






之前设计了一个积分功能,通过获取的积分可以参与排行,这个排行榜单可以设计为实时榜单(本赛季榜单)和历史榜单(历史赛季榜单)。
1.1 实时积分榜
1.1.1 设计思路
积分记录明细表中,一个用户对应的有很多条积分记录,如果要根据积分形成排行榜的话,就需要在查询积分记录明细表的时候,先对用户分组,在对积分求和,然后按照积分和排序。
但是,在积分记录表中,每个用户可能有数十条甚至上百条的积分记录,当用户规模达到百万规模时,可能产生的积分记录就是数以亿计的,那当查询排行的时候,就需要在内存中对这么多数据进行分组、求和和排序,对内存和cpu来说非常不友好,所以可以考虑用Redis来保存排行榜数据。
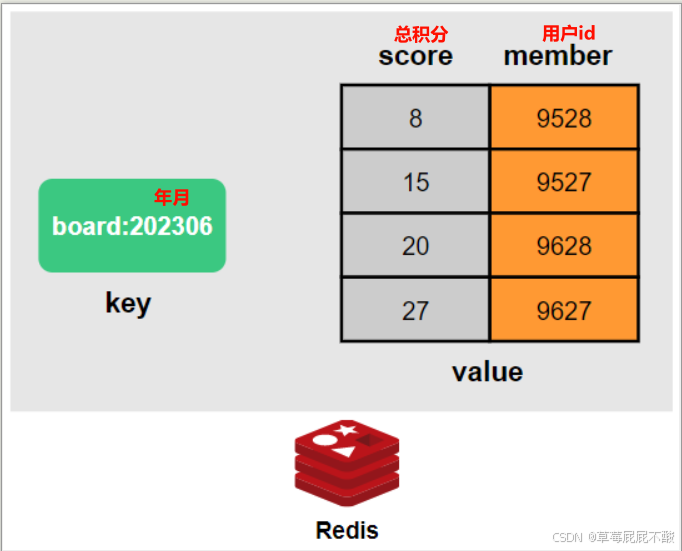
用Redis保存数据,并不是将所有的用户积分记录数据都放入Reids,而是设计两个字段:
- 一个是用户id,一个是用户的总积分,初始总积分设置为0
- 当某用户通过某种途径获取积分之后,在Redis中给对应的用户的总积分加上获得的分数
- 通过总积分数进行排序,用来排行
- 排序首选使用到zset结构来存储数据
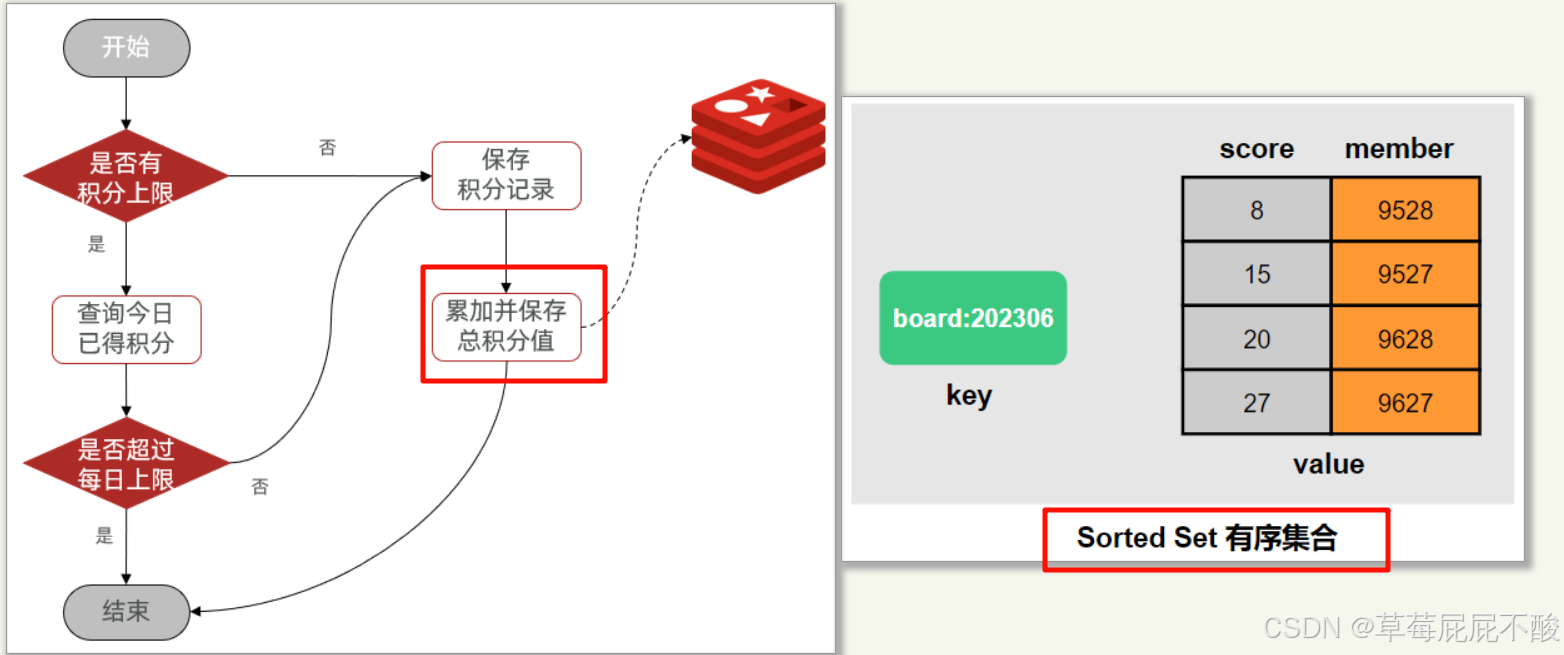
1.1.2 生成积分榜
此功能很简单,只需要在我们原来保存积分的功能上改进一下,将积分保存到MySQL的同时保存到redis中进行积分累加和榜单排序即可。
1.1.3 查询积分榜
在个人中心,学生可以查看指定赛季积分排行榜,还可以查看自己总积分和排名(即使自己并没有上榜,但是也能看到自己在第一个位置上面)。
而且排行榜分为本赛季榜单(从Redis中查)和历史赛季榜单(从数据库中查),但是两种情况查询返回的数据是一样的,只需要在一个接口中实现这两类榜单的查询即可。
