







目录
一、简介
本文主要记录在使用YOLO和Paddle Detection做目标检测任务时,初始数据集与模型输入数据集不匹配时,对初始数据集预处理中的代码。
二、YOLO模型
1.初始数据集格式
初始的训练数据格式分为图片数据的 jpg 格式和边缘框的 json 格式。以一个边缘框的 json文件为例。json文件中是一个列表,列表每个元素代表当前图片中一个框的信息。
"id" : 边缘框索引数
"name" : 图片名
"box" : 边缘框坐标表示参数(四个数中前两数代表矩形框左上点xy坐标,后两数右下点xy坐标)
2.转为YOLO的 txt 格式
YOLO支持 txt 格式的标注文件,具体如下图,文本文件.txt 的每一行代表当前图片中的一个边缘框,每一行的五个数中第一个数代表区域的类别(如边缘框选择区域的内容是猫?狗?大象?)。该项目中暂不涉及检测区域类别任务,因此所有框类别都是0类。后四个数是将初始 json 文件中的 “box” 经过处理归一化后的边缘框信息(具体的数据变化逻辑在代码处注解中有解释)。
"yolo格式"
'类别号', '左上x坐标', '左上y坐标', '右下x坐标', '右下y坐标'YOLO可以训练的标注框文件格式:

将初始 json 文件转为 yolo 可读的训练数据格式,并对完整数据集进行拆分为训练train和测试val数据集,其Python代码如下。
import os
import json
from PIL import Image, ImageDraw, ImageChops
import random
from shutil import copyfile
# 图片和锚框数据保存路径
jpg_path = '填入实际图片所在地址'
json_path = '填入实际json标注文件所在地址'
txt_path = '创建你需要保存yolo txt的文件夹,将创建地址填入'
# yolo模型数据保存路径
yolo_jpg = '创建训练测试数据集图片文件夹,将创建地址填入'
yolo_lab = '创建训练测试数据集标注框文件夹,将创建地址填入'
# 训练测试验证数据比重设置
weight = [0.9, 0.1]
#####################(分界线)上述是需根据情况修改的参数,以下函数不需修改
# 锚框归一化
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1. / size[0] # 1/w
dh = 1. / size[1] # 1/h
x = (box[0] + box[2]) / 2.0 # 物体在图中的中心点x坐标
y = (box[1] + box[3]) / 2.0 # 物体在图中的中心点y坐标
w = box[2] - box[0] # 物体实际像素宽度
h = box[3] - box[1] # 物体实际像素高度
x = x * dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w * dw # 物体宽度的宽度比(相当于 w/原图w)
y = y * dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h * dh # 物体宽度的宽度比(相当于 h/原图h)
return [x, y, w, h] # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
# 将锚框json文件归一化后保存为yolo可读的txt文件
def normal_box(json_path, jpg_path,txt_path):
for file in os.listdir(json_path):
basename = file.split('.')[0]
box_file = os.path.join(json_path, basename+'.json')
jpg_file = os.path.join(jpg_path, basename+'.jpg')
img = Image.open(jpg_file)
img_size = (img.width, img.height) # 获取图片尺寸
with open(box_file, 'r') as f:
box_list = json.load(f)
for box_dict in box_list:
box = box_dict['box'][:-1] # 删除实际标注的锚框类别
conv_box = convert(img_size, box)
conv_box.insert(0, 0) # 不对锚框类别进行训练
save = os.path.join(txt_path, basename+'.txt')
for box_txt in conv_box:
with open(save, 'a') as f:
f.writelines(str(box_txt)+' ')
with open(save, 'a') as f:
f.write('\n')
print(file + ' success')
# 复制文件——拆分后的数据移动到对应文件夹
def copy_file(file_path_list, file_path, target_path, last_name):
for file in file_path_list:
real_path = os.path.join(file_path, file+last_name)
copyfile(real_path, target_path+file+last_name) #copyfile(文件所在地,复制目标路径)
print(file + last_name + ' success')
# 拆分数据集
def set_train_test_val(jpg_path, txt_path, yolo_jpg, yolo_lab, weight):
filelist = os.listdir(jpg_path)
length = len(filelist)
random.shuffle(filelist)
tr_namelist = [tr[:-4] for tr in filelist[:int(weight[0]*length)]]
va_namelist = [va[:-4] for va in filelist[int(weight[0]*length):]] # 文件basename不含格式后缀
os.makedirs(yolo_jpg+'train') # 创建图片训练 train文件夹
os.makedirs(yolo_jpg+'val') # 创建图片测试 val文件夹
os.makedirs(yolo_lab+'train') # 创建标签训练 train文件夹
os.makedirs(yolo_lab+'val') # 创建标签测试 val文件夹
copy_file(tr_namelist, jpg_path, yolo_jpg+'train/','.jpg') # 图片jpg训练集train
copy_file(va_namelist, jpg_path, yolo_jpg + 'val/', '.jpg') # 图片jpg验证集val
copy_file(tr_namelist, txt_path, yolo_lab + 'train/', '.txt') # 标签label训练集train
copy_file(va_namelist, txt_path, yolo_lab + 'val/', '.txt') # 图片label训练集val
if __name__ =='__main__':
# 总数据集数据归一化与txt格式标准化处理
normal_box(json_path, jpg_path, txt_path)
# 训练集train、测试集text、验证集val划分
set_train_test_val(jpg_path, txt_path, yolo_jpg, yolo_lab, weight)经过上述程序运行后,可以在设置的保存文件夹内得到如下的结果。根据设置的训练和测试样本的权重比例,将不同的训练集放入 images 和 labels 文件夹下。


