






目录
一.准备好三台虚拟机,我这里分别为master,slave1,slave2
搭建Hadoop集群所需包在 https://pan.baidu.com/s/1MGiwXCKgmlM54e7NafCC2w
提取码: tdqm
一.准备好三台虚拟机,我这里分别为master,slave1,slave2
二.配置hosts文件(三台虚拟机都需要)
[root@master ~]# vi /etc/hosts
三.ssh免密登录(三台虚拟机都需要)
1.生成密钥
[root@master ~]# ssh-keygen -t rsa (按四次回车)2.将本机密钥文件复制给其他虚拟机
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id slave1
[root@master ~]# ssh-copy-id slave2
3.测试免密是否成功
从master登录到slave1,登录成功即免密成功。exit退出
[root@master ~]# ssh slave1
其他两台虚拟机同上
三.安装JDK(三台都需要)
1.解压jdk
[root@master ~]# tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/servers/2.改名
[root@master ~]# mv /opt/servers/jdk1.8.0_212/ /opt/servers/java
3.配置环境变量
3.1.添加坏境变量
vi /etc/profile
#在文件末尾添加
export JAVA_HOME=/opt/servers/java
export PATH=$PATH:$JAVA_HOME/bin3.2.使环境变量生效
[root@master ~]# source /etc/profile 3.3查看是否配置成功
[root@master ~]# java -version
4.将JDK分发至slave1,slave2
[root@master ~]# scp -r /opt/servers/java/ slave1:/opt/servers/
[root@master ~]# scp -r /opt/servers/java/ slave2:/opt/servers/5.将环境变量分发至slave1,slave2且生效
[root@master ~]# scp -r /etc/profile slave1:/etc/profile
[root@master ~]# scp -r /etc/profile slave2:/etc/profile
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile四.配置Hadoop集群
1.解压hadoop安装包(我使用的版本是3.1.3)
[root@master ~]# tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/servers/2.改名
[root@master ~]# mv /opt/servers/hadoop-3.1.3/ /opt/servers/hadoop
3.配置环境变量且生效
[root@master ~]# vi /etc/profile
export HADOOP_HOME=/opt/servers/hadoop
export HADOOP_CONF_DIR=/opt/servers/hadoop/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin[root@master ~]# source /etc/profile4.查看是否配置成功
[root@master ~]# hadoop version 
5.修改hadoop配置文件
hadoop的配置文件都存放在hadoop目录下的/etc/hadoop,需要修改以下六个文件
[root@master ~]# cd /opt/servers/hadoop/etc/hadoop/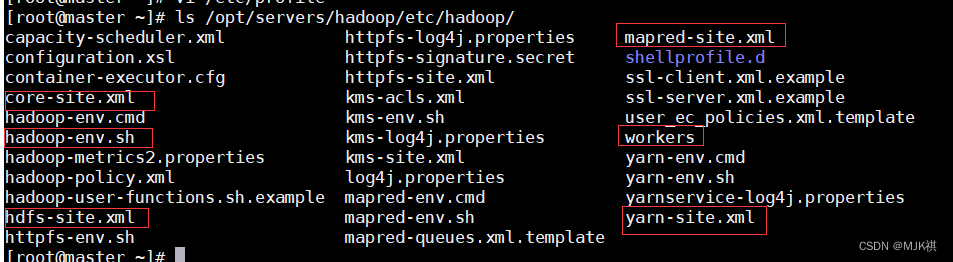
5.1 修改hadoop-env.sh文件
vi ./hadoop-env.sh
#找到相应位置,添加java路径
export JAVA_HOME=/opt/servers/java
5.2 修改core-site.xml文件
vi ./core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/servers/hadoop/tmp</value>
</property>
</configuration>
5.3 修改hdfs-site.xml文件
vi ./hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>5.4 修改mapred-site.xml文件
vi ./mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.5 修改yarn-site.xml文件
vi ./yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.6 修改workers文件
vi ./workers
master
slave1
slave2
6.将hadoop分发至slave1,slave2
[root@master servers]# scp -r /opt/servers/hadoop/ slave1:/opt/servers/
[root@master servers]# scp -r /opt/servers/hadoop/ slave2:/opt/servers/
7.将环境变量分发至slave1,slave2,并生效
[root@master servers]# scp -r /etc/profile slave1:/etc/profile
profile 100% 2112 2.4MB/s 00:00
[root@master servers]# scp -r /etc/profile slave2:/etc/profile
profile 100% 2112 3.6MB/s 00:00
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile
8.在master节点格式化
[root@master ~]# hdfs namenode -format

