







目录
目录

一、lzo算法简介
Lempel-Ziv-Oberhumer算法是一种最 快速 的 无损 数据压缩解压 算法,简称LZO算法。一个实现LZO算法的软件工具是lzop,较之常见的gzip,lzop可以提供更快的压缩与解压缩速度。最初LZO库由ANSI C编写,现在LZO有Perl、Python以及Java等各种版本。
LZO以处理速度为设计原则,LZO的解压速度要快于其压缩速度,但其压缩比例可以根据需要自由调节,并且不会影响到解压速度。算法解压很简单,无需内存支持;并且LZO可以提供无损压缩。
优点:
- 快速得到解压和压缩数据
- 不消耗过多cpu资源
- 合理压缩率
二、hadoop中使用lzo算法
在hadoop中使用lzo的压缩算法可以减小数据的大小和数据磁盘读写时间。不仅如此,lzo是基于block分块的,这样他就允许数据被分解成chunk,并行的被hadoop处理。基于这样的特点,就可以让lzo在hadoop上成为一种非常好用的压缩格式。
lzo本身不是splitable的,所以当数据为text格式时,用lzo压缩出来的数据当做job的输入是一个文件作为一个map。但是sequencefile本身是分块的,所以sequencefile格式的文件,再配上lzo的压缩格式,就可实现lzo文件方式的splitable。
三、lzo算法在HDFS上
压缩的数据通常只有原始数据的1/4,在HDFS中存储压缩数据,可以使集群能保存更多的数据,延长集群的使用寿命。不仅如此,由于mapreduce作业通常瓶颈都在IO上,存储压缩数据就意味这更少的IO操作,job运行更加的高效。
