







下面是我没有修改的代码
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
with open("mybaidu.html", mode="w") as f:
f.write(resp.read().decode("utf-8"))运行后出现了乱码
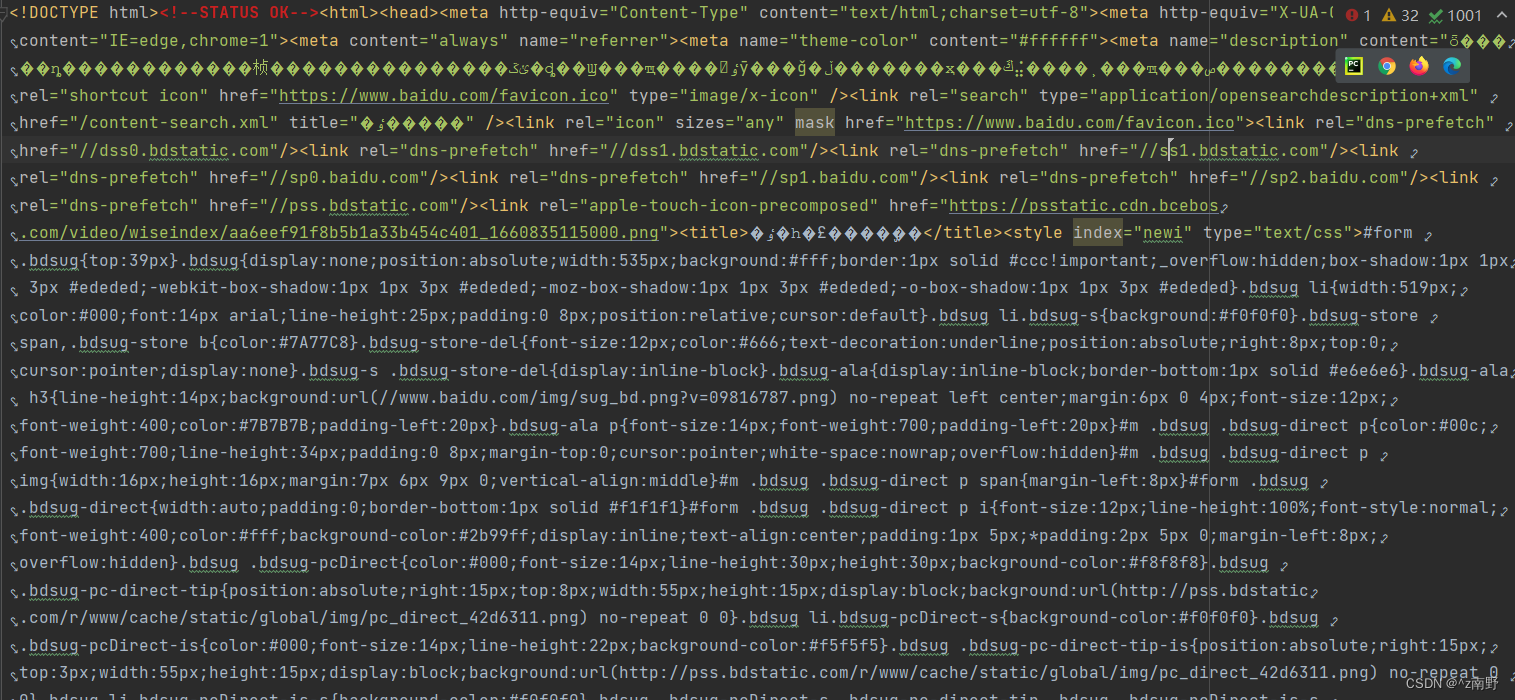
解决办法,使用UTF-8编码方式来处理字符串或文件的读写操作。
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
# encoding="utf-8"表示将使用UTF-8编码方式来处理字符串或文件的读写操作。
# decode("utf-8")将这些字节字符串解码为Unicode字符串,使用的编码方式是UTF-8
with open("mybaidu.html", mode="w", encoding="utf-8") as f:
f.write(resp.read().decode("utf-8")) 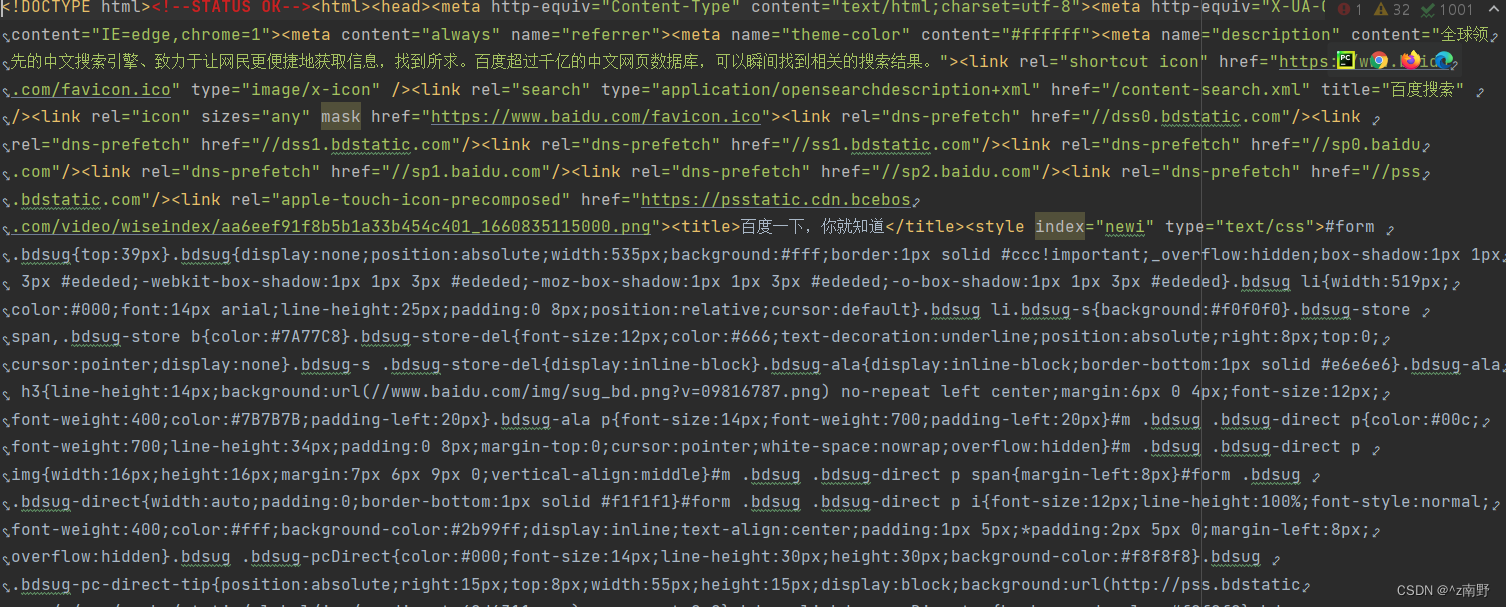
嘿嘿,美好的一天又要结束了,愿自己保持热爱,淦!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











