







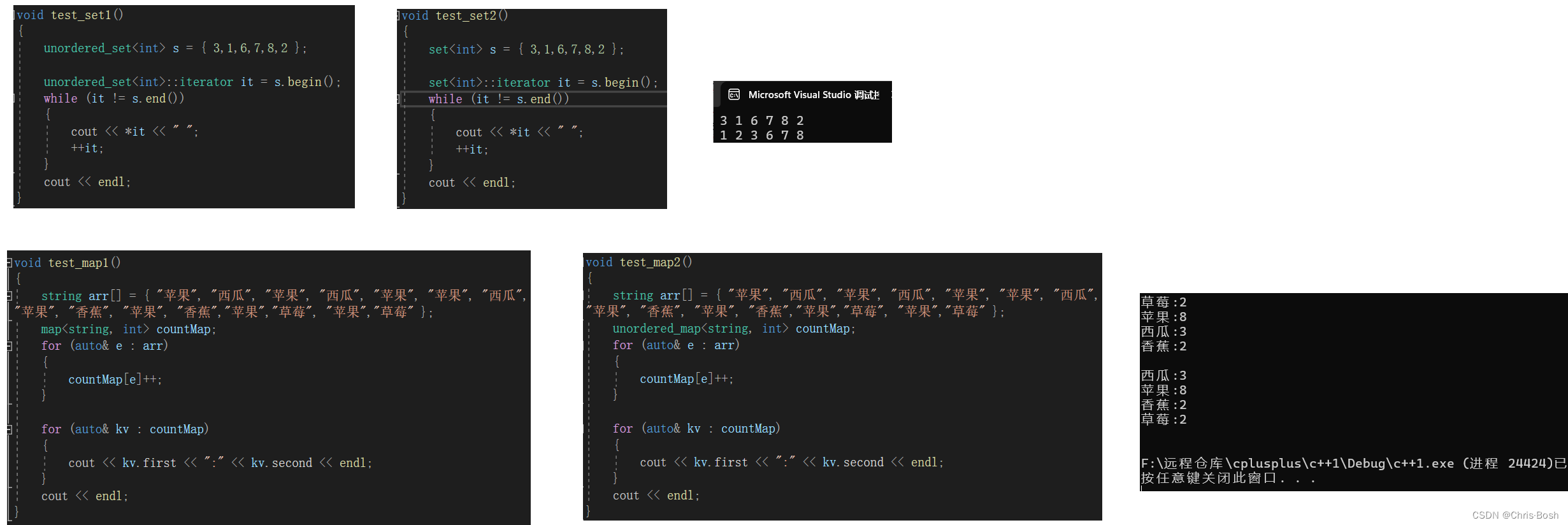
unordered_map和unordered_set的底层是哈希表
1.unordered_map和unordered_set

unordered_map和unordered_set与map和set的对比:
2.什么是哈希?
①插入:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。
②搜索:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
该方式就和计数排序非常相似
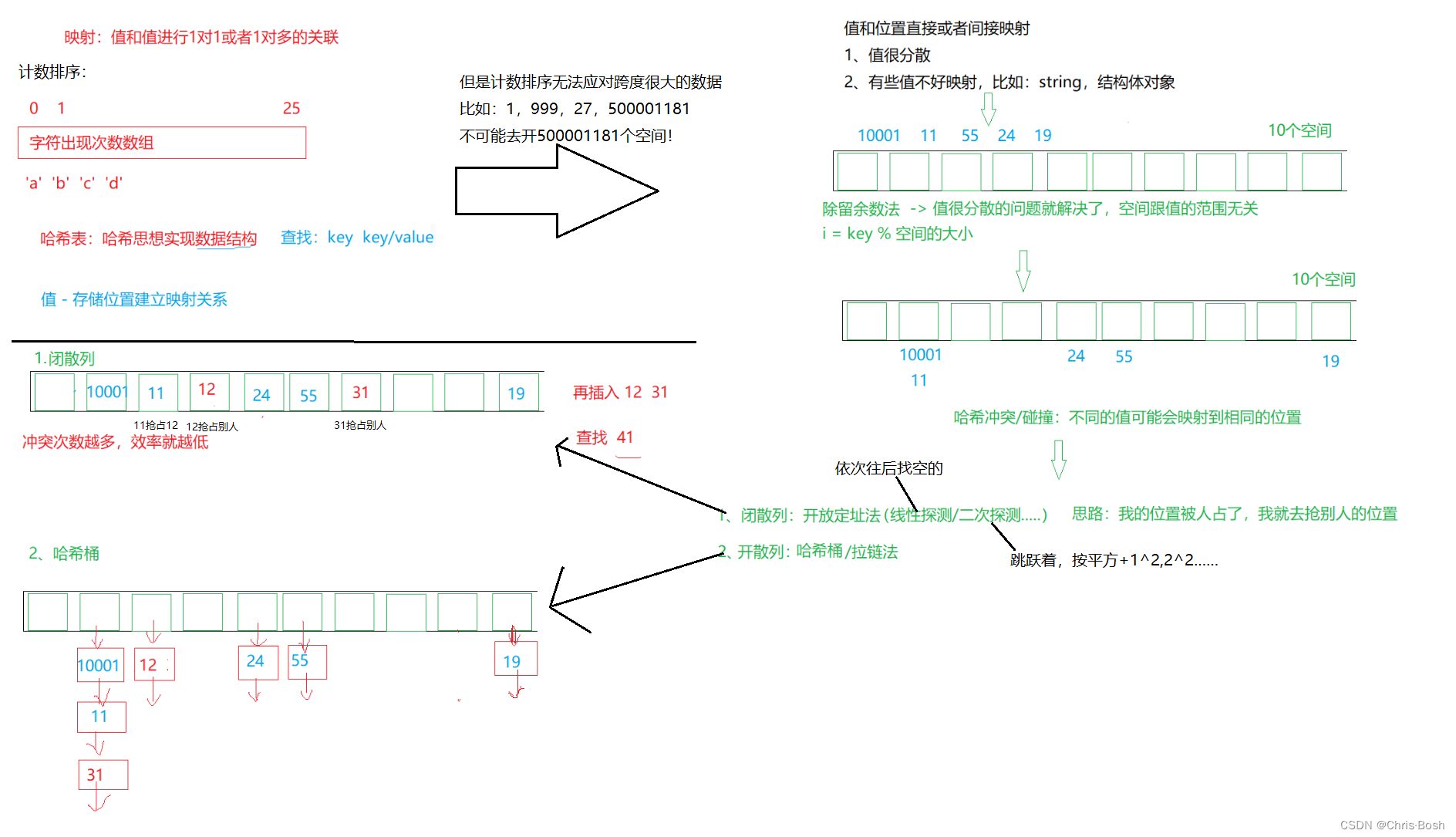
2.1 哈希表

哈希表闭散列线性探测实现
// 注意:假如实现的哈希表中元素唯一,即key相同的元素不再进行插入
// 为了实现简单,此哈希表中我们将比较直接与元素绑定在一起
namespace Close_Hash
{
enum State{EMPTY, EXIST, DELETE};
template<class K, class V>
class HashTable
{
struct Elem
{
pair<K, V> _val;
State _state;
};
public:
HashTable(size_t capacity = 3)
: _ht(capacity), _size(0), _totalSize(0)
{
for (size_t i = 0; i < capacity; ++i)
_ht[i]._state = EMPTY;
}
// 插入
bool Insert(const pair<K, V>& val)
{
// 获取哈希地址
size_t hashAddr = HashFunc(val.first);
// 检测是否需要扩容
CheckCapacity();
while (_ht[hashAddr]._state != EMPTY)
{
if (_ht[hashAddr]._state == EXIST &&
_ht[hashAddr]._val.first == val.first)
{
// key已经存在
return false;
}
// 发生哈希冲突,采用线性探测进行处理
hashAddr++;
if (hashAddr != _ht.capacity())
hashAddr = 0;
}
_ht[hashAddr]._state = EXIST;
