






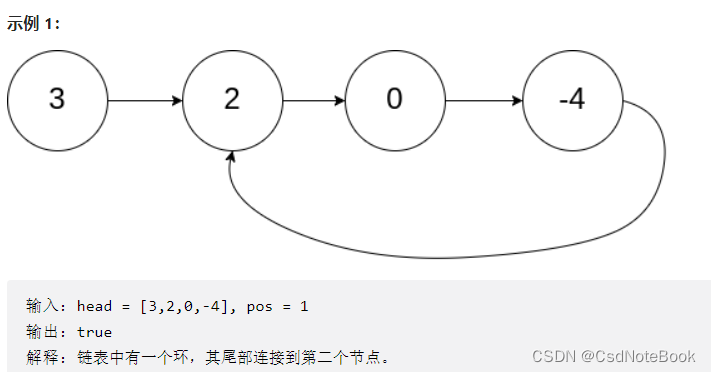
方法一:哈希表
遍历所有节点,每次遍历到一个节点时,判断该节点此前是否被访问过。
具体地,我们可以使用哈希表来存储所有已经访问过的节点。每次我们到达一个节点,如果该节点已经存在于哈希表中,则说明该链表是环形链表,否则就将该节点加入哈希表中。重复这一过程,直到我们遍历完整个链表即可
struct hashTable {
struct ListNode* key; //链表结点
UT_hash_handle hh;
};
struct hashTable* hashtable;
struct hashTable* find(struct ListNode* ikey) { //查找
struct hashTable* tmp;
HASH_FIND_PTR(hashtable, &ikey, tmp);
return tmp;
}
void insert(struct ListNode* ikey) { //插入
struct hashTable* tmp = malloc(sizeof(struct hashTable));
tmp->key = ikey;
HASH_ADD_PTR(hashtable, key, tmp); //添加
}
//以上的创建哈希表、find、insert的代码基本都一样,可以当模板记住
bool hasCycle(struct ListNode* head) {
hashtable = NULL;
while (head != NULL) { //遍历每个结果
if (find(head) != NULL) {//通过find查找,如果哈希表中存在,则是环
return true;
}
insert(head); //如果哈希表中不存在,则插入到哈希表中
head = head->next; //并且把头结点给下一个元素,继续遍历
}
return false;
}

方法二:快慢指针
Floyd 判圈算法(又称龟兔赛跑算法)
具体地,我们定义两个指针,一快一慢。慢指针每次只移动一步,而快指针每次移动两步。初始时,慢指针在位置 head,而快指针在位置 head.next。这样一来,如果在移动的过程中,快指针反过来追上慢指针,就说明该链表为环形链表。否则快指针将到达链表尾部,该链表不为环形链表。
为什么我们要规定初始时慢指针在位置 head,快指针在位置 head.next,而不是两个指针都在位置 head(即与「乌龟」和「兔子」中的叙述相同)?
观察下面的代码,我们使用的是 while 循环,循环条件先于循环体。由于循环条件一定是判断快慢指针是否重合,如果我们将两个指针初始都置于 head,那么 while 循环就不会执行。因此,我们可以假想一个在 head 之前的虚拟节点,慢指针从虚拟节点移动一步到达 head,快指针从虚拟节点移动两步到达 head.next,这样我们就可以使用 while 循环了。
当然,我们也可以使用 do-while 循环。此时,我们就可以把快慢指针的初始值都置为 head。
bool hasCycle(struct ListNode* head) {
if (head == NULL || head->next == NULL) {
return false;
}
struct ListNode* slow = head;
struct ListNode* fast = head->next;
while (slow != fast) {
if (fast == NULL || fast->next == NULL) {
return false;
}
slow = slow->next;
fast = fast->next->next;
}
return true;
}

















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











