








一.什么是HTTP协议

前面已经介绍了计算机网络的一些基本原理,而我前面的介绍应用层就是需要我们自己"根据具体的需求场景,来设计并实现应用层协议",但是又由于程序员的圈子里每个人的水平都是不一样的,因此设计出来的协议也是有好有坏的,因此圈子里面的大佬们就发明了一些很好用的协议,直接供大家使用,这样即使一个很菜的程序员也可以使用很好的应用层协议, 而HTTP协议就是其中一个的典型代表,而且HTTP虽然是已经设计好的,但是自身的可扩展性是非常好的,程序员是可以根据实际需要,让程序员传输自定义的数据信息~~ 那么HTTP具体用在哪呢?其实我们基本上天天都在使用,只要你打开浏览器或者打开一个手机APP,随便加载一些数据,这个时候你大概率就已经使用到了HTTP!!
二.HTTP的协议格式

想要了解一个协议,首先就需要了解一下其协议格式(数据具体是怎么组织的),像前面所介绍过的UDP/TCP/IP这些协议都是属于"二进制"的协议,想要理解就必须理解其二级制的bit位,而这对于人来说其实是非常不友好的,而HTTP则是一个文本格式的协议,因此就不需要去理解具体的二进制为,而只需要理解文本的格式就可以了
那如何才能看到HTTP的报文格式呢?
其实可以借助一些"抓包工具(其实就是一个第三方的程序,在网络通信过程中类似于"代理"一样,请求和响应都是要路过代理的,因此代理就可以在传输过程中获得到其具体的请求和响应信息)"来获得到具体的HTTP交互过程中的请求和响应,这里我就具体介绍一个我经常使用的抓包工具Fiddler
1.Fiddler

具体下载路径:Fiddler
使用这个就可以了
而里面的具体内容如下:
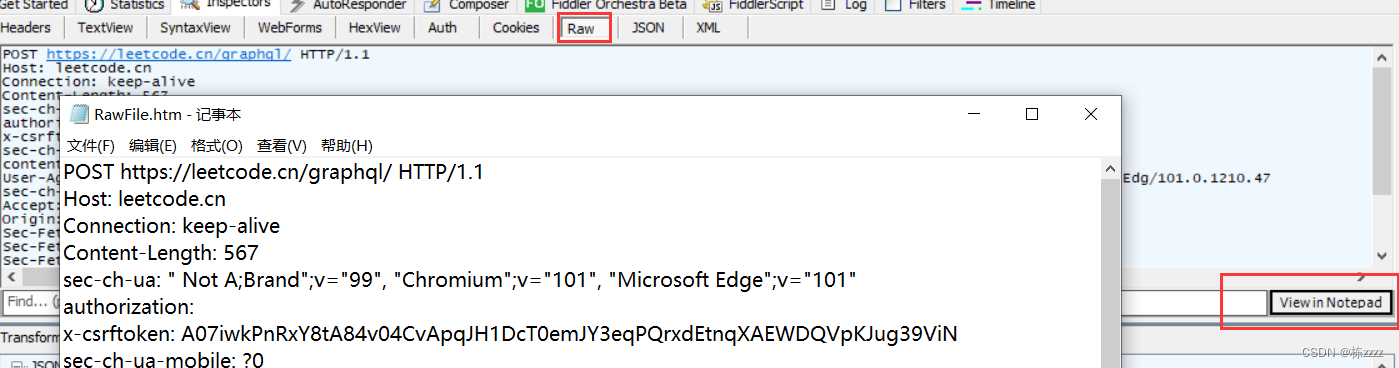
想要查看其具体的内容可以这样做:
这样通过记事本的格式就可以查看其具体内容了,
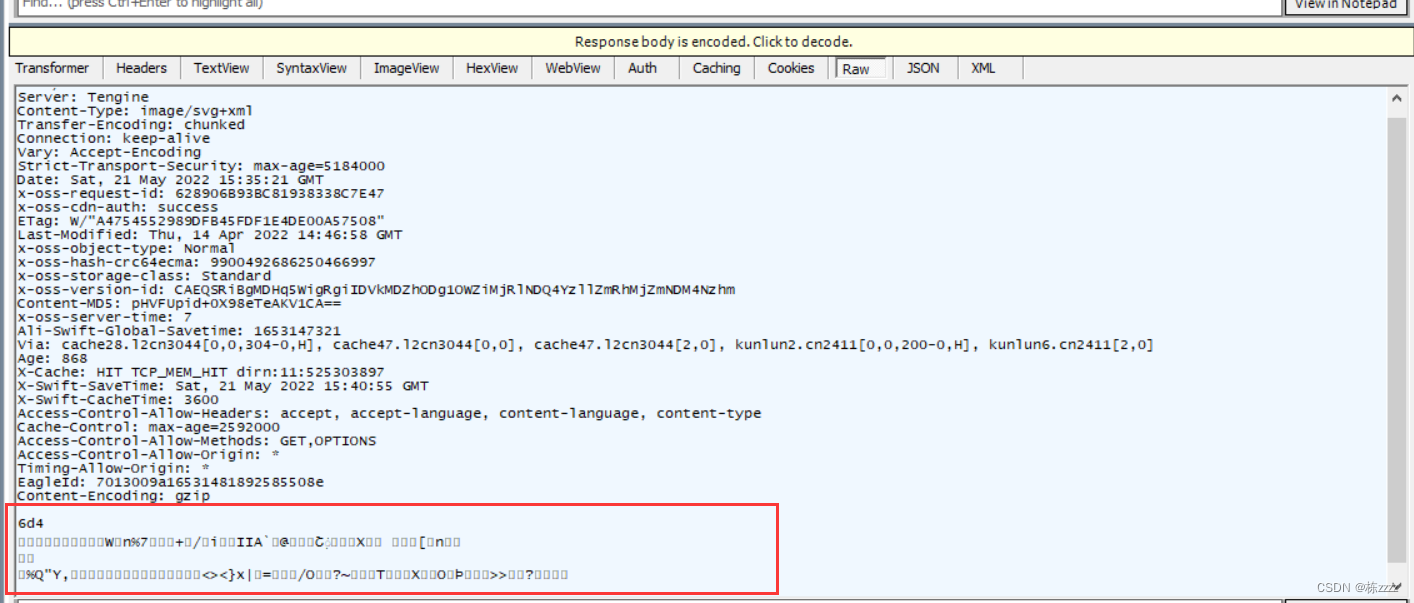
而针对响应有可能会出现这样的情况:
会出现乱码的现象,这是怎么回事呢,这其实是内容过多,而压缩过后的结果(因为内容过多的话,传输速率会下降,带宽也会占的更多,所以需要压缩),而想要查看具体的内容只要点击上面的
这一行字就可以解决乱码的问题了!!!


