






一、异常
1.1java中的异常
编译异常:类找不到、文件找不到、sql异常......
- ClassNotFoundException:类找不到的异常
- FileNotFoundException:文件找不到的异常
- SQLException:数据库操作异常
- TimeoutException:执行超时异常
- NoSuchMethodException:没有匹配的方法异常
- NoSuchFieldException:没有匹配的属性异常
运行异常:数组下标越界异常、空指针异常......
- ArithmeticException :异常算术条件时抛出。 例如,“除以零”的整数会抛出此类的一个实例。
-
ClassCastException:表示代码尝试将对象转换为不属于实例的子类。(比如:多态中的向下转型)。
-
DateTimeException:用于在计算日期时间时指示问题的异常。该异常用于指示创建,查询和操作日期时间对象的问题。
-
IndexOutOfBoundsException分为ArrayIndexOutOfBoundsException表示使用非法索引访问数组。 索引为负数或大于或等于数组的大小。还有StringIndexOutOfBoundsException抛出String方法来指示索引为负或大于字符串的大小。 对于某些方法(如charAt方法),当索引等于字符串的大小时,也会抛出此异常。
-
NullPointerException:当应用程序尝试在需要对象的情况下使用null时抛出。 这些包括:
- 调用一个
null对象的实例方法。 - 访问或修改
null对象的字段。 - 取
null的长度,好像是一个数组。 - 访问或修改的时隙
null就好像它是一个数组。 - 投掷
null好像是一个Throwable价值。
- 调用一个
1.2Throwable
Throwable类是Java语言中所有错误和异常的Throwable类。其中它有2个直接子类,分别为Error(错误)和Excption(异常)。
构造方法:
- Throwable();无参的构造方法,抛出异常信息的值为null一个throwable对象;
- Throwable(String message);有参构造,抛出的异常是一个message;
补充:
- 通过构造方法可以实例化出对象。
- 看方法要看三点: 方法的功能 、方法的参数 、方法的返回值。
普通方法:
- String getMessage();获取异常信息字符串;
- String toString();获取描述错误的字符串;
- void printStackTrace();展示异常信息的前因后果(提供堆printSuppressed()打印的堆栈跟踪信息)。
package com.abc.b_throwable;
public class Test {
public static void main(String[] args) {
Throwable throwable = new Throwable();
Throwable throwable2 = new Throwable("错啦");
String mess = throwable.getMessage();
System.out.println(mess);
String mess1 = throwable2.getMessage();
System.out.println(mess1);
//toString
String str1 = throwable.toString();
System.out.println(str1);
String str2 = throwable2.toString();
System.out.println(str2);
//printStackTrace();
throwable2.printStackTrace();
}
}
1.3异常
代码在运行的时候,可能会出现不可预知的错误或异常。我们想让代码正常执行,所以要对出现异常代码进行处理。处理的时候分为两种方式:一种是捕捉,另外一种是抛出。
1.3.1捕获异常
在程序运行过程中可能会出现代码的异常。如果没有异常,就正常执行。有异常的话就进行捕捉,然后进行下一步的操作。
基本语法格式有以下5种:
//第一种语法格式
try {
有可能出现的异常代码
} catch(异常对象) {
针对上面异常的处理方案
}//第二种语法格式
try {
有可能出现的异常代码
} catch(异常对象) {
针对上面异常的处理方案
} catch(另外一个异常对象) {
针对另一个异常的处理方案
}//第3种语法格式
try {
有可能出现的异常代码
} catch(异常对象1 | 异常对象2) {
针对上面异常的处理方案
} //第4语法格式
try {
有可能出现的异常代码
} catch(Exception e) {
针对上面异常的处理方案
}
开发中用这个//第5种语法格式
try {
有可能出现的异常代码
} catch(Exception e) {
针对上面异常的处理方案
} finally{
无论有没有异常都要执行的
}案例演示:
package com.abc.exception;
public class Test2 {
public static void main(String[] args) {
test(3, 1, new int[4]);
}
public static void test (int a, int b, int[] arr) {
//解决方案 捕捉
try {
int ret = a / b;
arr[2] = 20;
System.out.println(ret);
} catch (Exception e) {
// TODO: handle exception
System.out.println(e.getMessage());
} finally {
System.out.println("你无论报错与否,我都要执行。");
}
System.out.println("789");
}
}
1.3.2抛出异常
在代码有可能出现异常的地方进行抛出,使用两个关键字:
- throw:在方法中抛出异常对象。
- throws:用在方法的声明的位置,告知调用者当前抛出的异常有哪些。
在代码中专门让它报错的,如果条件不满足的话,就让它抛出一个异常。
异常分为:运行时异常,编译时异常。