三、Paddle模型
1.VOC2007数据格式
对于paddle中的VOC,本人是将已有的yolo中 txt 文件转成 xml 格式来构建的VOC数据集。首先,需了解VOC格式在文件夹上的架构。VOC按照数据的类型(图片or框)来作为文件夹主逻辑的。其中完整数据的图片和标注分别放在JPEGImages和Annotations下,对于训练集和测试集的划分是在 ImageSets 下创建两个 txt 文件标明。txt文件中是不带后缀的图片文件名。



将YOLO 中 txt 文件转为 VOC 的 xml 格式的Python代码如下。下述代码只创建了数据集的标签数据和划分训练测试的txt文件,图片数据jpg没有进行移动,如果需要构建一个完整的数据集,只需将初始数据集中的图片复制到VOC下的JPEGImages下即可。
import os
from xml.dom.minidom import Document
import cv2
import random
from shutil import copyfile
import json
# txt, jpg文件和xml文件保存地址
jpgfiles = '填入实际图片所在地址'
txtfiles = '填入实际yolo的txt标注文件所在地址'
xmlfiles = '创建所需保存xml文件的路径'
# voc数据中训练测试样本划分方式txt文件保存地址
voc_txtfiles = './VOC2007/ImageSets/Main/'
# 训练测试验证数据比重设置
weight = [0.95, 0.05]
#####################(分界线)上述是需根据情况修改的参数,以下函数不需修改
## voc数据集构建(.xml)
# txt转xml函数
def translate(xmlfiles, jpgfiles, txtfiles):
dic = {'0' : "ZW"}
files = os.listdir(jpgfiles)
for i,jpg in enumerate(files):
# 获取图片信息
jpgfile = os.path.join(jpgfiles, jpg)
image = cv2.imread(jpgfile) # 路径不能有中文
Pheight, Pwidth, Pdepth = image.shape # 图片大小
# 获取标签信息
basename = jpg.split('.')[0]
txtfile = os.path.join(txtfiles, basename+'.txt')
txtFile = open(txtfile)
txtList = txtFile.readlines()
# xml文件编写
# 头信息
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
# folder项目名信息
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("page detection")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
# filename文件名信息
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(jpg)
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
# path地址信息
path = xmlBuilder.createElement("path") # path标签
pathcontent = xmlBuilder.createTextNode(jpgfiles+jpg)
path.appendChild(pathcontent)
annotation.appendChild(path) # path标签结束
# source信息
source = xmlBuilder.createElement("source") # source标签
database = xmlBuilder.createElement("database") # source子标签database
databasecontent = xmlBuilder.createTextNode("Unknown")
database.appendChild(databasecontent)
source.appendChild(database) # source子标签database结束
annotation.appendChild(source) # source标签结束
# size图片信息
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
# 标签信息
for j in txtList:
