







实验三:循环语句
1、某公司2021年培养学员8万人,每年增长25%,请问按此增长速度,到哪一年培训学员人数将达到20万人?
year=2021
num=8
while num<= 20:
num=num*(1+0.25)
year+=1
print("到%d年达到20万"%year)
结果:
到2026年达到20万2.请用户输入数字,直到输入 0 退出,最后求和
sum = 0 #定义和
b = 1 #定义输入的值
while b!=0:#循环条件,输入的值不为0
b = float(input('请输入数字:'))#键盘输入值
sum = sum + b#求和
print('输入的数字之和:%f' %sum)
结果:
请输入数字:5
请输入数字:4
请输入数字:3
请输入数字:0
输入的数字之和:12.0000003.求 100-200 以内同时能被 7,8 整除的数
for i in range (1,7)#代表1到10,不包含7
range:左开右闭
“==”相当与“等于”
for i in range(100,201):
if i % 7 == 0 and i % 8 == 0:
print(i)结果:
112
1684.输入班级学生语文成绩,求总成绩和平均成绩。班级人数从键盘输入
range(start, stop, step)
| 参数名称 | 说明 | 备注 |
| start | 计数起始位置 | 整数参数,可省略。省略时默认从0开始计数 |
| stop | 计位置终点数 | 不可省略的整数参数。计数迭代的序列中不包含stop |
| step | 步长 | 可省略的整数参数,默认时步长为1 |
round(x[,n])---------返回浮点数x的四舍五入的值,参数n指定保留的小数位数
num = int(input('请输入班级人数:'))#定义班级人数
avge = 0#定义平均值
count = 0#定义总分数
for i in range(num):
i = float(input('请输入学生语文成绩:'))#循环输入学生的成绩
count += i #计算总分数:count=count+i
avge = count / num #成绩平均值为总分数除以学生人数
print('班级语文总成绩为:', round(count,2))#对总数保留两位小数
print('班级平均语文成绩为:', round(avge,2))#对平均值保留两位小数结果:
请输入班级人数:3
请输入学生语文成绩:76
请输入学生语文成绩:87
请输入学生语文成绩:98
班级语文总成绩为: 261.0
班级平均语文成绩为: 87.0
5.循环输入 7 天温度,求平均温度
cuma = 0 #定义温度总和
avga = 0 #定义平均值
for i in range(1,8): #输入温度循环7次
i = float(input('请输入温度:'))#对输入的温度强制转换为浮点型
cuma += 1 #求输入的温度总和
avga = cuma/7#求温度的平均值
print('这七天的平均温度为',round(avga,2))结果
请输入温度:34
请输入温度:23
请输入温度:21
请输入温度:32
请输入温度:43
请输入温度:23
请输入温度:23
这七天的平均温度为 1.0实验4:格式化字符
1.在控制台依次提示用户输入:**姓名**、**公司**、**职位**、**电话**、**邮箱***按照以下格式输出∶
***************************************************************
公司名称
姓名(职位)
电话∶电话
邮箱︰邮箱
注意类型!!!
#实验四 1
g=str(input('请输入公司名称:'))
x=str(input('请输入名字:'))
z=str(input('请输入职位:'))
d=int(input('请输入电话:'))
y=int(input('请输入邮箱:'))
print('公司名称:',g)
print('姓名:',x)
print('职位:',z)
print('电话:',d)
print('邮箱:',y)结果
请输入公司名称:有前途
请输入名字:有前途
请输入职位:总经理
请输入电话:110
请输入邮箱:2222
公司名称: 有前途
姓名: 有前途
职位: 总经理
电话: 110
邮箱: 2222
2.定义一个列表,在列表中添加新的元素
a=[1,2,3]
a.append(4)
print(a)结果
[1, 2, 3, 4]3.定义两个列表,将两个列表合并。
a=[1,2,3]
c=[4,5,6]
d=a+c
print(d)
结果
[1, 2, 3, 4, 5, 6]4.将已有列表倒序排列
a=[1,2,3]
b=[4,5,6]
c=[1,2,3,4,5,6]
a.reverse()
b.reverse()
c.reverse()
print(a)
print(b)
print(c)
结果
[3, 2, 1]
[6, 5, 4]
[6, 5, 4, 3, 2, 1]列表的操作
1.列表:元素赋值
x=[1,2,3,4,5,6]
x[1]=1(下标是“1”,类似数组:从0开始)
print(x)结果:
[1, 1, 3, 4, 5, 6]
2.删除元素
names=['张','三','李','四']
del names[3]
print(names)结果:
['张', '三', '李']
3.分片赋值
(1)分片赋值可以一次为多个元素赋值,可改变原来列表的长
y=[1,2,3,4,5]
y[4:]=[6,7,8,9]
print(y)结果:
[1, 2, 3, 4, 6, 7, 8, 9]
(2)分片赋值可以在中间插入,相当于“替换”了空的分片
y[3:3]=['a','b','c']
print(y)结果:(接上面的代码)
