










💧 S p r i n g A O P + 主从数据源切换 + 读写分离 + 自定义注解案例实战! \color{#FF1493}{Spring AOP + 主从数据源切换 + 读写分离 + 自定义注解 案例实战!} SpringAOP+主从数据源切换+读写分离+自定义注解案例实战!💧
🌷 仰望天空,妳我亦是行人.✨
🦄 个人主页——微风撞见云的博客🎐
🐳 《数据结构与算法》专栏的文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
💧 《Java学习笔记》专栏的文章是本人在Java学习中总结的一些知识点~ 💐
🥣 《每天一点小知识》专栏的文章可以丰富你的知识库,滴水成河~ 🌊
🎐 《Redis》专栏的文章是在学习Redis时,整理的笔记与记录的思考~ 🥏
🥕 《RabbitMQ》专栏的文章是在学习尚硅谷课程时整理的笔记,方便复习巩固~ 🍑
🪁 希望本文能够给读者带来一定的帮助~🌸文章粗浅,敬请批评指正!🐥
🐳Spring AOP + 自定义注解 + 数据源 实现主从库切换&读写分离 项目实战
在现代的应用程序开发中,数据库读写分离是提高应用性能和可伸缩性的重要策略之一。Spring AOP 和自定义注解为我们提供了实现读写分离的有效工具,而德鲁伊(Druid)数据源则为我们提供了高性能的连接池,我们用它来实现动态数据源。本篇博客将带领你一步一步实现 Spring AOP 结合自定义注解和动态数据源实现主从数据库切换以及读写分离。
准备工作
项目搭建以及相关依赖
💧首先,我们需要确保已经创建好了一个 Spring Boot (2.x.x) 项目,并添加了相关依赖。
<dependencies>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!--SpringBoot集成Aop起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!--SpringBoot集成WEB起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mybatis集成SpringBoot起步依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.3</version>
</dependency>
<!--MySQL驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
💧项目结构如图所示:
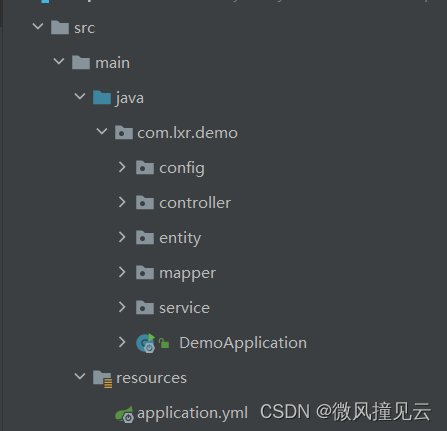
书写yml文件
💧我们在application.yml中配置一下主从数据源
server:
port: 8080
spring:
datasource:
#主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://yourhost:3306/yourdp?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=GMT%2B8
username:
password:
#从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://yourhost:3306/yourdp?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=GMT%2B8
username:
password:
数据库准备
💧准备两个数据库,分别作为主从数据库(当然,这里不用强制实现它们俩直接的主从关系 ),然后分别建 user2 表,然后准备一个可以作为区分的数据。如果有不清楚如何实现mysql主从复制的同学可以看看我的这篇文章:docker实现mysql 主从复制
CREATE TABLE `user2` (
`user_id` int NOT NULL,
`account` varchar(255) DEFAULT NULL,
`nickname` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`headimage_url` varchar(255) DEFAULT NULL,
`introduce` varchar(255) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;


config目录各文件介绍
定义Spring AOP的切面类 DataSourceAop
💧DataSourceAop 是一个Spring AOP切面类,用于拦截方法调用,并根据方法的特定条件来选择数据源类型。它通过@Pointcut定义了两个切点表达式,分别用于读操作和写操作的方法。在前置通知方法中,根据目标方法上是否存在 @Master 注解,来决定使用主库还是从库。这样,通过AOP的切面功能,实现了数据库的读写分离。
package com.lxr.demo.config;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
/**
* 默认情况下,所有的查询都走从库,插入/修改/删除走主库。我们通过方法名来区分操作类型(CRUD)
* <p>
* 切面不能建立在DAO层,事务是在service开启的,到dao层再切换数据源,那事务就废了
*/
@Aspect
@Component
public class DataSourceAop {
/**
* 第一个”*“符号 表示返回值的类型任意;
* com.sample.service.impl AOP所切的服务的包名,即,我们的业务部分
* 包名后面的”..“ 表示当前包及子包
* 第二个”*“ 表示类名,*即所有类。此处可以自定义,下文有举例
* .*(..) 表示任何方法名,括号表示参数,两个点表示任何参数类型
* <p>
* 这是一个切点表达式,它定义了一个切点,该切点在执行以下条件时成立:
* !@annotation(com.lxr.demo.config.Master): 这表示切点会排除那些带有@com.lxr.demo.config.Master注解的方法。
* execution(* com.lxr.demo.service.*.select*(..)):
* 表示切点会包含所有com.lxr.demo.service包下以select开头的方法,并且方法参数可以是任意个数、任意类型。