在hadoop上使用压缩也有两个比较麻烦的地方:第一,有些压缩格式不能被分块,并行的处理,比如gzip。第二,另外的一些压缩格式虽然支持分块处理,但是解压的过程非常的缓慢,使job的瓶颈转移到了cpu上,例如bzip2。比如我们有一个1.1GB的gzip文件,该文件 被分成128MB/chunk存储在hdfs上,那么它就会被分成9块。为了能够在mapreduce中并行的处理各个chunk,那么各个mapper之间就有了依赖。而第二个mapper就会在文件的某个随机的byte出进行处理。那么gzip解压时要用到的上下文字典就会为空,这就意味这gzip的压缩文件无法在hadoop上进行正确的并行处理。也就因此在hadoop上大的gzip压缩文件只能被一个mapper来单个的处理,这样就很不高效,跟不用mapreduce没有什么区别了。而另一种bzip2压缩格式,虽然bzip2的压缩非常的快,并且甚至可以被分块,但是其解压过程非常非常的缓慢,并且不能被用streaming来读取,这样也无法在hadoop中高效的使用这种压缩。即使使用,由于其解压的低效,也会使得job的瓶颈转移到cpu上去。
如果能够拥有一种压缩算法,即能够被分块,并行的处理,速度也非常的快,那就非常的理想。这种方式就是lzo。
四、HDFS配置lzo压缩
(1)编译
hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译。
a)环境准备
- 开发环境:centos 7 、jdk1.8、hadoop3.2.4、非root用户
- maven下载安装配置环境,修改setting配置文件
- 集群分配
服务器hadoop102
服务器hadoop103
服务器hadoop104
HDFS
NameNode
DataNode
DataNode
DataNode
SecondaryNameNode
Yarn
