







〇.写在前面
若读者朋友们发现问题,请不吝斧正。
一.插入排序
(1)直接插入排序
对于一个数组长度为n且有序的数组,我们要插入第n+1个元素,只需要从后往前迭代一次,就肯定能找到对应的位置,完成排序。直接插入排序的实现就基于以上思想。
代码实现如下:
void swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
//直接插入排序
void InsertSort(int* a, int n)
{
for (int i = 1; i < n; ++i)
{
for (int j = i; j > 0; --j)
{
if (a[j] < a[j - 1])
{
swap(&a[j], &a[j - 1]);
}
else
{
break;
}
}
}
}
(2)希尔排序
很容易发现,直接插入排序在数组接近有序时复杂度很低。正是基于这样的思想,我们有了希尔排序。
希尔排序是直接插入排序的优化版本,它的思想是:
选取一个整数d作为距离,把数组内下标相隔距离为gap的数归为一组,之后对每一个组进行直接插入排序。之后减小gap的值,重复此过程,直到gap减小为1。
图解如下:
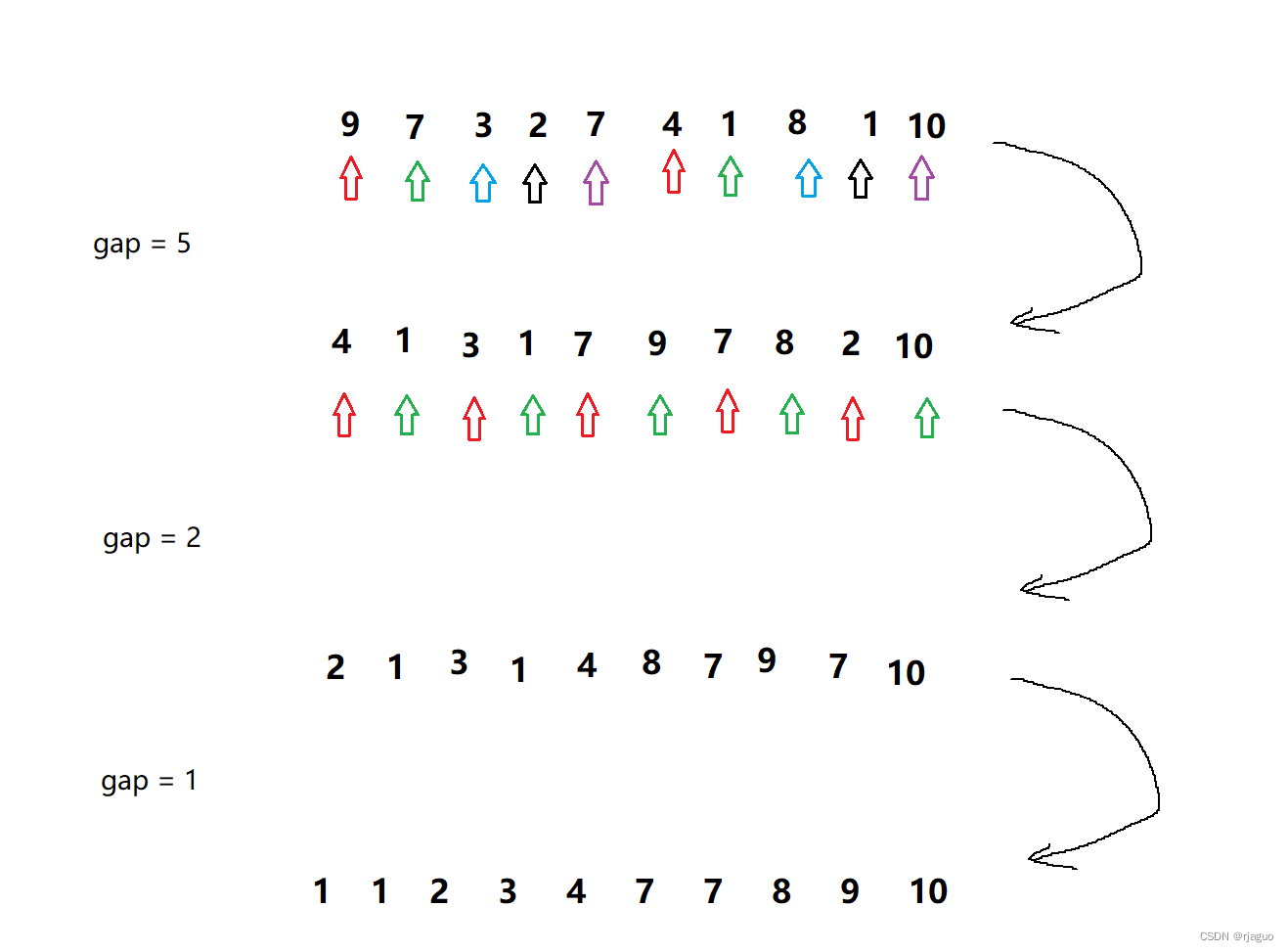
代码实现如下:
//希尔排序
void _ShellSort(int* a, int n, int gap)
{
for (int i = gap; i < n; ++i)
{
int key = a[i];
int j = i - gap;
for (; j >= 0; j -= gap)
{
if (a[j] > key)
{
a[j + gap] = a[j];
}
else
{
a[j + gap] = a[j];
a[j] = key;
break;
}
}
if (j < 0)
{
a[j + gap] = key;
}
}
}
void ShellSort(int* a, int n)
{
int gap = n / 2;
while (gap > 0)
{
_ShellSort(a, n, gap);
gap /= 2;
}
}
二.交换排序
(1)冒泡排序