* execution(* com.lxr.demo.service..*.find*(..)):
* 表示切点会包含所有com.lxr.demo.service包及其子包下以find开头的方法,并且方法参数可以是任意个数、任意类型。
*/
@Pointcut("!@annotation(com.lxr.demo.config.Master) " +
"&& (execution(* com.lxr.demo.service.*.select*(..)) || execution(* com.lxr.demo.service..*.find*(..)) ) ")
public void readPointcut() {
}
@Pointcut("@annotation(com.lxr.demo.config.Master) " +
"|| execution(* com.lxr.demo.service..*.save*(..)) " +
"|| execution(* com.lxr.demo.service..*.add*(..)) " +
"|| execution(* com.lxr.demo.service..*.insert*(..)) " +
"|| execution(* com.lxr.demo.service..*.update*(..)) " +
"|| execution(* com.lxr.demo.service..*.edit*(..)) " +
"|| execution(* com.lxr.demo..*.delete*(..)) " +
"|| execution(* com.lxr.demo..*.remove*(..))")
public void writePointcut() {
}
@Before("readPointcut()")
public void read(JoinPoint jp) {
/**
* JoinPoint对象封装了SpringAop中切面方法的信息,在切面方法中添加JoinPoint参数,就可以获取到封装了该方法信息的JoinPoint对象.
* 常用api:
*
* 方法名 功能
* Signature getSignature(); 获取封装了署名信息的对象,在该对象中可以获取到目标方法名,所属类的Class等信息
* Object[] getArgs(); 获取传入目标方法的参数对象
* Object getTarget(); 获取被代理的对象
* Object getThis(); 获取代理对象
*/
//获取当前的方法信息
MethodSignature methodSignature = (MethodSignature) jp.getSignature();//方法头指定修饰符(例如static)、返回值类型、方法名、和形式参数。
Method method = methodSignature.getMethod();
//判断方法上是否存在注解@Master
boolean present = method.isAnnotationPresent(Master.class);//判断注解是否存在该元素上,如果有则返回true,否则false
if (!present) {
//如果不存在,默认走从库读
System.out.println("no");
DBContextHolder.slave();
} else {
//如果存在,走主库读
System.out.println("yes");
DBContextHolder.master();
}
}
@Before("writePointcut()")
public void write() {
System.out.println("write");
DBContextHolder.master();
}
/**
* 另一种写法:if...else... 判断哪些需要读从数据库,其余的走主数据库
*/
// @Before("execution(* com.cjs.example.service.impl.*.*(..))")
// public void before(JoinPoint jp) {
// String methodName = jp.getSignature().getName();
//
// if (StringUtils.startsWithAny(methodName, "get", "select", "find")) {
// DBContextHolder.slave();
// }else {
// DBContextHolder.master();
// }
// }
}
配置数据源和动态数据源切换
💧我们首先创建一个配置类 DataSourceConfig 来配置德鲁伊数据源和动态数据源切换。这个配置类中使用了@Configuration和@Bean注解,定义了两个数据源(主库和从库)和一个动态数据源。动态数据源会根据业务需求自动选择主库还是从库,从而实现了读写分离的功能。这在多数据库场景下非常有用,可以提高数据库的读取性能。
package com.lxr.demo.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* 增加了 DataSourceConfig 这个配置文件之后,需要添加druid连接池,单数据源自动装载时不会出这样的问题
*
* @Configuration 注解,表明这就是一个配置类,指示一个类声明一个或者多个@Bean 声明的方法并且由Spring容器统一管理,以便在运行时为这些bean生成bean的定义和服务请求的类。
*/
@Configuration
public class DataSourceConfig {
/**
* 注入主库数据源
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return new DruidDataSource();
}
/**
* 注入从库数据源
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return new DruidDataSource();
}
/**
* 配置选择数据源
*
* @param masterDataSource
* @param slaveDataSource
* @return DataSource
*/