oneline = j.strip().split(" ") # 拆分yolo中关键信息
object = xmlBuilder.createElement("object") # object 标签
# name边缘框类型
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]]) # 边缘框类型
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
# 默认标签(无需修改)
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
# box边缘框信息
# yolo中心相对坐标转化为左上右下绝对位置坐标
mathData_x1 = int(((float(oneline[1])) * Pwidth) - (float(oneline[3])) * 0.5 * Pwidth)
mathData_y1 = int(((float(oneline[2])) * Pheight) - (float(oneline[4])) * 0.5 * Pheight)
mathData_x2 = int(((float(oneline[1])) * Pwidth) + (float(oneline[3])) * 0.5 * Pwidth)
mathData_y2 = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
xminContent = xmlBuilder.createTextNode(str(mathData_x1))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标
yminContent = xmlBuilder.createTextNode(str(mathData_y1))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
xmaxContent = xmlBuilder.createTextNode(str(mathData_x2))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
ymaxContent = xmlBuilder.createTextNode(str(mathData_y2))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlfiles + basename + ".xml", 'w')
xmlBuilder.writexml(f, indent='', newl='\n', addindent='\t', encoding='utf-8')
f.close()
print(basename + ' success')
# voc2007数据划分txt文件
def set_voc(xmlfiles, voc_txtfiles, weight):
filelist = os.listdir(xmlfiles)
length = len(filelist)
random.shuffle(filelist)
trival_namelist = [tr[:-4] for tr in filelist[:int(weight[0] * length)]]
val_namelist = [te[:-4] for te in filelist[int(weight[0] * length):]] # 文件basename不含格式后缀
trival = open(voc_txtfiles+'trainval.txt', 'w')
val = open(voc_txtfiles+'val.txt', 'w')
for i in trival_namelist:
trival.write(i+'\n')
for j in val_namelist:
val.write(j+'\n')
trival.close()
val.close()
if __name__ == '__main__':
# 将txt文件转为xml格式
translate(xmlfiles, jpgfiles, txtfiles)
# 构建voc文件格式
set_voc(xmlfiles, voc_txtfiles, weight)
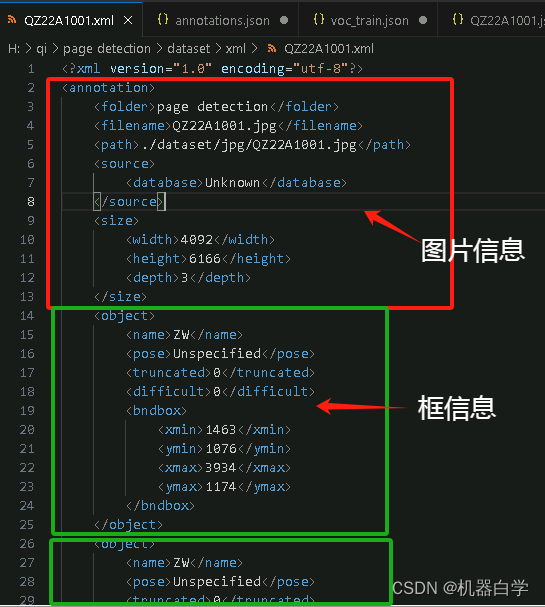
xml 文件具体格式如下图所示,其中的框信息中四个数和初始 json 文件中框信息的规则一致,显而易见,它们都是未经过归一化处理的绝对坐标信息。
2.COCO数据格式
COCO数据文件架构格式如下。其主要是按照训练样本集的类型来划分的,每个训练集下的架构一样。图片数据放在JPEGImages下,当前训练集所有的框数据汇总为一个json文件。


