






 本文详细描述了如何在CentOS7环境中搭建Hadoop集群,包括虚拟机安装、网络配置、环境变量设置、HDFS和YARN配置,以及SSH免密登录的设置过程。
本文详细描述了如何在CentOS7环境中搭建Hadoop集群,包括虚拟机安装、网络配置、环境变量设置、HDFS和YARN配置,以及SSH免密登录的设置过程。
Hadoop集群搭建
需要的镜像和文件
链接: https://pan.baidu.com/s/1NbTakX0A8lhKn4H1NfWEWw 提取码: ZjyL 复制这段内容后打开百度网盘App,操作更方便哦
1,安装虚拟机
安装位置用三个文件夹来分开(因为每台虚拟机要放在不同位置)
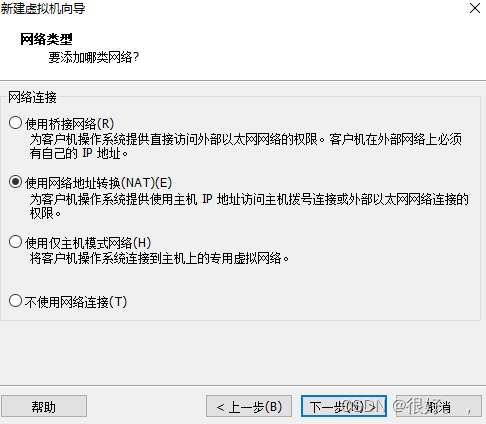

点击编辑虚拟机设置中cd 选择镜像

用上键选择安装Centos7

下一步

点击黄色感叹号这个

单击这个硬盘(自动分区) Done;

设置root用户密码

输入123456
再次输入 点Done(双击因为他会报密码太简单,你是root用户直接点两下确认);

重启打开虚拟机root
加刚才设置的密码

输入配置网络的命令;

进去以后修改成这样(使用 i 进入插入模式,输完以后英文冒号wq保存退出);

重启网络的命令

修改映射文件(ip地址加主机名)

修改映射文件

systemctl stop firewalld.service 关闭防火墙
systemctl disable firewalld.service 永久关闭防火墙
systemctl status firewalld.service 检查是否关闭防火墙

修改主机名的命令 bash刷新;

关闭虚拟机然后克隆两台虚拟机;

创建完整克隆两台命名分别为node5和node6;


使用命令修改node5的网络
ip地址保持与映射hosts中一致

别忘记重启网络

node6和node5同样之修改ip地址
重启网络

node5和node6的主机名修改与映射保持一致

至此虚拟机安装结束
虚拟机免密设置
免密报错的话看这里
或者就是虚拟机网络配置有问题检查检查;
链接: 虚拟机连接不上xshell
选择全部输入;

免密的操作基本就是三台虚拟机相互传文件的时候不需要输入命令
ssh-copy-id node4 将node4,5,6的密钥拷贝到公钥上(可以写node4 的ip地址,也可以是主机名),中间出现y/n或者yes/no选择yes
发送到所有会话后会向三个虚拟机中发送相同命令
ssh-keygen 可以显示公钥回车三下出现公钥
ssh-copy-id node5
ssh-copy-id node6
ssh node5 可以显示检查是否能查看到想要的主机上(exit)为退出命令

虚拟机环境搭建
在全部的虚拟机下要先切换到opt目录在opt下创建module(解压软件包的地方)software(放软件的地方)

关闭所有对话框选当前对话

切换到software目录下 cd software
在这里使用xftp软件。绿色的软件

上传hadoop和jdk 压缩文件(hadoop版本不同得改配置文件)

java 和hadoop解压到module目录下


新打开ndoe4 的窗口 pwd命令查看路径
复制路径粘到路径下

vi /etc/profile编辑系统环境变量

第一个为root用户需要的设置
第二个是java的环境变量

source /etc/profile 保存环境变量 使用java-version来查看java版本(检查是否安装好)

hadoop和上面步骤一样,环境变量有些不同.
使用hadoop命令来查看是否安装好


安装好的hadoop

配置文件(6步)
cd /opt/module/hadoop/etc/hadoop

vi core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/tmp</value>
</property>
<property>
<!-- 指定集群的文件系统类型:分布式文件系统 namenode在那个集群上-->
<name>fs.defaultFS</name>
<value>hdfs://node4:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<!-- 指定secondarynamenode 在那个主机上 -->
<property>
<name>dfs.secondary.http.address</name>
<value>node5:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node4</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
vi workers
node4
node5
node6
vi hadoop-env.sh 删掉#号复制java路径