@Bean
public DataSource myRoutingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource, @Qualifier("slaveDataSource") DataSource slaveDataSource) {
Map<Object, Object> targetDataSource = new HashMap<>();
targetDataSource.put(DBTypeEnum.MASTER, masterDataSource);
targetDataSource.put(DBTypeEnum.SLAVE, slaveDataSource);
MyRoutingDataSource myRoutingDataSource = new MyRoutingDataSource();
//找不到用默认数据源
myRoutingDataSource.setDefaultTargetDataSource(masterDataSource);
//可选择目标数据源
myRoutingDataSource.setTargetDataSources(targetDataSource);
return myRoutingDataSource;
}
}
创建自定义注解
💧接下来,我们创建一个自定义注解 Master 来标记我们需要进行主从分离的方法。
package com.lxr.demo.config;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 有时候主从延迟,需要强制读主库的注解
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Master {
}
定义数据库读写分离的工具类DBContextHolder
💧这里的 DBContextHolder 是一个线程上下文工具类,通过 ThreadLocal 来实现不同线程使用不同数据源的功能。在实现数据库读写分离的场景下,它可以根据业务需求自动选择主库或从库,确保在多线程环境下的数据源正确切换。这种实现方式非常适用于多线程环境下需要使用读写分离的项目。
package com.lxr.demo.config;
/**
* ThreadLocal 定义数据源切换,通过ThreadLocal将数据源绑定到每个线程上下文中,
* ThreadLocal 用来保存每个线程的是使用读库还是写库。操作结束后清除该数据,避免内存泄漏。
*/
public class DBContextHolder {
/**
* ThreadLocal是一个线程内部的数据存储类,通过它可以在指定的线程中存储数据,对数据存储后,只有在当前线程中才可以获取到存储的数据,对于其他线程来说是无法获取到数据。
* 大致意思就是ThreadLocal提供了线程内存储变量的能力,这些变量不同之处在于每一个线程读取的变量是对应的互相独立的,通过get和set方法就可以得到当前线程对应的值。
*/
private static final ThreadLocal<DBTypeEnum> contextHolder = new ThreadLocal<>();
public static void set(DBTypeEnum dbTypeEnum) {
contextHolder.set(dbTypeEnum);
}
public static DBTypeEnum get() {
return contextHolder.get();
}
public static void master() {
set(DBTypeEnum.MASTER);
System.out.println("--------以下操作为master(操作)--------");
}
public static void slave() {
set(DBTypeEnum.SLAVE);
System.out.println("--------以下操作为slave(读操作)--------");
}
public static void clear() {
contextHolder.remove();
}
}
定义枚举类DBTypeEnum
💧这里的 DBTypeEnum 是一个枚举类,用于表示数据库的主库和从库,在数据库读写分离的实现中,可能会用作标识数据源类型的常量,以便在动态数据源切换时选择不同的数据源。这种枚举常量的使用方式有助于代码的可读性和维护性。
package com.lxr.demo.config;
public enum DBTypeEnum {
MASTER, SLAVE;
}
配置Mybatis指定数据源:SqlSessionFactory和事务管理器
💧这里的MyBatisConfig 是一个Spring配置类,用于配置MyBatis的SqlSessionFactory和事务管理器。通过这个配置类,MyBatis可以连接到动态数据源,并实现数据库的读写分离。同时,启用了事务管理功能,确保在进行数据库操作时能够进行事务控制。
package com.lxr.demo.config;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.annotation.Resource;
import javax.sql.DataSource;
/**
* 配置Mybatis指定数据源:SqlSessionFactory和事务管理器
*/
@Configuration
@EnableTransactionManagement
public class MyBatisConfig {
/**
* 注入自己重写的数据源
*/
@Resource(name = "myRoutingDataSource")
private DataSource myRoutingDataSource;
/**
* 配置SqlSessionFactory
*
* @return SqlSessionFactory
* @throws Exception
*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(myRoutingDataSource);
//ResourcePatternResolver(资源查找器)定义了getResources来查找资源
