






Apache Phoenix主要是基于HBase一款软件, 提供了一种全新(SQL)的方式来操作HBase中数据, 从而降低了使用HBase的门槛, 并且 Phoenix提供了各种优化措施
Phoenix官方网址:Overview | Apache Phoenix
Phoenix官网:「We put the SQL back in NoSQL」
Apache Phoenix让Hadoop中支持低延迟OLTP和业务操作分析。
- 提供标准的SQL以及完备的ACID事务支持
- 通过利用HBase作为存储,让NoSQL数据库具备通过有模式的方式读取数据,我们可以使用SQL语句来操作HBase,例如:创建表、以及插入数据、修改数据、删除数据等。
- Phoenix通过协处理器在服务器端执行操作,最小化客户机/服务器数据传输
- Apache Phoenix可以很好地与其他的Hadoop组件整合在一起,例如:Spark、Hive、Flume以及MapReduce。
使用Phoenix 是否会影响HBase的性能呢?
- Phoenix不会影响HBase性能,反而会提升HBase性能
- Phoenix将SQL查询编译为本机HBase扫描
- 确定scan的key的最佳startKey和endKey
- 编排scan的并行执行
- 将WHERE子句中的谓词推送到服务器端
- 通过协处理器执行聚合查询
- 用于提高非行键列查询性能的二级索引
- 统计数据收集,以改进并行化,并指导优化之间的选择
- 跳过扫描筛选器以优化IN、LIKE和OR查询
- 行键加盐保证分配均匀,负载均衡
那些公司在使用Phoenix ?

官方性能测试

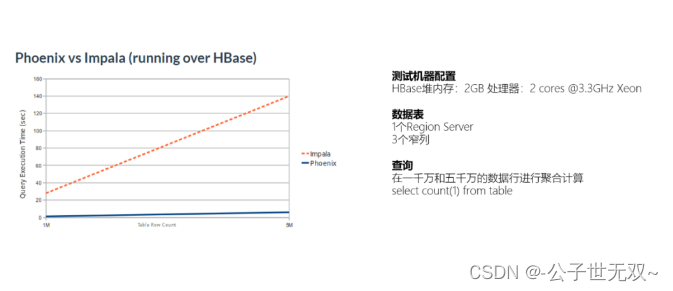
上述两张图是从Phoenix官网拿下来的,这容易引起一个歧义。就是:有了HBase + Phoenix,那是不是意味着,我们将来做数仓(OLAP)就可以不用Hadoop + Hive了?
千万不要这么以为,HBase + Phoenix是否适合做OLAP取决于HBase的定位。Phoenix只是在HBase之上构建了SQL查询引擎(注意:我称为SQL查询引擎,并不是像MapReduce、Spark这种大规模数据计算引擎)。HBase的定位是在高性能随机读写,Phoenix可以使用SQL快插查询HBase中的数据,但数据操作底层是必须符合HBase的存储结构,例如:必须要有ROWKEY、必须要有列蔟。因为有这样的一些限制,绝大多数公司不会选择HBase + Phoenix来作为数据仓库的开发。而是用来快速进行海量数据的随机读写。这方面,HBase + Phoenix有很大的优势。
















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