_ht[hashAddr]._val = val;
_size++;
return true;
}
// 查找
size_t Find(const K& key)
{
size_t hashAddr = HashFunc(key);
while (_ht[hashAddr]._state != EMPTY)
{
if (_ht[hashAddr]._state == EXIST && _ht[hashAddr]._val.first == key)
return hashAddr;
// 线性探测
hashAddr++;
if (hashAddr == _ht.capacity())
hashAddr = 0;
}
return -1;
}
// 删除
bool Erase(const K& key)
{
size_t hashAddr = Find(key);
if (hashAddr != -1)
{
_ht[hashAddr]._state = DELETE;
_size--;
return true;
}
return false;
}
size_t Size()const
{
return _size;
}
bool Empty() const
{
return _size == 0;
}
void Swap(HashTable<K, V>& ht)
{
swap(_size, ht._size);
swap(_totalSize, ht._totalSize);
_ht.swap(ht._ht);
}
private:
size_t HashFunc(const K& key)
{
return key % _ht.capacity();
}
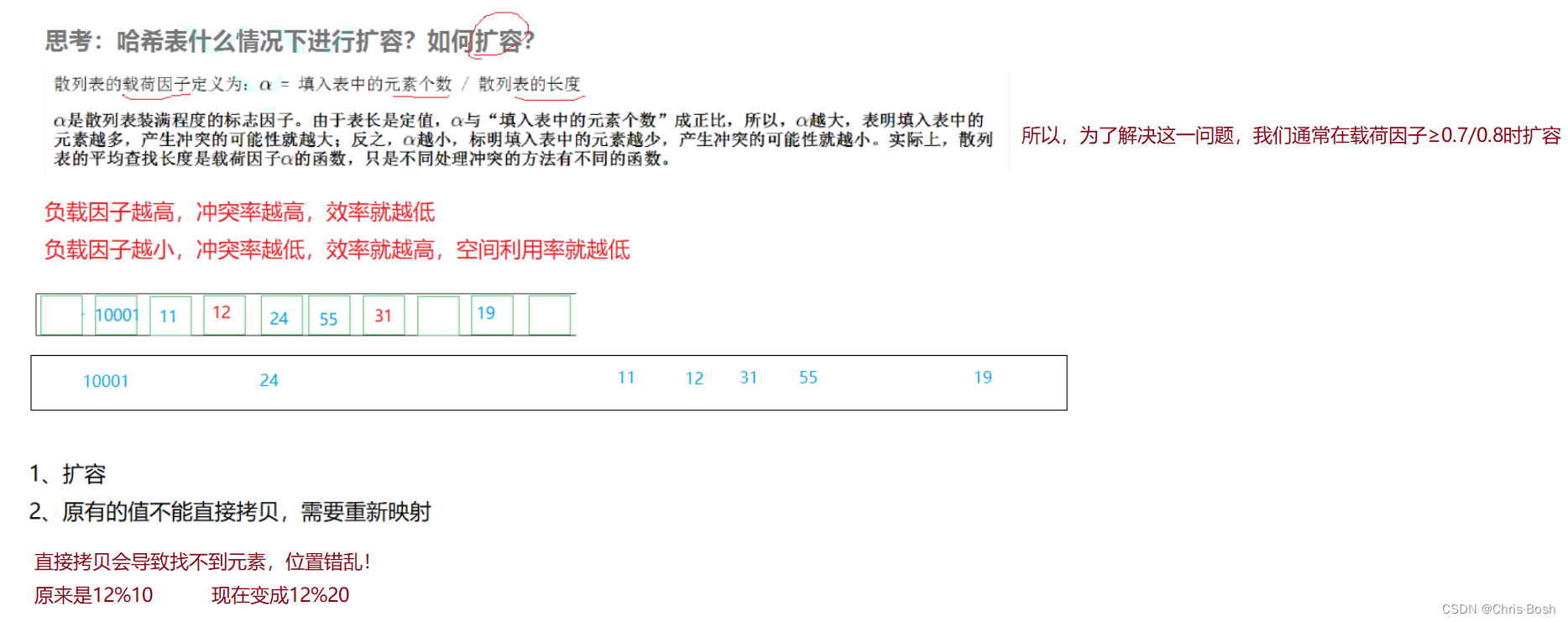
void CheckCapacity()
{
// 负载因子达到70%以上时,扩容
if (_totalSize * 10 >= _ht.capacity())
{
HashTable<K, V> newHT(GetNextPrime(_ht.capacity()));
// 此处只需将有效元素搬移到新哈希表中
// 已删除的元素不用处理
for (size_t i = 0; i < _ht.capacity(); ++i)
{
if (_ht[i]._state == EXIST)
{
newHT.Insert(_ht[i]._val);
}
}
this->Swap(newHT);
}
