






一、历史服务器JobHistory
为了查看程序的历史运行情况,需要配置一下历史服务器。在重启hadoop后All Applications 也就是我们之前配置的hadoop103:8088端口是无法查看历史信息的
1)配置mapred-site.xml
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ vim mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
2)分发配置
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ xsync mapred-site.xml
配置好后通过我们写的插件jpsall即可查看历史服务器是否启动
配置前

配置启动后
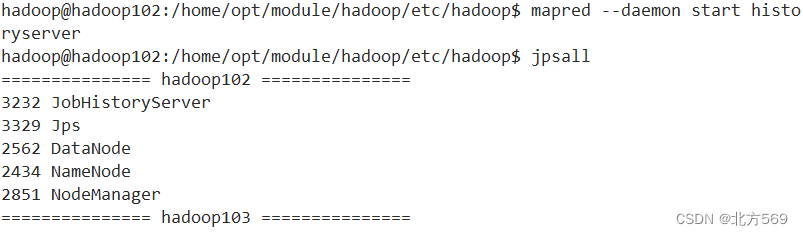
3)在hadoop102启动历史服务器
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ mapred --daemon start historyserver
4)查看历史服务器是否启动
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ jpsall
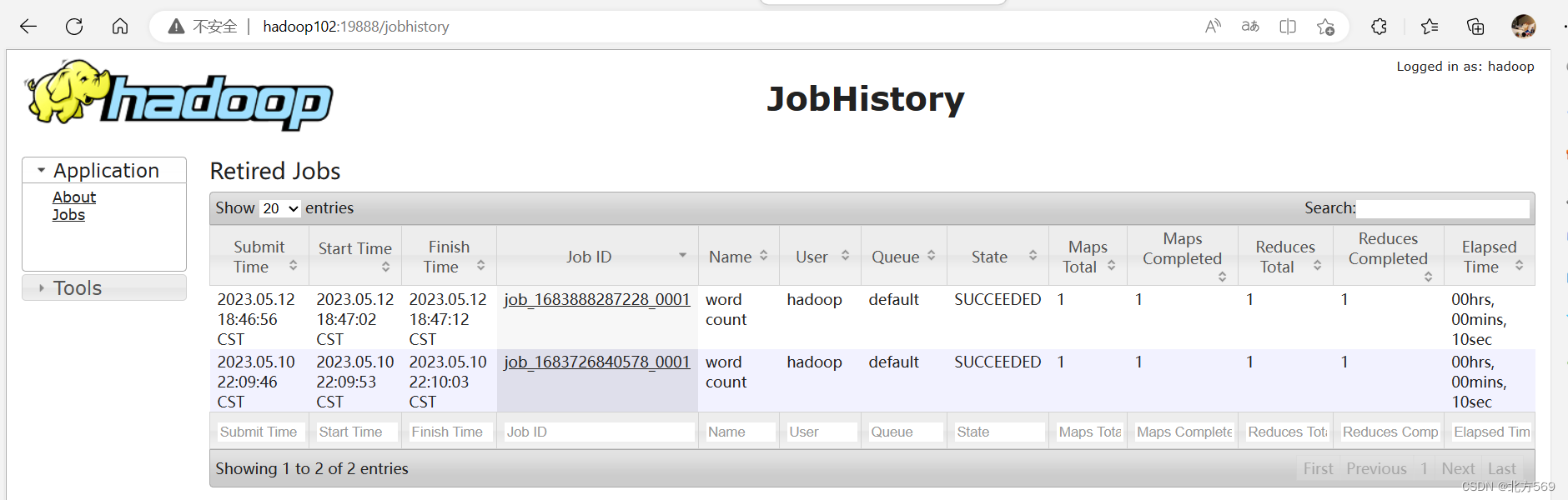
5)查看JobHistory
刚开始配置好jobhistory,web端是没有东西的我这里先运行了一个任务实验了一下
http://hadoop102:19888/jobhistoryy![]() http://hadoop102:19888/jobhistory
http://hadoop102:19888/jobhistory
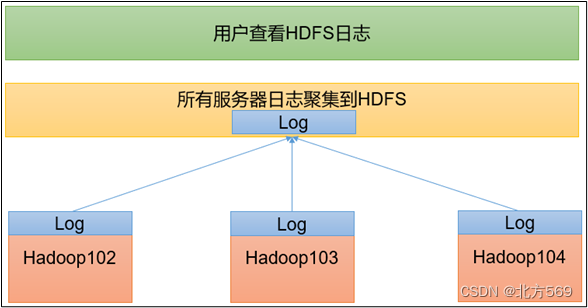
二、日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
1)配置yarn-site.xml
(1)在yarn-site.xml中加入以下内容
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ vim yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(2)分发配置:给其他虚拟机配置,使用我们自己写的基于rsync的shell插件