package com.abc.c_exception;
public class TTest3 {
//告知调用者下面的代码可能有异常,要小心
public static void main(String[] args) throws ArithmeticException {
// try {
// test(1, 0);
// } catch (Exception e) {
// // TODO: handle exception
// System.out.println("b为0了");
// }
//
test(1, 1);
}
public static void test (int a, int b){
if (b == 0) {
//throw 抛出一个异常的对象
//ArithmeticException 运行时异常
throw new ArithmeticException();
}
System.out.println("123");
}
}
package com.abc.exception;
import java.io.IOException;
public class Test5 {
public static void main(String[] args) throws IOException {
test1(3, 1);
}
public static void test1 (int a, int b) throws IOException {
if (a > b) {
//IOException 编译时异常 抛出的话,在方法的声明出 抛咱们的异常
throw new IOException();
}
}
}
1.4自定义异常
java中给咱们提供了很多异常类,但是有的时候还是满足不了咱们代码中异常。生活中的有一些逻辑是无法使用java封装好的异常类。那么就自定义一个异常,新建一个类去继承Exception。
package com.abc.textexception;
//自定义一个异常类
class AgeInputIllegalException extends Exception{
public AgeInputIllegalException() {
}
public AgeInputIllegalException(String message) {
super(message);
}
}
public class TestException {
public static void main(String[] args) throws AgeInputIllegalException {
age(156);
}
//编译时异常
public static void age(int age) throws AgeInputIllegalException {
if(age > 150) {
throw new AgeInputIllegalException("输入的年龄不合法。");
}
}
}
二、String类
2.1变量的存放位置
package com.abc.d_string;
public class Test1 {
public static void main(String[] args) {
//声明一个字符串
//name name2变量被存在了栈区
//"小明" 常量池
String name = "小明";
String nam2 = "小明";
System.out.println(name);
//name1 name3 引用 存在栈区,等号右边在堆区
String name1 = new String("小红");
String name3 = new String("小红");
System.out.println(name1);
}
}
String str1 = "小明";小明存在常量池中;
String name1 = new String("小红");等号左边(对象的引用)存放在栈中,等号右边(真正的数据)存放在堆中。小红是存在堆中的。
2.2==和equals ()的使用和区别
package com.abc.d_string;
public class Test {
public static void main(String[] args) {
String str1 = "小明";
String str2 = "小明";
String str3 = new String("小明");
String str4 = new String("小明");
System.out.println(str1);
System.out.println(str2);
System.out.println(str3);
System.out.println(str4);
//== 判断内存地址和内容,以后开发不用。因为太严格了
System.out.println(str1 == str2);
System.out.println(str1 == str3);
System.out.println(str3 == str4);
//String 类给咱们提供了一个方法 equals 开发必用!!!
//就是为了比较两个字符串的内容,以后千万你记住比较两个字符串的时候用euqals
System.out.println(str1.equals(str3));
System.out.println(str3.equals(str4));
}
}
- ==不仅比较字符串的内容,也比较内存地址,若两者都相等,返回ture,若有其中一个不相等,则返回false;
- equals():仅仅比较字符串的内容,只要字符串的内容相同,则返回ture ,否则返回false。
2.3String类常用的方法
- 获取字符串长度 int length();
- 获取特定位置的字符 char charAt(int index);
- 获取特定字符的位置 int indexOf(char ch); int indexOf(String str);
- 获取指定字符最后一个的位置 int lastIndexOf(char ch);
- 字符串的拼接 concat();
package com.abc.string;
public class Test1 {
public static void main(String[] args) {
String str1 = "多复习会有惊喜哦";
System.out.println(str1.length());//7