冒泡排序,顾名思义,就是像冒泡泡一样,把最大的那一个数冒泡到数组最后。以此方式选出最大的,次大的…直到最小的,完成排序。
代码实现如下:
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < n - i - 1; ++j)
{
if (a[j] > a[j + 1])
{
swap(&a[j], &a[j + 1]);
}
}
}
}
(2)快速排序
快速排序是所有排序中综合效率最高的排序方法,其基本思想是:先取数组中一个数作为基准值,通过遍历一次数组,使该数可以位于它最终的位置,且它左边的数都比它小,它右边的数都比它大。再对这个数左边和右边的数组重复此操作,直到排序完成。
或许文字不是那么易懂,有图解如下:(我们实现的是前后指针法):
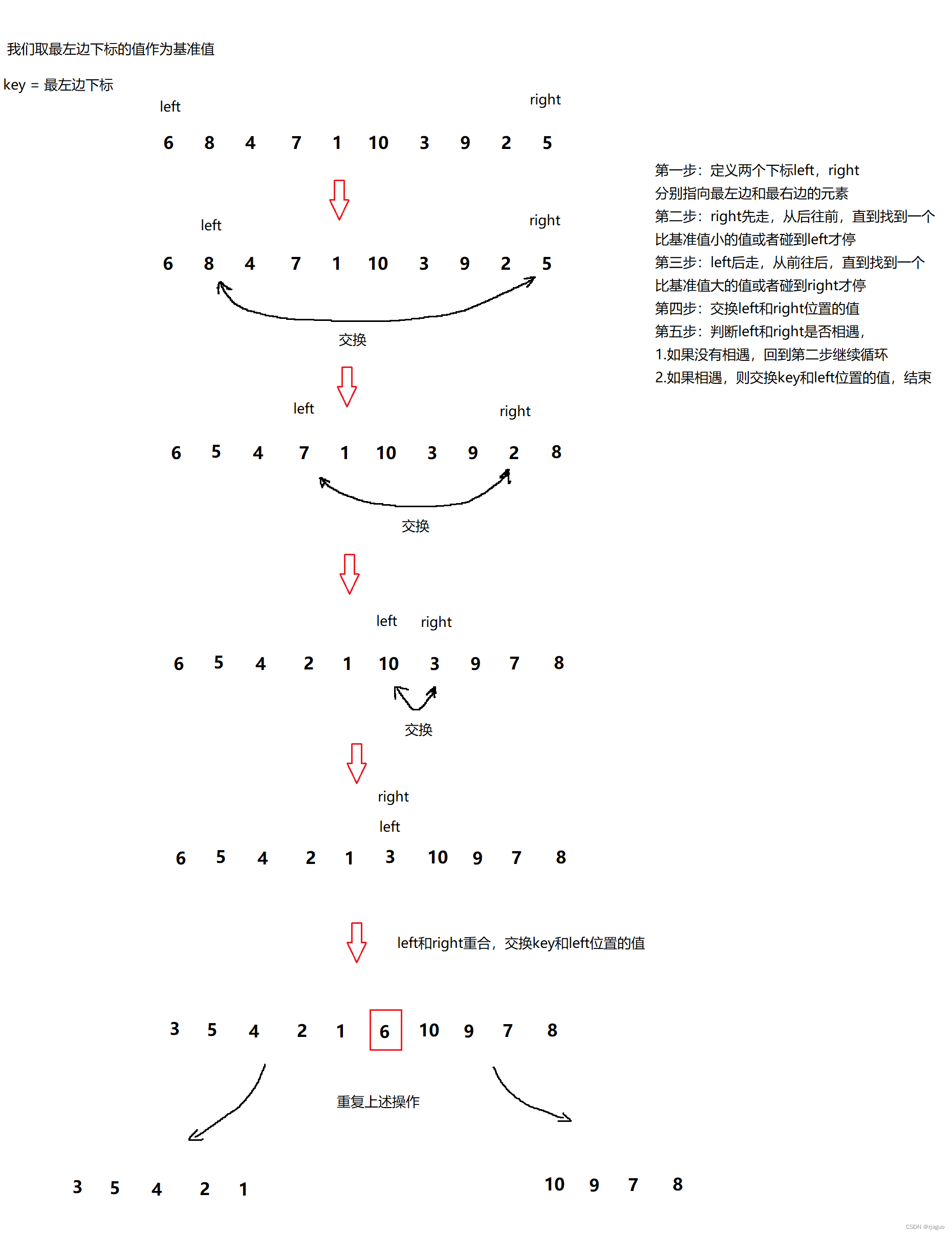
前后指针法:
第一步:定义两个下标left,right
分别指向最左边和最右边的元素
第二步:right先走,从后往前,直到找到一个比基准值小的值或者碰到left才停
第三步:left后走,从前往后,直到找到一个比基准值大的值或者碰到right才停
第四步:交换left和right位置的值
第五步:判断left和right是否相遇,
1.如果没有相遇,回到第二步继续循环
2.如果相遇,则交换key和left位置的值,递归到子数组
注意:实现时,如果以最左边的数作为基准值,一定要right先走。由此来保证:在left和right相遇位置的值一定会小于基准值。
虽然快排综合效率很高,但是面对接近有序数组时效率很低,所以我们对快速排序进行三数取中优化:
我们不再取最左边的数作为基准值,而是取三个数作为候选,分别是:最左边的数,最中间的数,最右边的数;从这三个数中取出大小位于中间的数。然后把这个数和最左边的数交换。
图解如下: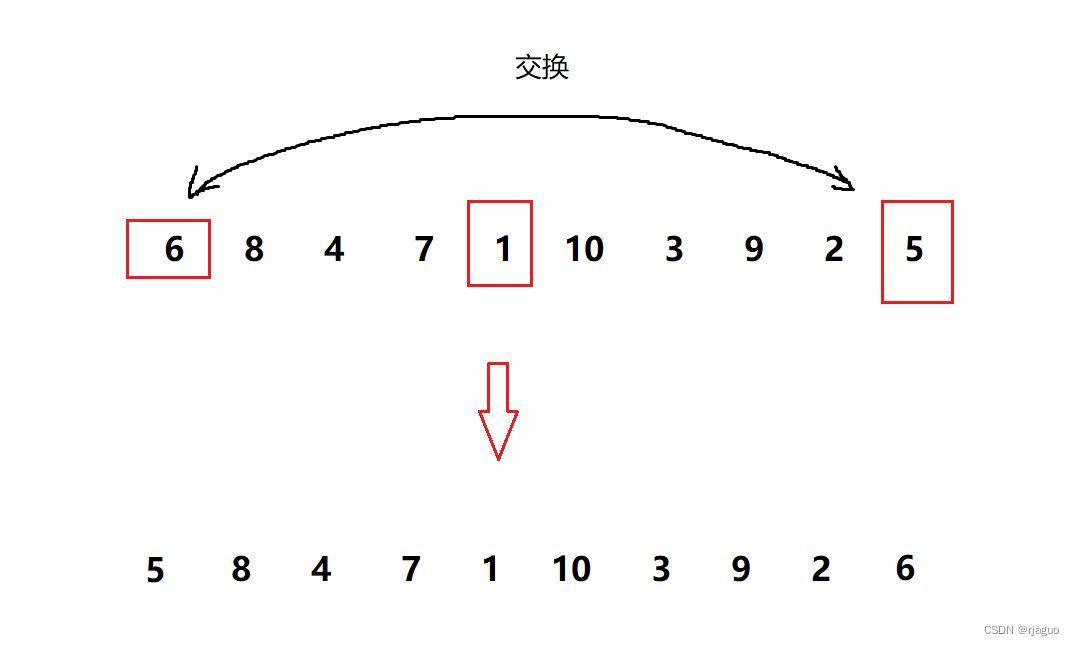
代码实现如下:
递归版本:
int GetMid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] >= a[mid] && a[left] >= a[right])
{
if (a[mid] >= a[right])
