







MySQL 核心技能:SQL 查询与数据库概述
一、数据库概述
1. 什么是数据库
数据库(Database,DB)是按照数据结构来组织、存储和管理数据的仓库。它是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。数据库通过数据库管理系统(DBMS)进行管理,使用户能够高效地存储、检索、更新和管理数据。
数据库中的数据通常以结构化的方式存储,例如表格形式,包含行和列,每列表示一个属性,每行表示一条记录。除了关系型数据库(如MySQL、Oracle、SQL Server等),还有非关系型数据库(如MongoDB、Redis、Cassandra等),它们以键值对、文档、列族或图结构等方式存储数据。
2.为什么要使用数据库
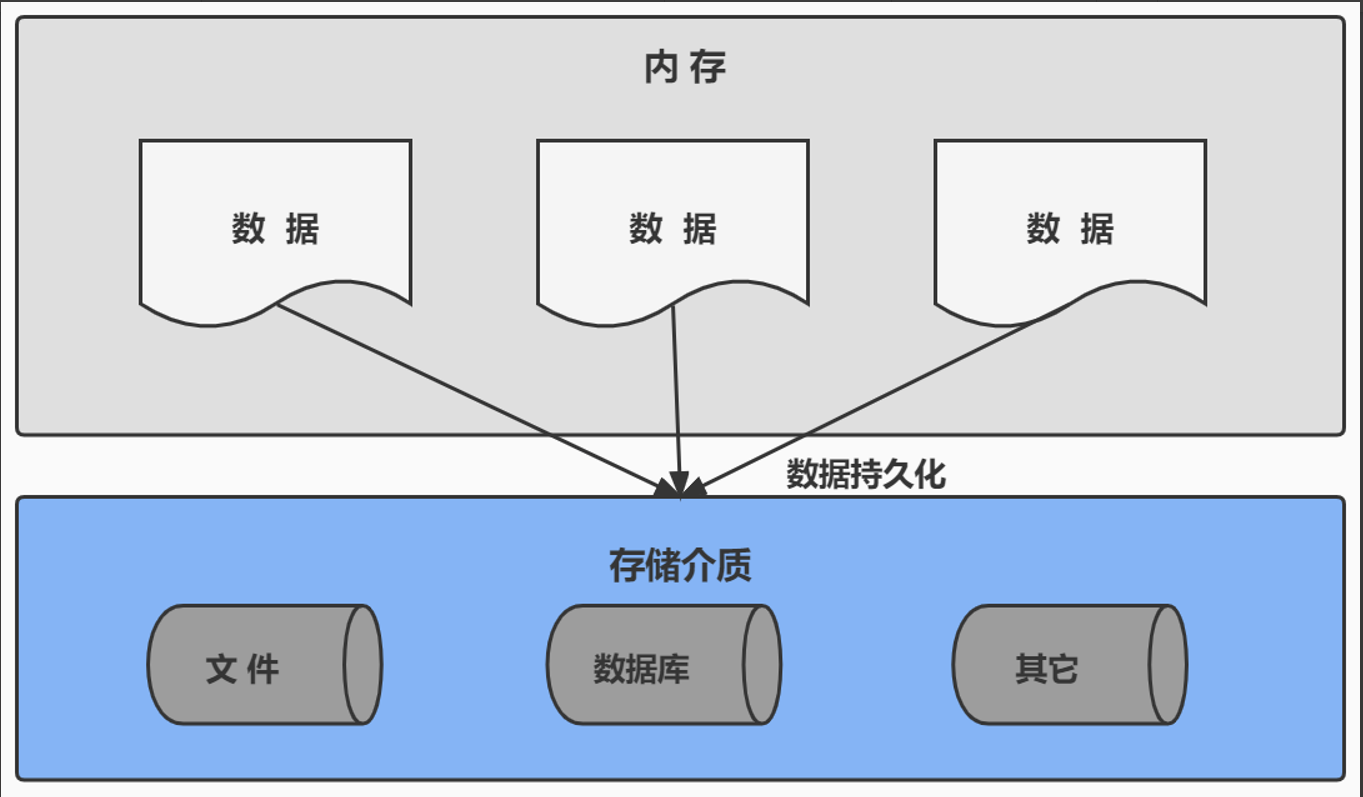
在多数场景下,尤其是企业级应用中,数据持久化非常重要,数据持久化是指将内存中动态生成或处理的数据通过“固化”手段存储至硬盘等持久性介质,从而确保数据在系统重启或异常终止后依然可用。
这种数据持久化机制的核心价值在于:
- 数据安全性:通过物理存储介质保障数据在内存释放或系统故障后不会丢失;
- 系统稳定性:减少因内存溢出或进程终止导致的数据丢失风险;
- 业务连续性:支持长时间的数据积累与分析,为历史数据查询与决策提供支撑。
3.数据库的相关概念
3.1 数据库(DB):数据的“仓库”
DB库本质是一个文件系统。它保存了一系列有组织的数据。(DB管理数据)
3.2 数据库管理系统(DBMS):数据库的“管家”
DBMS 是管理数据库的软件系统。(DBMS管理数据库)
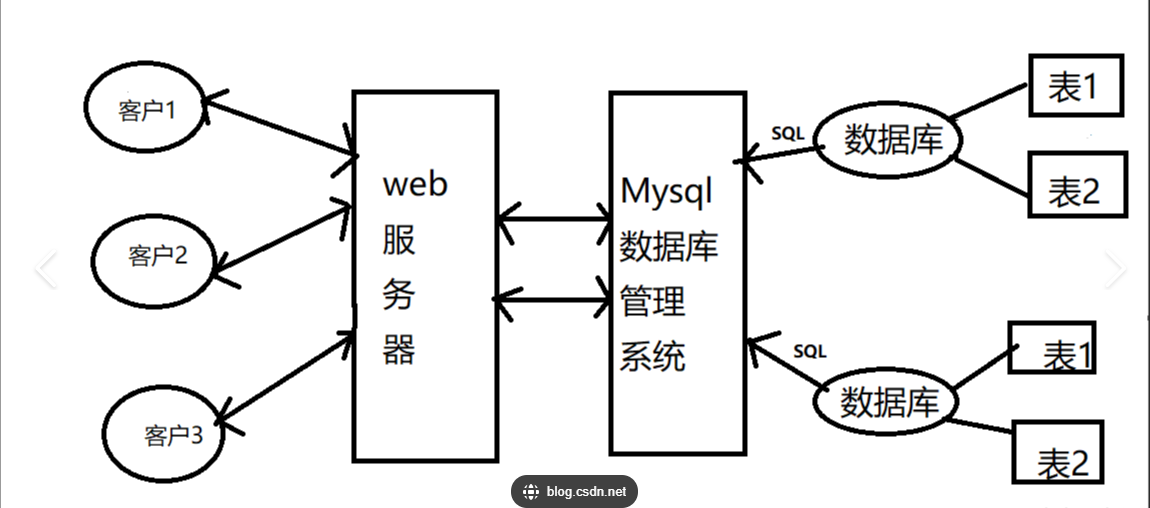
3.3 SQL(结构化查询语言)
- SQL 是操作数据库的“语言”:数据库是数据的集合,而 SQL 是访问和操作这些数据的工具。
例如,通过 SQL 查询可以从数据库中获取用户信息、更新订单状态等。 - SQL 不直接操作数据库:SQL 本身无法直接访问磁盘上的数据库文件,必须通过 DBMS 执行。例如,MySQL 的 SQL 查询会被 MySQL Server 解析并转化为对底层存储引擎的操作。
三者综合关系: 用户通过 SQL 向 DBMS 发送指令,DBMS 操作数据库并返回结果。
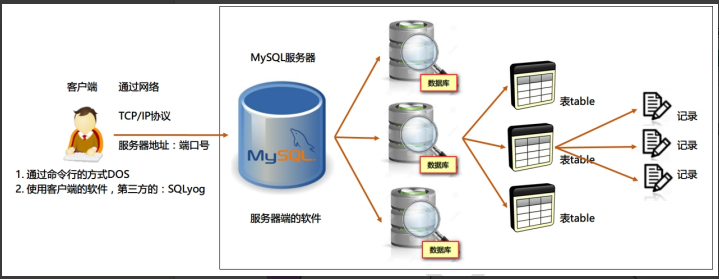
二、MySQL介绍
1.核心特点
- 免费