//PathMatchingResourcePatternResolver提供了以classpath开头的通配符方式查询,否则会调用ResourceLoader的getResource方法来查找
// ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// sqlSessionFactoryBean.setMapperLocations(resolver.getResources(mapperLocation));
return sqlSessionFactoryBean.getObject();
}
/**
* 事务管理器,不写则事务不生效:事务需要知道当前使用的是哪个数据源才能进行事务处理
*/
@Bean
public PlatformTransactionManager platformTransactionManager() {
return new DataSourceTransactionManager(myRoutingDataSource);
}
// /**
// * 当自定义数据源,用户必须覆盖SqlSessionTemplate,开启BATCH处理模式
// *
// * @param sqlSessionFactory
// * @return
// */
// @Bean
// public SqlSessionTemplate sqlSessionTemplate(@Qualifier("sqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
// return new SqlSessionTemplate(sqlSessionFactory, ExecutorType.BATCH);
// }
}
自定义数据源路由类MyRoutingDataSource
💧这里的MyRoutingDataSource 是一个自定义的数据源路由类,继承了 AbstractRoutingDataSource 类。它通过重写 determineCurrentLookupKey() 方法,动态决定使用哪个数据源,从而实现了数据库的读写分离。这种动态数据源切换的方式非常灵活,可以根据业务需求在运行时动态选择不同的数据源。
package com.lxr.demo.config;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.lang.Nullable;
/**
* 重写 determineCurrentLookupKey 方法,获取当前线程上绑定的路由key。Spring 在开始进行数据库操作时会通过这个方法来决定使用哪个数据库源,因此我们在这里调用上面 DbContextHolder 类的getDbType()方法获取当前操作类别。
*
* AbstractRoutingDataSource的getConnection() 方法根据查找 lookup key 键对不同目标数据源的调用,通常是通过(但不一定)某些线程绑定的事物上下文来实现。
*
* AbstractRoutingDataSource的多数据源动态切换的核心逻辑是:在程序运行时,把数据源数据源通过 AbstractRoutingDataSource 动态织入到程序中,灵活的进行数据源切换。
*
* 基于AbstractRoutingDataSource的多数据源动态切换,可以实现读写分离,这么做缺点也很明显,无法动态的增加数据源。
*/
public class MyRoutingDataSource extends AbstractRoutingDataSource {
/**
* determineCurrentLookupKey()方法决定使用哪个数据源、
* 根据Key获取数据源的信息,上层抽象函数的钩子
*/
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return DBContextHolder.get();
}
}
config配置类总结
💧上面介绍了config中的各种配置类以及相关工具类,现在对它们进行简单梳理 ↓
DBTypeEnum:这是一个枚举类,定义了两个枚举常量 MASTER 和 SLAVE,分别表示数据库的主库和从库。DBContextHolder:这是一个工具类,使用了 ThreadLocal 来定义数据源切换。它可以将数据源与每个线程的上下文绑定在一起,用于在多线程环境下实现不同线程使用不同的数据源。DataSourceConfig:这是一个Spring配置类,用于配置数据源。它定义了两个 @Bean 方法,分别用于创建主库数据源和从库数据源。此外,还定义了一个 myRoutingDataSource 方法,用于创建一个动态数据源,根据不同的数据源类型选择相应的数据源。MyRoutingDataSource:这是一个自定义的数据源路由类,继承了 AbstractRoutingDataSource 类。它重写了 determineCurrentLookupKey() 方法,用于动态决定当前使用的数据源,根据 DBContextHolder 中存储的数据源类型(主库或从库),选择相应的数据源。MyBatisConfig:这是一个Spring配置类,用于配置MyBatis的 SqlSessionFactory 和事务管理器。它通过 @Resource 注解将 myRoutingDataSource 自动注入,将动态数据源应用到MyBatis框架中。DataSourceAop:这是一个切面类,用于在使用自定义注解时拦截方法调用。它在 before 方法中根据方法上的自定义注解,决定将当前线程的数据源设置为主库或从库,从而实现读写分离的功能。
💧这些类共同实现了一个数据库读写分离的功能。DBTypeEnum 定义了数据源类型,DBContextHolder 管理当前线程的数据源类型,DataSourceConfig 配置多个数据源和动态数据源切换,MyRoutingDataSource 实现数据源的动态路由,MyBatisConfig 将动态数据源应用到MyBatis框架中,DataSourceAop 切面根据方法上的注解选择数据源类型。这种组合使得我们可以在一个Spring Boot项目中实现数据库读写分离的功能。
其他文件说明
UserController
💧这个文件是一个Spring Boot的控制器类,名为 UserController。它处理来自前端的HTTP请求,调用 UserService 中的方法来处理业务逻辑,并返回相应的结果。