下面我再具体介绍其报文的具体格式
2.报文格式
首先来看一下HTTP的请求格式:
2.1请求

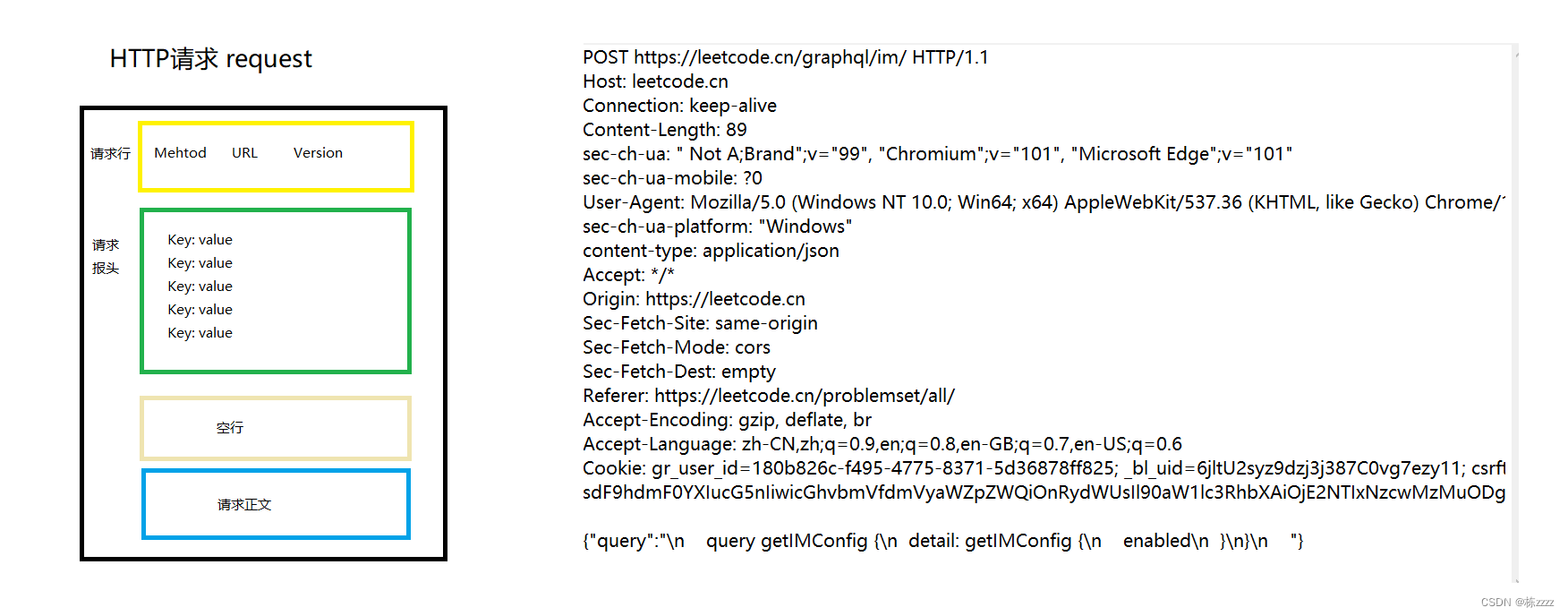
请求一般分成4个部分,下面来具体介绍一下
①请求行(首行)
首行一般包括三个部分:
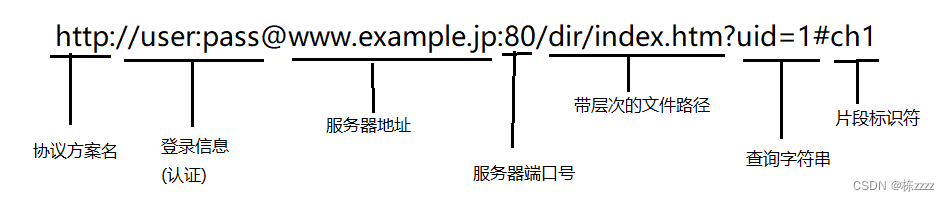
- HTTP的方法:方法就是描述了这个请求想干啥,HTTP协议的方法是非常多的,而一般常用的就是POST和GET,POST的意思就是向服务器提交/发送要被处理的数据,GET意思就是从服务器获得到的数据;
HTTP中引入这些方法,初衷就是根据不同的"语义"来使用不同的方法,但是随着时间的推移,使用就走形了,现在基本都是使用GET/POST,基本不考虑语义的事情,正因如此,也导致了多种HTTP方法之间的界限就越来越模糊了,而GET和POST的区别是什么呢?根据上面的现状可以得到其实GET和POST是没有本质区别的!!!具体来说,相当于GET能使用的场景,也能替换成POST,POST使用的场景,也能替换成GET~
但是细节上,还是有一些区别的,下面具体探讨一下其区别:
语义:GET通常用来取数据,POST通常用来上传数据,现状是GET也经常上传数据,POST也经常用来取数据
body:通常情况下,GET是没用body的,GET通过query string向服务器传递数据;通常情况下,POST是有body的,POST通过body向服务器传递数据,但是POST没有query string;而这种情况不是强制性的区别,只是习惯用法,这个习惯可以遵守,也可以不遵守,如果就像让GET有body(自己构造一个带有body的GET请求),或者让POST带有query string,也是完全可以的
幂等:GET请求一般是幂等的(每次相同的输入能得到的输出结果是确定的,相反不幂等就是相同的输入不能得到确定的输出结果),而POST一般是不幂等的(也不是强制要求而是建议)
缓存:GET可以被缓存,POST不能被缓存,缓存就是提前把结果记住,就例如上面的是幂等的话,记住的结果就是有用的,就可以节省下次访问的开销,如果不是幂等的,就不应该去记~
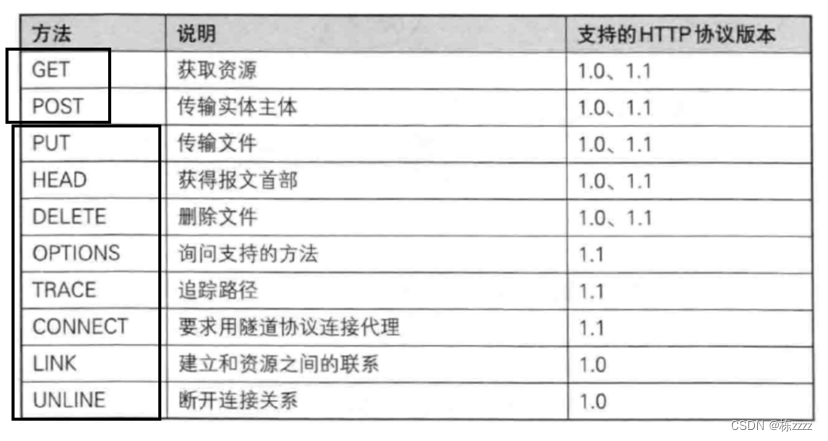
- URL,描述了访问的网络上的具体资源的位置,其含义就是"网络上唯一资源的地址符"(既要明确主机是啥,又要明确主机上的哪个资源) 类似于https://mp.csdn.net/就是一个URL,下面是一个URL的基本模板:
协议方案名:描述了当前的URL是给哪个协议来使用的,这里的http://就是给HTTP协议使用的,https://就是给HTTPS使用的~
登录信息:这个部分现在很少会用到,以前会使用到,会在这里体现用户名和密码
服务器地址:表示当前要访问的主机是啥,这里可以是一个IP地址,也可以是一个域名这两个是等价的,可以通过DNS域名解析来转换
服务器端口号:表示当前要访问的主机上的哪个应用程序,而端口号大部分情况下是省略的,省略的时候不是说没有端口号,而是浏览器会自动赋予一个默认值,对于http开头的URL,就会使用80端口作为默认值,对于https开头的URL,就会使用443端口作为默认值
带层次的文件路径:文件路径描述了当前要访问的服务器的资源是啥,虽然请求的URL中,写的是一个文件路径,但是不一定服务器上就真存在一个对应的文件,这个文件可能是一个真实的,在磁盘上存在的文件,也可能是一个虚拟的,由服务器代码,构造出的一个动态的数据…
查询字符串:本质上是浏览器/客户端给服务器传递的自定义的信息,相当于对获取的资源提出了进一步的要求(上面的地址,端口和文件路径就描述了网络中的一个具体资源,但在这个基础上,还可以携带一些其他的要求),而查询字符串的具体内容(插下一步字符串和文件路径通过?隔开),本质上也会是键值对结构的(每个键值对通过&隔开,键和值通过=连接),而且完全是程序员自己定义的~~
片段标识:描述了当前html页面中的哪一个具体的子部分,能够控制浏览器滚动到相关位置
补充一下,URL encode/decode,当query string中如果包含了特殊字符(/ : ? &…这些符号都是在URL中有特殊含义的,而且中文也算是特殊字符,一旦query string中包含了这类特殊符号,就可能导致URL被解析失败),就需要对特殊字符进行转义,而这个转义的过程,就叫做url encode,反之,将转义后的内容还原回来,就叫做url decode,例如在搜狗中搜索c++的时候,
可以看到URL中的query string里面,+就被url encode转移为了%2B,而这个2B其实是字符+的ascii的十六进制表示,因此url encode的规则就是把要转义的内容的ascii码值用十六进制表示,同时前面加上%,每一个特殊字符都这样处理!!

