







7-1在小批量梯度下降中,试分析为什么学习率要和批量大小成正比.

主要是为了降低批量过小带来的不稳定性风险,防止它更新时前往偏离方向太远,因为当批量越大时,梯度方向更具有代表性,随机梯度下降偏离正常方向的概率要更低,因此可以调整更大的学习率,批量越小时正相反,选取的梯度方向更容易偏离目标方向,因此选用较小的学习率来限制其更新步骤。
7-2在Adam算法中,说明指数加权平均的偏差修正的合理性(即公式(7.27)和公式(7.28)).
公式7.27:
M
t
^
=
M
t
1
−
β
1
t
\hat{M_t} = \frac{M_t}{1-\beta_1^t}
Mt^=1−β1tMt
公式7.28:
G
t
^
=
G
t
1
−
β
2
t
\hat{G_t}= \frac{G_t}{1-\beta_2^t}
Gt^=1−β2tGt
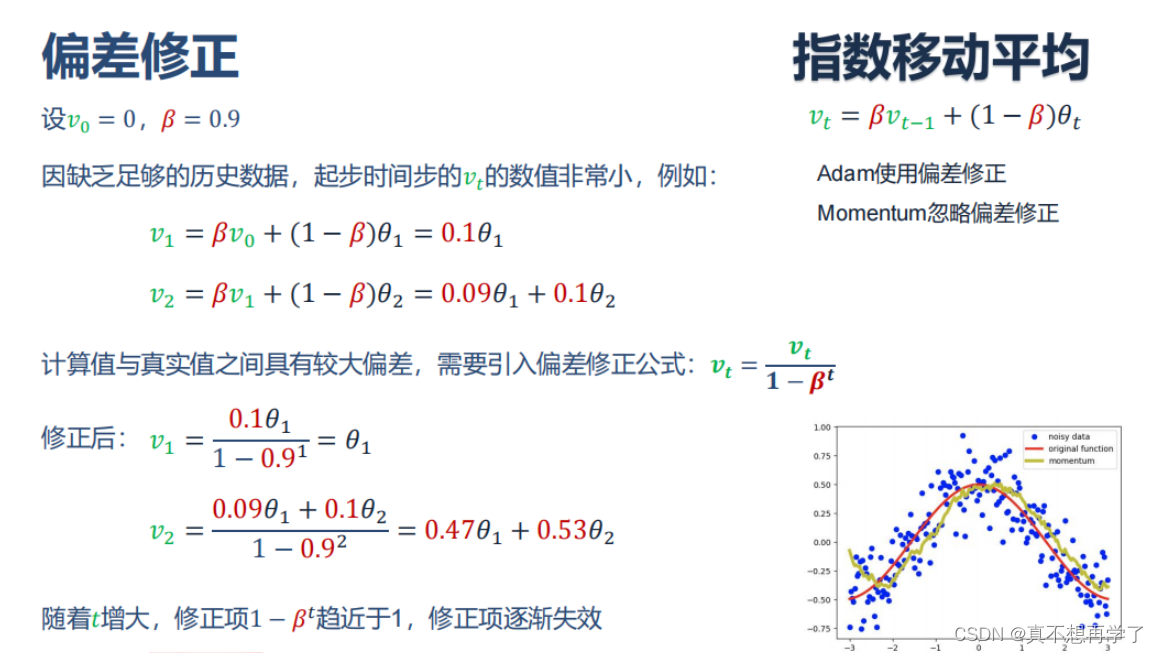
这两个是偏差修正公式,它是为了调整初始的v、m值而设计的,因为一开始由于v、m的值都来自于他们对应的指数移动平均,但是起步时的值很小(见下图),因此要通过偏差修正将其值放大,从而为初始的若干个步骤提供较大的‘动量’。在实际意义上,偏差修正就是指数移动平均的一次优化,优化位置在出发位置附近,并且随着步骤的增多而逐渐减弱其修正的影响。
7-9证明在标准的随机梯度下降中,权重衰减正则化和l2正则化的效果相同.并分析这一结论在动量法和Adam算法中是否依然成立.
以λ为衰减因子,给出了权值衰减方程。
权重衰减(正则化):
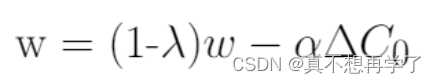
L2正则化:
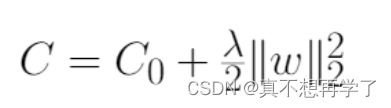
求
Δ
C
\Delta C
ΔC并据此计算SGD更新过程
Δ
C
=
Δ
C
0
+
λ
w
w
=
w
−
α
Δ
C
w
=
w
−
α
(
Δ
C
0
+
λ
w
)
w
=
w
−
α
Δ
C
0
−
α
λ
w
w
=
(
1
−
α
λ
)
w
−
α
Δ
C
0
(
1
)
\Delta C=\Delta C_0+\lambda w \\ w=w-\alpha\Delta C\\ w=w-\alpha(\Delta C_0+\lambda w)\\ w=w-\alpha\Delta C_0-\alpha\lambda w\\ w=(1-\alpha \lambda)w-\alpha\Delta C_0 (1)
ΔC=ΔC0+λww=w−αΔCw=w−α(ΔC0+λw)w=w−αΔC0−αλww=(1−αλ)w−αΔC0(1)
对比权重衰减,
w
=
(
1
−
λ
)
w
−
α
Δ
C
0
(
2
)
w=(1- \lambda)w-\alpha\Delta C_0 (2)
w=(1−λ)w−αΔC0(2)
发现它比权重衰减在w前面多乘了一个
α
\alpha
α,其计算方法实际上效果和SGD的权重衰减效果是一致的。
但是这在动量法和Adam中是不一致的,因为这两个算法还利用到了移动平均的思想,利用到了前几个状态的梯度方向,总体上要复杂很多,因此并不是简单的SGD算法,自然也就不能适合L2正则化了。
总结:分析了几个算法细节上的问题,对这几个算法的李姐进一步加深了,同时建立起了一些知识体系,找到了一些知识方面的联系。
思维导图:















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









