






目录
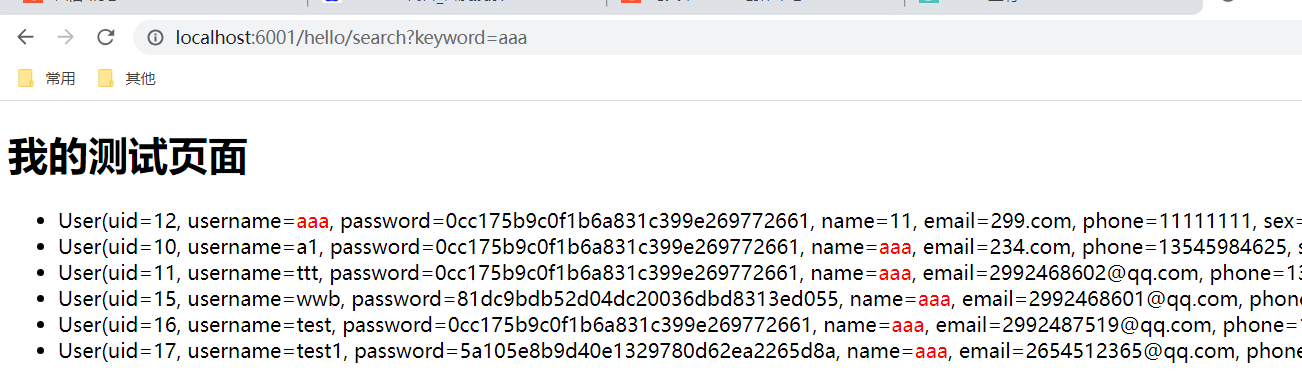
测试的效果如下

1.引入maven依赖
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.2.0</version>
</dependency>
<!-- lucene的默认分词器库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.2.0</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>8.2.0</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>8.2.0</version>
</dependency>2.索引目录存放数据
@Component
public class IndexBuilder {
//建立相应的索引目录
public void buildIndex(List<User> users) throws IOException {
Directory directory = FSDirectory.open(Paths.get("./index"));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
IndexWriter indexWriter = new IndexWriter(directory, config);
for (User user:users){
Document doc = new Document();
doc.add(new TextField("uid", user.getUid(), Field.Store.YES));
doc.add(new TextField("username", user.getUsername(), Field.Store.YES));
doc.add(new TextField("password", user.getPassword(), Field.Store.YES));
doc.add(new TextField("name", user.getName(), Field.Store.YES));
doc.add(new TextField("email", user.getEmail(), Field.Store.YES));
doc.add(new TextField("phone", user.getPhone(), Field.Store.YES));
doc.add(new TextField("sex", user.getSex(), Field.Store.YES));
doc.add(new TextField("state", user.getState(), Field.Store.YES));
doc.add(new TextField("code", user.getCode(), Field.Store.YES));
doc.add(new TextField("addr", user.getAddr(), Field.Store.YES));
indexWriter.addDocument(doc);
}
indexWriter.close();
}
}3.controller
@Autowired
private SearchService searchService;
@RequestMapping(value = "/search")
public String search(@RequestParam String keyword, Model model) throws IOException, ParseException, InvalidTokenOffsetsException {
List<User> search = searchService.search(keyword);
model.addAttribute("obj",search);
return "hello/search";
}4.处理类
@Component
public class SearchService {
@Autowired
private UserMapper mapper;
@Autowired
private IndexBuilder indexBuilder;
public List<User> search(String keyword) throws IOException, ParseException, InvalidTokenOffsetsException {
//查包含aaa
//把查到的数据丢到索引目录,用作测试,,这个索引目录应该是提前建好的
List<User> users = mapper.selectList(null);
indexBuilder.buildIndex(users);
//1.打开索引目录得到indexReader用于读取文件
List<User> results = new ArrayList<>();
Directory directory = FSDirectory.open(Paths.get("./index"));
IndexReader indexReader = DirectoryReader.open(directory);
//2.构建查询器,得到query,用于表示我要哪些字段
Analyzer analyzer = new StandardAnalyzer();
//查单个字段,比如只要content字段
//按传过来的值,在index目录下对content搜索
// QueryParser parser = new QueryParser("content", analyzer);
// Query query = parser.parse(keyword);
//多个字段
String[] fields = {"uid", "username","password","name","email","phone","sex","state","code","addr"}; // 定义多个字段
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, analyzer);
Query query = parser.parse(keyword);
//3.得到10条文档数据
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(query, 10);//查十个
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//3.对文档数据进行高亮处理
results=headle(query,scoreDocs,indexSearcher,analyzer);
indexReader.close();
directory.close();
return results;
}
//对查询结果进行处理及高亮显示
public List<User> headle(Query query,ScoreDoc[] scoreDocs,IndexSearcher searcher,Analyzer analyzer ) throws IOException, InvalidTokenOffsetsException {
// 查询高亮,对于name字段中符合keyWord的高亮
QueryScorer score = new QueryScorer(query);
List<User> results = new ArrayList<>();
// 定制高亮标签
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");
// 高亮分析器
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, score);
//对每个文档对象进行遍历
for (ScoreDoc scoreDoc : scoreDocs) {
User user=new User();
// 取出这一条文档编号
int docId = scoreDoc.doc;
// 根据编号去找文档
Document doc = searcher.doc(docId);
//一个文档对应数据库的一条记录,fields是这条记录的所以字段字段,循环字段
List<IndexableField> fields = doc.getFields();
for (IndexableField f : fields) {
//我这里对他的所有字段做高亮处理,可以通过if语句筛选
//f.name()//是这个字段的名称,如uid 等等
//如 uid 1
TokenStream tokenStream = analyzer.tokenStream(f.name(), new StringReader(doc.get(f.name())));
// 获取高亮的片段
String fieldContent = highlighter.getBestFragment(tokenStream, doc.get(f.name()));
//如果fieldContent==null,说明这个字段无需高亮显示
try {
Class<User> aClass = User.class;
Field field=aClass.getDeclaredField(f.name());
Method setNameMethod = aClass.getMethod("set" + f.name().substring(0, 1).toUpperCase() + f.name().substring(1), field.getType());
//私有方法
setNameMethod.setAccessible(true);
if (fieldContent!=null)
//通过反射调用对应的set方法
setNameMethod.invoke(user,fieldContent);
else
setNameMethod.invoke(user,doc.get(f.name()));
} catch (Exception e) {
e.printStackTrace();
}
}
results.add(user);
}
return results;
}
}















 3808
3808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