- 版本号,HTTP/1.1表示当前使用的HTTP的版本号是1.1(1.1也是当下最主流的版本,还有可能是1.0/2/3)
②请求头(header)
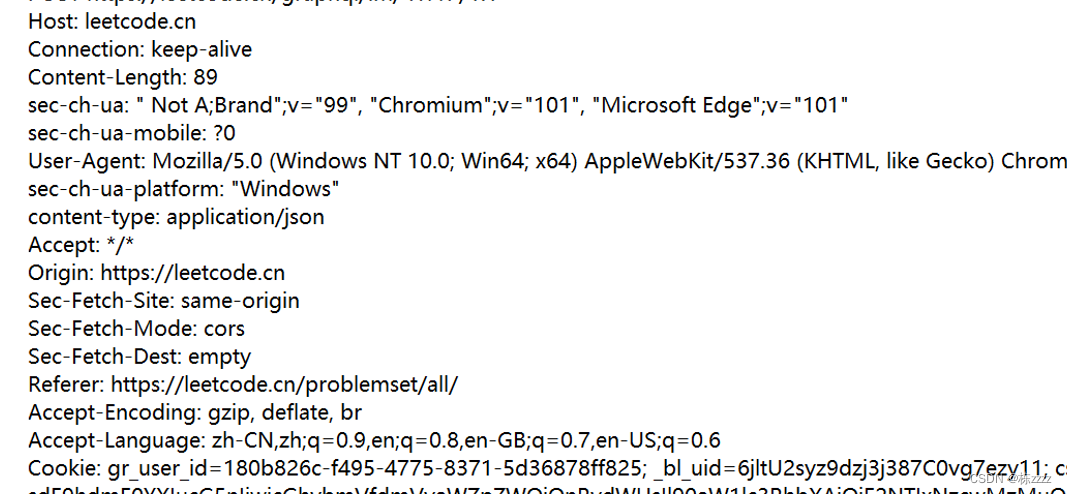
请求头里面包含了很多行,每一行都是一个键值对,键和值之间使用冒号加空格隔开,这里的键值对个数是不固定的,而且不同的键值对表示的含义也是不同的,这里介绍一些简单常见的键值对
Host就表示服务器主机的地址和端口(后面的域名和IP是一样的,端口是默认的)
一般body中会有这两个键值对:
Content-Length就表示请求中的body的长度(HTTP也是基于TCP的协议,因此就会存在一个面向字节流的问题:粘包问题,因此这就需要合理的设计应用层协议,明确包和包之间的边界,而HTTP协议在这也是有体现的1.使用分隔符(也就是空行),2.使用这里给出的长度,通过这两个搭配着使用就可以明确其界限了(如果是若干个GET请求,放到了TCP接收缓冲区内只需要通过空行就可以分隔开来,而如果是若干个POST请求的话,当放到TCP接收缓冲区内,在应用程序取请求的时候就要搭配着空行和这里给出的长度来分割数据,从而不产生粘包问题))
content-type就表示请求的body的数据格式(一般常用的数据格式有三种:application/x-www-form-urlencoded(提交数据的格式,这个格式和query string是一样的),multipart/form-data:form(form表单提交数据的格式),application/json(数据为json格式))
User-Agent:简称UA,可以说是一个"自报家门"的作用,Mozilla表示开发浏览器的组织,Windows NT 10.0; Win64; x64表示当前电脑的配置(操作系统的版本win10,64位的系统),在后面的Chrom和Safari和Edg其实都代表浏览器,这样的一组信息就可以让浏览器发送的请求中带有自己的各种信息,然后服务器就可以通过UA中的信息来确定应该返回什么样的结果(手机还是电脑等一系列满足条件的结果)
Referer:这就表示当前的页面是从哪个页面跳转过来的(Referer不一定会有,通过地址栏直接搜索过来的可能就是没有Referer的)
