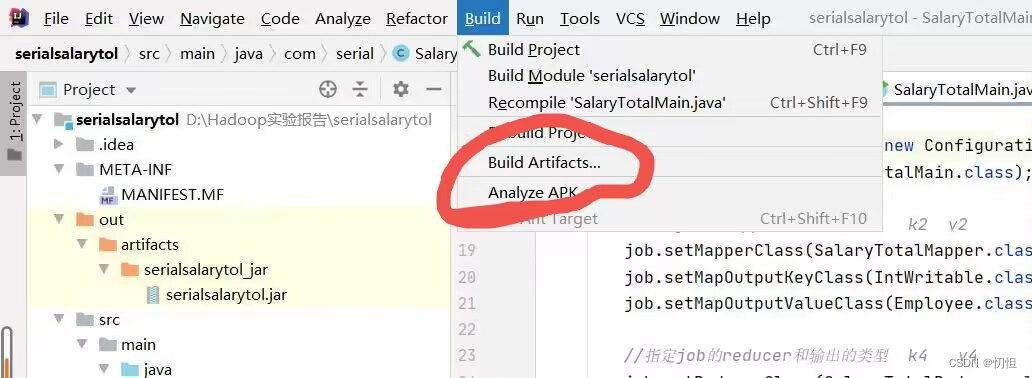
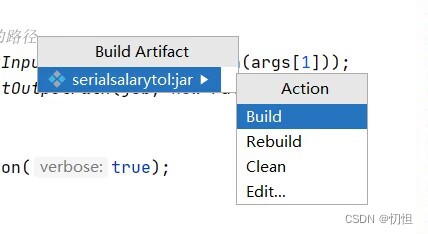
1.1.5 在左侧会生成out文件夹
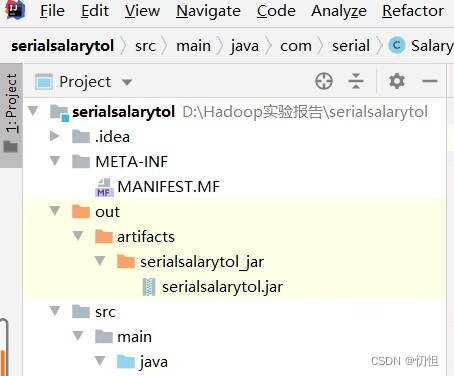
2.打开Xshell5
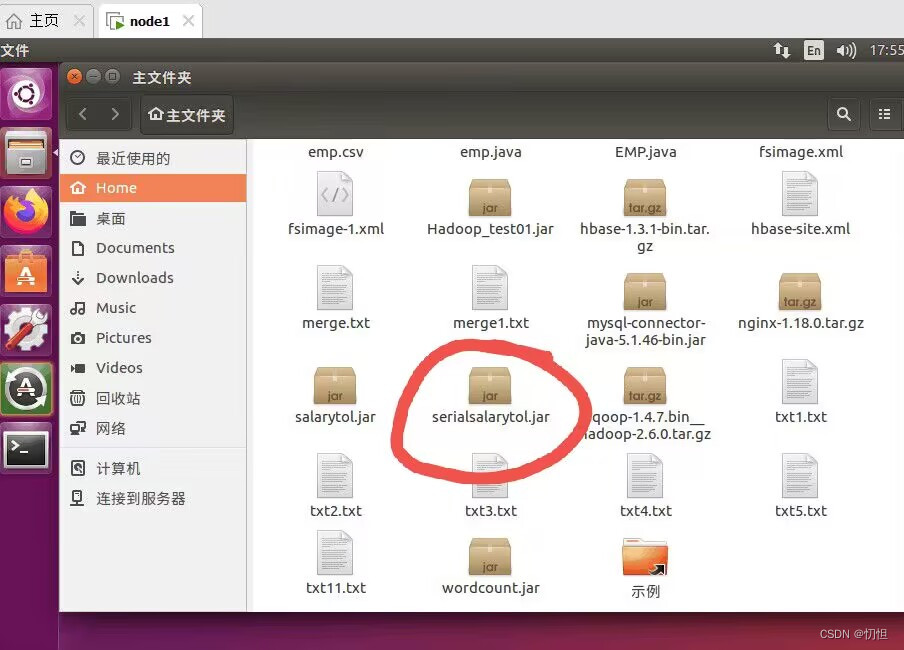
(1)成功连接上自己的Ubuntu之后,点击下面的图标即Xftp,将自己生成的jar包拖拽到Ubuntu中,生成的jar包可以在自己的IDEA项目工作环境中找到。
(2)将数据源emp.csv也上传到Ubuntu中