- 社区活跃,生态丰富,支持跨平台部署(Linux、Windows、macOS)。
- 标准化 SQL 支持
- 丰富的存储引擎(InnoDB(默认)、MyISAM、Memory)
- 开放源代码,使用成本低。
- 软件体积小,使用简单,并且易于维护。
2.关系型数据库(RDBMS)
这种类型的数据库是 最古老 的数据库类型,关系型数据库模型是把复杂的数据结构归结为简单的
二元关系 。数据以二维表形式存储,每张表有固定的列(字段)和动态的行(记录)。
常见的关系型数据库有MySQL、Oracle、SQL Server等。
- Oracle更适合大型跨国企业、或者医疗行业的使用,因为他们对费用不敏感,但是对性能要求以及安全性有更高的要求。
- MySQL由于其体积小、速度快、总体拥有成本低,可处理上千万条记录的大型数据库,尤其是开放源码这一特点,使得很多互联网公司、中小型网站选择了MySQL作为网站数据库(Facebook,Twitter,YouTube,阿里巴巴/蚂蚁金服,去哪儿,美团外卖,腾讯)。
3.非关系型数据库(非RDBMS)
非关系型数据库,可看成传统关系型数据库的功能 阉割版本 ,基于键值对存储数据,不需要经过SQL层的解析, 性能非常高 。同时,通过减少不常用的功能,进一步提高性能。
- 键值型数据库:键值型数据库通过 Key-Value 键值的方式来存储数据,其中 Key 和 Value 可以是简单的对象,也可以是复杂的对象。Key 作为唯一的标识符,优点是查找速度快,在这方面明显优于关系型数据库,缺点是无法像关系型数据库一样使用条件过滤(比如 WHERE),如果你不知道去哪里找数据,就要遍历所有的键,这就会消耗大量的计算。键值型数据库典型的使用场景是作为 内存缓存 。 Redis 是最流行的键值型数据库。
- 文档型数据库:此类数据库可存放并获取文档,可以是XML、JSON等格式。在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录。文档数据库所存放的文档,就相当于键值数据库所存放的“值”。MongoDB是最流行的文档型数据库。此外,还有CouchDB等。
- 搜索引擎数据库:虽然关系型数据库采用了索引提升检索效率,但是针对全文索引效率却较低。搜索引擎数据库是应用在搜索引擎领域的数据存储形式,由于搜索引擎会爬取大量的数据,并以特定的格式进行存储,这样在检索的时候才能保证性能最优。核心原理是“倒排索引”。典型产品:Solr、Elasticsearch、Splunk 等。
