







目录
一、什么是窗口函数?
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。 窗口函数的基本语法如下: <窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>) 使用窗口函数时,需要定义一个窗口(OVER 子句),它描述了如何为每一行定义相关的行集。窗口 定义通常包括以下部分: PARTITION BY:按给定的列或表达式对结果集进行分区。每个分区将被视为一个独立的窗口,窗口函数会在每个分区上分别计算。 ORDER BY:定义窗口内行的排序顺序。 ROWS/RANGE:定义窗口的大小和形状。ROWS 基于行数,RANGE 基于值范围。 PARTITION BY:在窗口函数中的作用类似于分组。它用于将结果集划分为多个分区,以便在每个分区内单独进行窗口函数的计算。通过使用 PARTITION BY 子句,您可以在每个分区内独立地应用窗口函数,而不是在整个结果集中应用(整个结果集上弄得话就是order by了,而order by没有分组的功能)。 那么语法中的<窗口函数>都有哪些呢? <窗口函数>的位置,可以放以下两种函数: 1) 专用窗口函数:rank, dense_rank, row_number等专用窗口函数。 2) 因为partition by有类似分组功能,所以也可以使用一些聚合函数:sum(),max(),min等 因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。 以下是一些常用的窗口函数: ROW_NUMBER():为结果集中的每一行分配一个唯一的整数序号。 RANK():为结果集中的每一行分配一个唯一的整数序号,但在具有相同值的行中使用相同的序号。在下一个序号时,会跳过重复的序号。 DENSE_RANK():与 RANK() 类似,但不会跳过重复的序号。 NTILE(N):将结果集分成 N 个组,并为每一行分配一个组号。 CUME_DIST():计算当前行在结果集中的累计分布。 PERCENT_RANK():计算当前行在结果集中的百分比排名。 LEAD():获取当前行后面的第 N 行的值。 LAG():获取当前行前面的第 N 行的值。 FIRST_VALUE():获取窗口中的第一行的值。 LAST_VALUE():获取窗口中的最后一行的值。 NTH_VALUE():获取窗口中的第 N 行的值。
二、窗口函数有什么用?
在日常工作中,经常会遇到需要在每组内排名,但是日常的如果没有窗口函数,就只知道order by,这个时候,比如遇到下面的业务需求: 排名问题——每个部门按业绩来排名 topN问题:找出每个部门排名前N的员工进行奖励 如果此时只用到order by的话,假如薪资、业绩相同,但是排名不一样,那说的过去吗?面对这类需求,就需要使用sql的高级功能窗口函数(在以前的MySQL版本中是没有窗口函数的,直到MySQL8.0才引入了窗口函数)。
三、实践动手去感受!
创建表和插入数据:
-- 创建 employees 表
CREATE TABLE employees (
employee_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
salary DECIMAL(10, 2) NOT NULL,
department_id INT NOT NULL
);
-- 插入示例数据
INSERT INTO employees (name, salary, department_id) VALUES
('炎龙掌', 5000.00, 1),
('黑白无常', 5500.00, 1),
('大舅子',5000,1),
('温涛', 6000.00, 2),
('将臣', 6500.00, 2),
('女帝', 7000.00, 3),
('张子凡', 18000.00, 3),
('姬如雪', 5500.00, 3),
('李淳风',18000,3),
('大帅', 6000.00, 4),
('李星云', 5800.00, 4);
select * from employees;数据展示:

需求:统计各部门得薪资排名,薪资相同得排名一致,且不占序号!