System.out.println(str1.charAt(3));
String str2 = "开心❤爱心";
//获取指定字符的下标
System.out.println(str2.indexOf('心'));
//如果当前字符不再字符串中返回值是-1
System.out.println(str2.indexOf("爱护"));
String str3 = "嘻嘻哒嘻嘻哒";
System.out.println(str3.lastIndexOf("嘻嘻"));
}
}
返回值是布尔类型的方法
- 是否以指定的字符结束 boolean endsWith(String str);
- 判断一个字符串是否为空 boolean isEmpty();
- 是否包含指定的字符串 boolean contains(String str);
- 忽略大小写是否相等 boolean eaqualsIgnoreCase(String otherStrinf);
package com.abc.string;
public class Test2 {
public static void main(String[] args) {
//是否以指定的字符串结尾
System.out.println("demo.java".endsWith("va"));
System.out.println("bhjsjsxjk".isEmpty());
//如果在字符串里面打印一个空格,字符串不为空
System.out.println("".isEmpty());
//是否包含指定的字符串
System.out.println("java2115".contains("a21"));
System.out.println("abcd".equals("ABCD"));//false
System.out.println("abcs".equalsIgnoreCase("AbCs"));
}
}
- 将字符数组转为字符串:
String(char[] chs);
String(char[] chs, int offset, int count)
static String valueOf(char[] chs);
- 将字符串转为字符数组:
char[] toCharArray();
package com.abc.a_string;
public class Test3 {
public static void main(String[] args) {
char[] ch = {'好', '困', '啊'};
String string = new String(ch);//将字符数组转为字符串
System.out.println(string);
char[] ch1 = {'你', '好', '可', '爱','呀'};
//offset 偏移量
//count 要转为字符串的字符的个数
String str1 = new String(ch1, 0, 2);
System.out.println(str1);
String string2 = String.valueOf(ch1);
System.out.println(string2);
String string3 = "好好学习,天天向上!";
char[] chs = string3.toCharArray();
System.out.println(chs);
//遍历
for (int i = 0; i < chs.length; i++) {
System.out.println(chs[i]);
}
// for (char c : chs) {
// System.out.println(c);
// }
}
}
- 字符串替换 String replace(char oldChar, char newChar);
String replaceAll(String old, String new);
- 切割字符串:String[] split(String regex);
- 截取字符串:String subString(int beginIndex);
String subString(int beginIndex, int endIndex); 要头不要尾
- 将小写字母转为大写字母:String toUpperCase();
- 将大写字母转为小写字母:String toLowerCase();
- 去除收尾空格的:String trim();
package com.abc.a_string;
public class Demo4 {
public static void main(String[] args) {
//替换方法
System.out.println("abcded".replace('d', '中'));
System.out.println("shjsjn".replace("h", "中国"));
System.out.println("abcdef".replaceAll("ab", "AB"));
//切割字符串
String str1 = "嘻嘻哒,呵呵哒,哈哈哒";
String[] strings = str1.split(",");
// for (int i = 0; i < strings.length; i++) {
// System.out.println(strings[i]);
// }
System.out.println("abcdef".substring(1));//包含1
System.out.println("0123456".substring(2, 5));//包含2 不包含5
//要头不要尾
//小写转为大写
System.out.println("abcdED".toUpperCase());
//大写转小写
System.out.println("ABCDer".toLowerCase());
String string = " nb hb\t\t";
System.out.println(string);
System.out.println(string.trim());
}
}
三、泛型
3.1、为什么要使用泛型
在实际开发中对于数据一致性的要求是比较重要的。例如:int[] arr = new int[5];
在向arr这个数组容器中添加数据的时候,必须要放int类型的数据,不能放其他类型的数据,这就是数据一致性的特点。