4.表的关联关系
表的关联关系是数据库设计中的核心概念,用于描述不同表之间的数据依赖和逻辑联系。
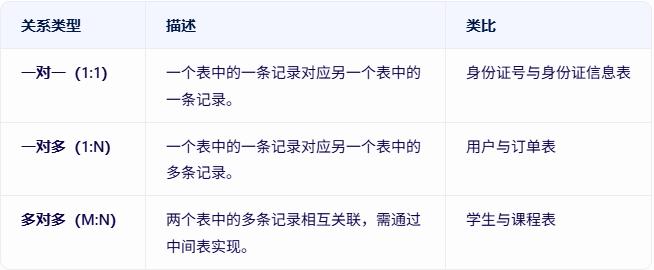
- 一对一关系:通过字段直接关联,通常用于补充信息。
- 一对多关系:最常见的关联类型,适用于主从数据结构。
- 多对多关系:需通过中间表实现,适用于复杂关联场景。
三、MySQL环境搭建
这里网上的相关安装教程非常多。这里给出几篇链接,需要的同学自行查看。
MySQL安装:
- https://blog.csdn.net/weixin_39289696/article/details/128850498
- https://blog.csdn.net/m0_52559040/article/details/121843945
- https://www.cnblogs.com/kendoziyu/p/MySQL.html
- https://www.cnblogs.com/aishangJava/p/13335254.html
MySQL卸载:
- https://blog.csdn.net/weixin_56952690/article/details/129678685
- https://developer.aliyun.com/article/1336936
- https://blog.csdn.net/weixin_52003205/article/details/132241518
四、基本的SELECT语句
1.sql分类
SQL语言在功能上主要分为如下3大类:
- DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。
- DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。SELECT是SQL语言的基础,最为重要。
- DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
- 因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。还有单独将 COMMIT 、 ROLLBACK 取出来称为TCL (Transaction Control Language,事务控制语言)。
2.基本的SELECT语句
2.1 SELECT基本语法
SELECT column1, column2, ...
