







 本文详细介绍了常见的敏感词过滤方法,包括Trie树(前缀树)和DFA算法的应用,以及Aho-Corasick自动机的扩展。重点推荐了sensitive-word框架,它基于DFA算法实现高效敏感词检测和处理,还涵盖了正则表达式过滤作为备选方案。
本文详细介绍了常见的敏感词过滤方法,包括Trie树(前缀树)和DFA算法的应用,以及Aho-Corasick自动机的扩展。重点推荐了sensitive-word框架,它基于DFA算法实现高效敏感词检测和处理,还涵盖了正则表达式过滤作为备选方案。
常见敏感词过滤方案汇总
目前大多数使用的系统需要对用户输入的文本进行敏感词过滤如色情、政治、暴力相关的词汇。
敏感词过滤成为了我们系统设计不可或缺的一部分
常见的敏感词过滤方法主要是 Trie 树算法 和 DFA 算法,本文主要就是介绍这两种算法+常用的框架介绍
Trie 树(前缀树)
Trie 树也称为前缀树、字典树、单词查找树,哈系树的一种变种,通常被用于字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。像浏览器搜索的关键词提示一般就是基于 Trie 树来做的
现在假设我们的敏感词库中有以下敏感词:
- 敏感词
- 敏感语
- 傻子
- 傻瓜
我们构造出来的敏感词 Trie 树就是下面这样的:
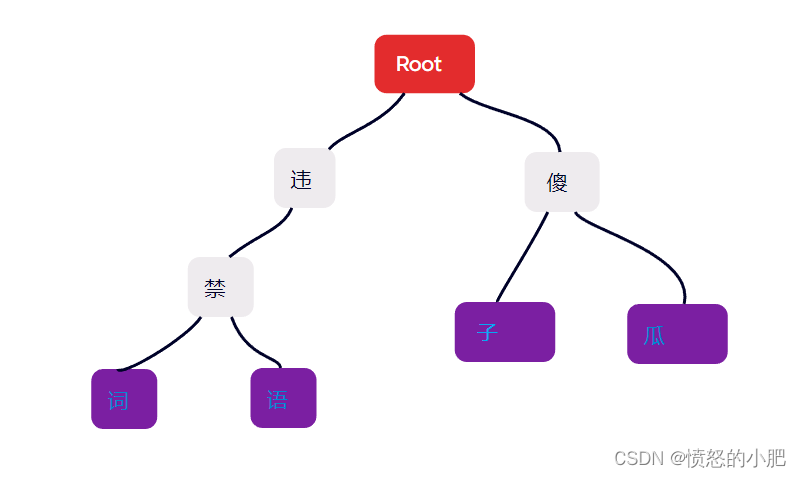
当我们要查找对应的字符串“敏感词”的话,我们会把这个字符串切割成单个的字符“敏”、“感”、“词”,然后我们从 Trie 树的根节点开始匹配。
可以看出, Trie 树的核心原理就是通过公共前缀来提高字符串匹配效率。
Apache Commons Collecions 这个库中就有 Trie 树实现
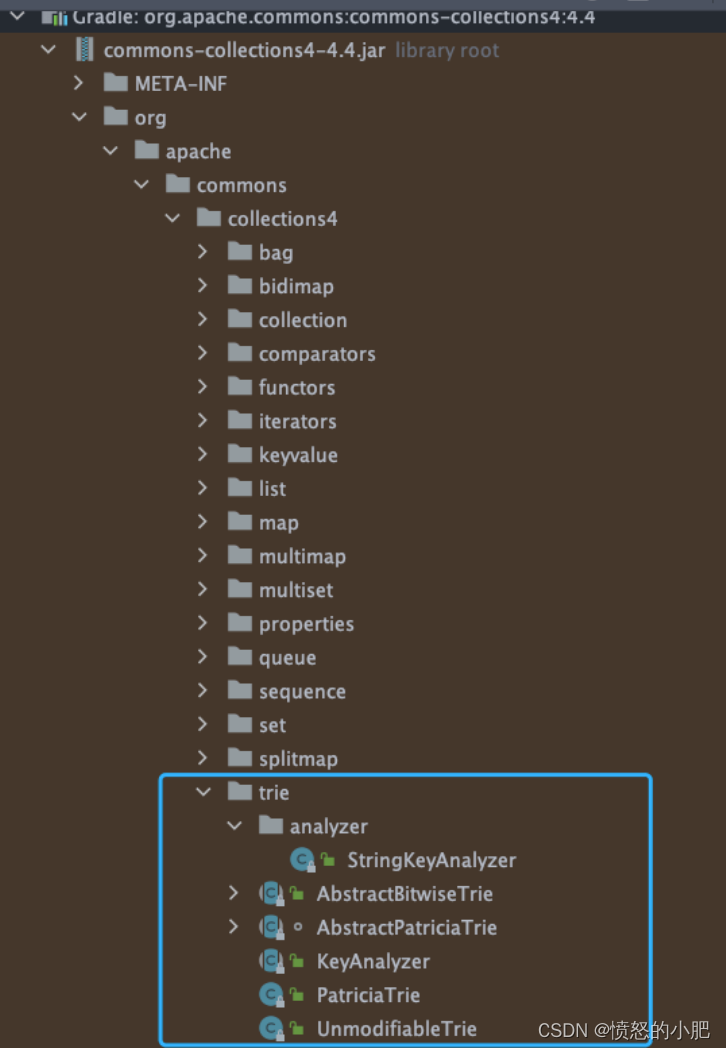
我们举代码为例:
Trie<String, String> trie = new PatriciaTrie<>();
trie.put("Abigail", "student");
trie.put("Abi", "doctor");
trie.put("Annabel", "teacher");
trie.put("Christina", "student");
trie.put("Chris", "doctor");
Assertions.assertTrue(trie.containsKey("Abigail"));
assertEquals("{Abi=doctor, Abigail=student}", trie.prefixMap("Abi").toString());
assertEquals("{Chris=doctor, Christina=student}", trie.prefixMap("Chr").toString());
扩展内容:Aho-Corasick(AC)自动机是一种建立在 Trie 树上的一种改进算法,是一种多模式匹配算法,由贝尔实验室的研究人员 Alfred V. Aho 和 Margaret J.Corasick 发明。AC 自动机算法使用 Trie 树来存放模式串的前缀,通过失败匹配指针(失配指针)来处理匹配失败的跳转。
相关文章链接:地铁十分钟 | AC 自动机
DFA算法
DFA(Deterministic Finite Automata)即确定有穷自动机,与之对应的是 NFA(Non-Deterministic Finite Automata,不确定有穷自动机)。
关于 DFA 的详细介绍可以看这篇文章:有穷自动机 DFA&NFA (学习笔记) - 小蜗牛的文章 - 知乎
我们常用的hutool工具包中就有相关的DFA算法的实现:

我们举代码为例:
WordTree wordTree = new WordTree();
wordTree.addWord("大傻子");
wordTree.addWord("大猪头");
wordTree.addWord("猪头");
wordTree.addWord("大傻");
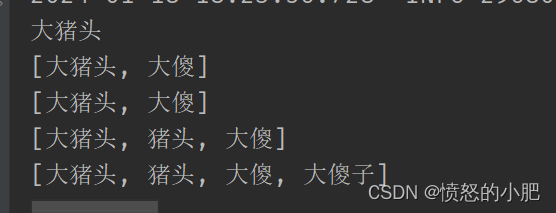
String text = "我真是个大猪头大傻子!";
// 获得第一个匹配的关键字
String matchStr = wordTree.match(text);
System.out.println(matchStr);
// 标准匹配,匹配到最短关键词,并跳过已经匹配的关键词
List<String> matchStrList = wordTree.matchAll(text, -1, false, false);
System.out.println(matchStrList);
//匹配到最长关键词,跳过已经匹配的关键词
List<String> matchStrList2 = wordTree.matchAll(text, -1, false, true);
System.out.println(matchStrList2);
List<String> matchStrList3 = wordTree.matchAll(text, -1, true, false);
System.out.println(matchStrList3);
List<String> matchStrList4 = wordTree.matchAll(text, -1, true, true);
System.out.println(matchStrList4);
其中matchAll的参数分别是:
- text:匹配的段落
- limit:匹配关键词的上限(-1表示无上限)
- isDensityMatch:是否跳过已经匹配的关键词
- isGreedMatch:是否贪婪匹配(同一个词词取匹配到最长的关键词)
以上代码结果如下:
sensitive-word 框架
sensitive-word 是一款基于 DFA 算法实现的高性能敏感词工具。
github官网地址:https://github.com/houbb/sensitive-word
特性:
- 6W+ 词库,且不断优化更新
- 基于 fluent-api 实现,使用优雅简洁
- 基于 DFA 算法,性能为 7W+ QPS,应用无感
- 支持敏感词的判断、返回、脱敏等常见操作
- 支持常见的格式转换
- 全角半角互换、英文大小写互换、数字常见形式的互换、中文繁简体互换、英文常见形式的互换、忽略重复词等
- 支持敏感词检测、邮箱检测、数字检测、网址检测等
- 支持自定义替换策略
- 支持用户自定义敏感词和白名单
- 支持数据的数据动态更新(用户自定义),实时生效
- 支持敏感词的标签接口
- 支持跳过一些特殊字符,让匹配更灵活