而集合类似数组,就是可以向集合中添加数据的。数组对数据个数有限制,所以开中一般不用数组,用集合。
3.2、集合的优点
- 保证数据一致性
- 操作统一化
- 具有普适性
- 避免了强转出现错误
案例:
package com.abc.fanxing;
import java.util.ArrayList;
/**
* 在java中堆数据的一致性的要求是比较看中的,
* 在开发中很少使用数组,因为数组在定义的时候就指定了数组的容量,所以很少用
*一般在实际将开发中都是使用集合
*集合:我们可以把它想象成一个容器,这个容量是可以存方法数据的
* @author 紫色的贝壳
*
*/
public class Test1 {
public static void main(String[] args) {
int[] arr = new int[4];//创建一个容量为4的int类型的数组
String[] strings = new String[5];//创建一个容量为5的String类型的数组
ArrayList arrayList = new ArrayList();//ArrayList是java中封装好的一个集合类,那么arrayList就是这个类的对象,可以用来存放数据
arrayList.add(24);//现在arrayList对象调用的add方法中的参数类型是object类型的,所以它可以存放任意的数据类型
arrayList.add("越努力,越幸运");//存放字符串类型的数据
arrayList.add(false);//存放布尔类型的数据
/*
* 取值
* 通过索引下标进行取值
* get方法的返回值类型是Object类型的数据,Object是所有类的父类
* 在存数据的时候,存放的数据类型不一致,所以存放的形参是Object类型的数据,这是堕胎的一种体现
* 将Object类型的数据转换为String类型的数据,通过向下转型(强制转换)的方式
*
*/
String string = (String) arrayList.get(1);
System.out.println(string);//越努力,越幸运
/*
* 强转会使效率降低,也可能出现ClassCastException异常
* 为了避免这种情况的发生,在java1.5版本之后提供了一个泛型,用来保证数据一致性的操作
*/
ArrayList<String> strList = new ArrayList<String>();//<String>是泛型的一种体现形式,要求strList存放的数据必须都是String类型的数据
strList.add("加油,我们都是追梦人!");
//strList.add(15);//<String>限定了集合中存放的数据类型,如果添加其他类型的数据将会报错
strList.add("不要放弃,相信自己一定可以!");
String str = strList.get(0);//用get方法取值
System.out.println(str);
}
}
3.3、泛型的基本语法格式
<无意义的字符>
无意义的字符一般放的是<T> <E> <?>
3.4、自定义泛型在方法中如何使用
语法格式:
权限修饰符 [static] <无意义的占位符> 返回值的类型 方法名字 (参数类型) {
}
例如:public <T> void get(T t){}案例:
package com.abc.fanxing;
/**
* 总结:有参数有返回值的方法,有必要写泛型
* 有参数无返回值的方法,有必要写泛型
* 无参数有返回值的方法,没有必要写泛型
* 无参数无返回值的方法,没有必要写泛型
* 也就是说,无参数的方法,没有必要写泛型
* @author 紫色的贝壳
*
*/
public class Test2 {
public static void main(String[] args) {
test("你好呀");
test1(23,25);
test2(false);
test4();
}
//普通方法
public static void test(String str) {
System.out.println(str);
}
//带有泛型的方法
/*
* 带有泛型的方法,在static和返回值类型之间必须写<T>,这就声明了当前的方法是带有泛型的方法
* 这种写法具有普适性,在上面调用这个方法的时候,就不用写方法的重载了
* T只是一个占位符,它的数据类型是通过传入的参数类型来决定的
*/
//无返回值,有参数
public static <T> void test(T t) {
System.out.println(t);
}
//无返回值,多个参数
public static <T> void test1(T t1, T t2) {
System.out.println(t1);
System.out.println(t2);
}
//有返回值,有参数
/*
* 参数类型要和返回值的类型保持一致,所以要使用当前的参数来返回数据
* 但是,从这里我们可以发现,泛型也有一定的局限性
*/
public static <T> T test2(T t) {
return t;
}
//有返回值,多个参数
public static <T> T test3 (T t1,T t2,T t3) {
System.out.println(t1);
System.out.println(t2);
System.out.println(t3);
//当使用运算符对两个或多个泛型进行操作时,是不可以的。因为此时还不能确定t1,t2,t3都是什么数据类型的,比如两个boolean类型的数据相加是不可以的,在语法格式上都会编译不通过
//System.out.println(t1 + t2 t3);
//return t1 && t2;
return t3;//只能有一个return返回值
}
//无参数,无返回值
public static <T> void test4() {
System.out.println("加油,你是最棒的!");
}
//有返回值,无参数
public static <T> T test5() {
return null;//此时返回的是null,null是Object数据类型,当返回0时,会报错,这样相当于指定了T的返回值类型时int
}
}
3.5、自定义泛型在类中如何使用
语法格式:
class 类名<无意义的占位符> {
