







Spark shell 提供了一种来学习该 API 比较简单的方式,以及一个强大的来分析数据交互的工具。在 Scala(运行于 Java 虚拟机之上,并能很好的调用已存在的 Java 类库)或者 Python 中它是可用的。
启动 Spark Shell
spark-shell 的本质是在后台调用了 spark-submit 脚本来启动应用程序的,在 spark-shell 中已经创建了一个名为 sc 的 SparkContext 对象,通过在 Spark 目录中运行以下的命令来启动它:
./bin/spark-shell
通过设定 local[N] 参数来启动本地 Spark 集群,其中 N 表示运行的线程数,或者用 * 表示使用机器上所有可用的核数。
spark-shell --master local[N]spark-shell --master local[*]
在本地模式设定内存,如设置本地进程使用 2GB 内存。
spark-shell --driver-memory 2g --master local[*]
集群模式启动,设置本地进程使用 1GB 内存,CPU 数为 3 核:
spark-shell --master spark://linux01:7077 --executor-memory 1g --total-executor-cores 3
如果 spark-shell 需要引用一些其他的 jar包(比如 MySQL jdbc),可以通过 --jars 引用它;或者将 jar 包的路径添加到 classpath。
Spark Shell
Spark Shell 操作
Spark 的主要抽象是一个称为 Dataset 的分布式的 item 集合。Datasets 可以从 Hadoop 的 InputFormats(例如 HDFS 文件)或者通过其它的 Datasets 转换来创建。
让我们从 Spark 源目录中的 README 文件来创建一个新的 Dataset: 首先在当面目录下创建一个名为 data.txt 的文件,文件内容如下:
菜中路,梁鹏,13799999999,15778423030,2017-06-28 06:29:22,2017-06-28 06:32:46,204,宁夏回族自治区,陕西省刘飞飞,刘能宗,15732648446,18620192711,2018-01-04 12:18:55,2018-01-04 12:25:38,403,辽宁省,广西壮族自治区刘能宗,张阳,18620192711,17731088562,2017-12-15 14:57:23,2017-12-15 15:01:32,249,云南省,四川省梁鹏,邓二,15778423030,13666666666,2017-08-08 13:33:45,2017-08-08 13:37:13,208,山西省,重庆市张倩,刘飞飞,15151889601,15732648446,2016-03-03 02:17:36,2016-03-03 02:19:33,117,新疆维吾尔自治区,天津市刘飞飞,王世昌,15732648446,13269361119,2018-04-16 12:26:43,2018-04-16 12:31:41,298,西藏自治区,湖南省杨力谋,王世昌,18301589432,13269361119,2016-07-17 11:22:30,2016-07-17 11:23:24,54,浙江省,黑龙江省张涛,菜中路,15032293356,13799999999,2016-11-30 19:07:55,2016-11-30 19:14:45,410,澳门特别行政区,云南省张倩,任宗阳,15151889601,15614201525,2016-08-21 10:54:24,2016-08-21 10:54:40,16,江西省,福建省朱尚宽,刘飞飞,18332562075,15732648446,2016-05-14 15:36:56,2016-05-14 15:40:33,217,贵州省,香港特别行政区张倩,郭美彤,15151889601,18641241020,2017-05-02 17:02:27,2017-05-02 17:03:18,51,天津市,河南省刘能宗,唐会华,18620192711,13560190665,2018-04-30 18:31:06,2018-04-30 18:33:11,125,广东省,福建省菜中路,郭美彤,13799999999,18641241020,2017-01-24 18:09:52,2017-01-24 18:11:03,71,台湾省,山西省# 加载 data.txt 文件val textFile = spark.read.textFile("data.txt")

打印次数据集的项数:
textFile.count()

textFile.first()

我们可以直接从 Dataset 中获取 values(值),通过调用一些 actions(动作),或者 transform(转换)Dataset 以获得一个新的。
查找刘飞飞的通话记录:
val linesWithSpark = textFile.filter(line => line.contains("刘飞飞"))

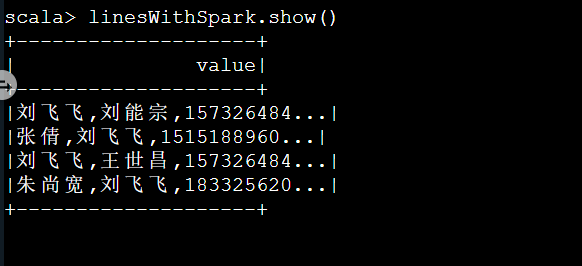
查看 Dataset 数据集的内容:
linesWithSpark.show()
将结果保存到 result 目录中:
linesWithSpark.write.text("result")
退出界面:
:quit

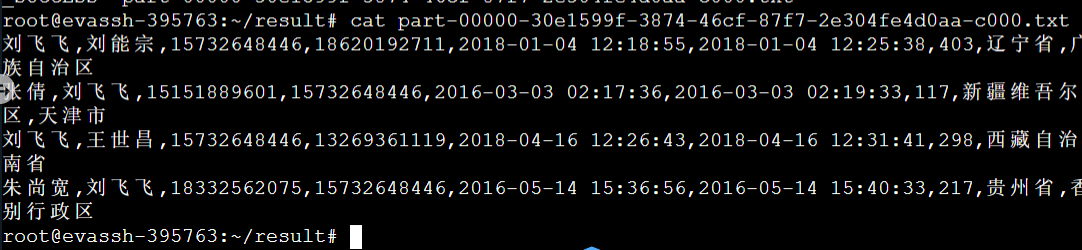
查看系统文件,我们会发现当前目录下生成了一个 result 的目录文件:

result 目录下的 part* 文件保存着我们最后的结果数据:

编程要求
在右侧命令行中读取 /data/workspace/myshixun 下的 phone.txt 文件的数据,查找张涛与王世昌之间的通话记录,并将统计结果保存到 /root/re 目录文件中。
phone.txt 文件数据如下:
邓二,张倩,13666666666,15151889601,2018-03-29 10:58:12,2018-03-29 10:58:42,30,黑龙江省,上海市
| 邓二 | 张倩 | 13666666666 | 15151889601 | 2018-03-29 10:58:12 | 2018-03-29 10:58:42 | 30 | 黑龙江省 | 上海市 |
|---|---|---|---|---|---|---|---|---|
| 用户名A | 用户名B | 用户A的手机号 | 用户B的手机号 | 开始时间 | 结束时间 | 通话时长 |















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









