






引言
近年来,强化学习(Reinforcement Learning, RL)在人工智能领域取得了显著进展,成为研究者们关注的核心领域之一。然而,尽管强化学习在许多应用中取得了突破,仍然面临着诸如策略评估不稳定和过估计等挑战。尤其是Q值的过估计问题,往往导致算法在训练过程中无法准确评估策略,从而影响优化效果。为了解决这一难题,值分布强化学习(Distributional Reinforcement Learning, DRL)应运而生,它通过显式建模价值的分布,缓解了过估计现象,并增强了策略优化的精度与鲁棒性。
基于这一思想,我们在2021年提出了DSAC(Distributional Soft Actor-Critic)算法,通过引入值分布方法有效减少了过估计带来的不利影响,并在多种强化学习任务中取得了显著的性能提升。然而,DSAC-v1在训练稳定性和处理复杂环境时仍存在一些挑战。为此,我们在DSAC-v1的基础上进行了三项关键性创新改进,推出了DSAC-T(DSAC-v2)。这三项改进不仅进一步降低了Q值的过估计问题,还显著提高了算法的稳定性和通用性,使其在更广泛的决策任务中表现出色。
在本文中,我们将详细介绍DSAC-T的创新之处、实验评估结果以及其在实际应用中的潜力。
研究贡献与技术创新
我们的工作旨在提升强化学习策略的性能,并通过以下三项创新性改进,打造了DSAC-T算法:
- 期望值替代(Expected Value Substituting):提高了学习的稳定性和效率;
- 基于方差的评论家梯度调整(Variance-based Critic Gradient Adjusting):减少了对人工调参的依赖,提高了算法的通用性;
- 双重值分布学习(Twin Value Distribution Learning):进一步抑制了过估计问题,提升了算法稳定性。
这些创新使得DSAC-T成为一种强大的model-free强化学习算法,能够有效抑制RL中的过估计现象,并在多个复杂决策场景中实现显著的性能提升,广泛应用于游戏AI、自动驾驶、工业控制等领域。
DSAC-v1论文链接:IEEE TNNLS DSAC-v1
DSAC-T论文链接:arXiv DSAC-T
DSAC-T项目地址:GitHub DSAC-T
技术路线与改进分析
DSAC-T(DSAC-v2)在DSAC-v1的基础上进行了三项关键性改进,成功突破了算法的性能瓶颈。
-