2.1上传成功后,可以在Ubuntu中查看
2.2 在Ubuntu的终端或者Windows的Xshell5中执行接下来的代码都可以
2.2.1 需要将数据源emp.csv上传到hdfs文件系统中,并且可以在Windows的浏览器中,输入网址:你的Ubuntu用户名:50070,查看hdfs文件系统更直观。例如,我的用户名为B18041739
hdfs dfs -put emp.csv /input/ //上传到hdfs的代码
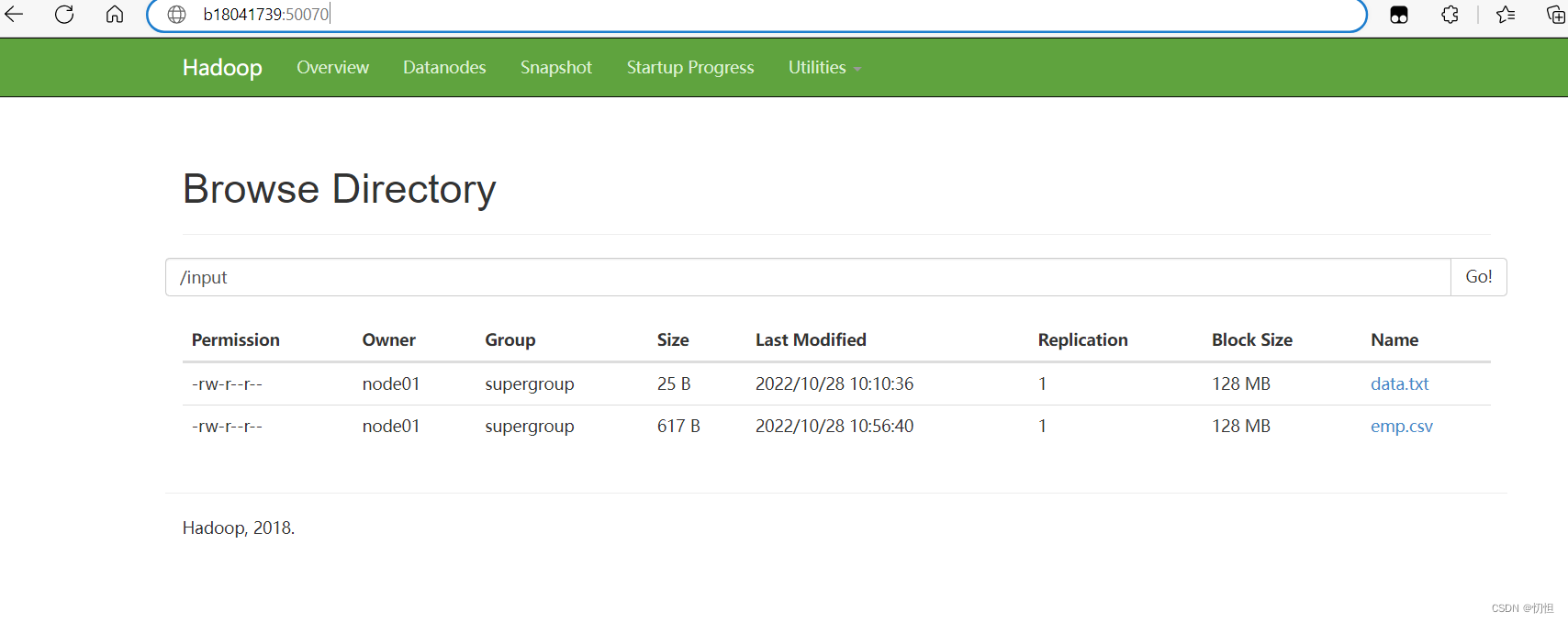
2.2.2 代码格式:hadoop jar jar包名字 IDEA项目中主类所在路径 数据源所在位置 输出路径,例如:
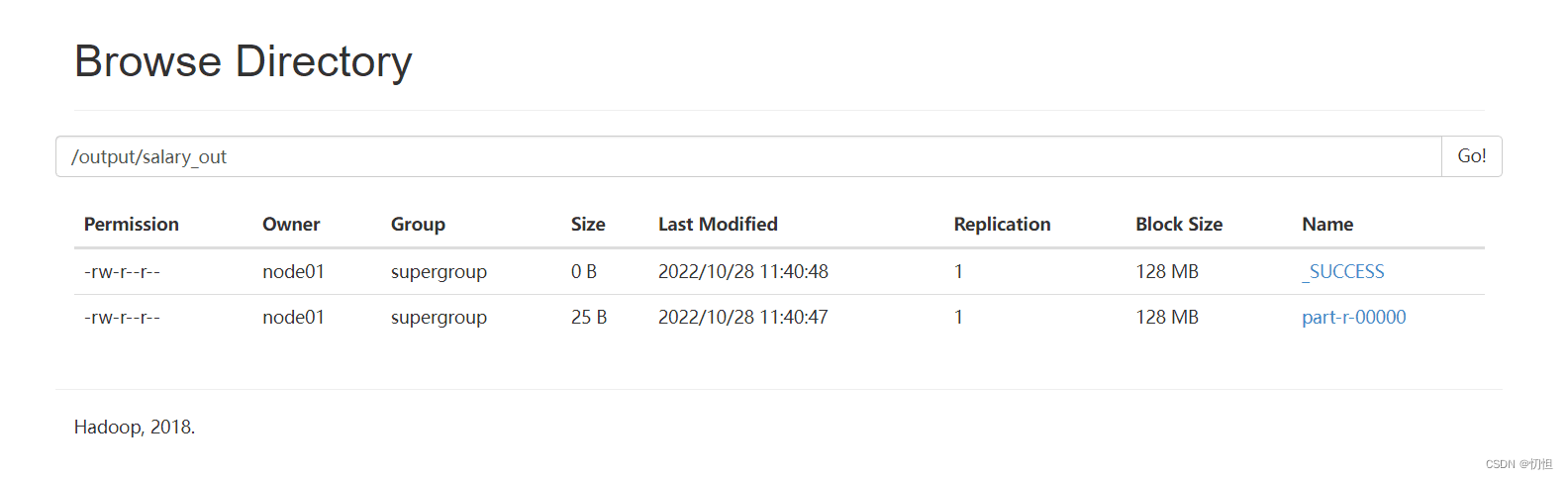
hadoop jar serialsalarytol.jar cn.zf.mapreduce.EmployeeMain /input/emp.csv /output/salary_out
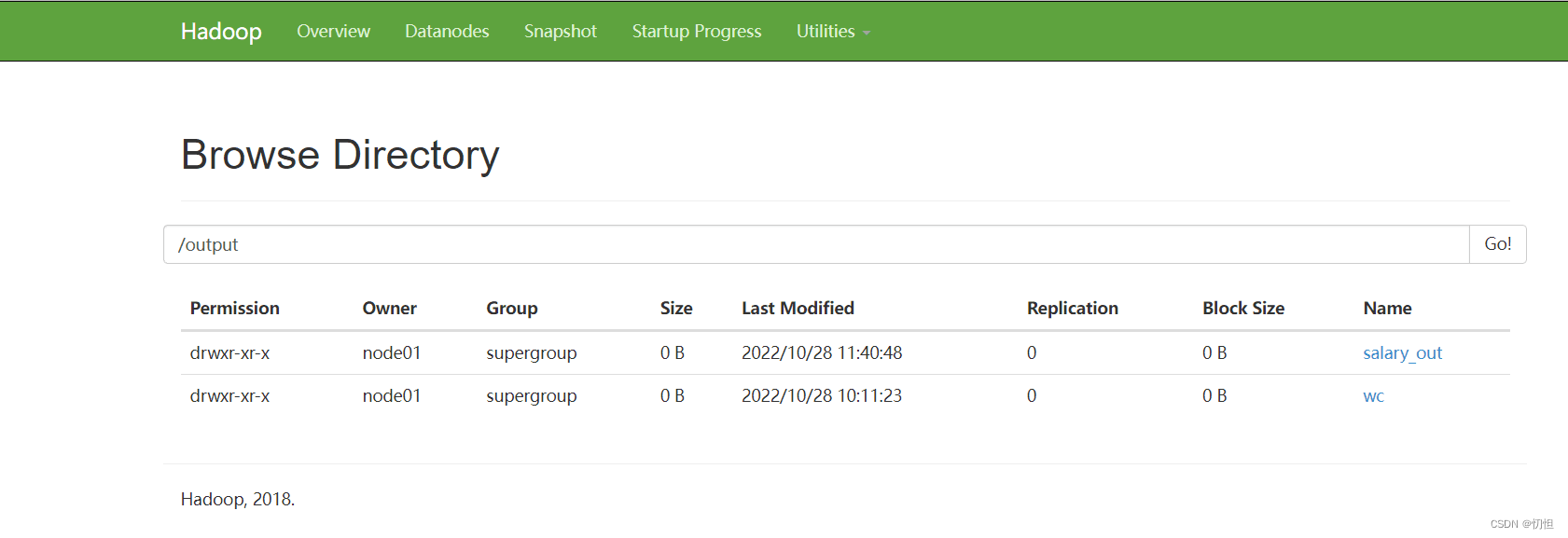
2.2.3 查看输出结果















 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