Cookie:其实是浏览器给页面提供的一种可持久化存储(数据不会因为程序重启或者主机的重启而丢失数据,这是写到磁盘里面的)信息的机制;
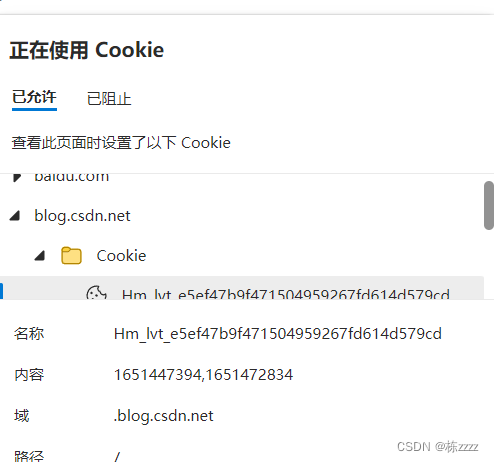
一般浏览器为了安全起见,是不会让页面的js访问到用户电脑的系统文件的(万一某个页面存在恶意代码,一不小心触发这个恶意代码,可能会将用户所有的信息都删除掉),但是这样的安全机制就不能保证一些数据的持久化存储,例如用户的身份信息,一般用户登录上一个页面之后,可能会不断的跳转到其他页面,如果不保存用户的信息的话,每次跳转都需要用户登录信息,用户肯定是不满意的,因此这样的服务器返回的用户信息就需要浏览器保存下来,保存到一个特定的位置上,后续再访问同一个网站的其他页面的时候,服务器就可以自动识别了,就不需要每次都登录了,而这个特定的位置是有很多种不同的形式的,而Cookie就是其中一种比较古老,也比较经典的形式,现在的浏览器也会支持一些其他的形式;Cookie的具体组织格式:先按照域名来组织,然后每个域名都分配一个空间~~在这个空间里面就会根据键值对的方式组织数据
这里的名称和内容就是key和value的形式
那Cookie上面的数据是怎么得到的?
其实是服务器返回给客户端的,服务器完成身份认证之后,在响应头里面就包含了这样的Set-Cookie这样的信息,这里面就包含了Cookie的数据;
简单举个例子:类似于去医院看病,第一件事就是挂号,挂完号就会发一个就诊卡,这个就诊卡上面就存储了一些你自己的基本信息(姓名,身份证号码,电话…),而不论去哪个就诊室,医生都会先刷一下你的就诊卡,这个就诊卡上面就会包含你的基本信息,而且还可以查到之前的病例,然后医生就可以根据你之前的病例再搭配上你的问题,然后再诊断,然后解决你的问题…而这里的就诊卡其实就是Cookie,但其实就诊卡上并不是存储了用户的所有信息,毕竟卡片那么小也容易丢失,也存储不了多少信息,更准确的说这个卡上只存储一个身份标识然后通过身份标识就可以得到这些具体的信息,真正的信息是存储在医院的服务器上的,而这些关键信息,存储在服务器上,将这个东西称为"session",也就是会话(记录历史关键信息),每个用户一个会话,每个会话一个会话标识,然后Cookie(就诊卡)上就存储了这个会话标识(sessionId),而且这个Cookie一般都是程序员自己设定的,因此也是可以存储一些其他的信息的



