






走进机器学习线性回归
机器学习线性回归案例讲解_机器学习⼊门:线性回归案例机器学习定义
机器学习是⼀个源于数据的模型的训练过程,最终归纳出⼀个⾯向⼀种性能度量的决策。
机器学习步骤
提出问题
理解数据
数据清洗
构建模型
评估
案例: 学习时间与考试分数之间的相关性
1,问题:学习时间与考试分数之间的相关性
2,理解数据
导⼊数据集
#导⼊包
from collections import OrderedDict
import pandas as pd
#数据集
examDict={
'学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,
2.50,2.75,
3.00,3.25,3.50,
4.00,4.25,4.50,4.75,
5.00,5.50],
'分数': [ 10, 22, 13, 43, 20, 22, 33, 50, 62,
48, 55, 75, 62, 73, 81, 76, 64, 82, 90, 93]
}
examOrderDict=OrderedDict(examDict)
examDf=pd.DataFrame(examOrderDict)
examDf
获取数据描述统计信息
examDf.describe()
examDf.shape
绘制散点图
#绘制散点图
import matplotlib.pyplot as plt
exam_X=examDf.loc[:,'学习时间']
exam_y=examDf.loc[:,'分数']
#散点图
plt.scatter(exam_X,exam_y,color='b',label='exam data')
#添加图标标签
plt.xlabel('Hours')
plt.ylabel('Score')
#显⽰图⽚
plt.show() rDf=examDf.corr()
print('相关系数矩阵:')
rDf
构建模型
#Linear Regression in python
from sklearn import linear_model
reg=linear_model.LinearRegression()
reg.fit([[0,0],[1,1],[2,2]],[0,1,2])
reg.coef_
查看数据
examDf.head()提取特征标签
#提取特征和标签
#特征features
exam_X=examDf.loc[:,'学习时间']
exam_y=examDf.loc[:,'分数']
导⼊数据
from sklearn.cross_validation import train_test_split
#建⽴训练数据和测试数据
X_train,X_test,y_train,y_test=train_test_split(exam_X, #样本特征
exam_y, #样本标签
train_size= .8) #训练数据占⽐
#输出数据⼤⼩
print('原始数据特征:',exam_X.shape,
'训练数据特征:',X_train.shape,
'测试数据特征:',X_test.shape)
print('原始数据标签:',exam_y.shape,
'训练数据标签:',y_train.shape,
'测试数据标签:',y_test.shape)可视化
#绘制散点图
import matplotlib.pyplot as plt
plt.scatter(X_train,y_train,color='blue',label='train data')
plt.scatter(X_test,y_test,color='red',label='test,data')
#添加标签
plt.legend(loc=2)
plt.xlabel('Hours')
plt.ylabel('Score')
#显⽰图像
plt.show()
构建模型 :训练数据80% ——输出模型
测试数据20% ——评估模型准确率
#将训练数据特征转换成⼆维数组XX⾏*1列
X_train=X_train.reshape(-1,1)
#将测试数据特征转换成⼆维数组⾏数*1列
X_test=X_test.reshape(-1,1)
#训练模型
#第⼀步:导⼊线性回归
from sklearn.linear_model import LinearRegression
#第⼆步:创建模型:线性回归
model=LinearRegression()
#第三步:训练模型
model.fit(X_train,y_train) '''
最佳拟合线:
y=a+bx
截距intercept:a
回归系数:b
'''
#截距
a=model.intercept_
b=model.coef_
print('最佳拟合线:截距a=',a,'回归系数b=',b)可视化
#绘图
import matplotlib.pyplot as plt
#绘制散点图
plt.scatter(X_train,y_train,color='blue',label='train data')
#训练数据的预测值
y_train_pred=model.predict(X_train)
#绘制最佳拟合线
plt.plot(X_train,y_train_pred,color='black',linewidth=3 ,label='best line')
#添加标签
plt.legend(loc=2)
plt.xlabel('Hours')
plt.ylabel('Score')
#显⽰图⽚
plt.show()
评估
#评估模型:决定系数R平⽅
model.score(X_test,y_test)
总结果可视化
#绘图
import matplotlib.pyplot as plt
#绘制散点图
plt.scatter(X_train,y_train,color='blue',label='train data')
plt.scatter(X_test,y_test,color='red',label='test data')
#绘制最佳拟合
y_train_pred=model.predict(X_train)
plt.plot(X_train,y_train_pred,color='black',label='best line')
#添加标签
plt.legend(loc=2)
plt.xlabel('Hours')
plt.ylabel('Score')
plt.show()结论:学习时间与分数成正相关关系。学习时间越长,分数越⾼。
统计知识点解析:
1、单变量数据与⼆变量数据
单变量数据:只考虑⼀个单⼀变量的频数或概率。
⼆变量数据:考虑两个变量数值,并给出两变量间关系。
⼆变量数据可视化:散点图(Scatter)
2、相关与回归
3种线性相关:正线性相关、负线性相关、不相关
3,误差平⽅和和协⽅差
误差平⽅和:Y的实际值以及通过最佳拟合线得出的预测值之间的差值
公式:SSE=∑(y-^y)² 近似⽅差
协⽅差:协⽅差⽤于衡量两个变量的总体误差
公式:4、最佳拟合线
定义:使样本点到该直线的离差平⽅和达到最⼩的直线
公式:y=a+bx (回归线)
b=∑(x- ¯x)(y- ¯y)/∑(x- ¯x)²
a=¯y-b¯x
5、相关系数
定义:计算直线拟合度
功能:
1)两个变量的相关⽅向 正:朝上 负:朝下
2)相关性⼤⼩表⽰两个变量每单位的相关程度
一、代码实现部分
1.导入必备的库并且设置中文乱码问题
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 设置正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 设置字体大小
plt.rcParams.update({'font.size': 16})
data = pd.read_excel('./居民人均可支配收入基尼系数.xlsx',header=0, index_col=0)
2.读取数据
data = pd.read_excel('./居民人均可支配收入基尼系数.xlsx',header=0, index_col=0)
2.1打印数据

3.设定X和y1的值并保存模型
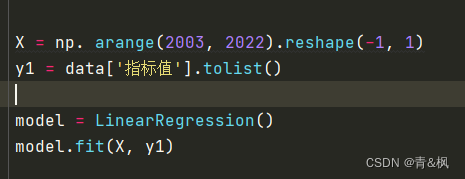
4.设定新的X值

5.绘图

二、结果展示
三、实现的完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 设置正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 设置字体大小
plt.rcParams.update({'font.size': 16})
data = pd.read_excel('./居民人均可支配收入基尼系数.xlsx',header=0, index_col=0)
#print('data:\n',data)
X = np. arange(2003, 2022).reshape(-1, 1)
y1 = data['指标值'].tolist()
model = LinearRegression()
model.fit(X, y1)
X_new = np.arange(2001, 2026).reshape(-1, 1)
plt.figure(figsize=(16, 8))
# 历史样本散点图
plt.scatter(X, y1)
# 新样本预测
plt.plot(X_new, model.predict(X_new), color='red')
plt.title('\n基尼系数\n')
plt.xlabel('年份')
plt.ylabel('单位:%')
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