package com.lxr.demo.controller;
import com.lxr.demo.entity.UserEntity;
import com.lxr.demo.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Random;
@RestController
public class UserController {
@Autowired
UserService userService;
@RequestMapping("/listUser")
public List<UserEntity> listUser() {
List<UserEntity> users = userService.findAll();
return users;
}
@RequestMapping("/insertUser")
public void insertUser() {
UserEntity userEntity = new UserEntity();
Random random = new Random();
userEntity.setUser_id(random.nextInt());
userEntity.setAccount("22222");
userEntity.setNickname("lxrlxrlxr");
userEntity.setPassword("123");
userService.insertUser(userEntity);
}
}
UserEntity
💧一个普通的实体类,使用了lombok的@Data注解。
package com.lxr.demo.entity;
import lombok.Data;
@Data
public class UserEntity {
private Integer user_id;
private String account;
private String nickname;
private String password;
private String headimage_url;
private String introduce;
}
UserMapper
💧一个简单的dao层。
package com.lxr.demo.mapper;
import com.lxr.demo.entity.UserEntity;
import org.apache.ibatis.annotations.*;
import java.util.List;
/**
* Spring通过@Mapper注解实现动态代理,mybatis会自动创建Dao接口的实现类代理对象注入IOC容器进行管理,这样就不用编写Dao层的实现类
*/
@Mapper
public interface UserMapper {
@Select("SELECT * FROM user2")
List<UserEntity> findAll();
@Insert("insert into user2(user_id,account,nickname,password) values(#{user_id},#{account}, #{nickname}, #{password})")
int insert(UserEntity user);
// @Update("UPDATE user2 SET account=#{account},nickname=#{nickname} WHERE id =#{id}")
// void update(UserEntity user);
//
// @Delete("DELETE FROM user2 WHERE id =#{id}")
// void delete(Long id);
}
UserService
💧一个简单的Service层。
package com.lxr.demo.service;
import com.lxr.demo.entity.UserEntity;
import com.lxr.demo.mapper.UserMapper;
import com.lxr.demo.config.Master;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
UserMapper userMapper;
public List<UserEntity> findAll() {
return userMapper.findAll();
}
@Master
public int insertUser(UserEntity user) {
return userMapper.insert(user);
}
// void update(UserEntity user);
//
// void delete(Long id);
}
主启动类DemoApplication
package com.lxr.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.lxr.demo.mapper")
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class,args);
}
}
功能演示
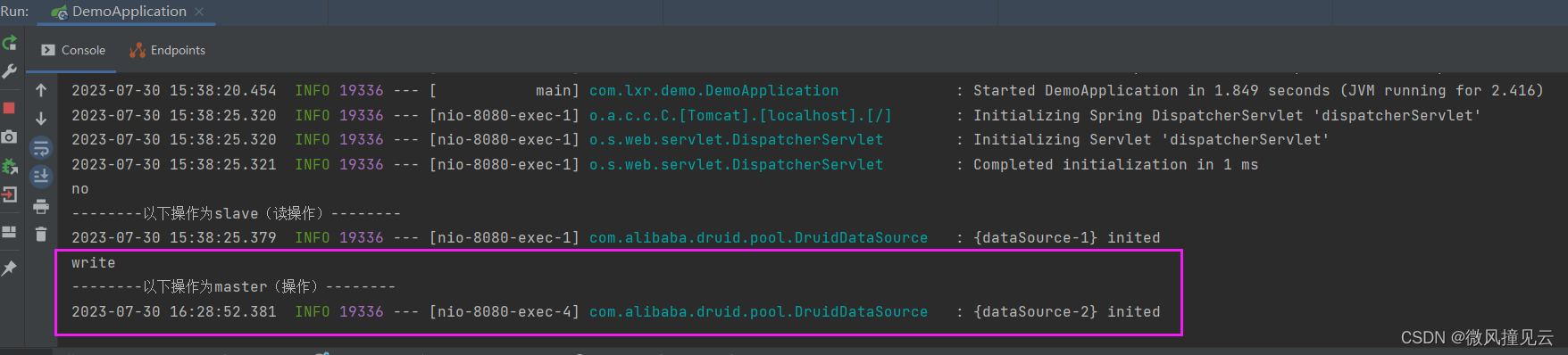
💧我们启动项目,打开浏览器或者postman等工具
💧分别访问:
从库的读操作 :http://localhost:8080/listUser


主库的写操作 :http://localhost:8080/insertUser

总结
💧通过本篇博客,我们学习了如何使用 Spring AOP 结合自定义注解和德鲁伊数据源来实现主从数据库切换和方法的读写分离。通过自定义注解 @Master 来区分主库还是从库,通过切点来区分读写方法,我们成功地将读写操作路由到不同的数据源,从而提高了应用程序的性能和可伸缩性。读写分离是一个重要的数据库优化策略,在实际的生产环境中非常有用。
💧希望本篇博客对您有所帮助,如果您有任何问题或建议,欢迎在评论区留言。谢谢阅读!

🐳结语
🐬初学一门技术时,总有些许的疑惑,别怕,它们是我们学习路上的点点繁星,帮助我们不断成长。
🐟积少成多,滴水成河。文章粗浅,希望对大家有帮助!
















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