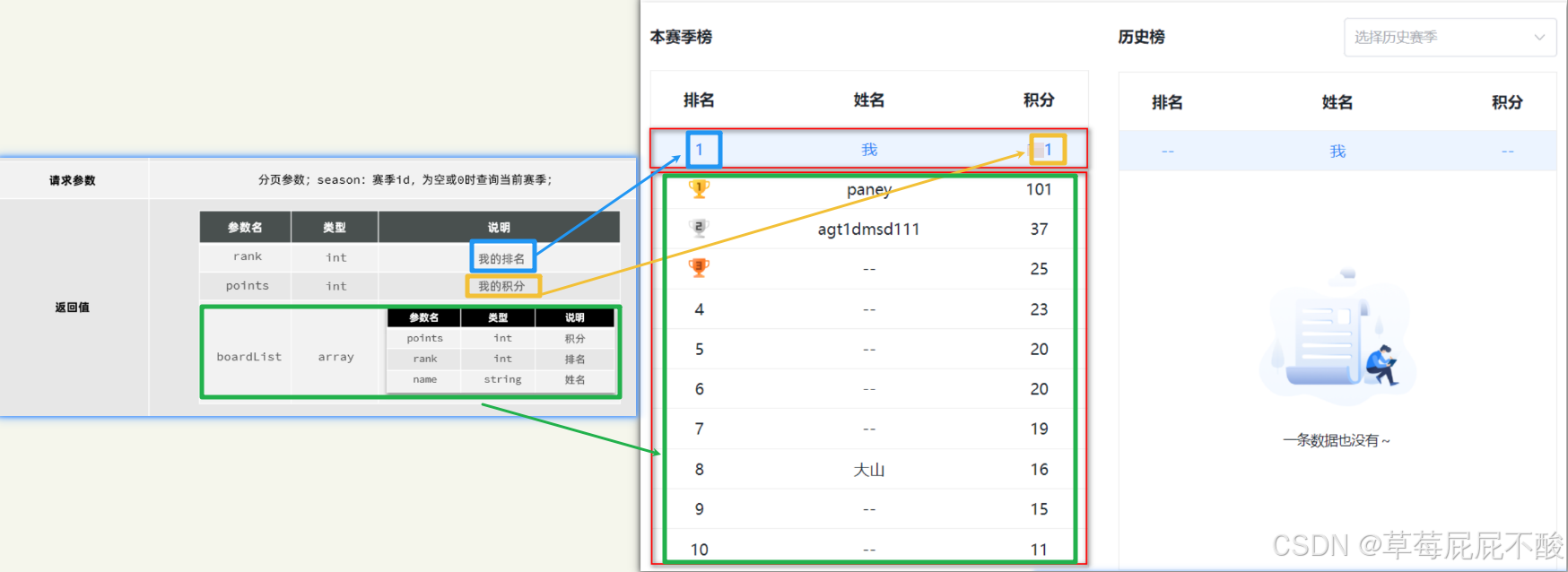
请求参数:
-
由于要查询历史榜单需要知道赛季,因此参数中需要指定赛季标识,当赛季标识为空,则认定是查询当前赛季。
-
榜单数据非常多,不可能一次性查询出来,因此需要分页查询。
返回值:
无论是历史榜单还是当前榜单,结构都一样,分为两部分:
-
榜单数据,就是N个用户的积分、排名形成的集合
-
当前用户的积分和排名,当前用户不一定上榜,因此需要单独查询
具体实现:
- 判断是否为当前赛季
- 是,在Redis中查询数据
- 在Redis中查询我在当前赛季的积分和排名(参数:key--年月)
- 通过key和用户id(通过ThreadLocal获取)获得对于的积分和排名
- 若积分为null,则返回0
- 若排名为null,则返回0
- 在Redis中查询积分和排名分页列表( 参数: key、start=(当前页数 - 1) * 每页条数、end=start + 当前页数 - 1 )
- 根据分数倒序排序
- 将查询到的set通过循环转换为返回需要的List
- 设置名字字段
- 在Redis中查询我在当前赛季的积分和排名(参数:key--年月)
- 否,从数据库中分页查询历史排行榜
1.2 历史积分榜
1.2.1 设计思路
- 每个月结束,当月的积分和排行榜名次就已经确定,不会在发生改动,就可以存入历史积分榜中
- 查询量也会大大减少,也就不在需要Redis,所以将Redis存储的上月的最终排行榜数据写入数据库,然后清空Redis即可。
- 可以设置一个定时任务,在每月第一天的00:00实现数据的同步,和Redis历史数据的删除。

1.2.2 数据库表数据
历史榜单数据需要记录到数据库中,就需要设计一个数据库表---排行榜表,表中主要设计到的字段有:榜单id、用户id、总积分、排行名次、赛季