NodeManager
Resourcemanager
NodeManager
NodeManager
1.下载maven Linux版
maven最新版下载地址:Maven – Download Apache Maven![]() https://maven.apache.org/download.cgi
https://maven.apache.org/download.cgi
maven以前版本下载地址:Index of /dist/maven/maven-3![]() https://archive.apache.org/dist/maven/maven-3/
https://archive.apache.org/dist/maven/maven-3/
2.上传解压maven包
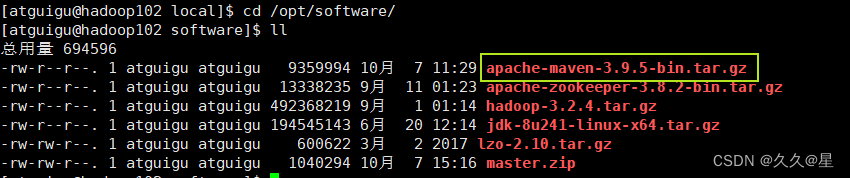
#解压命令:
tar -xf apache-maven-3.9.5-bin.tar.gz -C /usr/local/maven/
#我解压到我自己创建的maven文件夹里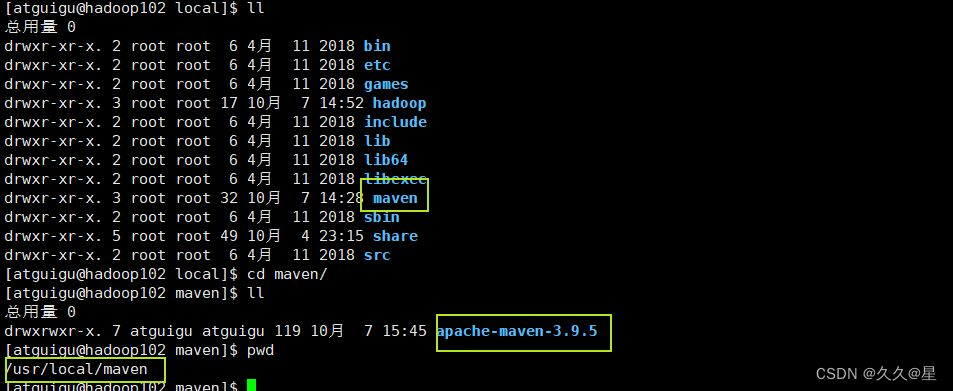
3.配置maven环境
cd apache-maven-3.9.5/ #进入
mkdir repositories #创建文件夹 本地仓库地址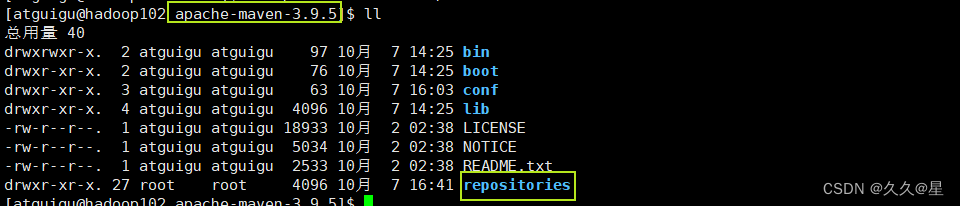
1 vim conf/settings.xml #编辑setting.xml
2 #添加参数 55行处
<localRepository>/usr/local/maven/apache-maven-3.9.5/repositories/</localRepository>
