






引擎原理
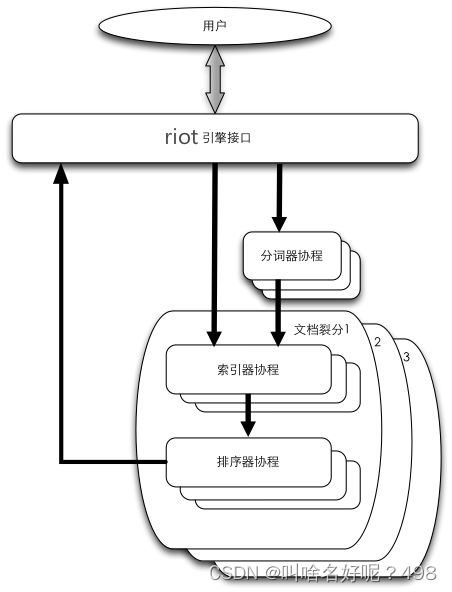
引擎中处理用户请求,分词,索引和排序分别由不同的协程完成
1.主协程,用于收发用户请求
2.分词器协程,负责分词
3.索引器协程,负责建立和查找索引表
4.排序器协程,负责对文档评分排序
索引流程
当一个将文档加入索引的请求进来以后,主协程会通过一个信道(channel)将要分词的文本发送给某个分词协程,该协程将文本分词后通过另一个信道发送给一个索引器协程。索引器协程建立从搜索键到文档的反向索引,反向索引保存在内存中
搜索流程
主协程接到用户请求,将请求短语在主协程内分词,然后通过信道发送给索引器,索引器查找每个搜索键对应的文档然后进行逻辑操作(归并求交集)得到一个精简的文档列表,此列表通过信道传递给排序器,排序器对文档进行评分(scoring)、筛选和排序,然后将排好序的文档通过指定的信道发送给主协程,主协程将结果返回给用户。
分词、索引和排序都有多个协程完成,中间结果保存在信道缓冲队列以避免阻塞。为了提高搜索的并发度降低延迟,riot 引擎将文档做了裂分(裂分数目可以由用户指定),索引和排序请求会发送到所有裂分上并行处理,结果在主协程进行二次归并排序
索引
需要用到两个包
import (
"github.com/go-ego/riot"
"github.com/go-ego/riot/types" '
)
第一个包定义了引擎的功能,第二个包定义了常用的结构体,在使用引擎前需要初始化
var searcher riot.Engine
searcher.Init(types.EngineOpts{
GseDict: "../../data/dict/dictionary.txt", //
StopTokenFile: "../../data/dict/stop_tokens.txt", //停用词词典,
IndexerOpts: &types.IndexerOpts{
IndexType: types.LocsIndex,
},
})GseDict:分词词典
作用:
字典对于提高搜索的准确性和效率至关重要,因为它帮助搜索引擎理解文档内容并快速定位到相关的词汇
StopTokenFile:停用词词典
作用:
停用词是指在搜索和索引过程中通常被忽略的词汇,因为它们对于搜索结果的相关性贡献不大。常见的停用词包括“的”、“和”、“是”等在很多语言中频繁出现但信息量较低的词汇。通过排除这些词汇,可以减少索引的大小,提高搜索速度,并且使得搜索结果更加精准。
IndexerOpts定义了索引器初始化选项
// IndexerOpts 初始化索引器选项]
type IndexerOpts struct {
// 索引表的类型,见上面的常数
IndexType int
// 待插入索引表文档 CACHE SIZE
DocCacheSize int
// BM25 参数
BM25Parameters *BM25Parameters
}
其中IndexType需要特别注意,IndexType有三种类型
- DocIdsIndex,提供了最基本的索引,仅仅记录搜索键出现的文档 docid。
- FrequenciesIndex,除了记录 docid 外,还保存了搜索键在每个文档中出现的频率,如果你需要BM25那么 FrequenciesIndex 是你需要的。
- LocsIndex,这个不仅包括上两种索引的内容,还额外存储了关键词在文档中的具体位置,这用来计算紧邻距离
// DocIdsIndex 仅存储文档的
docIdDocIdsIndex = 0
// FrequenciesIndex 存储关键词的词频,用于计算
BM25FrequenciesIndex = 1
// LocsIndex 存储关键词在文档中出现的具体字节位置(可能有多个)
// 如果你希望得到关键词紧邻度数据,必须使用 LocsIndex 类型的索引
LocsIndex = 2三种索引由上到下提供了更多的计算能力的同时也消耗了更多的内存,特别是LocsIndex,当文档很长时会占用大量内存
初始化索引完成将文章加入索引
调用searcher.Index方法将文章加入到索引中
searcher.Index(docId, types.DocData{
Content: weibo.Text, // Weibo结构体见上文的定义。必须是UTF-8格式。
Fields: WeiboScoringFields{
Timestamp: weibo.Timestamp,
RepostsCount: weibo.RepostsCount,
},
})文档的 docId 必须大于 0 且唯一,对微博来说可以直接用微博的 ID。riot 引擎允许你加入三种索引数据:
- 文档的正文(content),会被分词为关键词(tokens)加入索引。
- 文档的关键词(tokens)。当正文为空的时候,允许用户绕过 riot 内置的分词器直接输入文档关键词,这使得在引擎外部进行文档分词成为可能。
- 文档的属性标签(labels),比如微博的作者,类别等。标签并不出现在正文中。
- 自定义评分字段(scoring fields),这允许你给文档添加 任意类型 、 任意结构 的数据用于排序。“搜索”一节会进一步介绍自定义评分字段的用法。
type DocData struct {
// 文档全文(必须是 UTF-8 格式),用于生成待索引的关键词
Content string
// new 类别
// Class string
// new 属性
Attri interface{}
// 文档的关键词
// 当 Content 不为空的时候,优先从 Content 中分词得到关键词
// 并叠加
Tokens。
// Tokens 存在的意义在于可以绕过 riot 内置的分词器,在引擎外部
// 进行分词和预处理。
// Tokens []*TokenData
Tokens []TokenData
// 文档标签(必须是 UTF-8 格式),比如文档的类别属性等,
// 这些标签并不出现在文档文本中
Labels []string
// 文档的评分字段,可以接纳任何类型的结构体
Fields interface{}
}引擎采用了非同步的索引方式,也就是说当Index返回时索引可能还没有加入索引表中,这方便你循环并发地加入索引。如果你需要等待索引添加完毕再进行后续操作使用 searcher.Flush()
搜索
搜索的过程分为两步:
第一步是在索引表中查找包含搜索键的文档
实现代码:
使用搜索引擎中的SearchDoc函数,传入types.SearchReq结构体,该结构体中的RankOpts需要使用types.RankOpts结构体
output := searcher.SearchDoc(types.SearchReq{
Text: query,
RankOpts: &types.RankOpts{
ScoringCriteria: &WeiboScoringCriteria{},
OutputOffset: 0,
MaxOutputs: 2,
},
})types.SearchReq结构体详细
type SearchReq struct {
// 搜索的短语(必须是 UTF-8 格式),会被分词
// 当值为空字符串时关键词会从下面的 Tokens 读入
Text string
// 关键词(必须是 UTF-8 格式),当 Text 不为空时优先使用 Text
// 通常你不需要自己指定关键词,除非你运行自己的分词程序
Tokens []string
// 文档标签(必须是 UTF-8 格式),标签不存在文档文本中,
// 但也属于搜索键的一种
Labels []string
// 类别
// Class string
// Logic 逻辑检索表达式
Logic Logic
// 当不为 nil 时,仅从这些 DocIds 包含的键中搜索(忽略值)
DocIds map[string]bool
// 排序选项
RankOpts *RankOpts
// 超时,单位毫秒(千分之一秒)。此值小于等于零时不设超时。
// 搜索超时的情况下仍有可能返回部分排序结果。
Timeout int
// 设为 true 时仅统计搜索到的文档个数,不返回具体的文档
CountDocsOnly bool
// 不排序,对于可在引擎外部(比如客户端)排序情况适用
// 对返回文档很多的情况打开此选项可以有效节省时间
Orderless bool
}types.RankOpts结构体详细
type RankOpts struct {
// 文档的评分规则,值为 nil 时使用 Engine 初始化时设定的规则
ScoringCriteria ScoringCriteria
// 默认情况下(ReverseOrder = false)按照分数从大到小排序,否则从小到大排序
ReverseOrder bool
// 从第几条结果开始输出
OutputOffset int
// 最大输出的搜索结果数,为 0 时无限制
MaxOutputs int
}第二步是对所有索引到的文档进行排序
对所有搜索到的文档,需要进行排序, 按照每个文档的评分来进行排序
riot支持自定义评分规则
微博搜索的例子(评分规则)
- 首先按照关键词紧邻距离排序,比如搜索“自行车运动”,这个短语会被切分成两个关键词,“自行车”和“运动”,出现两个关键词紧邻的文章应该排在两个关键词分开的文章前面。