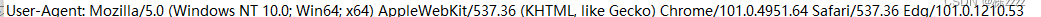


③空行
空行就相当于请求头的结束标记,类似于链表的null就结束了
④请求正文
这个内容不一定有,如果有的话,空行后面的内容就是请求正文了,这个主要就是和上面介绍的content-type一样,这里就不再介绍了
2.2 响应


响应也是分成四个部分:
①首行
首行包含了三个部分
- 版本号:HTTP1.1
- 200 状态码,描述了这个响应式成功的还是失败的,以及不同的状态码,描述了失败的原因,这里介绍一些常见的状态码:
200 OK:浏览器很顺利的就或得到内容了,成功了
404 Not Found:表示要访问的资源不存在,没找到
403 Forbidden:虽然资源存在,但是我们没有权限使用,就会出现403;
405 Method Not Allowed:对方的服务器不支持你使用的HTTP方法就会出现405;
500 Internal Server Error:表示服务器出问题了,服务器出现bug了;
504 Gateway Timeout:表示服务器太繁忙了,出问题了;
302 Move temporarily:表示重定向,这个很重要,就类似于电话的呼叫转移一样
而在302重定向的响应头里面会包含一个Location,这就表示接下来要跳转的地址,这就是要重新跳转的页面;
总结一下:状态码也是有很多的,一方面能记住一些常见的状态码就可以,另一方面可以明确状态码的几个大分类:1开头的表示消息,2开头的都属于成功了(200),3开头的都数距重定向(301,302),4开头的都是客户端出现错误了(404,403),5开头的都是服务器出错误了(500,504),这里其实还有一个特殊的状态码418,这个就表示是一个彩蛋,了解一下就可以了;- OK 状态描述码:通过一个/一组简单的单词,来描述当前状态码的含义


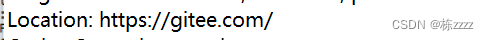
②响应头
响应头里面同样也是键值对结构,每个键值对占一行,每个键和值用:空格隔开,这里的键值对个数是不固定的,而且不同的键值对表示的含义也是不同的
③空行
表示响应头的结束标记
④响应正文
服务器返回给客户端的具体数据,这里面可能有各种不同的格式,其中最常见的就是html格式,另外还有css格式,js格式,json格式!
















 31
31











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