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s) [ASC|DESC];
说明:
- SELECT column1, column2, …: 指定要查询的列。可以使用 * 来选择所有列。
- FROM table_name: 指定查询的表名。
- WHERE condition: (可选)用于过滤记录,只返回满足条件的行。
- GROUP BY column_name(s): (可选)用于根据一个或多个列对结果集进行分组。通常与聚合函数(如 COUNT(), SUM(), AVG(), MIN(), MAX())一起使用。
- HAVING condition: (可选)用于过滤分组后的结果集。HAVING 通常用于对 GROUP BY 的结果应用条件。
- ORDER BY column_name(s) [ASC|DESC]: (可选)用于对结果集进行排序。ASC 表示升序(默认),DESC 表示降序
将 SQL 关键字书写为大写形式是一个好的编码习惯。但是,SQL 不区分大小写。比如下面的语句也是完全正确执行的:
select column1, column2, ...
from table_name
where condition
group by column_name(s)
having condition
group by column_name(s) [asc|desc];
这段SQL 查询的实际执行顺序(逻辑顺序)通常如下:
- FROM: 从 table_name 或其他数据源中读取数据。
- WHERE: 对读取的数据应用 WHERE 条件,过滤出符合条件的行。
- GROUP BY: 将过滤后的数据按照 GROUP BY 子句中的列进行分组。
- HAVING: 对分组后的数据应用 HAVING 条件,过滤出符合条件的分组。
- SELECT: 选择需要的列(包括聚合函数的结果)。
- ORDER BY: 对最终结果集按照 ORDER BY 子句中的列进行排序(可选)。
2.2 SELECT语句示例
假设有一个名为 employees 的表,包含以下列:id, name, position, salary。
查询所有员工的姓名和职位:
SELECT name, position FROM employees;
查询工资大于5000的员工姓名:
SELECT name FROM employees WHERE salary > 5000;
查询每个职位的员工数量:
SELECT position, COUNT(*) AS num_employees FROM employees GROUP BY position;
查询每个职位的员工数量,并只显示员工数量大于2的职位:
SELECT position, COUNT(*) AS num_employees
FROM employees
GROUP BY position
HAVING COUNT(*) > 2;
查询所有员工,并按工资降序排列:
SELECT * FROM employees ORDER BY salary DESC;
3.WHERE
3.1 WHERE 子句介绍
WHERE 子句允许您为 SELECT 查询指定搜索条件。以下是 WHERE 子句的语法:
SELECT
columns_list
FROM
table_name
WHERE
query_condition;
其中 query_condition 就是查询条件,它的结果是一个布尔值,其值可能为 TRUE, FALSE 或 UNKNOWN。最终, SELECT 语句返回的结果集就是满足查询条件结果为 TRUE 的记录。
查询条件一般用来比较某个字段是否匹配某个值,一般形式如下:
column_name = value
查询条件也可以是使用 AND , OR 和 NOT 逻辑运算符一个或多个表达式的组合。
除了用在 SELECT 语句之外, WHERE 子句还可以用在 UPDATE 和 DELETE 语句中,用来指定要更新或删除的行。
3.2WHERE 子句示例
使用相等比较运算
以下查询使用 WHERE 子句查找姓为 ALLEN 的所有演员:
SELECT
*
FROM
actor
WHERE
last_name = 'ALLEN'
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 118 | CUBA | ALLEN | 2006-02-15 04:34:33 |
| 145 | KIM | ALLEN | 2006-02-15 04:34:33 |
| 194 | MERYL | ALLEN | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
17 rows in set (0.00 sec)
在这个语句中查询条件 last_name = ‘ALLEN’ 的含义是表中记录行的 last_name 字段的值为 ALLEN。
使用 AND 组合多个条件查询
以下查询使用 WHERE 子句查找姓为 DAVIS 名为 SUSAN 的所有演员:
SELECT
*
FROM
actor
WHERE
last_name = 'DAVIS' AND first_name = 'SUSAN';
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 101 | SUSAN | DAVIS | 2006-02-15 04:34:33 |
