







1、数据容器

2、列表的语法定义
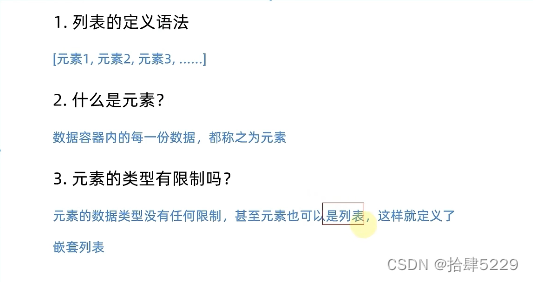
# 定义一个基础列表
my_list = ["itheima","itca
print(my_list)
print(type(my_list))
my_list = ["itheima", 666,
print(my_list)
print(type(my_list))
# 定义一个嵌套列表
my_list = [[1, 2, 3],[4, 5
print(my_list)
print(type(my_list))
3、列表的下索引

# 使用列表的下标索引从列表中取出元素
my_list = ["tom", "lily", "rose"]
print(my_list[0])
print(my_list[1])
print(my_list[2])
print(my_list[-1])
print(my_list[-2])
print(my_list[-3])
# 取出嵌套列表中的元素
my_list = [[1, 2, 3], [4, 5, 6]]
print(my_list[1][1]) 4、列表的常用操作
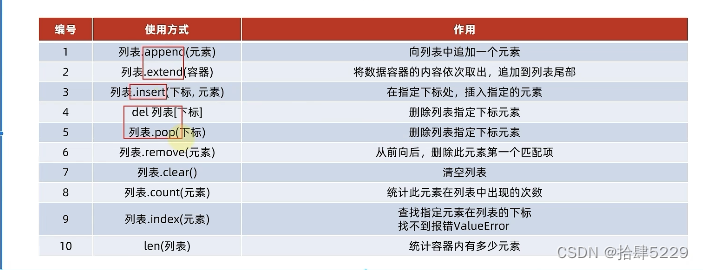
# 演示数据容器中,list列表中的常用操作
mylist = ["itheima", "itcast", "python"]
# 1、查找某元素在列表内的下标索引
index = mylist.index("itheima")
print(f"itheima在列表中的下标索引值是:{index}")
# 2.如果元素不存在,则会出现把报错
# 3.修改特定下标索引值
mylist[1] = "传智教育"
print(f"列表被修改元素的值后,结果是:{mylist}")
# 4.插入元素
mylist.insert(1, "best")
print(f"列表插入元素后,结果是:{mylist}")
# 5.元素追加,只能写入到尾部中
mylist.append("黑马程序员")
print(f"列表在追加元素后,结果是:{mylist}")
# 6.追加多个元素
mylist2 = [1, 2, 3]
mylist.extend(mylist2)
print(f"追加多个元素后的结果是:{mylist}")
# 7.删除指定元素(2种方式)
mylist = ["itheima", "itcast", "python"]
del mylist[2]
print(f"删除列表的元素后的结果是:{mylist}")
# 第二种方式
mylist = ["itheima", "itcast", "python"]
element = mylist.pop(2)
print(f"通过pop方法取出元素列表内容,{mylist},取出的元素是:{element}")
# 8.删除某元素在列表中的第一个匹配项,从前到后搜索第一个元素
mylist = ["itcat", "itheima", "itcast", "ithiema", "python"]
mylist.remove("itheima")
print(f"通过remove方法移除元素后,列表的结果是:{mylist}")
# 9.清空列表
mylist.clear()
print(f"列表被清空了,结果是:{mylist}")
# 10.统计列表元素的数量
mylist = ["itcat", "itheima", "itcast", "ithiema", "python"]
count = mylist.count("itheima")
print(f"列表中itheima的数量是:{count}")
# 11.统计列表中全部元素的数量
mylist = ["itcat", "itheima", "itcast", "ithiema", "python"]
count = len(mylist)
print(f"列表的元素数量总共有:{count}")