- 然后按照微博的发布时间大致排序,每三天为一个梯队,较晚梯队的文章排在前面。
- 最后给微博打分为 BM25*(1+转发数/10000)
实现举例
// WeiboScoringFields weibo scoring fields
type WeiboScoringFields struct {
Timestamp uint64
RepostsCount uint64
}
// WeiboScoringCriteria custom weibo scoring criteria
type WeiboScoringCriteria struct {
}
// Score score and sort
func (criteria WeiboScoringCriteria) Score(
doc types.IndexedDoc, fields interface{}) []float32 {
if reflect.TypeOf(fields) != reflect.TypeOf(WeiboScoringFields{}) {
return []float32{}
}
wsf := fields.(WeiboScoringFields)
output := make([]float32, 3)
if doc.TokenProximity > MaxTokenProximity {
output[0] = 1.0 / float32(doc.TokenProximity)
} else {
output[0] = 1.0
}
output[1] = float32(wsf.Timestamp / (SecondsInADay * 3))
output[2] = float32(doc.BM25 * (1 + float32(wsf.RepostsCount)/10000))
return output
}WeiboScoringCriteria 实际上继承了 types.ScoringCriteria 接口,这个接口实现了 Score 函数。这个函数带有两个参数:
- types.IndexedDoc 参数传递了从索引器中得到的数据,比如词频,词的具体位置,BM25值,紧邻度等信息,具体见types/index.go
- 第二个参数是 interface{} 类型的,你可以把这个类型理解成 C 语言中的 void 指针,它可以指向任何数据类型。在我们的例子中指向的是 WeiboScoringFields 结构体,并通过反射机制检查是否是正确的类型。
需要实现该接口的Score方法
package types
// ScoringCriteria 评分规则通用接口
type ScoringCriteria interface {
// 给一个文档评分,文档排序时先用第一个分值比较,如果
// 分值相同则转移到第二个分值,以此类推。
// 返回空切片表明该文档应该从最终排序结果中剔除。
Score(doc IndexedDoc, fields interface{}) []float32
}
// RankByBM25 一个简单的评分规则,文档分数为BM25
type RankByBM25 struct {
}
// Score score
func (rule RankByBM25) Score(doc IndexedDoc, fields interface{}) []float32 {
return []float32{doc.BM25}
}有了自定义评分数据和自定义评分规则,就可以进行检索,
将自定义评分规则加入到,riot引擎中的Search方法中的types.SearchReq结构体参数中的RankOpts中
response := searcher.Search(types.SearchReq{
Text: "自行车运动",
RankOpts: &types.RankOpts{
ScoringCriteria: &WeiboScoringCriteria{},
OutputOffset: 0,
MaxOutputs: 100,
},
})其中,Text是输入的搜索短语(必须是UTF-8格式),会被分词为关键词。和索引时相同,riot 引擎允许绕过内置的分词器直接输入关键词和文档标签,见 types.SearchReq 结构体的注释。RankOpts 定义了排序选项。WeiboScoringCriteria 就是我们在上面定义的评分规则。另外你也可以通过 OutputOffset 和 MaxOutputs 参数控制分页输出。搜索结果保存在 response 变量中















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