select department_id,
name,
salary,
rank() over (partition by department_id order by salary desc ) as '部门薪资'
from employees;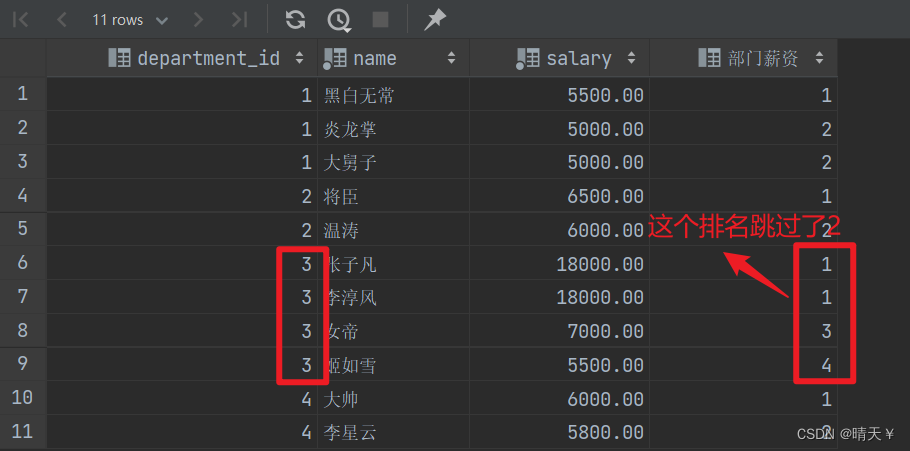
但是,我们需要的是,排名不会跳的!所以这里需要使用到另外的一个窗口函数dense_rank() 函数
-- 需求:统计各部门的薪资排名,薪资相同的排名一致,且不占序号!
select department_id,
name,
salary,
dense_rank() over (partition by department_id order by salary desc ) as '部门薪资'
from employees;
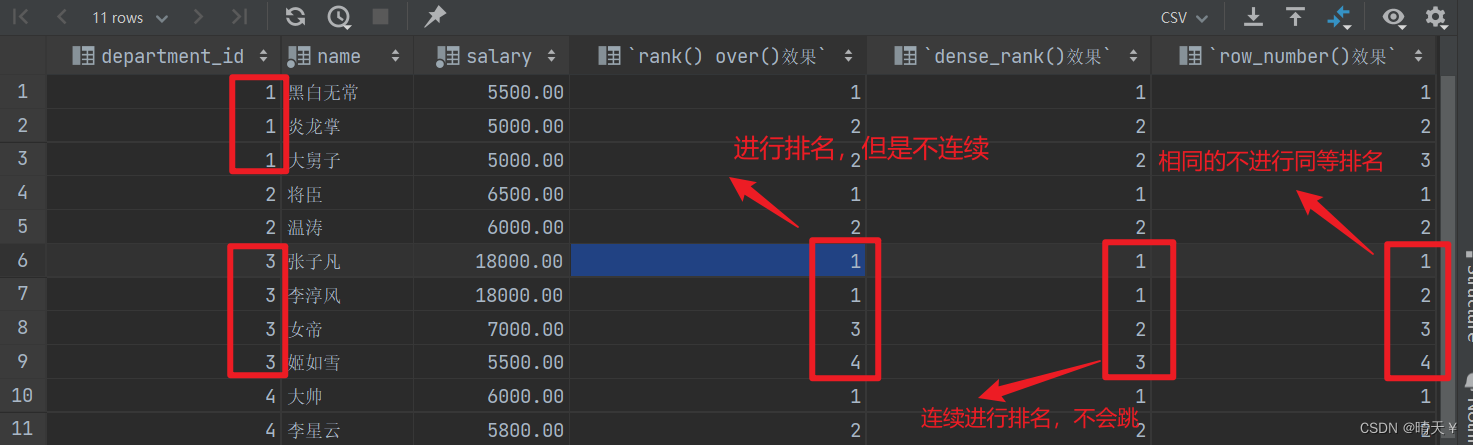
下面把三种常见的窗口函数rank, dense_rank, row_number有什么区别呢?
聚合函数也可以作为我们的窗口函数:应用场景——统计方面,比如统计某个年纪所有班的平均成绩,从而来判断班级的平均水平,统计公司各部门的平均薪资水平
-- 窗口函数也可以是聚合函数,例如sum,avg,max,min等
-- 聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
select department_id,
name,
salary as '应发放工资',
-- 统计部门的总发放薪资
sum(salary) over(partition by department_id ) as '部门总发放薪资',
avg(salary) over(partition by department_id) as '部门平均薪资'
from
employees;
桀桀桀,完结!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