将node5,6 传输hadoop和java


在module目录下的两个文件

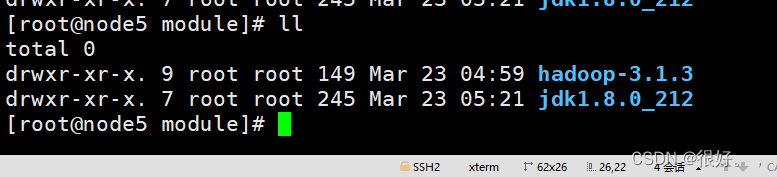
再传node4环境变量给node5 和node6
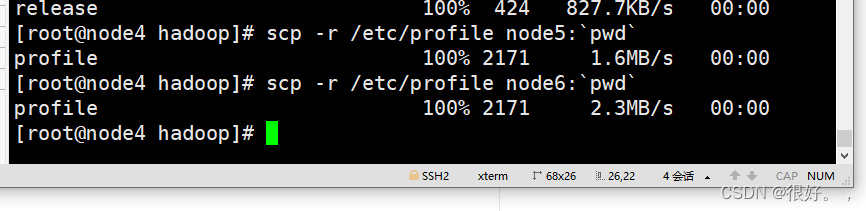
到node5 node6 刷新环境变量检查是否正确;