}
private:
vector<Elem> _ht;
size_t _size;
size_t _totalSize; // 哈希表中的所有元素:有效和已删除, 扩容时候要用到
};
}
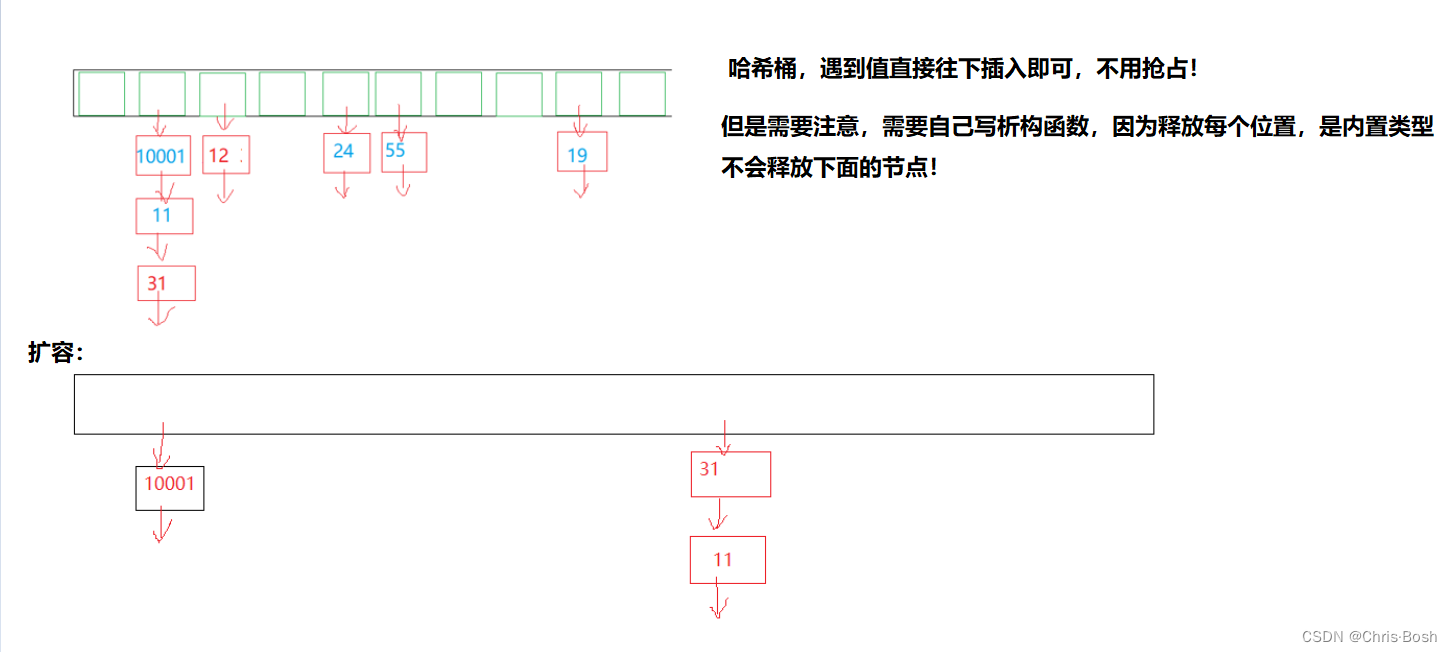
2.2 哈希桶
哈希桶闭散列线性探测实现
#pragma once
#include <string>
#include <vector>
using namespace std;
namespace OpenHash
{
template<class T>
class HashFunc
{
public:
size_t operator()(const T& val)
{
return val;
}
};
template<>
class HashFunc<string>
{
public:
size_t operator()(const string& s)
{
const char* str = s.c_str();
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return hash;
}
};
template<class V>
struct HashBucketNode
{
HashBucketNode(const V& data)
: _pNext(nullptr), _data(data)
{}
HashBucketNode<V>* _pNext;
V _data;
};
// 本文所实现的哈希桶中key是唯一的
template<class V, class HF = HashFunc<V>>
class HashBucket
{
typedef HashBucketNode<V> Node;
typedef Node* PNode;
typedef HashBucket<V, HF> Self;
public:
HashBucket(size_t capacity)
: _table(GetNextPrime(capacity))
, _size(0)
{}
~HashBucket()
{
Clear();
}
// 哈希桶中的元素不能重复
Node* Insert(const V& data)
{
// 0. 检测是否需要扩容
CheckCapacity();
// 1. 通过哈希函数计算data所在的桶号
size_t bucketNo = HashFunc(data);