[1, 2, 3, 'a', 'b', 'c', 4, 6, 7, 8, 9]
(3)分片赋值也可以用来删除
y[4:6]=[]
print(y)
结果:(左闭右开)[1, 2, 3, 'a', 4, 6, 7, 8, 9]
列表方法
1.append 在列表末尾追加新的对象
lst=[1,2,3] lst.append(4) print(lst) 结果:[1, 2, 3, 4]
2.count 用于统计某个元素再列表中出现的次数a=['to','be','to'] b=['to','be','to'].count('to') print(b)结果:
2
3.extend 在列表的末尾一次性追加另一个序列中的多个值c=[1,2,3,4] d=[5,6,7,8] print(c+d) #c+d和这个方法的效果一样,但是用c+d没有改变c的长度和内容,用extend则改变了 #c[len(c):]=d #print(c) 用分片赋值的方法也可以完成这个操作,而且也改变了c的内容 c.extend(d) print(c)结果:
[1, 2, 3, 4, 5, 6, 7, 8]
[1, 2, 3, 4, 5, 6, 7, 8]
4.index用于列表中找出某个元素的位置1、f=['who','are','you'] print(f.index('who')) print()2、
f=['who','are','you'] print(f.index('are')) print()结果:
1、0---数组
2、1
5.insert 用于将对象插入到列表中numbers=[1,2,3,4,5] numbers.insert(3,'four') print(numbers) print()结果:
[1, 2, 3, 'four', 4, 5]
6.pop 移除列表中的某的元素(默认最后一个),并返回其值--位置n=[1,2,3,4,5,6,7] print(n) n.pop() print(n) n.pop(3) print(n) print()结果:
[1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 5, 6]
7.remove用于移除列表中的某个值的第一个匹配项p=['to','be','be','a','good','man'] print(p) p.remove('be') print(p) print()结果:
['to', 'be', 'be', 'a', 'good', 'man']
['to', 'be', 'a', 'good', 'man']
8.reverse 将列表中的元素反向存放(不返回)q=[1,2,3,4,5,6] print(q) q.reverse() print(q)结果:
[1, 2, 3, 4, 5, 6]
[6, 5, 4, 3, 2, 1]
9.sort用于在原位置对列表进行排序n=[1,4,3,5,7,8,0,3,5,4,6] print(n) n.sort() print(n)结果:
[1, 4, 3, 5, 7, 8, 0, 3, 5, 4, 6]
[0, 1, 3, 3, 4, 4, 5, 5, 6, 7, 8]
5.定义一个包含 10 个元素的元组,打印第 3-第 8 位元素。--左闭右开
a=(1,2,3,4,5,6,7,8,9,10)
print(a[2:8])结果
(3, 4, 5, 6, 7, 8)6.创建一个字典(包含 10 个键值对,其中值要包含“元组,列表,字典”),循 环输出所有元素。
dict = {"tuple1":(1,2,3),"tuple2":(4,5,6),"tuple3":(7,8,9),
'list1':[1,2,3],'list2':[4,5,6],'list3':[7,8,9],
'name':{'lihua'},'age':{12},'address':{'gx'},'height':{'56kg'}}
for key in dict:
print(key,dict[key])结果
tuple1 (1, 2, 3)
tuple2 (4, 5, 6)
tuple3 (7, 8, 9)
list1 [1, 2, 3]
list2 [4, 5, 6]
list3 [7, 8, 9]
name {'lihua'}
age {12}
address {'gx'}
height {'56kg'}
7.九九乘法
a = 1
while a <= 9:
b = 1
while b <= a:
print("%d * %d = %d" % (a,b,a*b), end=" ")
b = b + 1
print('')
a = a + 1结果
1 * 1 = 1
2 * 1 = 2 2 * 2 = 4
3 * 1 = 3 3 * 2 = 6 3 * 3 = 9
4 * 1 = 4 4 * 2 = 8 4 * 3 = 12 4 * 4 = 16
5 * 1 = 5 5 * 2 = 10 5 * 3 = 15 5 * 4 = 20 5 * 5 = 25
6 * 1 = 6 6 * 2 = 12 6 * 3 = 18 6 * 4 = 24 6 * 5 = 30 6 * 6 = 36
7 * 1 = 7 7 * 2 = 14 7 * 3 = 21 7 * 4 = 28 7 * 5 = 35 7 * 6 = 42 7 * 7 = 49
8 * 1 = 8 8 * 2 = 16 8 * 3 = 24 8 * 4 = 32 8 * 5 = 40 8 * 6 = 48 8 * 7 = 56 8 * 8 = 64
9 * 1 = 9 9 * 2 = 18 9 * 3 = 27 9 * 4 = 36 9 * 5 = 45 9 * 6 = 54 9 * 7 = 63 9 * 8 = 72 9 * 9 = 81 实验5:函数的使用
1.定义一个函数,辨别两个输入数值的大小,并输出结果