属性
方法(带有泛型的)
}【注意事项】:
1.在泛型类中,成员方法不用带<T> , 因为一旦带了,这个方法约束的数据和当前类约束的就不一样了;
2.在泛型类中,带有泛型的静态方法和类的泛型没有关系。
案例:
package com.abc.fanxing;
//带有泛型的类
class Dog<T> {
//属性可以不写,泛型是不影响属性的
//成员方法
//1.能不能写普通的成员方法? 能
public void eat () {
System.out.println("狗吃在吃狗粮");
}
//2.能不能写带有泛型的方法?能
//这种写法 方法的参数和上面类的泛型有关系吗?没有
//这种写法是没有必要,起不到一个约束的作用
// public <T> void draw(T t) {//狗在画画
// System.out.println(t);
// }
//以后记住,在泛型类中书写泛型方法的时候 <T>不写,
//当前方法可以直接使用类中的泛型进行约束
public void draw(T t) {//狗在画画
System.out.println(t);
}
//能不能写静态的方法?能,但是无意义。
//静态方法的泛型和当前类定一的泛型没有关系
//<E>和上面的 <T>没有关系的
public static <E> void testStatic (E e) {
System.out.println(e);
}
}
public class Demo3 {
public static void main(String[] args) {
// Dog dog = new Dog();
// dog.eat();
//这个一旦这样写的话 draw(T t) 这个方法必须传的值是STring类型的
Dog<String> dog = new Dog<String>();
dog.draw("狗用脚在雪地里画画");
//dog.draw(12);//不能写int类型的数据,在new Dog 的时候已经限定了数据类型为String
}
}
3.6、自定义泛型在接口中如何使用
语法格式:
interface 接口名字<T> {
} 案例:
package com.abc.fanxing;
interface A<T> {
//成员方法 抽象方法
public void test (T t);//有参数 没有返回值的
public T test1(T t);//有参数 有返回值
}
//要写一个类去实现当前的接口
//接口带有泛型,那么它的实现类必须带有泛型
//而且带有的泛型是和接口保持一致
class TestA<T> implements A<T> {
@Override
public void test(T t) {
// TODO Auto-generated method stub
System.out.println(t);
}
@Override
public T test1(T t) {
// TODO Auto-generated method stub
return t;
}
}
public class Demo{
public static void main(String[] args) {
//int 的包装类 Integer
//boolean的包装类 Boolean
//double的包装类 Double
//char包装类 Character
TestA<Integer> testA = new TestA<Integer>();
testA.test(12);
testA.test1(45);
}
}
3.7、自定义泛型在抽象类中如何使用
语法格式:
abstract class 类名<无意义的占位符> {
}
案例:
package com.abc.fanxing;
abstract class B<T> {
public abstract void get(T t);
public void getArgs(T t) {
System.out.println(t);
}
}
class TestB<T> extends B<T> {
@Override
public void get(T t) {
// TODO Auto-generated method stub
System.out.println(t);
}
}
public class Demo{
public static void main(String[] args) {
TestB<Integer> testB = new TestB<Integer>();
testB.get(12);
TestB<String> testB2 = new TestB<String>();
testB2.get("你好呀");
}
}
四、权限修饰符
4.1类的访问权限修饰符
-
public 最大访问权限,本项目中任何位置都可以访问
-
默认不写:包级别的访问权限,只能在同包中访问
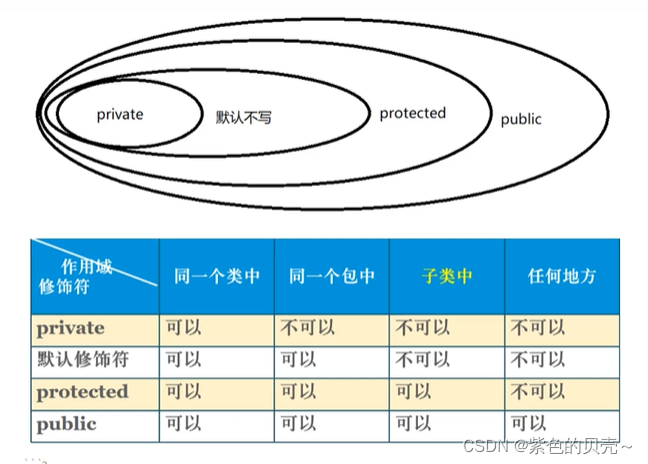
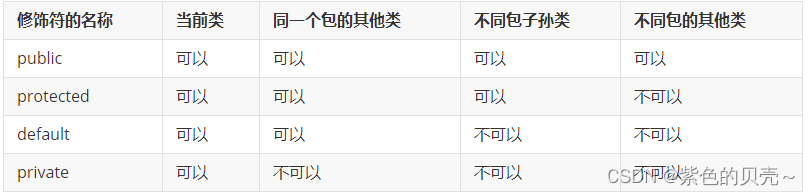
4.2类成员的访问权限修饰符
类成员包括属性、方法以及构造方法。
类成员的4种访问修饰符:
-
private:本类中(红色的正方形)
-
默认不写:本包中(蓝色的三角形)
-
protect:本类、本包、子类中(黄色的菱形)
-
public :本项目中(绿色的圆圈)
附带详细的总结:
五、集合
5.1为什么要使用集合
集合和数组是一样,都是用来存数据的。
数组在存数据的时候:
1.数组容量需要提前定义;
2.数组在封装给咱们java程序员提供的方法比较少,大部分是程序员自己写的。
java给封装了集合。给我们提供了很多封装好的方法,java程序员只需要依靠对象调用一个方法即可完成想要的需求,代码的复杂度变小了。
5.2集合的架构
interface Collection<E> Java 中所有集合的总接口,有两个子接口 一个叫List,另 一个叫Set。
--|List<E> 是Collection 的子接口,特征:存放数据的时候是有序的,可以重复的。
接口不能被实例化,肯定有实现类
--|--|ArrayList<E> 是List接口下面的实现类。底层是一个数组,默认的容量为10;
--|--|LinkedList<E> 是List接口下面的实现类。底层是一个双向链表;
--|Set<E> 是Collection 子接口,特征:存放数据的时候无序的不可重复。