return mid;
else
return right;
}
else if(a[mid] >= a[left] && a[mid] >= a[right])
{
if (a[left] >= a[right])
return left;
else
return right;
}
else
{
if (a[left] >= a[mid])
return left;
else
return mid;
}
}
void _QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int mid = GetMid(a, left, right);
swap(&a[left], &a[mid]);
int key = a[left];
int _left = left;
int _right = right;
while (_left < _right)
{
//相同也跳过
while (_left < _right && a[_right] >= key)
_right--;
while (_left < _right && a[_left] <= key)
_left++;
swap(&a[_left], &a[_right]);
}
swap(&a[left], &a[_left]);
_QuickSort(a, left, _left - 1);
_QuickSort(a, _right + 1, right);
}
//快速排序
void QuickSort(int* a, int n)
{
_QuickSort(a, 0, n - 1);
}
非递归版本(c++实现):
void swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
int GetMid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] >= a[mid] && a[left] >= a[right])
{
if (a[mid] >= a[right])
return mid;
else
return right;
}
else if (a[mid] >= a[left] && a[mid] >= a[right])
{
if (a[left] >= a[right])
return left;
else
return right;
}
else
{
if (a[left] >= a[mid])
return left;
else
return mid;
}
}
//快速排序的非递归实现(队列)
void FQuickSort(int* a, int n)
{
queue<int> q;
q.push(0);
q.push(n - 1);
while (!q.empty())
{
int left = q.front();
q.pop();
int right = q.front();
q.pop();
int mid = GetMid(a, left, right);
swap(&a[left], &a[mid]);
int key = a[left];
int _left = left;
int _right = right;
while (_left < _right)
{
while (_left < _right && a[_right] >= key)
_right--;
while (_left < _right && a[_left] <= key)
_left++;
swap(&a[_left], &a[_right]);
}
swap(&a[left], &a[_left]);
if (left < _left - 1)
{
q.push(left);
q.push(_left - 1);
}
if (_right + 1 < right)
{
q.push(_right + 1);
q.push(right);
}
}
}
三.选择排序
(1)直接选择排序
直接选择排序,顾名思义,从数组中选出最大的元素放在最后面,然后再依次把前n-1,n-2…个数重复上述操作,直到只剩一个数,排序结束。
代码实现如下:
//选择排序
void swap(int* pa, int* pb)
{
int tmp = *pa;
*pa = *pb;
*pb = tmp;
}
void SelectSort(int* a, int n)
{