| 110 | SUSAN | DAVIS | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
2 rows in set (0.00 sec)
在这个语句中,查询条件 last_name = ‘DAVIS’ AND first_name = ‘SUSAN’ 的意思是过滤表中 last_name 字段的值为 DAVIS,并且 first_name 字段的值为 SUSAN 的所有记录行。
last_name = ‘DAVIS’ 是一个条件,first_name = ‘SUSAN’ 也是一个条件,AND 将两者组合在一起,意思是查询的记录行要同时满足这两个条件。
AND 两边的条件表达式,必须两个表达式都返回了 TRUE,整个表达式的结果才是 TRUE。
使用 OR 组合多个查询条件
以下查询使用 WHERE 子句查找姓为 ALLEN 或 DAVIS 的所有演员:
SELECT
*
FROM
actor
WHERE
last_name = 'ALLEN' OR last_name = 'DAVIS';
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 118 | CUBA | ALLEN | 2006-02-15 04:34:33 |
| 145 | KIM | ALLEN | 2006-02-15 04:34:33 |
| 194 | MERYL | ALLEN | 2006-02-15 04:34:33 |
| 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33 |
| 101 | SUSAN | DAVIS | 2006-02-15 04:34:33 |
| 110 | SUSAN | DAVIS | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
在这个语句中,查询条件 last_name = ‘ALLEN’ OR last_name = ‘DAVIS’ 代表了表中记录行的 last_name 字段的记录值等于 ALLEN 或者 DAVIS。
OR 两边的条件表达式,只要一个表达式返回了 TRUE,整个表达式的结果就是 TRUE。
WHERE 子句常见运算符
在上面的几个例子中,我们只使用了一种比较运算符 = 。 比较运算符 = 的作用是比较运算符两边的操作数(字段或表达式或值)是否相等。
MySQL 提供了很多比较运算符以满足各种不同比较需求。下表列出了可用于 WHERE 子句中的比较运算符。

4.ORDER BY
4.1 ORDER BY子句介绍
在 ORDER BY 子句中,我们可以指定一个或多个排序的字段。 ORDER BY 子句的语法如下:
SELECT
column1, column2, ...
FROM
table_name
[WHERE clause]
ORDER BY
column1 [ASC|DESC],
column2 [ASC|DESC],
...;
说明:
- ORDER BY 子句可以指定一个或多个字段。
- [ASC|DESC] 代表排序是升序还是降序,这是可选的。
- ASC 代表升序,DESC 代表降序。
- 未指定 [ASC|DESC] 时,默认值是 ASC。即,默认是按指定的字段升序排序。
- 当指定多个列时,首先按照前面的字段排序,其次按照后面的字段排序。
4.2 ORDER BY排序规则
-
ORDER BY column ASC:此 ORDER BY 子句对结果集按 column 字段的值升序排序。
-
ORDER BY column DESC:此 ORDER BY 子句对结果集按 column 字段的值降序排序。
-
ORDER BY column:此 ORDER BY 子句对结果集按 column 字段的值升序排序。这个语句等效于: ORDER BY column ASC。
-
ORDER BY column1, column2:此 ORDER BY 子句对结果集先按 column1 字段的值升序排序,然后再按 column2 字段的值升序排序。
也就是说主排序按 column1 字段升序排序,在主排序的基础上,对 column1 字段相同的行,再按 column2 字段升序排序。 -
ORDER BY column1 DESC, column2:此 ORDER BY 子句对结果集先按 column1 字段的值降序排序,然后再按按 column2 字段的值升序排序。
也就是说主排序按 column1 字段降序排序,在主排序的基础上,对 column1 字段相同的行,再按 column2 字段升序排序。
4.3 ORDER BY子句示例
以下 SQL 语句使用 ORDER BY 子句按演员姓氏升序进行排序
SELECT
actor_id, first_name, last_name
FROM
actor
ORDER BY last_name;
+----------+-------------+--------------+
| actor_id | first_name | last_name |
+----------+-------------+--------------+
| 92 | KIRSTEN | AKROYD |
| 58 | CHRISTIAN | AKROYD |
| 182 | DEBBIE | AKROYD |
| 194 | MERYL | ALLEN |
| 118 | CUBA | ALLEN |
| 145 | KIM | ALLEN |
...