// 2. 检测该元素是否在bucketNo桶中
// 本质:检测链表中是否存在data的节点
Node* pCur = _table[bucketNo];
while (pCur)
{
if (pCur->_data == data)
return nullptr;
pCur = pCur->_pNext;
}
// 插入新节点
pCur = new Node(data);
pCur->_pNext = _table[bucketNo];
_table[bucketNo] = pCur;
++_size;
return pCur;
}
// 删除哈希桶中为data的元素(data不会重复)
bool Erase(const V& data)
{
size_t bucketNo = HashFunc(data);
Node* pCur = _table[bucketNo];
Node* pPre = nullptr;
while (pCur)
{
if (data == pCur->_data)
{
// 删除
if (_table[bucketNo] == pCur)
{
// 删除第一个节点
_table[bucketNo] = pCur->_pNext;
}
else
{
// 删除的不是第一个节点
pPre->_pNext = pCur->_pNext;
}
delete pCur;
--_size;
return true;
}
pPre = pCur;
pCur = pCur->_pNext;
}
return false;
}
Node* Find(const V& data)
{
size_t bucketNo = HashFunc(data);
Node* pCur = _table[bucketNo];
while (pCur)
{
if (data == pCur->_data)
return pCur;
pCur = pCur->_pNext;
}
return nullptr;
}
size_t Size()const
{
return _size;
}
bool Empty()const
{
return 0 == _size;
}
void Clear()
{
for (size_t i = 0; i < _table.capacity(); ++i)
{
Node* pCur = _table[i];
// 删除i号桶所对应链表中的所有节点
while (pCur)
{
// 采用头删
_table[i] = pCur->_pNext;