# 定义一个列表,并用列表接收它
mylist = [21, 25, 21, 23, 22, 20]
# 2.追加一个数字31到列表的尾部
mylist.append(31)
# 3.追加一个新列表[29, 33, 30]到泪飙的队尾
mylist.extend([29, 33, 30])
# 4.取出的第一个元素应该是21
num1 = mylist[0]
print(f"从列表中取出来的第一个元素应该是21,实际上是:{num1}")
# 5.取出最后一个元素应该是30
num2 = mylist[-1]
print(f"从列表中取出最后一个元素应该是31,实际上是:{num2}")
# 6.查找元素31,在列表中的下标位置
index = mylist.index(31)
print(f"元素31在列表中的下标位置是:{index}")
print(f"列表的内容是:{mylist}")5.列表的循环遍历

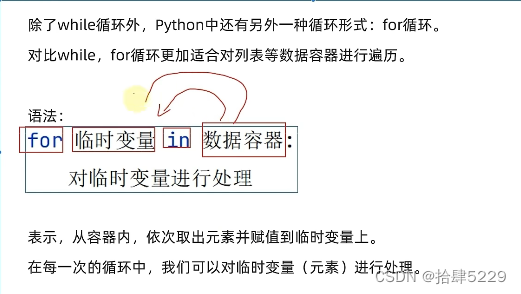

def list_while_func():
my_list = ["传智教育", "黑马程序员", "python"]
# 使用while循环列表来演示函数
# 循环控制变量下标索引来控制,默认为0
# 每一次循环将下标索引变量+1
# 循环条件:下标索引变量 < 列表的元素数量
# 定义一个变量来标记列表的下标
index = 0
while index < len(my_list):
element = my_list[index]
print(f"列表的元素为:{element}")
index += 1
# 将循环变量每次循环加1
list_while_func()
def list_for_func():
my_list = [1, 2, 3, 4, 5]
for element in my_list:
print(f"列表中的元素有:{element}")
list_for_func()

6.元组的定义和操作

# 元组一旦定义就不可以修改,而列表是可以修改的
# 定义元组
t1 = (1, "hello", True)
t2 = ()
t3 = tuple()
print(f"t1的类型是:{type(t1)},内容是:{t1}")
print(f"t2的类型是:{type(t2)},内容是:{t2}")
print(f"t3的类型是:{type(t3)},内容是:{t3}")
# 定义单个元组
t4 = ("hello",)
print(f"t4的类型是:{type(t4)},内容是:{t4}")
# 元组的嵌套
t5 = ((1, 2, 3),(4, 5, 6))
print(f"t5的类型是:{type(t5)},内容是:{t5}")
# 下标索引取出内容
num = t5[1][2]
print(f"从嵌套元组中取出的数据是:{num}")
t6 = ("传智教育", "黑马程序员", "python")
index = t6.index("黑马程序员")
print(f"在元组t6中查找黑马程序员,的下表是:{index}")
t7 = ("传智教育", "黑马程序员", "python","黑马程序员", "python")
num = t7.count("黑马程序员")
print(f"在元组中统计黑马程序员的数量有:{num}个")
t8 = ("传智教育", "黑马程序员", "python","黑马程序员", "python")
num = len(t8)
print(f"在元组中元素的数量有:{num}个")
# 元组的遍历
index = 0
while index < len(t8):
print(f"元组的元素有:{t8[index]}")
# 至关重要
index += 1
# for循环遍历
for element in t8:
print(f"2元组的元素有:{element}")
# 修改元组元素内容
t9 = (1, 2,["itheima", "itcast"])
print(f"t9的内容是:{t9}")
t9[2][0] = "黑马程序员"
t9[2][1] = "传智教育"
print(f"t9的内容是:{t9}")
7、字符串的定义和操作