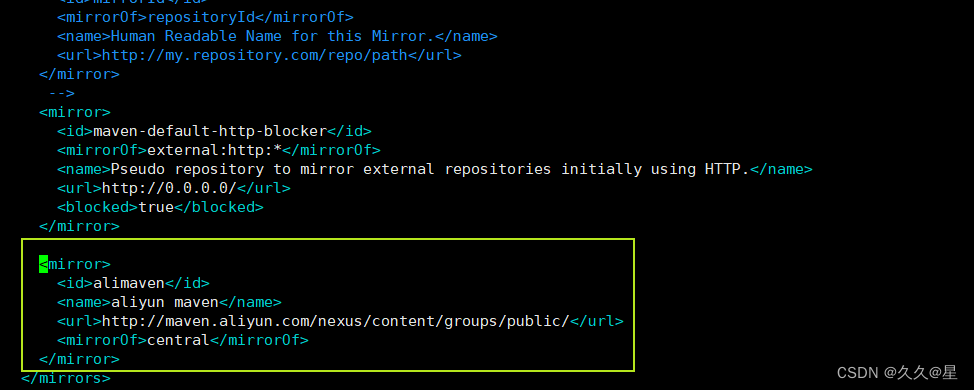
3 #添加阿里镜像仓库 175行处
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>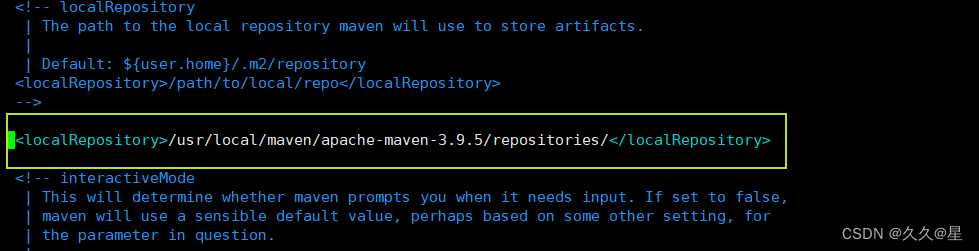
#进入环境编辑文件
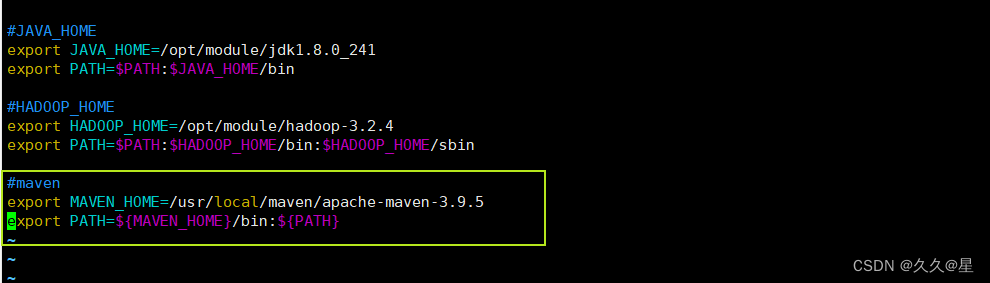
vim /etc/profile.d/my_env.sh
#添加配置环境
export MAVEN_HOME=/opt/inst/maven354
export PATH=$PATH:$MAVEN_HOME/bin
#刷新环境变量
source vim/etc/profile.d/my_en.sh
#检查maven环境
mvn -v
这里我使用的xsync脚本一键分发,所以配置文件在 vim /etc/profile.d/my_env.sh 如何配置xsync脚本,详情参考:配置xsync(详解)_久久@星的博客-CSDN博客使用xsync命令同步一个文件,会只将这个文件,同步到其他服务器的相同路径下面(没有的目录与文件会自动创建)使用xsync命令同步一个目录,会将这个目录下面的所有文件以及子目录,同步到其他服务器相同路径下面(没有的目录与文件会自动创建)多次同步某一个文件或者目录,第一次全部同步,第二次以及之后就只会同步里面发生更改的部分,未更改的部分不会重复同步https://blog.csdn.net/qq_58534786/article/details/133322121

4.通过yum下载以下插件
gcc-c++
zlib-devel
autoconf
automake