快速开始
maven引入:
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>sensitive-word</artifactId>
<version>0.12.0</version>
</dependency>
核心方法
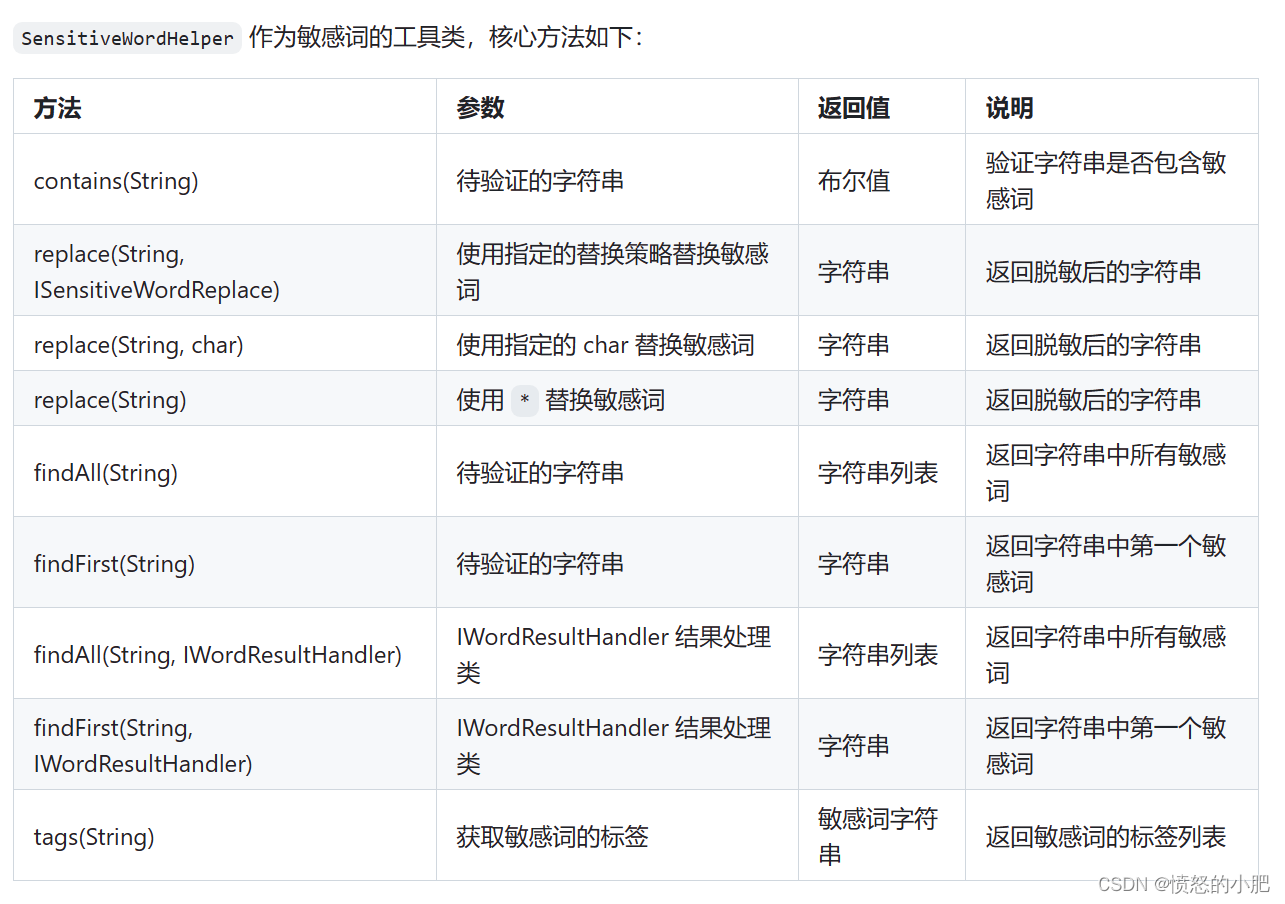
代码示例:
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前";
//判断是否包含敏感词
boolean result = SensitiveWordHelper.contains(text);
System.out.println(result);
//返回第一个敏感词
String word = SensitiveWordHelper.findFirst(text);
System.out.println(word);
//返回所有敏感词
List<String> wordList = SensitiveWordHelper.findAll(text);
System.out.println(wordList);
//默认的替换策略
String replace = SensitiveWordHelper.replace(text);
System.out.println(replace);
//指定替换内容
String replace1 = SensitiveWordHelper.replace(text, '0');
System.out.println(replace1);
结果如下:

更多方法以及自定义替换策略可以查看官网~
正则表达式过滤
除了上面两种算法过滤敏感词,其实还有公司使用的是前端正则表达式的模式来匹配敏感词
简单案例:
let textarea = document.querySelector("textarea");
let btn = document.querySelector("button");
let p = document.querySelector("p");
let reg = /傻子|坏蛋/g; //全局过滤词
btn.addEventListener('click', function() {
var text = textarea.value.replace(reg, '*') //把敏感词替换成*
p.innerText = text;
})
这里就不过多介绍了,总之还是要根据自己的实际情况取选择相对应的方法,对于Java开发的大多数项目来说使用sensitive-word工具可以满足绝大部分需求了!
参考:https://javaguide.cn/system-design/security/sentive-words-filter.html

















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