# 演示数据容器的角色,字符串操作
my_str = "itheima and itcast"
# 通过下标索引取值
value = my_str[2]
value2 = my_str[-16]
print(f"从字符串{my_str}取下标为2的元素,它的值是:{value}取下标为-16的元素的值是:{value2}")
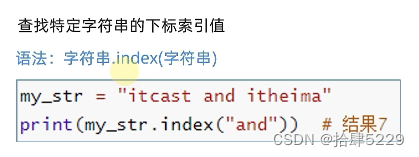
# index方法?
value = my_str.index("and")
print(f"在字符串{my_str}中查找and,其起始下标是:{value}")
# replce方法
new_my_str = my_str.replace("it", "程序")
print(f"将字符串{my_str},进行替换后得到:{new_my_str}")
# split方法
# 按照指定的分隔符字符穿,将字符串划分成多个字符串,列入表对象中
# 注意:字符串本身是不变的,而是得到一个列表对象
my_str = "hello python itheima itcast"
my_str_list = my_str.split(" ")
print(f"将字符串{my_str}进行split切分后得到{my_str_list},类型是:{type(my_str_list)}")
# strip方法
my_str = " itheima and itcas "
new_my_str = my_str.strip()
print(f"将字符串{my_str}被strip后,结果是:{new_my_str}")
my_str = "12itheima and itcas21"
new_my_str = my_str.strip("12")
print(f"将字符串{my_str}被strip(12)后,结果是:{new_my_str}")
# 统计字符串中某个字符串出现的次数count
my_str ="itheima and itcast"
count = my_str.count("it")
print(f"字符串{my_str}中it出现的次数是:{count}")
# 统计字符串的长度
num = len(my_str)
print(f"字符串{my_str}的长度是:{num}") 

my_str = "itheima itcast boxuegu"
count = my_str.count("it")
print(f"字符串itheima itcast boxuegu中有:{count}个it字符")
my_str = "itheima itcast boxuegu"
new_my_str = my_str.replace(" ", "|")
print(f"字符串itheima itcast boxuegu,被替换后空格后,结果是:{new_my_str}")
my_str = "itheima|itcat|boxuegu"
my_str_list = my_str.split("|")
print(f"字符串itheima|itcat|boxuegu,按照|分隔后,得到:{my_str_list}")8、数据容器的切片操作
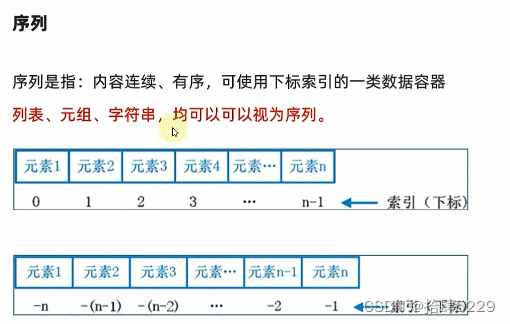

# 对list进行切片,从1开始,4结束,步长为1
my_list = [0, 1, 2, 3, 4, 5, 6]
# 步长为为1 ,可以省略不写
result1 = my_list[1:4]
print(f"结果1:{result1}")
# 对tuple进行切片,从头开始,到最后结束,步长为1
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result2 = my_tuple[:]
print(f"结果2是:{result2}")
# 对str进行切片,从头开始,到最后结束,步长为2
my_str = "0123456"
result3 = my_str[::2]
print(f"结果3是:{result3}")
# 对str进行切片,从头开始,到最后结束,步长为-1,也就是倒序
my_str = "0123456"
result4 = my_str[::-1]
print(f"结果4是:{result4}")
# 对列表进行切片,从3开始,到1结束,步长为-1
my_list = [0, 1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1]
print(f"结果5是:{result5}")
# 对元组进行切片,从头开始,到位结束,步长为-2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result6 = my_tuple[::-2]
print(f"结果6是:{result6}")
my_str = "万过薪月,员序程马黑来 nohtyp学"
# 倒序字符串,切片取出
result1 = my_str[::-1][9:14]
print(f"方式1结果是:{result1}")
# 切片取出,然后倒序
result2 = my_str[5:10][::-1]
print(f"方式2的结果是:{result2}")
# split分隔",".replace来替换"来"为空,倒序字符串
result3 = my_str.split(",")[1].replace("来", "")[::-1]
print(f"方式3结果是:{result3}")
9.集合的定义和操作