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ xsync yarn-site.xml
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
(3)使用myhadoop.sh 脚本重新启动hadoop并重启历史服务器
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ myhadoop.sh stop
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$mapred --daemon stop historyserver======启动 hadoop集群 =======
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ myhadoop.sh start
hadoop@hadoop102:/home/opt/module/hadoop/etc/hadoop$ mapred --daemon start historyserver
2)先在ubuntu运行一次wordcount任务,使你的历史服务器里面有历史任务
/output2:输出,因为第一次处理时生成了output文件夹,不能重复使用
hadoop@hadoop102:/home/opt/module/hadoop$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2
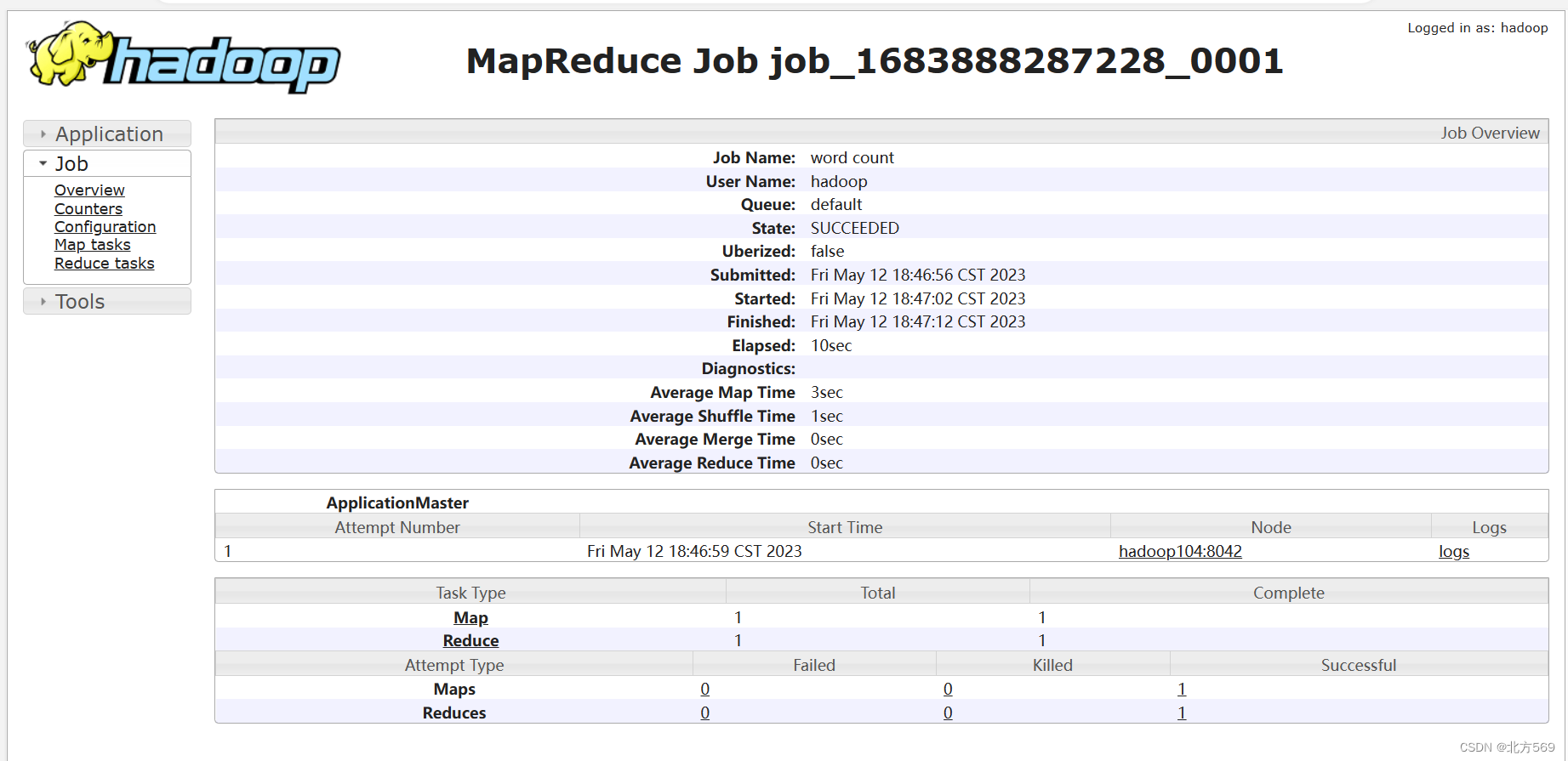
3)在浏览器进入JobHistory, 点击任务job ID进入job界面
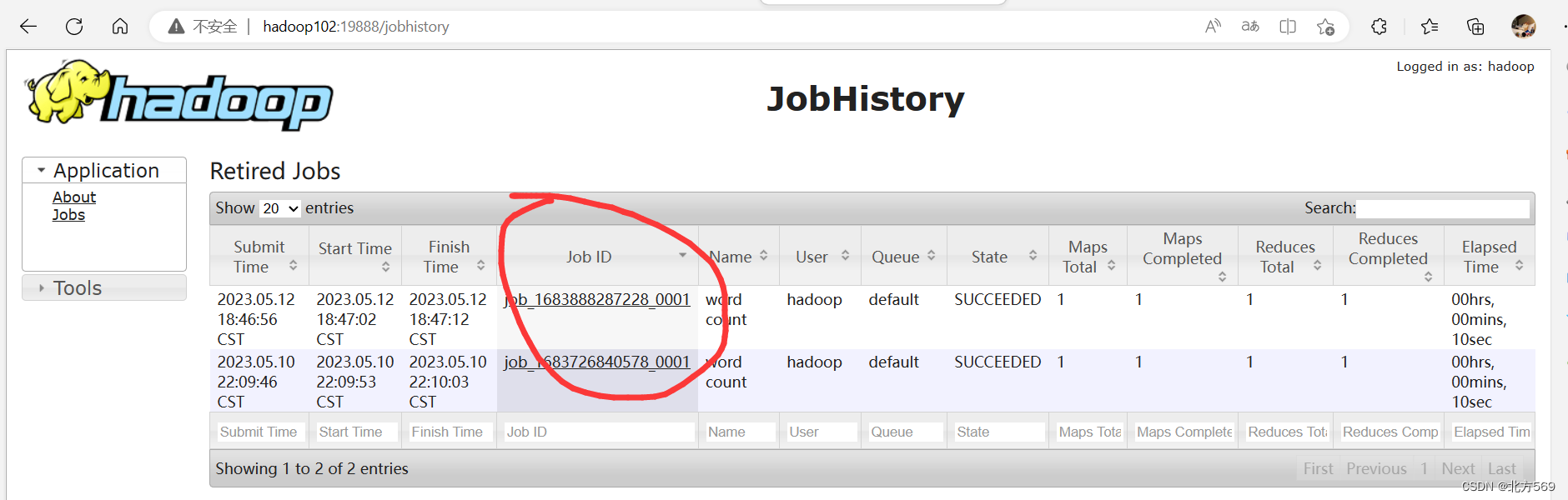
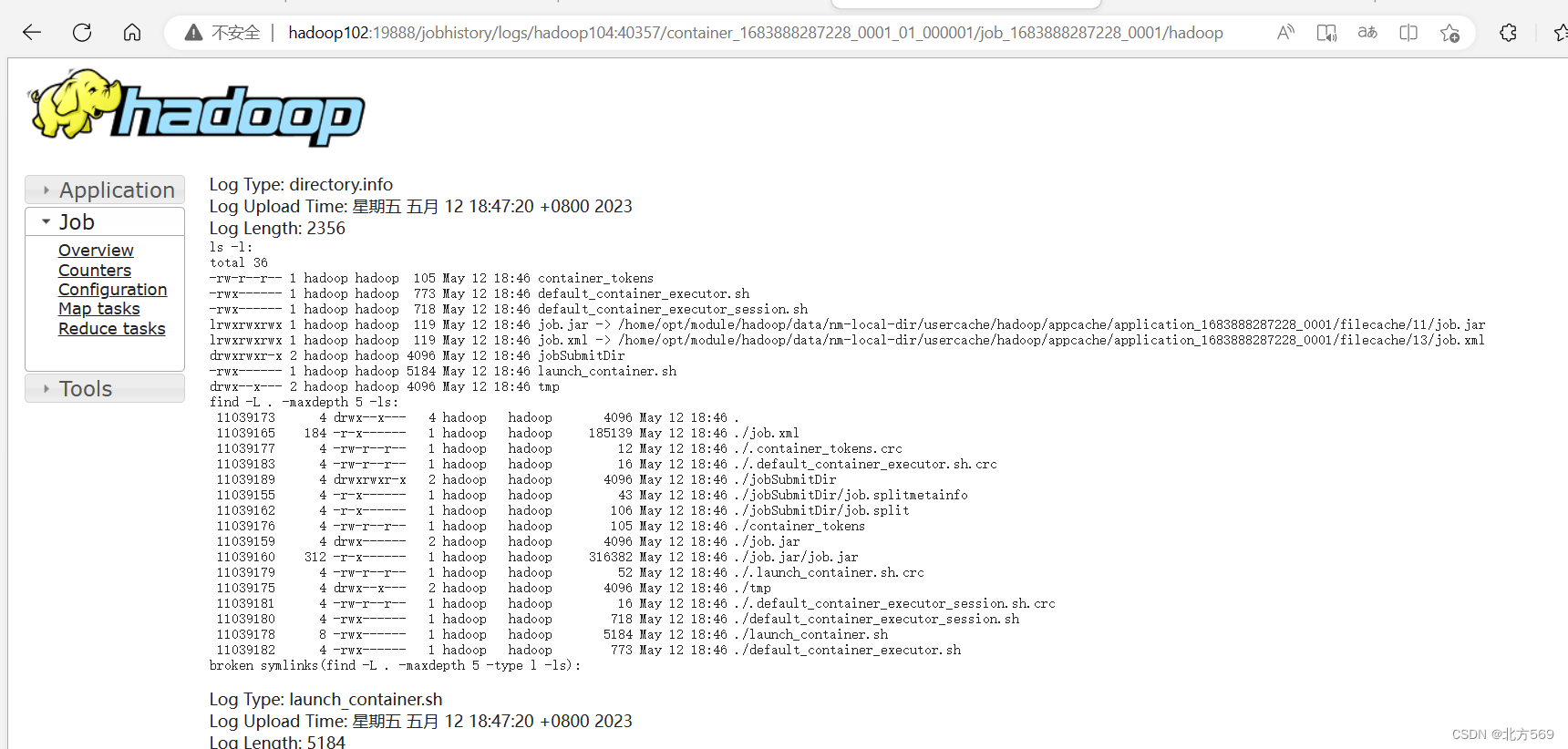
点击log:因为在配置yarn-site.xml时把日志配置到log里面因此点击log即可看到文件日志
















 3430
3430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