2.定义一个函数,输入商品ID,打印商品信息,包括:商品名称,价格,生产商。

3.掷骰子(提示:骰子最大值 6,输入’Q’退出)
import random
a=random.randint(1,6)
def p():
for i in range(1,7):
x=input("请投掷一下骰子,试试运气,退出请输入Q:")
if x=='Q':
print("投掷结束")
break
else:
print(f"掷得{a}点")
print(p())
结果

4.定义一个函数,求出指定列表中的最大值

5.定义一个函数,求学生最高分数

实验6:类的使用与异常练习
1.创建一个用户类,属性包含:姓名,性别,电话号码,地址;定义一个函数用于打印用户信息;定义另一个函数,用于向用户输出友好的问候语。
class User(object):
def __init__(self,name,gender,telephone,address):
self.name=name
self.gender=gender
self.telephone =telephone
self.address=address
def firend(self):
print("Hello, how are you?")
p=User("翠花","female sex",66666666666,"shanghai")
print(p.name)
print(p.gender)
print(p.telephone)
print(p.address)
p.firend()结果
翠花
female sex
66666666666
shanghai
Hello, how are you?2.定义一个学生类
![]() 有下面的类属性:姓名 年龄 成绩(语文,数学,英语)[每课成绩的类型为整数]
有下面的类属性:姓名 年龄 成绩(语文,数学,英语)[每课成绩的类型为整数]
![]() 类方法
类方法
1) 获取学生的姓名:get_name() 返回类型:str
- )获取学生的年龄:get_age() 返回类型:int
- )返回 3 门科目中最高的分数:get_course() 返回类型:int
class Student(object):
def __init__(self,name,age,course):
self.name=name
self.age=age
self.course=course
def get_name(self):
return str(self.name)
def get_age(self):
return int(self.age)
def get_course(self):
m=(self.course.values())
return max(m)
p=Student("吉吉国王",12,{"语文":90,"数学":98,"英语":99})
print(p.get_name())
print(p.get_age())
print(p.get_course())吉吉国王
12
993. 定义一个字典类:dictclass 完成下面的功能:
dict = dictclass({你需要操作的字典对象})
1) 删除某个 key
del_dict(key)
2 )判断某个键是否在字典里,如果存在则返回键对应的值,不存在则返回"not found"
get_dict(key)
3) 返回键组成的列表:返回类型;(list)
get_key()
class Dictclass(object):
def __init__(self,dictclass):
self.dictclass=dictclass
def del_dict(self,key):
if key in self.dictclass.keys():
del self.dictclass[key]
return self.dictclass
return "不存在这个键,无需操作"
def get_dict(self,key):
if key in self.dictclass.keys():
return self.dictclass[key]
return 'not found'
def get_key(self):
return list(self.dictclass.keys())
dict=Dictclass({"语文":90,"数学":98,"英语":99})
print(dict.del_dict("语文"))
print(dict.get_dict("数学"))
print(dict.get_key())
结果
{'数学': 98, '英语': 99}
98
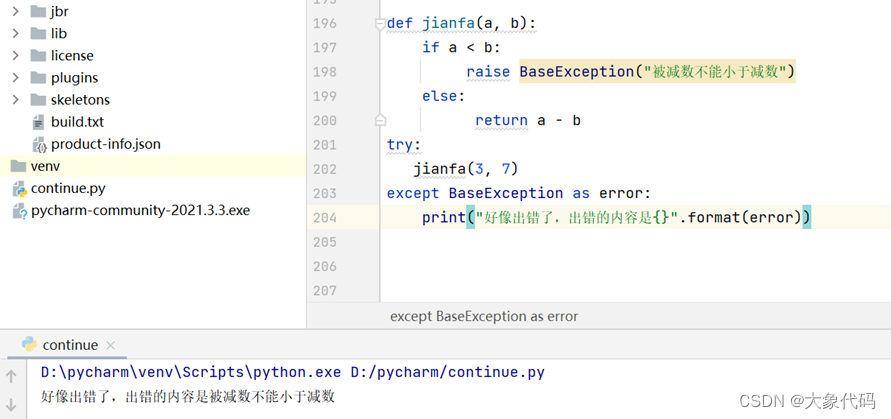
['数学', '英语']4.编写一个计算减法的方法,当第一个数小于第二个数时,抛出“被减数不能小于减数" 的异常