# 集合定义
my_set = {"传智教育", "黑马程序员", "python", "传智教育", "黑马程序员", "python", "传智教育", "黑马程序员", "python"}
my_set_empty = set() # 定义空集合
print(f"my_set的内容是:{my_set},类型是:{type(my_set_empty)}")
print(f"my_set_empty的内容是:{my_set_empty},类型死后:{type(my_set_empty)}")
# 修改
# 1.添加新元素
my_set.add("itheima")
print(f"添加新元素后的结果是:{my_set}")
# 2.移除元素
my_set.remove("黑马程序员")
print(f"移除黑马程序员后结果是:{my_set}")
# 3.随机取出一个元素
element = my_set.pop()
print(f"集合被取出的元素是:{element},取出后结果是:{my_set}")
# 4.清空集合clear
my_set.clear()
print(f"集合被清空了,结果是:{my_set}")
# 5.取两个集合的差集difference
set1 = {1, 2, 3}
set2 = {1, 4, 5}
set3 = set1.difference(set2)
print(f"取出差集后的结果是:{set3}")
print(f"取出差集后,原来的set1的内容是{set1}")
print(f"取出差集后,原来的set2的内容是{set2}")
# 6.消除集合的差集difference_update
set1 = {1, 2, 3}
set2 = {1, 4, 5}
set1.difference_update(set2)
print(f"消除差集后,集合1的结果是:{set1}")
print(f"消除差集后,集合2的结果是:{set2}")
# 7.两个集合合并union
# 将集合1和集合2组合诚信的集合,
# 得到的新集合,集合一和集合二不变
set1 = {1, 2, 3}
set2 = {1, 4, 5}
set3 = set1.union(set2)
print(f"两集合合并的结果是:{set3}")
print(f"合并后集合1:{set1}")
print(f"合并后集合1:{set2}")
# 8.统计集合元素数量len
set1 = {1, 2, 3, 4, 5, 6, 1, 2, 3, 4}
num = len(set1)
print(f"集合内元素的数量有:{num}个")
# 9.集合的遍历
# 集合不支持下标索引,不能用while,可以用for
set1 = {1, 2, 3, 4, 5, 6, 1, 2, 3, 4}
for element in set1:
print(f"集合的元素有:{element}")# 信息去重
my_list = ['黑马程序员', '传智播客', '黑马程序员', '传智播客',
'ithema', 'itcast', 'ithema', 'itcast', 'best']
# 定义一个空集合
my_set = set()
# 通过for循环遍历序列
for element in my_list:
my_set.add(element)
# for循环中将列表的元素添加到集合
# 最终得到元素去重后的集合对象,并打印输出
print(f"列表的内容是:{my_list}")
print(f"通过for循环后,得到的集合对象是:{my_set}")9.字典