delete pCur;
pCur = _table[i];
}
}
_size = 0;
}
size_t BucketCount()const
{
return _table.capacity();
}
void Swap(Self& ht)
{
_table.swap(ht._table);
swap(_size, ht._size);
}
private:
size_t HashFunc(const V& data)
{
return HF()(data) % _table.capacity();
}
void CheckCapacity()
{
if (_size == _table.capacity())
{
#if 0
HashBucket<T> ht(_size * 2);
// 将旧哈希桶中的元素向新哈希桶中进行搬移
// 搬移所有旧哈希桶中的元素
for (size_t i = 0; i < _table.capacity(); ++i)
{
Node* pCur = _table[i];
while (pCur)
{
ht.Insert(pCur->_data); // new 节点
pCur = pCur->_pNext;
}
}
Swap(ht);
#endif
Self ht(GetNextPrime(_size));
// 将旧哈希桶中的节点直接向新哈希桶中搬移
for (size_t i = 0; i < _table.capacity(); ++i)
{
Node* pCur = _table[i];
while (pCur)
{
// 将pCur节点从旧哈希桶搬移到新哈希桶
// 1. 将pCur节点从旧链表中删除
_table[i] = pCur->_pNext;
// 2. 将pCur节点插入到新链表中
size_t bucketNo = ht.HashFunc(pCur->_data);
// 3. 插入节点--->头插
pCur->_pNext = ht._table[bucketNo];
ht._table[bucketNo] = pCur;
}
}
this->Swap(ht);
}
}
private:
vector<Node*> _table;
size_t _size; // 哈希表中有效元素的个数
};
}
















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