这样即格式化成功
9.启动hadoop集群
start-all.sh如报以下错误,在环境变量添加以下内容:(添加完成后需分发至slave1,slave2且生效,分发,生效命令上面有)
vi /etc/profile
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

然后再启动,启动后查看各节点进程
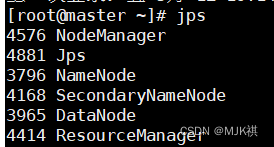
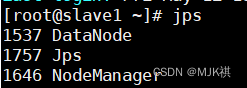

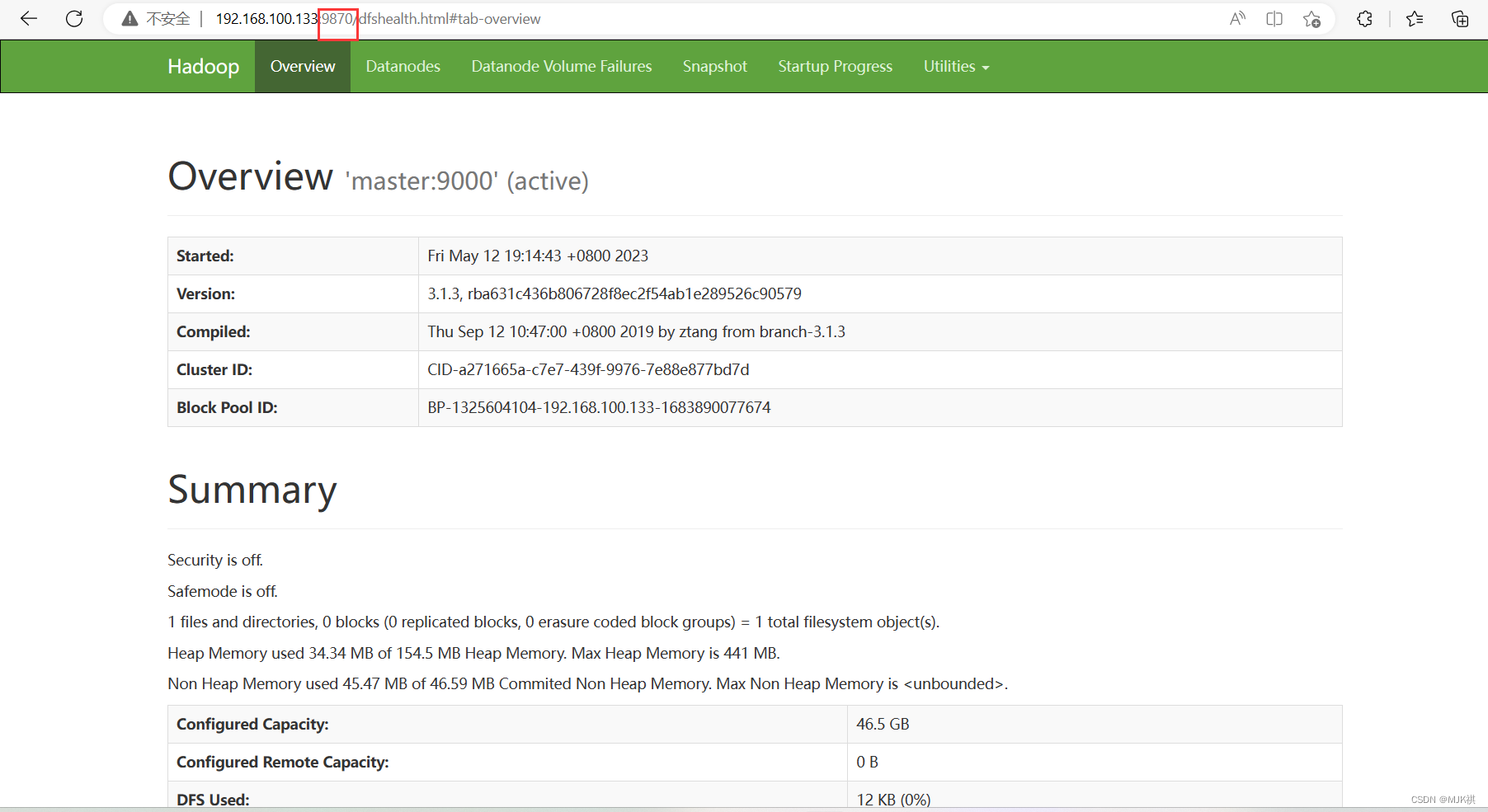
10. 查看HDFS集群状态 (http://主节点IP:9870)
11.查看Yarn集群状态 (http://主节点IP:8088)
















 2588
2588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