libtoolyum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool
b)下载安装并编译lzo
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
# 直接输入命令进行下载(我放在专门存放压缩包的地方)
#也可以直接在windows上面下载后,上传
下载地址:http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
#解压
tar -xf lzo-2.10.tar.gz -C /opt/module/
#进入lzo-2.10
cd lzo-2.10
export CFLAGS=-m64
#配置指定lzo编译地址
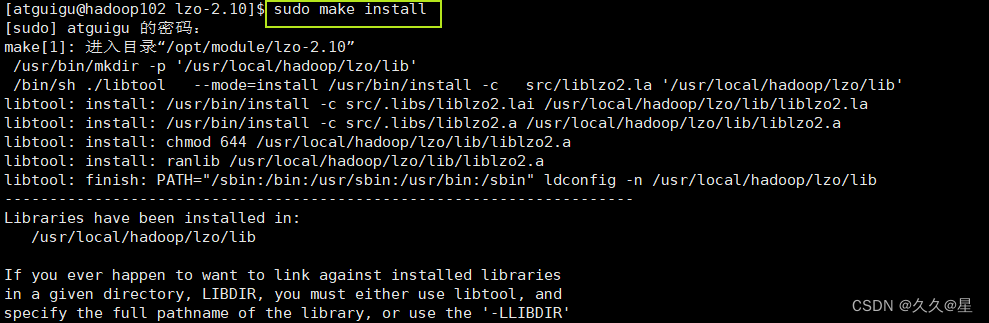
./configure -prefix=/usr/local/hadoop/lzo/
#开始编译安装(root权限)
make
make install
#查看编译安装状态
cd /usr/local/hadoop/lzo


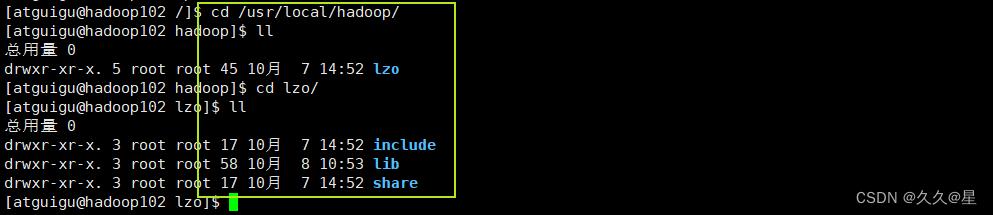
#直接输入以下命令下载
wget https://github.com/twitter/hadoop-lzo/archive/master.zip
#或者上传,下载地址
https://github.com/twitter/hadoop-lzo/archive/master.zip
#若出现ssh拒绝连接 ,可能是没有下载ssh
sudo apt-get install openssh-server
#解压master.zip