pandas--练习题
import pandas as pd
import numpy as np
frame = pd.DataFrame(np.random.randn(3,3),columns=list('bcd'),index=['Ohio','Texas','Colorado'])
f = lambda x:x.max() - x.min()
frame.apply(f)b 2.065997
c 2.889240
d 1.587271
dtype: float64
df=pd.DataFrame([[1,2],[3,4]],index=['a','b'],columns=['s1','s2'])
df| s1 | s2 | |
| a | 1 | 2 |
| b | 3 | 4 |
#series的创建方法
import pandas as pd
a = pd.Series([1,2,3,4,5])
b = pd.Series(range(4))
c = pd.Series(range(4),index=['a','b','c','d'])
d = {'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}#使用下标和切片对series进行访问
a = pd.Series([11,22,33,44,55])
a[1:3]1 22
2 33
dtype: int64
a = pd.Series([1,2,3,4,5])
a0 1
1 2
2 3
3 4
4 5
dtype: int64
#求平均值mean函数的调用方法
print(a.mean())3.0
#series的数组间的运算
a=pd.Series([1,2,3,4])
b=pd.Series([1,2,1,2])
print(a+b)
print(a*2)
print(a>=3)
print(a[a>=3])0 2
1 4
2 4
3 6
dtype: int64
0 2
1 4
2 6
3 8
dtype: int64
0 False
1 False
2 True
3 True
dtype: bool
2 3
3 4
dtype: int64
#series数据结构的索引创建方式,索引在series中称为index
a=pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
aa 1
b 2
c 3
d 4
e 5
dtype: int64
#series数据结构的重新,重新索引表示创建一个适应新索引的新对象,对series而言,
#在索引重排过程中,如果某个索引值当前不存在,会在索引值对应的值中加入缺失值
s1=pd.Series(['a','b','c','d','e'],index=[2,1,3,5,4])
s2=s1.reindex([1,2,3,4,5,6],fill_value=0)#添加一个值
s3=s2.reindex(range(10),method='bfill')#reindex重整索引;重建索引;
print(s1)
print(s2)
print(s3)2 a
1 b
3 c
5 d
4 e
dtype: object
1 b
2 a
3 c
4 e
5 d
6 0
dtype: object
0 b
1 b
2 a
3 c
4 e
5 d
6 0
7 NaN
8 NaN
9 NaN
dtype: object
#使用字典创建DataFrame
import pandas as pd
d={'coll':[1,2],'col2':[3,4]}
a=pd.DataFrame(data=d)
a| coll | col2 | |
| 0 | 1 | 3 |
| 1 | 2 | 4 |
#使用series创建DATa Frame
c={'one':pd.Series([1.,2.,3.],index=['a','b','c']),'two':pd.Series([1.,2.,3.,4.],index=['a','b','c','d'])}
e=pd.DataFrame(d)
d=pd.DataFrame(c,index=['d','b','a'])
print(c)
print(e)
print(d){'one': a 1.0
b 2.0
c 3.0
dtype: float64, 'two': a 1.0
b 2.0
c 3.0
d 4.0
dtype: float64}
coll col2
0 1 3
1 2 4
one two
d NaN 4.0
b 2.0 2.0
a 1.0 1.0















 2966
2966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