上述 json 文件的具体格式如下,整体是一个字典,字典里有三个键对,分别代表图片信息“images”、框信息“annotations”、类别信息“categories”。



实现上述转化的 Python 代码如下。
import os
from xml.dom.minidom import Document
import cv2
import random
from shutil import copyfile
import json
# json、jpg文件保存地址
jpg_path = '填入实际图片所在地址'
json_path = '填入实际json标注文件所在地址'
# coco数据格式保存地址:训练集、测试集、验证集
cocofiles = './coco/'
# 训练测试验证数据比重设置
weight = [0.9, 0.05, 0.05]
#####################(分界线)上述是需根据情况修改的参数,以下函数不需修改
## coco数据集构建(.json)
# 复制文件——拆分后的数据移动到对应文件夹
def copy_file(file_path_list, file_path, target_path, last_name):
for file in file_path_list:
real_path = os.path.join(file_path, file+last_name)
copyfile(real_path, target_path+file+last_name) #copyfile(文件所在地,复制目标路径)
print(file + last_name + ' success')
# 划分coco训练测试验证集
def set_train_test_val(jpgfiles, cocofiles, weight):
filelist = os.listdir(jpgfiles)
length = len(filelist)
random.shuffle(filelist)
tr_namelist = [tr[:-4] for tr in filelist[:int(weight[0] * length)]]
te_namelist = [te[:-4] for te in filelist[int(weight[0] * length):int((weight[0] + weight[1]) * length)]]
va_namelist = [va[:-4] for va in filelist[int((weight[0] + weight[1]) * length):]] # 文件basename不含格式后缀
copy_file(tr_namelist, jpgfiles, cocofiles + 'train/JPEGImages/', '.jpg') # 图片jpg训练集train
copy_file(te_namelist, jpgfiles, cocofiles + 'test/JPEGImages/', '.jpg') # 图片jpg测试集test
copy_file(va_namelist, jpgfiles, cocofiles + 'val/JPEGImages/', '.jpg') # 图片jpg验证集val
# 根据数据集生产相应annotation文件.json格式
def create_anno(cocofiles, t, jsonfiles):
jpgfile = os.path.join(cocofiles,t+'/JPEGImages/')
images = []
annotation = []
j = 0 # 框id计数
for i, jpg in enumerate(os.listdir(jpgfile)):
basename = jpg.split('.')[0]
print(basename)
# 获取图片信息:图片名;高宽;id
jpgdir = os.path.join(jpgfile, jpg)
image = cv2.imread(jpgdir)
h, w, _ = image.shape # 图片大小
jpg_dict = {"file_name": str(jpg),
"height": h,
"width": w,
"id": i}
images.append(jpg_dict)
# 获取边缘框信息:area; bbox;类别;图片id;框id
jsondir = os.path.join(jsonfiles, basename+'.json')
with open(jsondir, 'r') as f:
box_list = json.load(f)
for box in box_list:
# 框定义为左上坐标(x,y)和框的宽高
x,y,w,h = box["box"][0], box["box"][1], box["box"][2]-box["box"][0], box["box"][3]-box["box"][1]
area = w*h
box_dict ={"area": area, "iscrowd": 0,
"bbox": list((x,y,w,h)),
"category_id": 1,
"ignore": 0,
"image_id": i,
"id": j }
j += 1 # 框id计数
annotation.append(box_dict)
# 类别信息字典
categories = [{"supercategory": "none", "id": 1, "name": "ZW"}]
result = {"images":images, "annotations":annotation, "categories":categories}
savefile = os.path.join(cocofiles, t+'/annotations.json')
with open(savefile, 'w') as f:
json.dump(result, f)
print(t+' success')
if __name__ == '__main__':
# 划分数据集
set_train_test_val(jpgfiles, cocofiles, weight)
# 保存coco格式的annotations
create_anno(cocofiles, 'train', jsonfiles)
create_anno(cocofiles, 'test', jsonfiles)
create_anno(cocofiles, 'val', jsonfiles)















 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