tar -xf master.zip -C /opt/module
# 如果提示没有 unzip 记得用yum 安装,需root权限
sudo yum -y install unzip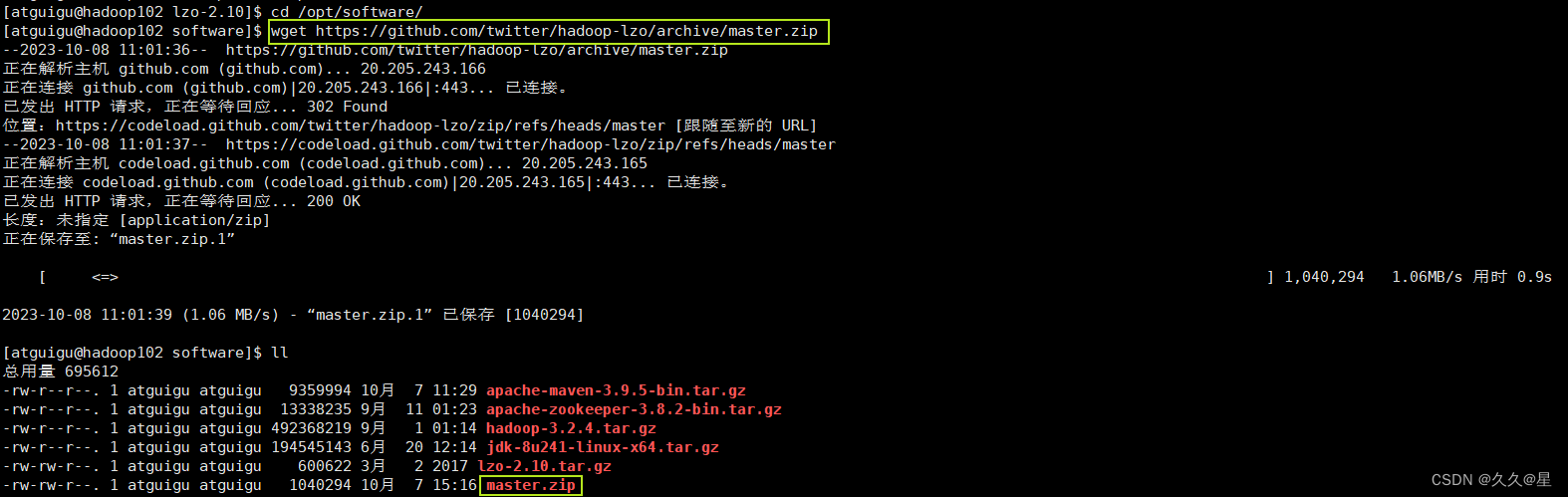

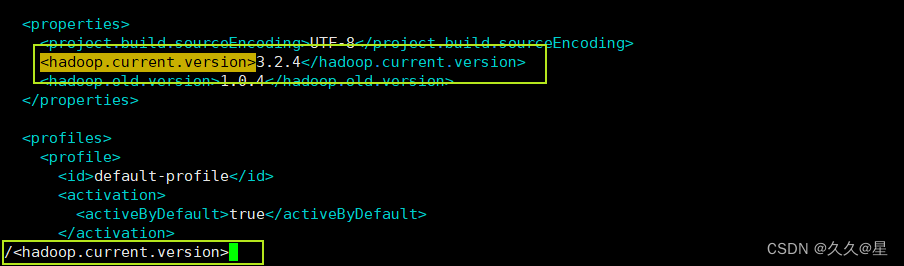
#修改pom.xml文件(hadoop版本)
<hadoop.current.version>3.2.4</hadoop.current.version>
#声明变量
export CFLAGS=-m64
export CXXFLAGS=-m64
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include
export LIBRARY_PATH=/usr/local/hadoop/lzo/lib
非编辑模式下,/+想查找内容,即可快速查找
cd hadoop-lzo-master/
export CFLAGS=-m64
export CXXFLAGS=-m64
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include # 这里需要提供编译好的lzo的include文件
export LIBRARY_PATH=/usr/local/hadoop/lzo/lib # 这里需要提供编译好的lzo的lib文件
#开始编译,若因为权限出错请在最前面加上sudo
mvn clean package -Dmaven.test.skip=true
#查看编译结果
cd target

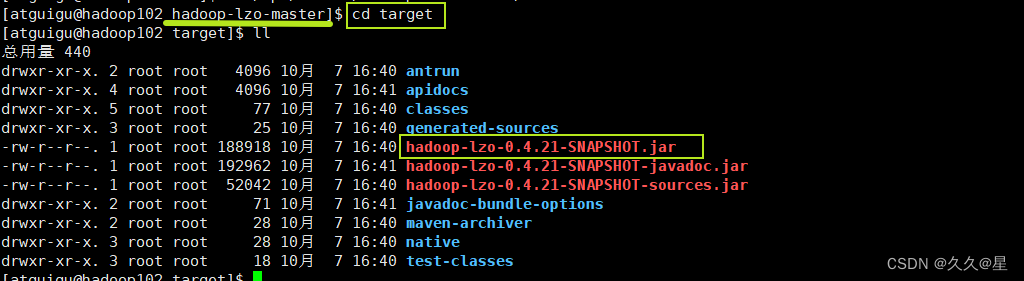
c)配置lzo