以下 SQL 语句使用 ORDER BY 子句按演员姓氏降序进行排序。
SELECT
actor_id, first_name, last_name
FROM
actor
ORDER BY last_name DESC;
+----------+-------------+--------------+
| actor_id | first_name | last_name |
+----------+-------------+--------------+
| 111 | CAMERON | ZELLWEGER |
| 85 | MINNIE | ZELLWEGER |
| 186 | JULIA | ZELLWEGER |
| 63 | CAMERON | WRAY |
| 156 | FAY | WOOD |
| 13 | UMA | WOOD |
| 144 | ANGELA | WITHERSPOON |
| 68 | RIP | WINSLET |
....
以下 SQL 语句使用 ORDER BY 子句先按演员姓氏升序排序,再按演员名字升序排序。
SELECT
actor_id, first_name, last_name
FROM
actor
ORDER BY last_name, first_name;
+----------+-------------+--------------+
| actor_id | first_name | last_name |
+----------+-------------+--------------+
| 58 | CHRISTIAN | AKROYD |
| 182 | DEBBIE | AKROYD |
| 92 | KIRSTEN | AKROYD |
| 118 | CUBA | ALLEN |
| 145 | KIM | ALLEN |
| 194 | MERYL | ALLEN |
....
5.LIMIT
5.1 LIMIT 子句介绍
该 LIMIT 子句可用于限制 SELECT 语句返回的行数。 LIMIT 接受一个或两个非负数正数作为参数。 LIMIT 子句的语法如下:
LIMIT [offset,] row_count;
或
LIMIT row_count OFFSET offset;
说明:
- 上述两种语法的结果是等效的,只是写法略有不同。
- offset 指定要返回的第一行的偏移量。偏移量是相对于未使用 LIMIT 语句时的原始结果集而言的。offset 可理解为在原始结果集的基础上跳过的行数。
- row_count 执行要返回的最大行数。
- offset 是可选的。当未指定 offset 时,默认的值 offset 为 0。
- LIMIT 一般位于 SELECT 语句的最后。
例如:
LIMIT 5:最多返回 5 个记录行,等效于 LIMIT 0 5
LIMIT 2 5:在原始结果集中,跳过 2 个记录行,并从 第 3 个记录行开始,最多返回 5 个记录行。
5.2 LIMIT 子句示例
查询片长最长的 10 部影片
以下 SQL 语句返回 film 表中等级为 G 的片长最长的 10 部影片。
SELECT
film_id, title, length
FROM
film
WHERE
rating = 'G'
ORDER BY length DESC
LIMIT 10;
+---------+--------------------+--------+
| film_id | title | length |
+---------+--------------------+--------+
| 212 | DARN FORRESTER | 185 |
| 182 | CONTROL ANTHEM | 185 |
| 609 | MUSCLE BRIGHT | 185 |
| 597 | MOONWALKER FOOL | 184 |
| 128 | CATCH AMISTAD | 183 |
| 996 | YOUNG LANGUAGE | 183 |
| 50 | BAKED CLEOPATRA | 182 |
| 467 | INTRIGUE WORST | 181 |
| 510 | LAWLESS VISION | 181 |
| 612 | MUSSOLINI SPOILERS | 180 |
+---------+--------------------+--------+
查询片长最短的 10 部影片
以下 SQL 语句返回 film 表中等级为 G 的片长最短的 10 部影片。
SELECT
film_id, title, length
FROM
film
WHERE
rating = 'G'
ORDER BY length
LIMIT 10;
+---------+---------------------+--------+
| film_id | title | length |
+---------+---------------------+--------+
| 247 | DOWNHILL ENOUGH | 47 |
| 237 | DIVORCE SHINING | 47 |
| 2 | ACE GOLDFINGER | 48 |