for (int i = 0; i < n; ++i)
{
int max_index = 0;
int max = a[max_index];
for (int j = 1; j < n - i; ++j)
{
if (a[j] > max)
{
max_index = j;
max = a[j];
}
}
swap(&a[max_index], &a[n - i - 1]);
}
}
(2)堆排序
要明白堆排序,首先我们需要知道堆是什么。
- 堆是一棵满二叉树,分为大根堆和小根堆;
- 大根堆:每一个非叶子节点的值都不小于它孩子节点的值
- 小根堆:每一个非叶子节点的值都不大于它孩子节点的值
图例如下(来自网络):
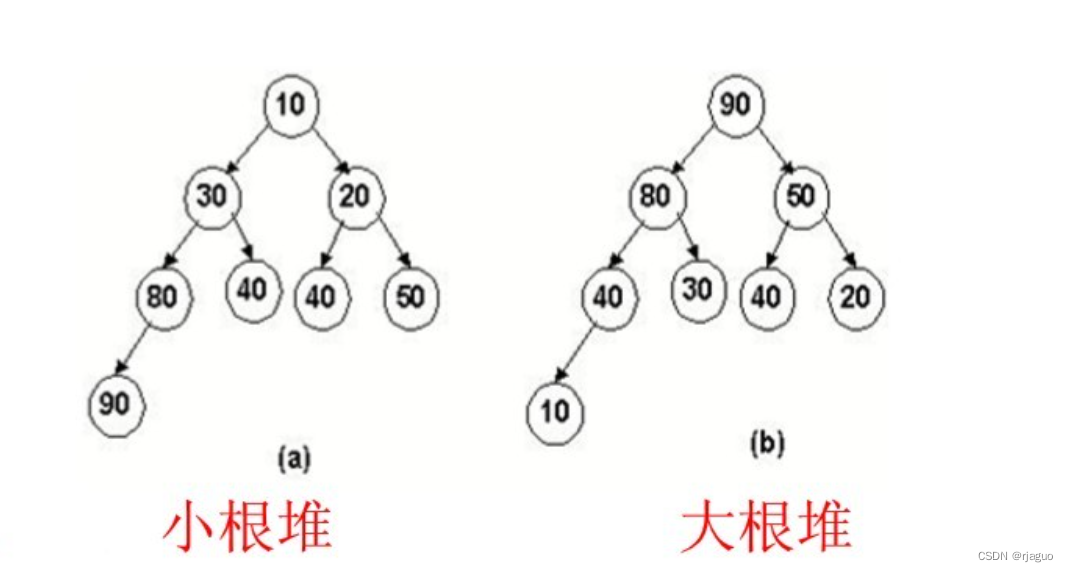
堆的删除:堆只能删除堆顶元素,且删除后需要重新调整,使它仍是一个堆。
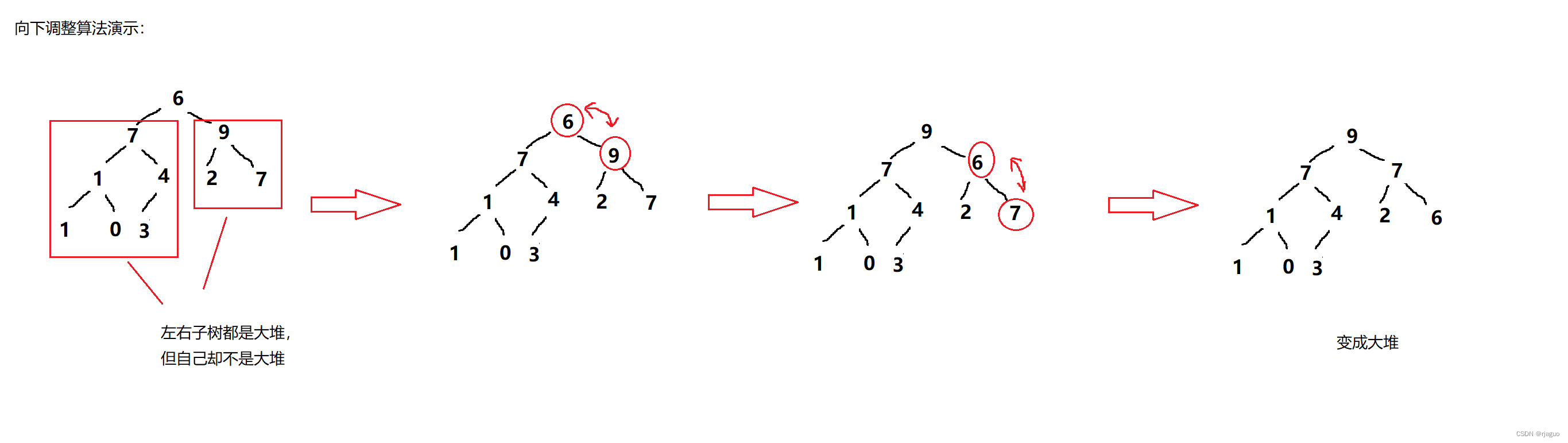
之后,我们引入向下调整算法(大堆):
- 当左右子树都是堆,但节点本身却不一定满足堆的条件时,就要向下调整
- 在自身节点,左孩子节点和右孩子节点中选出最大的个:
a. 如果最大的那个是自身节点,则函数到此结束
b. 如果最大的那个是左孩子节点,则交换自身和左孩子节点的值,递归到左孩子节点
c. 如果最大的那个是右孩子节点,则交换自身和右孩子节点的值,递归到右孩子节点
图解如下:
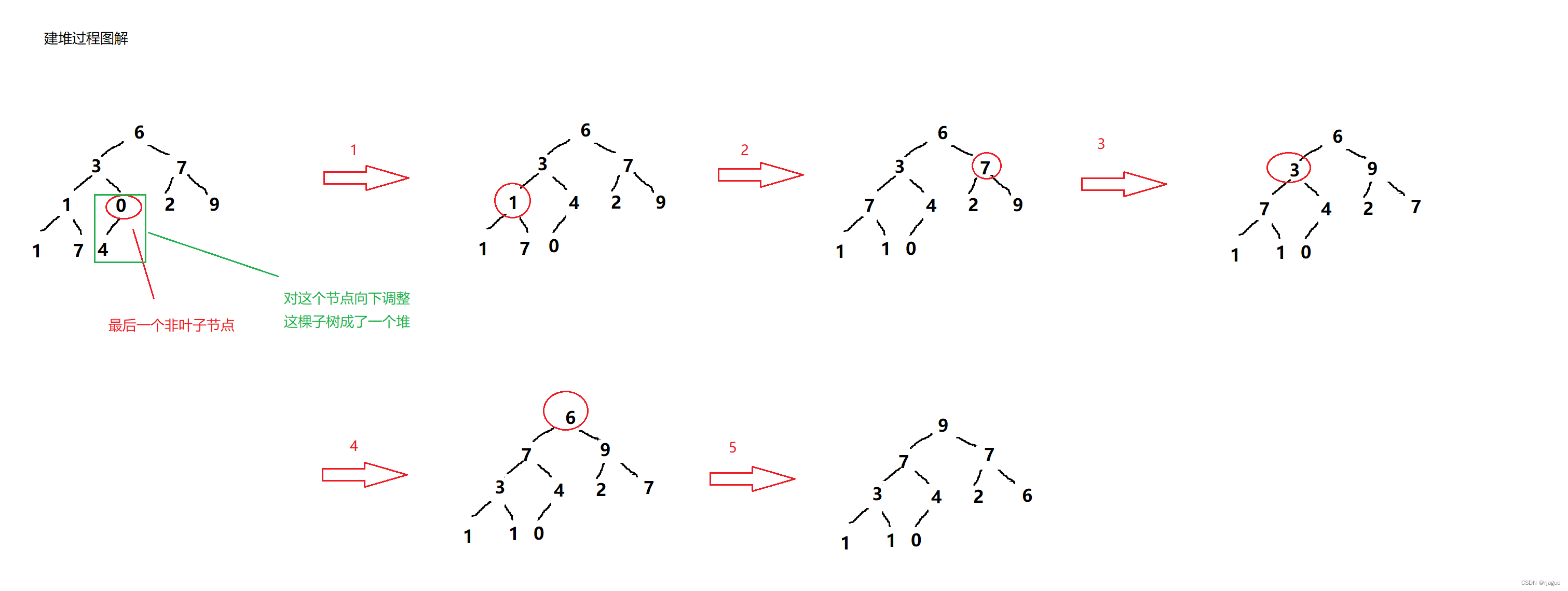
建堆:
从最后一个非叶子节点开始到根节点,逐个执行向下调整算法。
图解如下:
最后,我们就可以排序了
堆排序的基本原理(以大堆排升序为例)就是:
- 当传入一个长度为n的待排序的数组,我们先用这个数组构建一个大小为n的大堆
- 然后拿出最大值(也就是首元素),和最后一个元素交换,再通过向下调整重新构建一个大小为n-1的堆
- 此时我们已经把这n个元素中的最大值放到了数组的最后。再重复2的操作,直到只剩一个元素时,排序就完成了。
图解如下:

代码实现如下:
void AdjustDown(int* a, int n, int parent)
{
//左孩子节点索引:lchild = parent * 2 + 1;