将编译好后的hadoop-lzo-0.4.21-SNAPSHOT.jar 移动hadoop-3.2.4/share/hadoop/common/
sudo mv hadoop-lzo-0.4.21-SNAPSHOT.jar /opt/module/hadoop-3.2.4/share/hadoop/common/
#查看移动结果
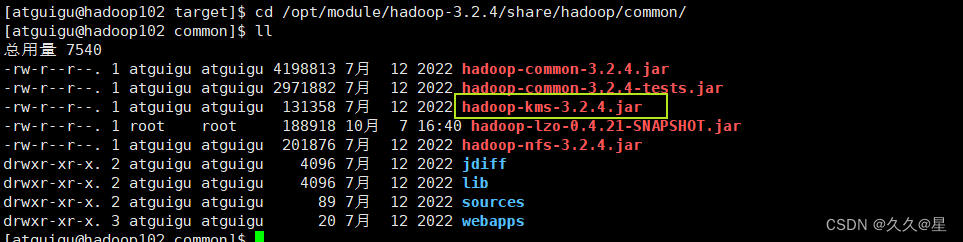
cd /opt/module/hadoop-3.2.4/share/hadoop/common/
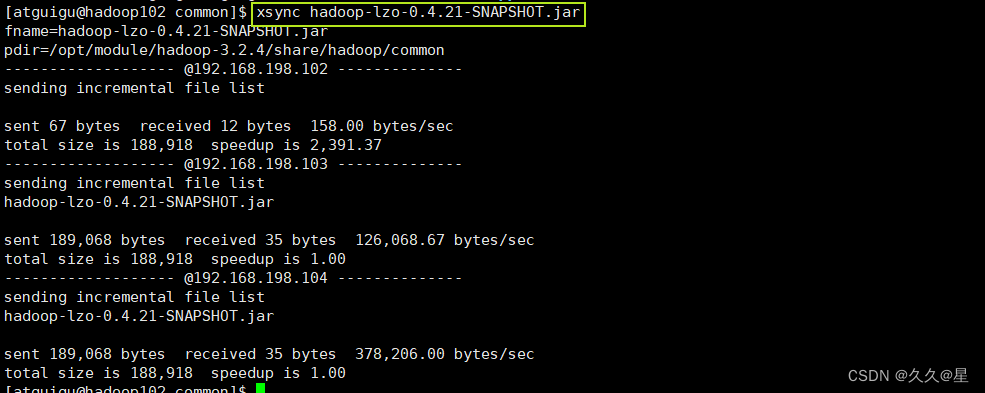
#分发给hadoop103、hadoop104
xsync hadoop-lzo-0.4.21-SNAPSHOT.jar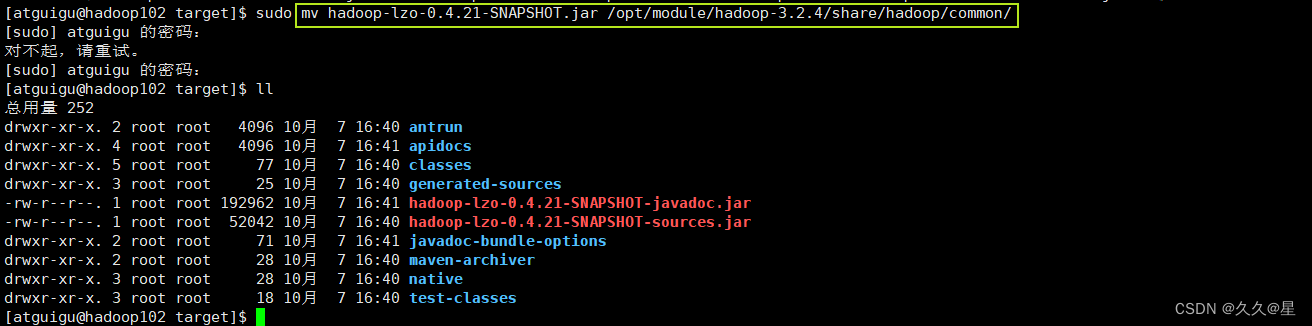
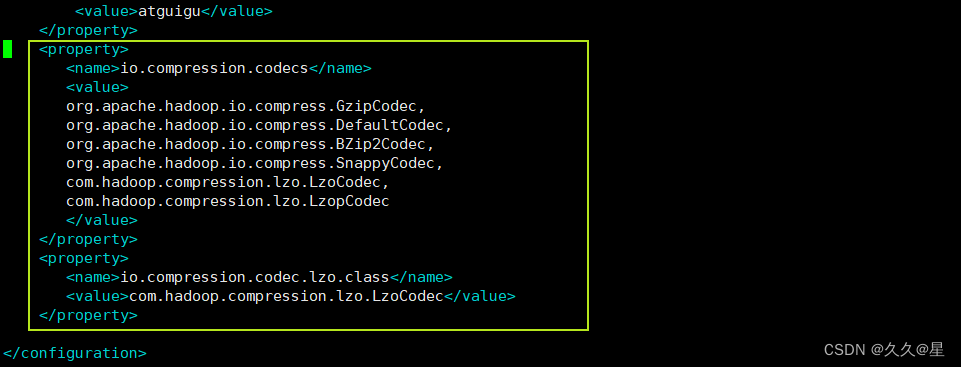
# 配置core-site.xml
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
![]()
#同步到hadoop103/hadoop104
xsync core-site.xml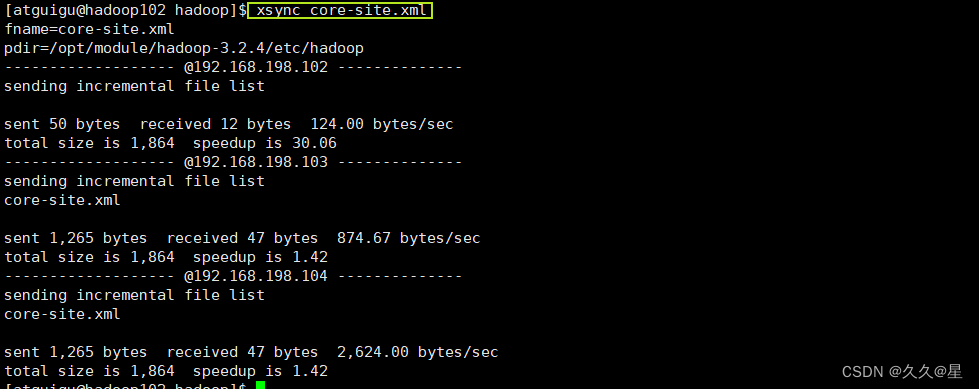
启动集群查看状态
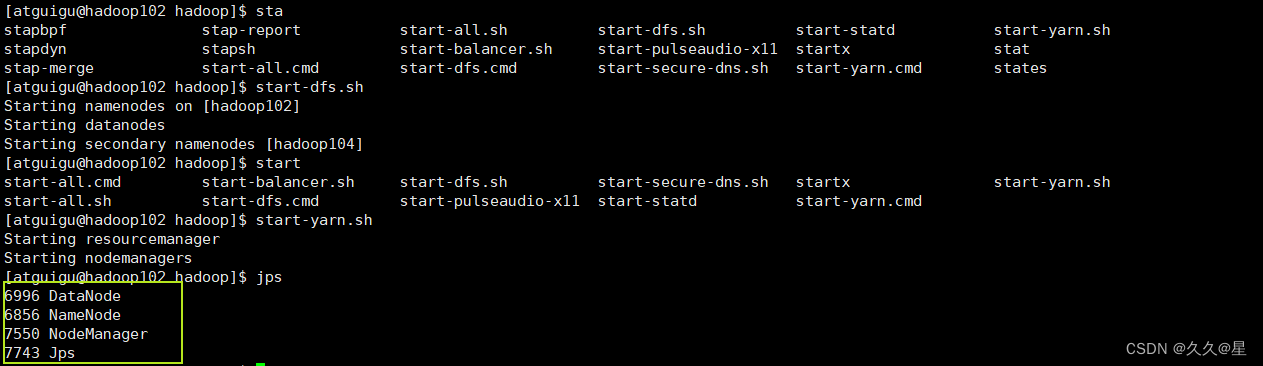

下一期测试lzo以及创建索引,hadoop参数调优
















 2452
2452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