| 575 | MIDSUMMER GROUNDHOG | 48 |
| 430 | HOOK CHARIOTS | 49 |
| 83 | BLUES INSTINCT | 50 |
| 292 | EXCITEMENT EVE | 51 |
| 402 | HARPER DYING | 52 |
| 794 | SIDE ARK | 52 |
| 542 | LUST LOCK | 52 |
+---------+---------------------+--------+
使用 LIMIT 子句进行分页
LIMIT 的一个很重要的应用就是分页查询。对于一些大型的数据表来说,分页查询能很好的减少数据库的消耗和提高用户体验。
film 表中共有 1000 行数据,这个我们可以通过以下的 COUNT(*) 查询得知。
mysql> SELECT COUNT(*) FROM film;
+----------+
| COUNT(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.00 sec)
如果没有分页查询,所有数据都显示在页面上,会引入以下的问题:
- 增加数据库的性能消耗
- 传输过程中的数据量增加
- 用户的体验不好,太多的数据对让用户眼花缭乱。
如果我们引入分页,每页显示 10 行数据,那么 1000 行数据需要 100 (1000 / 10) 页就能显示完全。
查询第一个页只需限制最多行数为 10 行数据即可,整个 SQL 如下:
SELECT film_id, title FROM film LIMIT 10;
+---------+------------------+
| film_id | title |
+---------+------------------+
| 1 | ACADEMY DINOSAUR |
| 2 | ACE GOLDFINGER |
| 3 | ADAPTATION HOLES |
| 4 | AFFAIR PREJUDICE |
| 5 | AFRICAN EGG |
| 6 | AGENT TRUMAN |
| 7 | AIRPLANE SIERRA |
| 8 | AIRPORT POLLOCK |
| 9 | ALABAMA DEVIL |
| 10 | ALADDIN CALENDAR |
+---------+------------------+
要查询第二页需要先跳过第一页的 10 行数据并限制最多行数为 10 行数据,整个 SQL 如下:
SELECT film_id, title FROM film LIMIT 10, 10;
+---------+------------------+
| film_id | title |
+---------+------------------+
| 1 | ACADEMY DINOSAUR |
| 2 | ACE GOLDFINGER |
| 3 | ADAPTATION HOLES |
| 4 | AFFAIR PREJUDICE |
| 5 | AFRICAN EGG |
| 6 | AGENT TRUMAN |
| 7 | AIRPLANE SIERRA |
| 8 | AIRPORT POLLOCK |
| 9 | ALABAMA DEVIL |
| 10 | ALADDIN CALENDAR |
+---------+------------------+
同样,最后一页的 SQL 语句如下:
SELECT film_id, title FROM film LIMIT 990, 10;
6.DISTINCT
6.1 DISTINCT 关键字介绍
在 SELECT 语句中使用 DISTINCT 关键字会返回一个没有重复记录行的结果集。 DISTINCT 的用法如下:
SELECT DISTINCT
columns_list
FROM
table_name
说明:
- DISTINCT 关键字位于 SELECT 关键字的后面。
- columns_list 指定要查询的字段列表,也是 DISTINCT 评估记录行是否唯一的字段。
- columns_list 可以是一个字段,也可以是多个字段。
- columns_list 也可以是 *。
6.2 DISTINCT 关键字示例
DISTINCT 单个字段
姓氏重复是一个很正常的现象。我们先使用 SELECT 语句检索以下 actor 表中的姓氏。
SELECT last_name FROM actor;
+--------------+
| last_name |
+--------------+
| AKROYD |
| AKROYD |
| AKROYD |
| ALLEN |
| ALLEN |
...
| ZELLWEGER |
| ZELLWEGER |
+--------------+
200 rows in set (0.01 sec)
然后我们使用 DISTINCT 删除重复的数据,返回唯一的姓氏列表:
SELECT DISTINCT last_name FROM actor;
+--------------+
| last_name |
+--------------+
| AKROYD |
| ALLEN |
| ASTAIRE |
| BACALL |
| BAILEY |
...