期望值替代(Expected Value Substituting): 这一创新通过将随机目标回报替换为更加稳定的Q值目标,显著减少了值分布学习过程中的随机性。此改进减少了基于均值的梯度的不稳定性,从而使得学习过程更加稳定和高效。通过精确的时间差分误差(TD error)计算,DSAC-T在面对不同奖励规模的环境时,能够展现更好的适应性与鲁棒性。
-
基于方差的评论家梯度调整(Variance-based Critic Gradient Adjusting): DSAC-v1中固定裁切边界的设置对奖励规模变化非常敏感,容易导致梯度爆炸问题。为此,DSAC-T通过引入基于奖励方差的自适应裁切边界来解决这一问题。具体而言,DSAC-T引入了新的参数ξ,使得剪裁边界b能够自动适应不同任务中的奖励规模变化。
-
双重值分布学习(Twin Value Distribution Learning): DSAC-T通过引入双重值分布网络来进一步抑制Q值的过估计现象。在每次梯度计算时,DSAC-T选择两个独立的值分布网络中均值较小的一个作为目标分布进行更新,从而引入适度的低估偏差。这种方式能够有效减少过估计问题,提高学习过程的稳定性。
性能对比
我们对DSAC-T进行了广泛的性能评估,并将其与多种主流model-free强化学习算法(如SAC、TD3、DDPG、TRPO、PPO)进行了对比。实验结果显示,DSAC-T在没有进行任何任务特定超参数调整的情况下,在所有测试环境中均超越或与其他算法匹敌。此外,相比于DSAC-v1,DSAC-T在学习过程中展现出更高的稳定性,并能够在不同奖励规模下保持一致的高性能。
在11个测试任务中,DSAC-T取得了10项第一名和1项第三名的优异成绩。这些结果表明,DSAC-T在多种任务环境中都表现出了非常强的性能和稳定性。
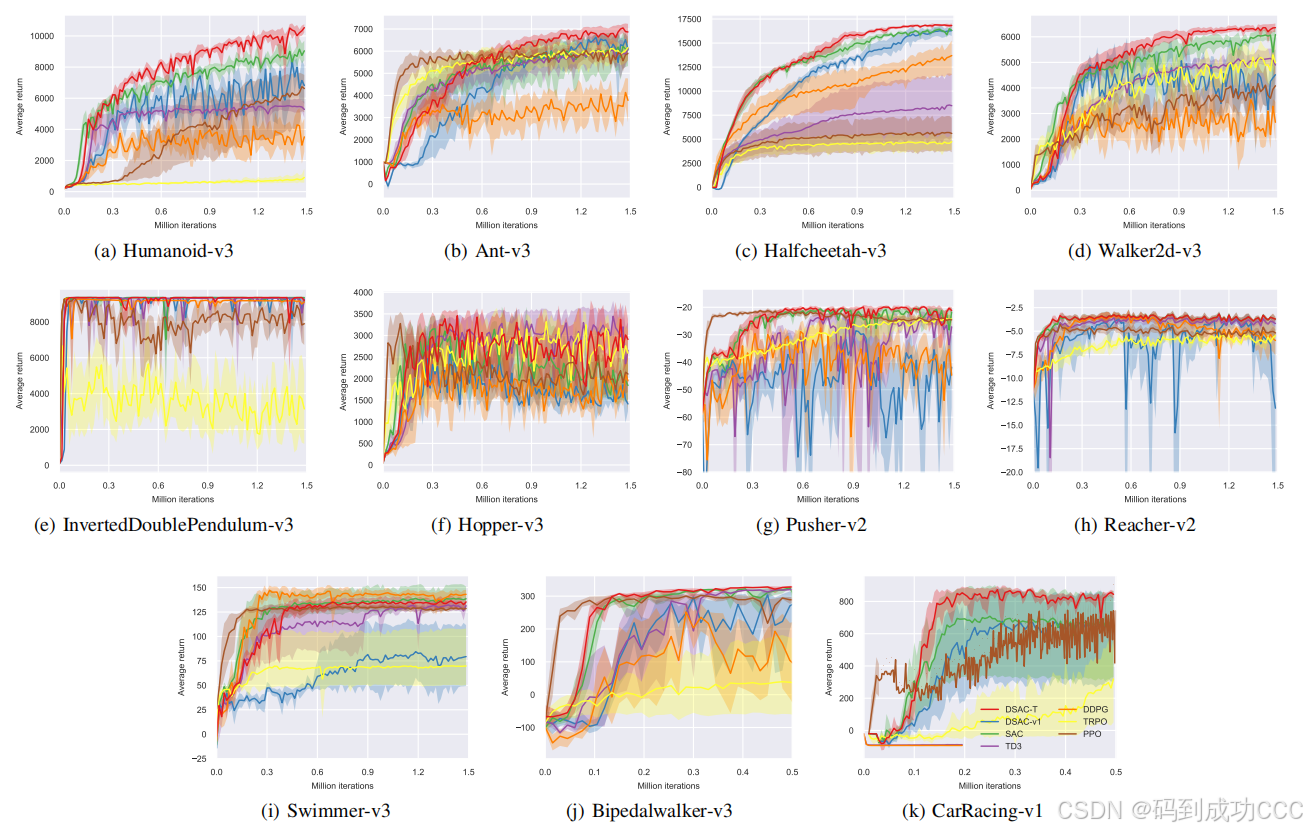
主流算法在各任务下累计平均回报曲线
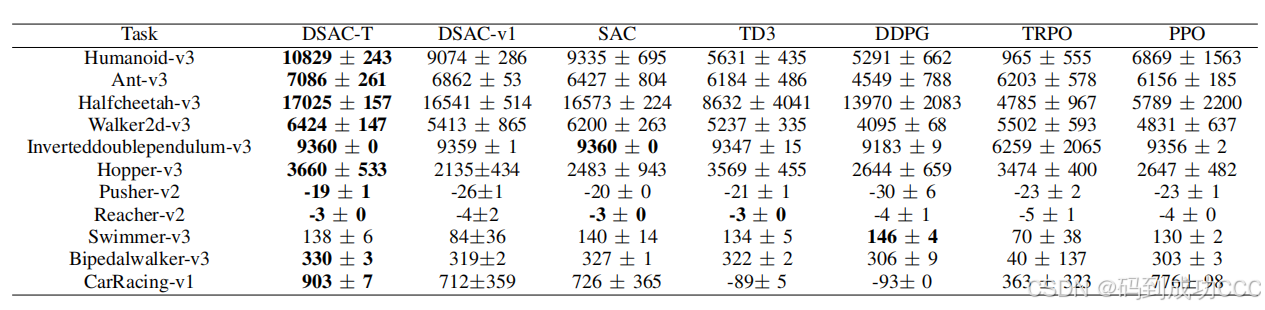
回报return
随着强化学习技术的不断进步,DSAC-T作为一种全新的值分布强化学习算法,展现了出色的性能和广泛的适应性。我们相信,随着进一步的优化和应用,DSAC-T将成为解决复杂决策任务和高维问题的有力工具。未来,我们计划将其应用于更广泛的领域,以推动强化学习在实际问题中的深度融合与落地应用。此外,随着计算能力和算法研究的进一步发展,DSAC-T也有望与其他前沿技术,如元学习和多任务学习,结合,进一步提升其在动态和多变环境中的表现。我们期待着在强化学习的新时代,DSAC-T能够为更多的创新和突破提供技术支持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









