






数据清洗
新建一个maven项目和前面获取数据步骤一样,完成后的目录
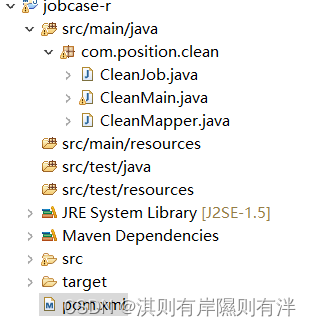
首先在pom.xml中设置环境
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itcase.jobcase</groupId>
<artifactId>jobcase-r</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>C:/Program Files/Java/jdk1.8.0_341/lib/tools.jar</systemPath>
</dependency>
</dependencies>
</project>第一个类为:CleanJob.java
package com.position.clean;
import org.codehaus.jettison.json.JSONArray;
import org.codehaus.jettison.json.JSONException;
import org.codehaus.jettison.json.JSONObject;
public class CleanJob {
//在CleanJob类中添加方法deleteString(),用于对薪资字符串进行处理,即去除薪资中的‘k’字符。
public static String deleteString(String str, char delChar) {
StringBuffer stringBuffer = new StringBuffer("");
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) != delChar) {
stringBuffer.append(str.charAt(i));
}
}
return stringBuffer.toString();}
// 在CleanJob类中添加方法mergeString(),用于将companyLabelList字段中的数据内容和positionAdvantage字段中的数据内容进行合并处理,生成新字符串数据(以“-”为分隔符)。
public static String mergeString(String position,JSONArray company)
throws JSONException{
String result = "";
if (company.length() != 0) {
for (int i = 0; i < company.length(); i++) {
result = result + company.get(i) + "-";}}
if(position !=""){
String[] positionList = position.split(" |;|,|、|,|;|/");
for (int i = 0; i < positionList.length; i++) {
result =result + positionList[i].replaceAll("[\\pP\\p{Punct}]","")+"-";
}}
return result.substring(0, result.length()-1);}
//在CleanJob类中创建方法killResult()将数据文件中的技能标签进行处理并重新生成新的字符串形式(以“-”为分隔符)
public static String killResult(JSONArray killData )
throws JSONException{
String result ="";
if (killData.length() != 0) {
for (int i = 0; i < killData.length(); i++){
result = result + killData.get(i) + "-";
}
return result = result.substring(0, result.length() - 1);
}
return result;
}
//在CleanJob类中创建方法resultToString()将数据文件中的每一条职位信息数据进行处理并重新组合成新的字符串形式
public static String resultToString(JSONArray jobdata) throws JSONException{
String jobResultData = "";
for (int i = 0; i < jobdata.length(); i++) {
//获取每条职位信息
String everyData=jobdata.get(i).toString();
//将String类型的数据转换为JSON对象
JSONObject everyDataJson = new JSONObject(everyData);
//获取职位信息中的城市数据
String city = everyDataJson.getString("city");
//获取职位信息中的薪资数据
String salary = everyDataJson.getString("salary");
//获取职位信息中的公司福利标签数据
String positionAdvantage = everyDataJson.getString("positionAdvantage");
//获取职位信息中的公司福利标签数据
JSONArray companyLabelList = everyDataJson.getJSONArray("companyLabelList");
//获取职位信息中的技能标签数据
JSONArray skillLables = everyDataJson.getJSONArray("skillLables");
//调用上面3个方法处理薪资字段数据
String salaryNew = deleteString(salary, 'k');
String welfare = mergeString(positionAdvantage,companyLabelList);
String kill = killResult(skillLables);
//如果是第30页的最后一行是不需要换行的,其他的需要换行所以用if判断一下
if (i ==jobdata.length()-1) {
jobResultData = jobResultData + city + ","
+ salaryNew + "," + welfare + "," + kill;
}
else {
jobResultData = jobResultData + city + ","
+ salaryNew + "," + welfare + "," + kill + "\n";
}
}
return jobResultData;
}}第二个为:CleanMain.java
package com.position.clean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
public class CleanMain {
public static void main(String[] args) throws Exception {
//控制台输出日志
BasicConfigurator.configure();
//初始化hadoop配置
Configuration conf = new Configuration();
//从hadoop命令行读取参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//判断从命令行读取参数正常是两个,分别是输入文件和输出文件目录
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
//定义一个新的Job,第一个参数是hadoop配置信息,第二个参数是Job的名字
Job job=new Job(conf,"job");
//设置主类
job.setJarByClass(CleanMain.class);
//设置mapper类
job.setMapperClass(CleanMapper.class);
//处理小文件,默认是CombineTextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//n个小文件之和不能大于2MB
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
//在n个小文件之和不能大于2MB情况下,需满足n+1个小文件之和不能大于4MB
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
//设置job输出数据的key类
job.setOutputKeyClass(Text.class);
//设置job输出数据的value类
job.setOutputValueClass(NullWritable.class);
//设置输入文件
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
//设置输出文件
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}第三个为:CleanMapper.java
package com.position.clean;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.codehaus.jettison.json.JSONArray;
import org.codehaus.jettison.json.JSONException;
import org.codehaus.jettison.json.JSONObject;
public class CleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
String jobResultData = "";
//将每一个数据文件的内容转换为String类型
String reptileData = value.toString();
//通过截取字符串的方式获取content中的数据
String jobData = reptileData.substring(reptileData.indexOf("=",reptileData.indexOf("=")+1)+1,reptileData.length()-1);
try {
//获取content中的数据内容
JSONObject contentJson = new JSONObject(jobData);
String contentData = contentJson.getString("content");
//获取content下的positionResult中的数据内容
JSONObject positionResultJson = new JSONObject(contentData);
String positionResultData = positionResultJson.getString("positionResult");
//获取最终的result中的数据内容
JSONObject resultJson = new JSONObject(positionResultData);
JSONArray resultData = resultJson.getJSONArray("result");
jobResultData = CleanJob.resultToString(resultData);
context.write(new Text(jobResultData), NullWritable.get());
} catch (JSONException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
然后需要创建jar包
在你java代码所在的目录下打开powershell或者cmd,在powershell或者cmd窗口输入mvn package就可以把数据预处理程序打包成jar包,在本地项目目录的target目录下查看生成得jar包

将jar包提交到集群运行
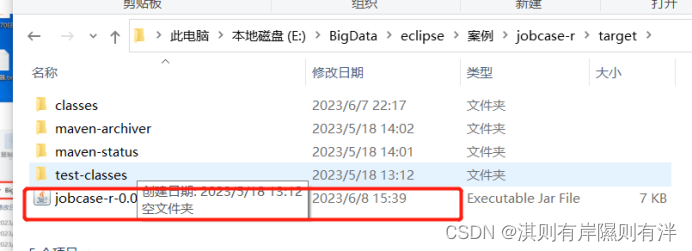
(1)在hadoop01虚拟机通过Xftp将jar包上传至export/software目录,然后改名字mv jobcase-clean-0.0.1-SNAPSHOT.jar clean.jar
(2)在hadoop01中运行hadoop jar命令执行数据预处理程序的jar包,在命令中指定数据输入和结果输出的目录,指令如下
hadoop jar clean.jar com.position.clean.CleanMain /JobData/20230515/ /JobData/output 20230515这个是修改的,根据你自己的文件命名
(3)在虚拟机中通过Hadoop命令查看HDFS上生成的结果文件。
hadoop dfs -cat /JobData/output/part-r-00000

这样我们加将数据进行简单的数据,下回我们说怎么通过hive处理数据















 2739
2739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