| ZELLWEGER |
+--------------+
121 rows in set (0.00 sec)
我们可以看到输出的结果集中已经没有了重复数据。结果集的行数也从原来的 200 行变成了 121 行。
DISTINCT 多个字段
DISTINCT 还可以清除多个字段的重复值。当指定多个字段值时, DISTINCT 使用多个字段组合确定记录行的唯一性。
现实中,我们不但存在姓氏重复的情况,名字也可能重复。我们检索 actor 表中的名字和姓氏:
SELECT last_name, first_name FROM actor;
+--------------+-------------+
| last_name | first_name |
+--------------+-------------+
| GUINESS | PENELOPE |
| WAHLBERG | NICK |
| CHASE | ED |
| DAVIS | JENNIFER |
| LOLLOBRIGIDA | JOHNNY |
| NICHOLSON | BETTE |
...
| TEMPLE | THORA |
+--------------+-------------+
200 rows in set (0.01 sec)
然后我们使用 DISTINCT 删除重复的数据:
SELECT DISTINCT last_name, first_name FROM actor;
+--------------+-------------+
| last_name | first_name |
+--------------+-------------+
| GUINESS | PENELOPE |
| WAHLBERG | NICK |
| CHASE | ED |
| DAVIS | JENNIFER |
| LOLLOBRIGIDA | JOHNNY |
...
| TEMPLE | THORA |
+--------------+-------------+
199 rows in set (0.01 sec)
我们可以看到输出结果集的行数也从原来的 200 行变成了 199 行。
7.GROUP BY
7.1 GROUP BY子句介绍
GROUP BY 子句是 SELECT 语句的可选子句。 GROUP BY 子句语法如下:
SELECT column1[, column2, ...], aggregate_function(ci)
FROM table
[WHERE clause]
GROUP BY column1[, column2, ...];
[HAVING clause]
说明:
- column1[, column2, …] 是分组依据的字段,至少一个字段,可以多个字段。
- aggregate_function(ci) 是聚合函数。这是可选的,但是一般都用得到。
- SELECT 后的字段必须是分组字段中的字段。
- WHERE 子句是可选的,用来过滤结果集中的数据。
- HAVING 子句是可选的,用来过滤分组数据。
经常使用的聚合函数主要有:
- SUM(): 求总和
- AVG(): 求平均值
- MAX(): 求最大值
- MIN(): 求最小值
- COUNT(): 计数
7.2 GROUP BY子句示例
我们使用 GROUP BY 子句和聚合函数 COUNT() 查看 actor 表中的姓氏列表以及每个姓氏的次数。
SELECT last_name, COUNT(*)
FROM actor
GROUP BY last_name
ORDER BY COUNT(*) DESC;
+--------------+----------+
| last_name | COUNT(*) |
+--------------+----------+
| KILMER | 5 |
| NOLTE | 4 |
| TEMPLE | 4 |
| AKROYD | 3 |
| ALLEN | 3 |
| BERRY | 3 |
...
| WRAY | 1 |
+--------------+----------+
121 rows in set (0.00 sec)
本例中,执行的顺序如下:
- 首先使用 GROUP BY 子句按照 last_name 字段对数据进行分组。
- 然后使用聚合函数 COUNT(*) 汇总每个姓氏的行数。
- 最后使用 ORDER BY 子句按照 COUNT(*) 降序排列。
- 这样,数量最多的姓氏排在最前面。
8. 别名
有列别名和表别名。
SELECT column_name AS `alias`
FROM table_name t1;
别名其实就是起到一个简化我们书写的作用,比如说下面这个sql每个表不弄一个简化的别名,如果要查询的字段很多的话,写起来很麻烦。还有字段别名在我们开发过程中与实体对应也起到一定的作用。
SELECT
u.user_id,
u.user_name,
o.order_id,
o.order_date,
p.product_id,
p.product_name,
od.quantity,
a.address_id,
a.address
FROM
users u
JOIN
orders o ON u.user_id = o.user_id
JOIN
order_details od ON o.order_id = od.order_id
JOIN
products p ON od.product_id = p.product_id
JOIN
addresses a ON u.user_id = a.user_id
WHERE
o.order_date >= '2023-01-01' -- 示例条件:查询2023年1月1日之后的订单
ORDER BY
o.order_date DESC;




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