//右孩子节点索引:rchild = lchild + 1;
int lchild = parent * 2 + 1;
int rchild = lchild + 1;
//没有孩子节点,结束递归
if (lchild >= n)
{
return;
}
else
{
//右孩子存在
if (rchild < n)
{
if (a[parent] >= a[lchild] && a[parent] >= a[rchild])
{
return;
}
//左孩子最大
else if (a[lchild] >= a[parent] && a[lchild] >= a[rchild])
{
swap(&a[lchild], &a[parent]);
AdjustDown(a, n, lchild);
}
//右孩子最大
else
{
swap(&a[rchild], &a[parent]);
AdjustDown(a, n, rchild);
}
}
//右孩子不存在
else
{
if (a[parent] >= a[lchild])
return;
else
swap(&a[lchild], &a[parent]);
}
}
}
void HeapSort(int* a, int n)
{
//建堆
//最后一个非叶子节点的坐标index = (n - 1 - 1) / 2;
int index = (n - 2) / 2;
for (int i = index; i >= 0; --i)
{
AdjustDown(a, n, i);
}
//排序
for (int i = n - 1; i > 0; --i)
{
swap(&a[0], &a[i]);
AdjustDown(a, i, 0);
}
}
(3)TopK问题
如果我们要从一个长度为N数组中找出最大或最小的前K个数,我们应该怎么做?排序,然后选出前K个数。这是一种方法,但我们还有更高效率的方法:
我们要求前K个最小的数:
- 建一个大小为K的大堆。
- 从第K+1个数开始,比较它和堆顶元素的大小,如果它比堆顶元素小,就把它和堆顶元素交换,然后向下调整;直到最后一个元素。
- 最后,这个大堆里的K个数就是我们要找的前K个最小的数。
为什么这种方法可以找到最小的K个数呢?