1.2.3 具体实现
由于一个用户肯能会有多个赛季的历史榜单,并且系统又会有多个用户,所有数据都存储到一张表中就会造成海量数据问题,在这里,可以采用水平分表存储历史榜单数据,一个赛季的数据存储在一张表中。
历史榜单数据的保存:redis中上一个赛季的完整数据保存到mysql中,主要分为三步:
-
创建历史赛季表(一个赛季一张表)
-
从redis中将数据保存到mysql中对应的赛季表中(数据持久化)
-
删除redis中历史赛季的数据
上面三个定时任务应该使用xxl-job实现,而且要规定好执行顺序(任务链)
1.2.3.1 生成积分榜单表
由于我们要解决的是数据过多问题,因此分表的方式选择水平分表。具体来说,就是按照赛季拆分,每一个赛季是一个独立的表。还可以做一些简化:
-
我们可以将id采用自增id,那么id就是排名,
排名字段就不需要了。 -
不同赛季用不同表,那么
赛季字段就不需要了。
1.2.3.2 榜单数据持久化
- 通过一个死循环,分页从Redis中读取数据
- 读取不到,代表已经读完了
- redis中查询到的每一条记录收集数据表对应的一条记录,批量向MySQL中保存
1.2.3.3 清理Redis缓存任务
添加清理Redis缓存任务,这里不使用del ,否则可能因为大数据量删除阻塞主线程,而是使用unlink命令开启异步线程删除。
- delete -- 同步 阻塞
- unlink -- 异步 非阻塞
1.2.3.4 任务链
xxl-job支持任务链调度,可以直接在子任务中设置,在10号里面设置子任务ID为12,12里面设置子任务ID为13,这样只需要设置一个定时任务时间。
我们期待的任务执行顺序,如图:



1.3 海量数据存储
对于数据库的海量数据存储,方案有很多,常见的有:
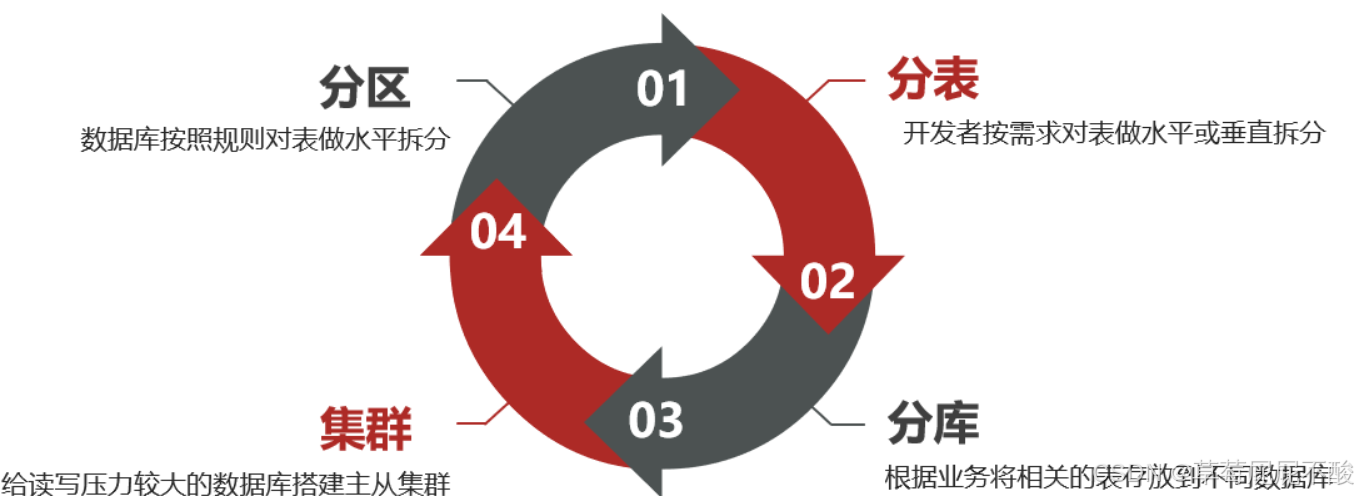
1.3.1 分区
表分区(Partition)是一种数据存储方案,可以解决单表数据较多的问题,MySQL5.1开始支持表分区功能。分区就是按照某种规则,把表数据对应的ibd文件拆分成多个文件来存储
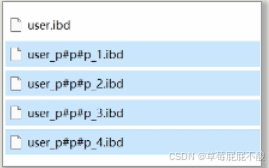
从物理上来看,一张表的数据被拆到多个表文件存储了;从逻辑上来看,他们对外表现是一张表。
增删改查的方式不会有什么变化,只不过底层MySQL底层的处理上会有变更,例如检索时可以只检索某个文件,而不是全部
优点:
• 可以存储更多的数据,突破单表上限,甚至可以存储到不同磁盘,突破磁盘上限
• 查询时可以根据规则只检索某一个文件,提高查询效率
• 数据统计时,可以多文件并行统计,最后汇总结果,提高统计效率
• 对于一些历史数据,如果不需要时,可以直接删除分区文件,提高删除效率
缺点:
-
分区字段必须是索引字段
-
分区方式不够灵活
-
只支持水平分区
1.3.2 分表
分表是一种表设计方案,由开发者在创建表时按照自己的业务需求拆分表。一旦做了分表,无论是逻辑上,还是物理上,就从一张表变成了多张表
增删改查的方式就发生了变化,必须自己考虑要去哪张表做数据处理。
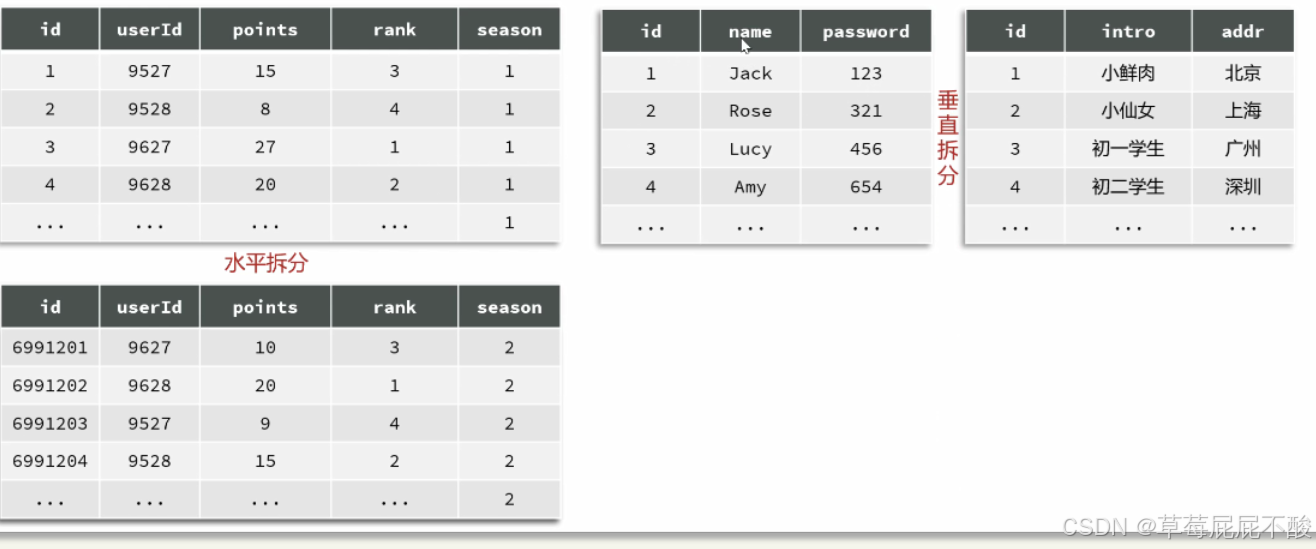
1.3.2.1 水平分表
例如,对于赛季榜单,我们可以按照赛季拆分为多张表,例如每一个赛季一张新的表,水平分表仅仅是每张表数据不同。
但结构一样,查询赛季1,就找第一张表。查询赛季2,就找第二张表。
1.3.2.2 垂直分表
如果一张表的字段非常多,比如达到30个以上,这样的表我们称为宽表。