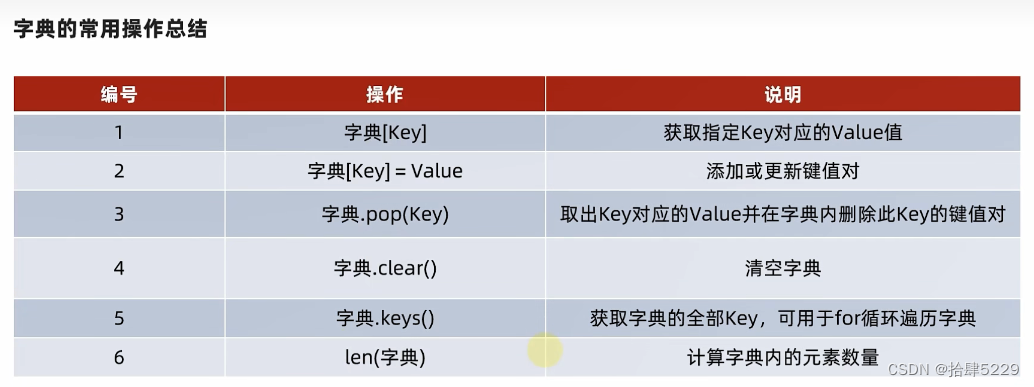
# 1.定义字典
my_dict1 = {"王俊凯":100, "王源":99, "易烊千玺":101}
# 2.定义空字典
my_dict2 = {}
my_dict3 = dict()
print(f"字典1的内容是:{my_dict1},类型是:{type(my_dict1)}")
print(f"字典1的内容是:{my_dict2},类型是:{type(my_dict2)}")
print(f"字典1的内容是:{my_dict3},类型是:{type(my_dict3)}")
# 3.定义重复key的字典
my_dict1 = {"王俊凯":100, "王俊凯":101, "王源":99, "易烊千玺":101}
print(f"重复key的字典的内容是:{my_dict1}")
# 4.从字典中基于key获取value
my_dict1 = {"王俊凯":100, "王源":99, "易烊千玺":101}
score = my_dict1["王俊凯"]
print(f"王俊凯的考试分数是:{score}")
score = my_dict1["易烊千玺"]
print(f"易烊千玺的考试分数是:{score}")
# 5.字典的嵌套
stu_score_dict = {
"小明": {
"语文": 99,
"英语": 88,
"数学": 98
},
"小泓": {
"语文": 89,
"英语": 98,
"数学": 78
},
"小艾": {
"语文": 99,
"英语": 98,
"数学": 86
}
}
print(f"学生的考试信息是:{stu_score_dict}")
# 6.从嵌套字典中获取数据
score = stu_score_dict["小艾"]["语文"]
print(f"小艾的分数是:{score}")
score = stu_score_dict["小明"]["数学"]
print(f"小明的分数是:{score}")

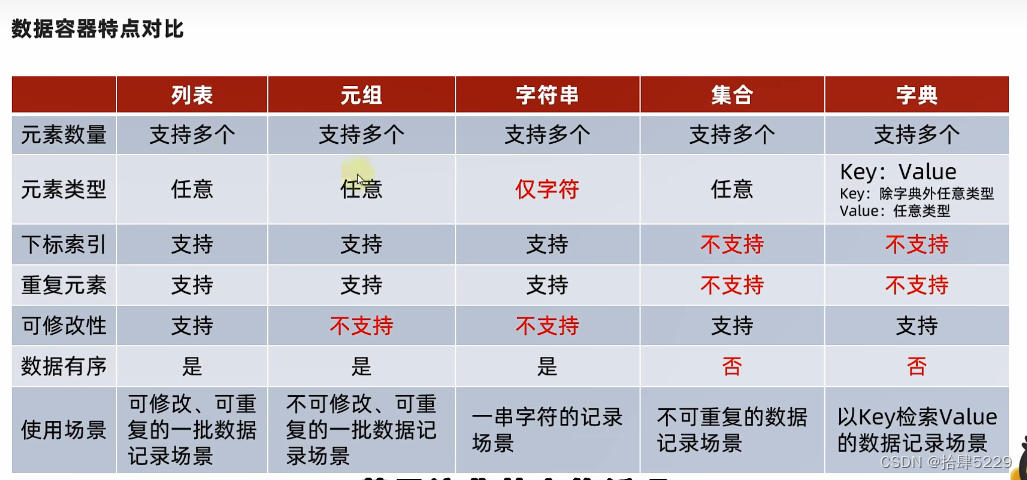
10.数据容器的对比
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