使用 hdfs namenode -format 来格式化集群
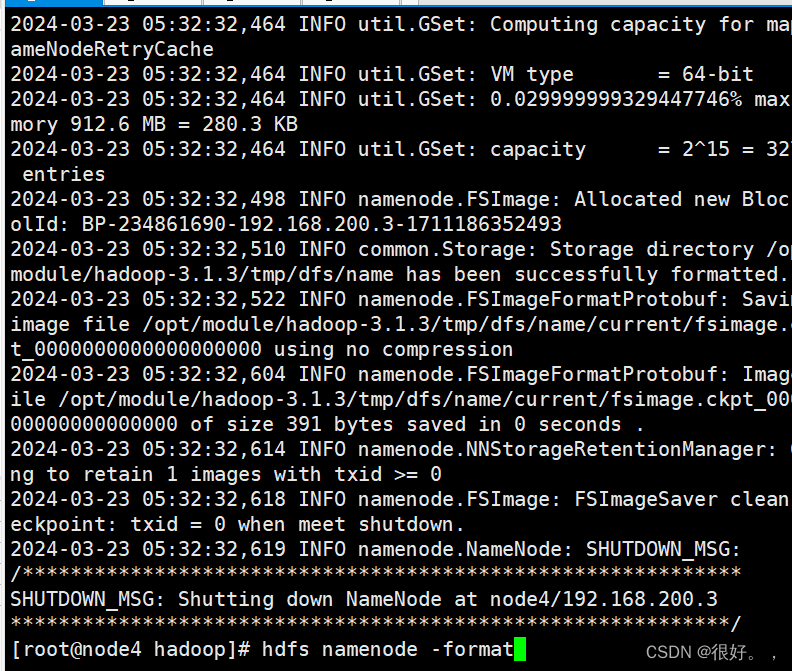
start-all.sh
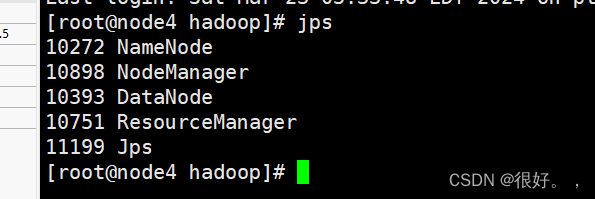
HDFS 守护进程是 NameNode、SecondaryNameNode 和 DataNode。
YARN 守护进程是 ResourceManager、NodeManager
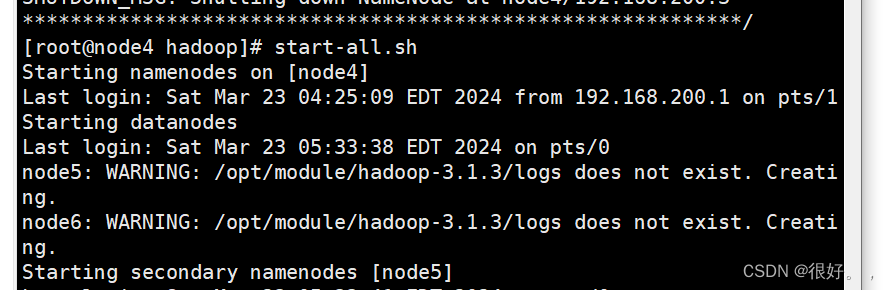
jps
查看节点
