






小白学习记录
昨天在练sql的时候,看到这样一个题目

我的代码是这个样子的
set @i:=0;
set @j:=0;
SELECT tt1.user_id,tt1.login_time ,TIMEDIFF(tt2.login_time,tt1.login_time) as jiange FROM
(
SELECT t1.*
,@i := @i + 1 as rank
FROM(
SELECT user_id
,login_time
FROM login_info GROUP BY user_id,login_time) t1 )tt1
JOIN
(
SELECT t2.*
,@j := @j + 1 as rank
FROM(
SELECT user_id
,login_time
FROM login_info GROUP BY user_id,login_time) t2 )tt2
ON tt1.user_id=tt2.user_id
WHERE tt2.rank-tt1.rank = 1 AND tt2.user_id=tt1.user_id先说一下我的思路:先将group by user_id,login_time,再定义一个变量,从上到下排序叫做rank,和一张一样的表join一下就成了这样
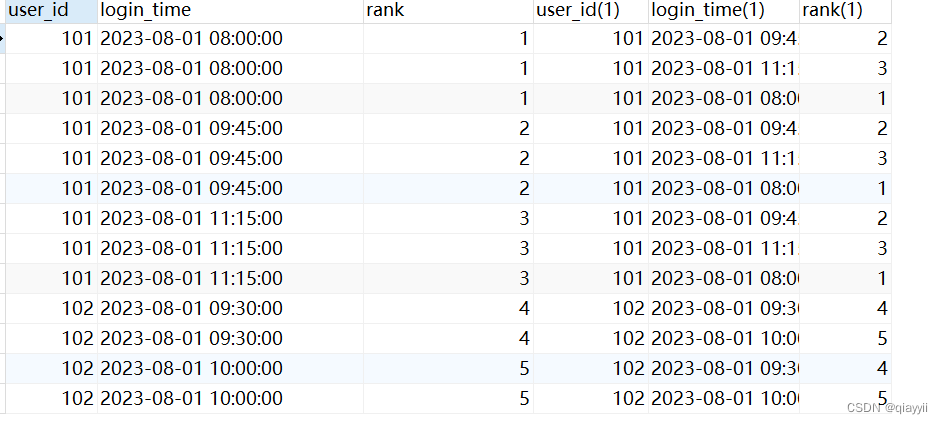
然后再套一个select把两张表里面id相同,rank值差1的做差(timediff)就可以把同一个人的登录时间差给求出来了,结果如下:

但我觉得这个sql写的好傻,暂时又想不到其他可以优化的方法,我就去问了我的老师,
老师给我的代码时这个样子的
select user_id
,login_time
,(select max(login_time)
from login_info t2
where t1.login_time>t2.login_time and t1.user_id=t2.user_id) as prev_time
from login_info t1;我的跟这个对比,简直依托答辩,这个代码运行出来是这个样子的

说一下老师的思路吧
要求登录时间差,在表的后面接上一个离该条记录时间最近的一条时间,那怎么求呢,比如第五条数据 11:15:00 ,只要求出所有比他小的时间中的最大值,不就是离他最近的时间了吗,当然user_id要 相同。
简简单单的思路怎么就没想到呢,起司沃勒。














 2963
2963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