宽表由于字段太多,单行数据体积就会非常大,虽然数据不多,但可能表体积也会非常大!从而影响查询效率。
这个时候一张表就变成了两张表。而且两张表的结构不同,数据也不同。这种按照字段拆分表的方式,称为垂直拆分。
优点
• 拆分方式更加灵活
• 可以解决单表字段过多(垂直拆分)和数据过多(水平拆分)的问题
缺点:
• 增删改查时,需要自己判断访问哪张表
• 垂直拆分还会导致事务问题及数据关联问题:原本一张表的操作,变为多张表操作。
1.3.3 分库和集群
无论是分区,还是分表,我们刚才的分析都是建立在单个数据库的基础上。但是单个数据库也存在一些问题:
-
单点故障问题:数据库发生故障,整个系统就会瘫痪
-
单库的性能瓶颈问题:单库受服务器限制,其网络带宽、CPU、连接数都有瓶颈
-
单库的存储瓶颈问题:单库的磁盘空间有上限,如果磁盘过大,数据检索的速度又会变慢
综上,在大型系统中,我们除了要做分表、还需要对数据做分库,建立综合集群。
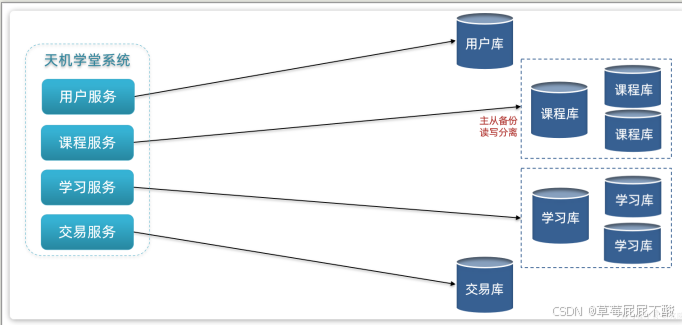
首先,在微服务项目中,我们会按照项目模块,每个微服务使用独立的数据库,因此每个库的表是不同的,这种分库模式成为垂直分库。
而为了保证单节点的高可用性,我们会给数据库建立主从集群,主节点向从节点同步数据。两者结构一样,可以看做是水平扩展。
这个时候就会出现垂直分库、水平扩展的综合集群,如图:
优点:
• 解决了海量数据存储问题,突破了单机存储瓶颈
• 提高了并发能力,突破了单机性能瓶颈
• 避免了单点故障
缺点:
• 成本非常高
• 数据聚合统计比较麻烦
• 主从同步的一致性问题
• 分布式事务问题

















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