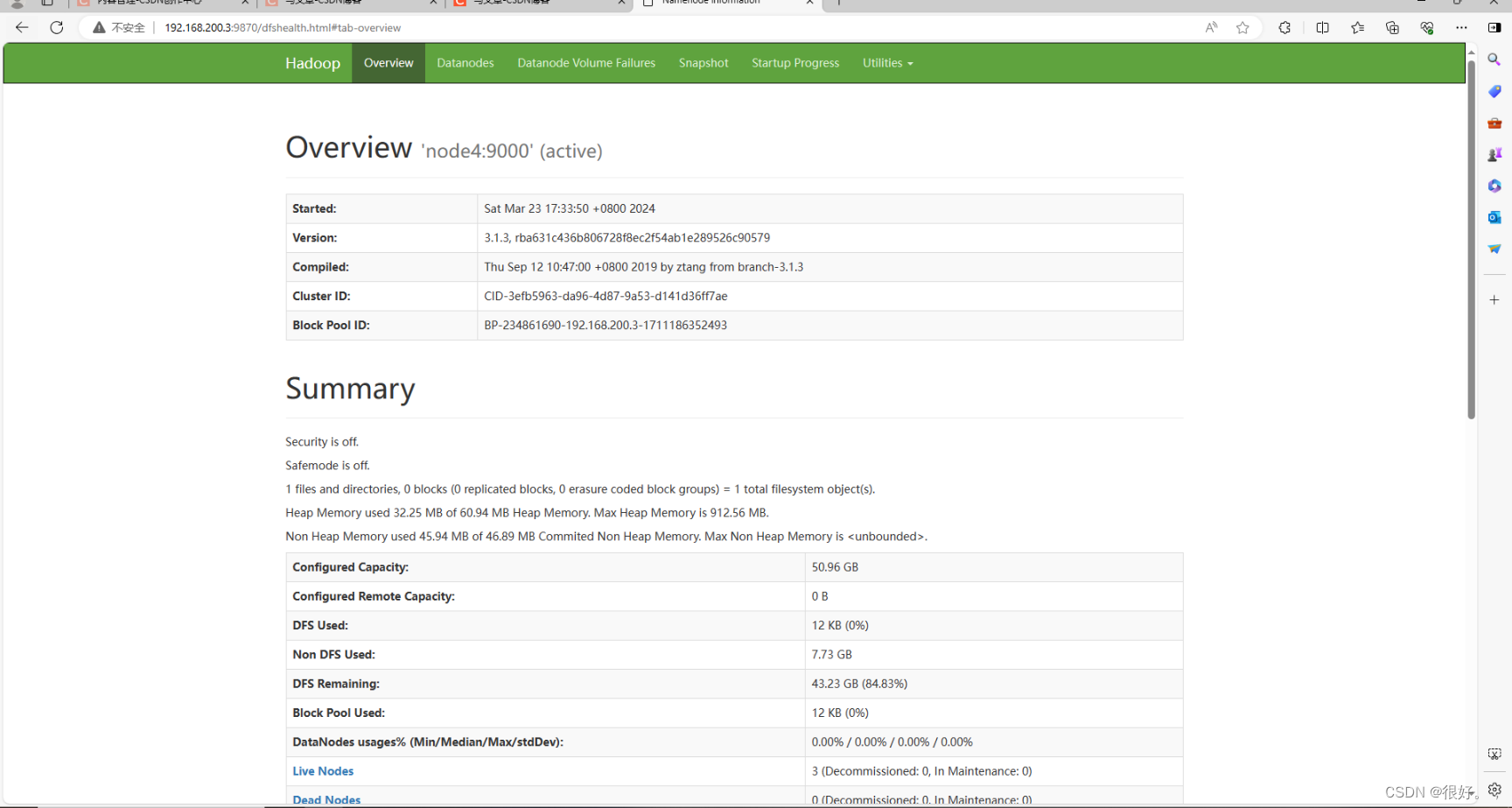
ip地址 + : 9870
192.168.200.3:9870
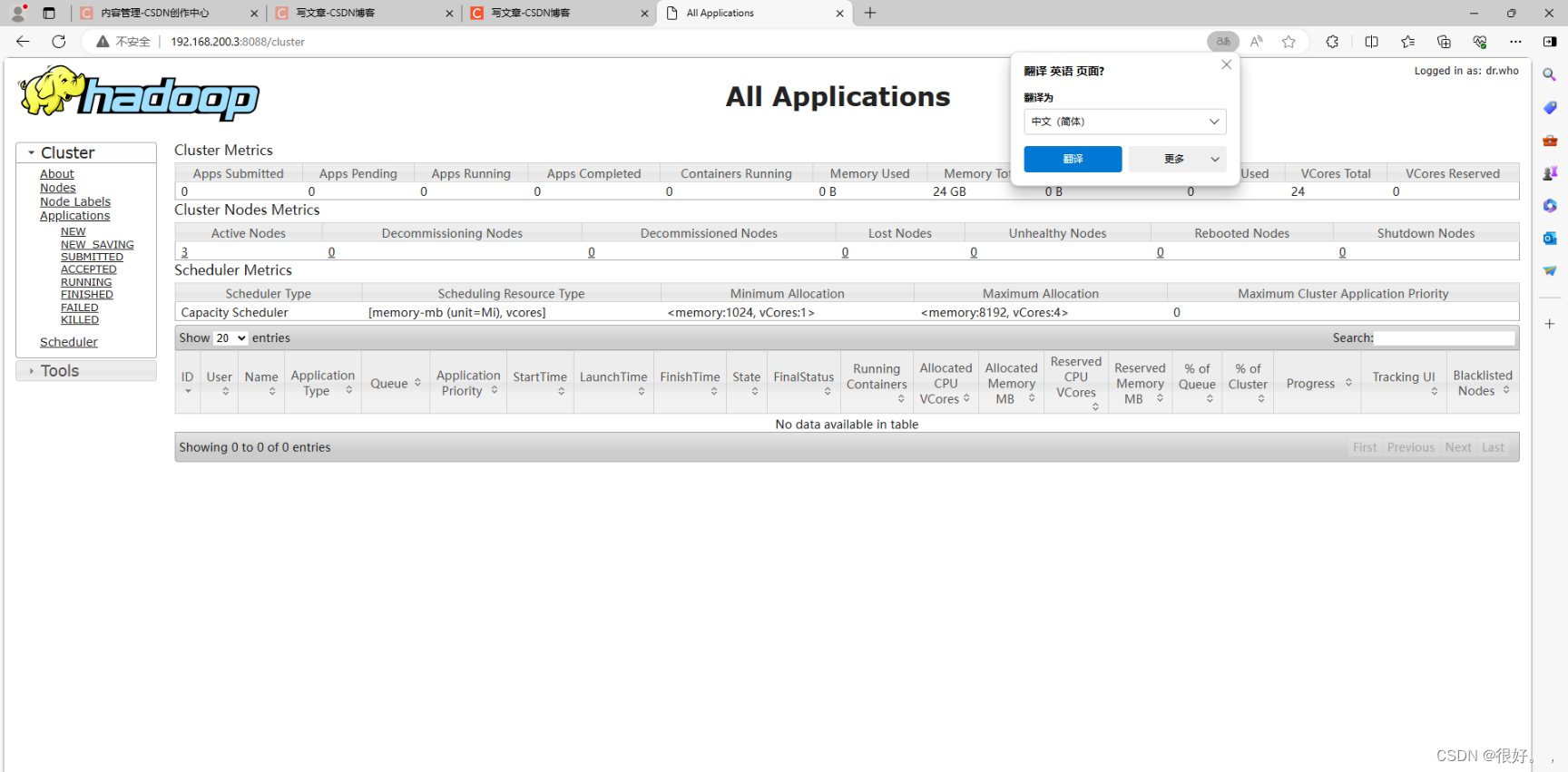
192.168.200.3:8088
我曾经问过我们老师一个问题我说老师你为什么打字那么快
老师回答我"多用tab,你也可以"
哈哈哈,现在想起来也是很有趣的一件事,可tab它可以检查路径错误,多敲。
人生的容错率真的很大,放手去做就够了。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