因为每一个不在这个大堆里的数都比这个大堆的堆顶元素要大,也就比整个堆的元素都要大。所以这个大堆里的元素就是最小的前K个数。
注:如果要找最大的前K个数,建小堆;找最小的前K个数,建大堆。
代码实现:
void TopK(int* a, int n, int k)
{
//建大堆 得最小K个
//建大小为k的堆
//最后一个非叶子节点的坐标index = (k - 1 - 1) / 2;
int index = (k - 2) / 2;
for (int i = index; i >= 0; --i)
{
AdjustDown(a, k, i);
}
for (int i = k + 1; i < n; ++i)
{
if (a[i] < a[0])
{
swap(a[i], a[0]);
AdjustDown(a, k, 0);
}
}
for (int i = 0; i < k; ++i)
{
cout << a[i] << " ";
}
}
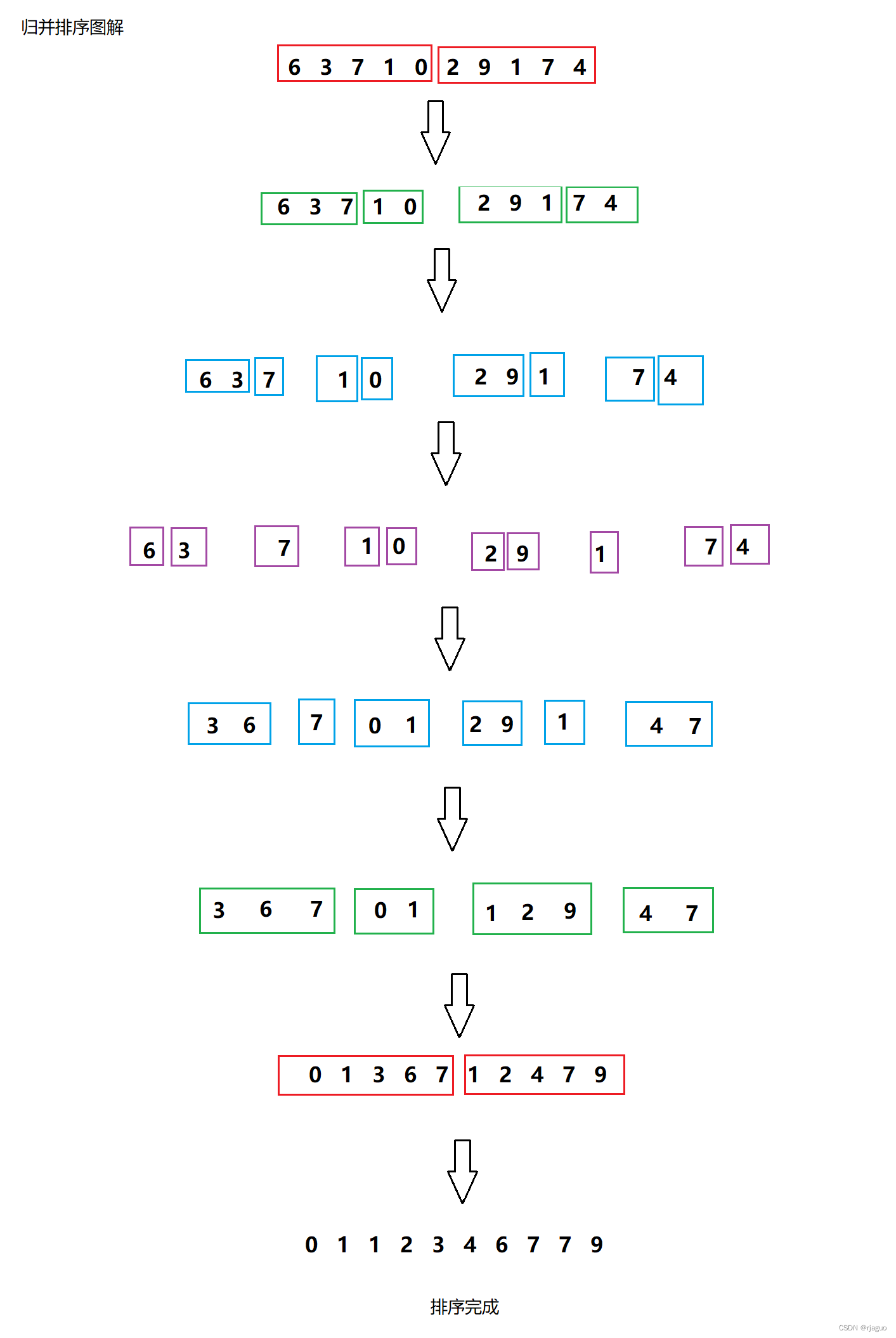
四.归并排序
我们先考虑这样一种情况:
对于两个有序的数组,我们想要把这两个数组合并成一个大的有序数组,我们可以很轻松地完成。
那么,对于无序的数组呢?
我们可以把它从中间二分为两个数组,把这两个数组排序完成,就可以完成对整个数组的排序。
我们发现,这个过程是一个递归的过程,数组可以被细分到只有一个元素,然后向上不断合并,就完成了排序。
这就是归并排序的原理。
图解如下:
代码实现如下:
递归实现:
//归并排序
void _MergeSort(int* a, int* tmp, int left, int right)
{
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, tmp, left, mid);
_MergeSort(a, tmp, mid + 1, right);
int index = left;
int index1 = left;
int index2 = mid + 1;
while (index1 <= mid && index2 <= right)
{
if (a[index1] < a[index2])
{
tmp[index] = a[index1];
index++;
index1++;
}
else
{
tmp[index] = a[index2];
index++;
index2++;
}
}
while (index1 <= mid)
{
tmp[index] = a[index1];
index++;
index1++;
}
while (index2 <= right)
{
tmp[index] = a[index2];
index++;
index2++;
}
memmove(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(n * sizeof(int));
_MergeSort(a, tmp, 0, n - 1);
}
非递归实现
//归并排序(非递归)
void FMergeSort(int* a, int n)
{
int* tmp = (int*)malloc(n * sizeof(int));
int gap = 2;
int step = (gap - 1) / 2;
while (step < n)
{
for (int i = 0; i < n; i += gap)
{
int left1 = i;
int right1 = left1 + step;
int left2 = right1 + 1;
int right2 = left2 + step;
if (right1 >= n)
{
continue;
}
else if (right2 >= n)
{
right2 = n - 1;
}
//归并
int index = left1;
int index1 = left1;
int index2 = left2;
while (index1 <= right1 && index2 <= right2)
{
if (a[index1] < a[index2])
{
tmp[index] = a[index1];
index++;
index1++;
}
else
{
tmp[index] = a[index2];
index++;
index2++;
}
}
while (index1 <= right1)
{
tmp[index] = a[index1];
index++;
index1++;
}
while (index2 <= right2)
{
tmp[index] = a[index2];
index++;
index2++;
}
memmove(a + left1, tmp + left1, sizeof(int) * (right2 - left1 + 1));
}
gap *= 2;
step = (gap - 1) / 2;
}
free(tmp);
}
五.稳定性
稳定性是指相同的数在排列完成后相对位置不变,举例如图:
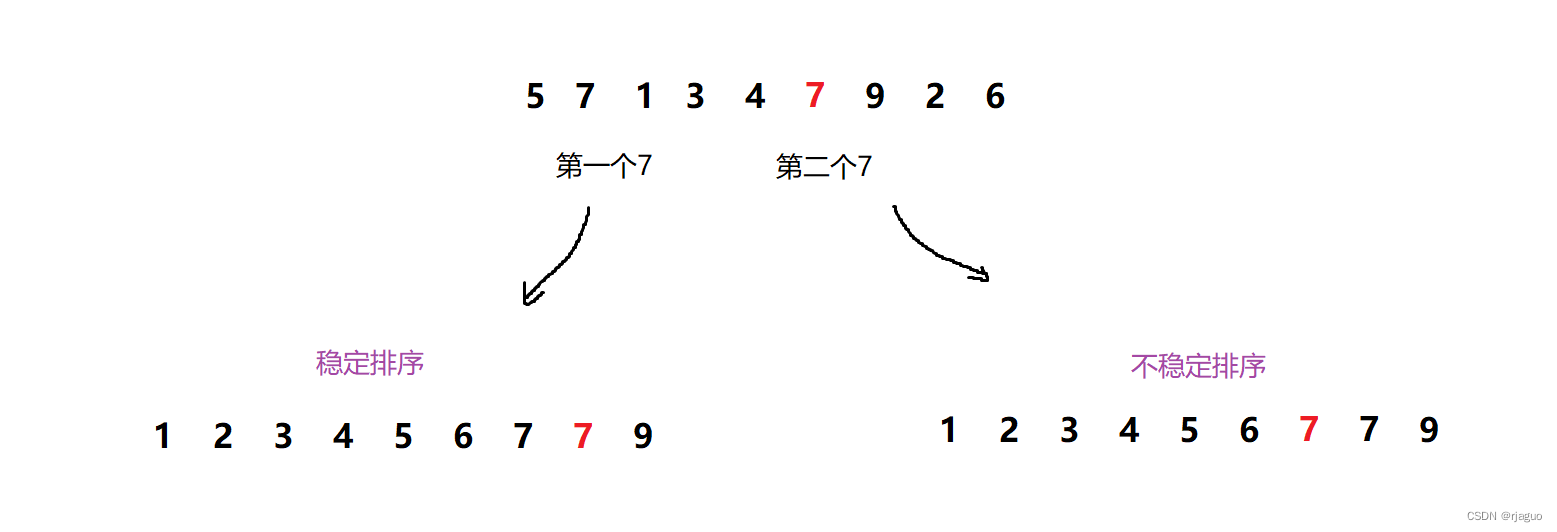
稳定的排序有:
直接插入排序,直接选择排序,冒泡排序,归并排序。















 3010
3010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