--|--|HashSet<E> 是Set接口的实现类,底层是是hash表;
--|--|TreeSet<E> 是Set接口的实现类,底层是树形结构。

5.3Collection接口的常用方法
增加:
- boolean add(E e);添加指定的数据到指定的位置
- boolean addAll(Collection<? extends E>);添加另外一个集合到当前集合对象中,但是一定要保证两个集合的泛型保持一致。
删除:
- boolean remove(Object obj);删除指定的元素
- boolean removeAll(Collection<? extends E>);删除两个集合中的交集
- void clear();清空所有的元素
查询:
- int size();查看集合中元素的个数
- Object[] toArray();将集合转为Object类型的数组 就意味着以后数组和集合可以互相转换
- boolean contains(Object obj);判断一个元素是否在当前集合中
- boolean isEmpty();判断集合元素是否为空。如果有数据就是一个false, 没有数据就是一个true。
案例:
package com.abc.d_Collection;
import java.util.ArrayList;
import java.util.Collection;
public class Demo{
public static void main(String[] args) {
//这个是多态的体现形式,父类的引用指向了子类的对象
//但是collection对象只能调用父类下面的方法。不能调用子类下面独有的方法
//collection这个对象是一个空的集合,把它想象成一个空的容器
Collection<String> collection = new ArrayList<String>();
//向空的容器中添加数据
collection.add("苹果");
collection.add("香蕉");
collection.add("柚子");
//添加数据的时候可以添加重复的数据
collection.add("柚子");
//大家想想 咱们之前讲数组的时候,添加一个数据相当麻烦
//现在呢直接对象调用一个方法add()即可,这就是面向对象好处
System.out.println(collection);
//addAll() 将另外一个集合添加到一个集合中
Collection<String> collection1 = new ArrayList<String>();
//向空的容器中添加数据
collection1.add("芒果");
collection1.add("柠檬");
Collection<Integer> collection2 = new ArrayList<Integer>();
//规定 collection集合泛型要和collection1集合泛型保持一致
//不然就报错,数据类型不一致没有办法进行合并
collection.addAll(collection1);
System.out.println(collection);
//从集合中移除一个元素
System.out.println(collection.remove("香蕉"));
System.out.println(collection);
System.out.println("==========");
collection.removeAll(collection1);
System.out.println(collection);
System.out.println("---------");
//collection.clear();//清空元素
//System.out.println(collection);
System.out.println(collection.size());//元素的个数
Object[] objs = collection.toArray();
//碰到数组可以进行遍历,将数据取出来
for (int i = 0; i < objs.length; i++) {
System.out.println(objs[i]);
}
System.out.println(collection.contains("百香果"));
System.out.println(collection.isEmpty());
//System.out.println(col);
}
}
5.4迭代器
Iterator
迭代器能够遍历集合中的元素。
案例:
package com.abc.iterator;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class TestIterator {
public static void main(String[] args) {
// 创建一个集合,向集合中存储一些数据
Collection<String> list = new ArrayList<String>();//这种形式是多态的一种体现
list.add("java");
list.add("Linux");
list.add("Mysql");
System.out.println(list);
System.out.println("============================");
//将数据进行遍历,通过集合对象获取iterator对象
Iterator<String> iterator = list.iterator();//数据都在iterator这个对象里面了
//hasNext() 判断是否有下一个元素,有的话就是true 没有下一个元素就是一个false
//next() 返回迭代中的下一个元素。
while(iterator.hasNext()) {
System.out.println(iterator.next());
iterator.remove();//remove() 从底层集合中删除元素
}
System.out.println(list);
}
}
增强for循环
package com.abc.iterator;
/**
* 使用增强for循环遍历集合中的数据
* 增强for循环是普通for循环的加强版
* 写法比for循环更简便
*
* for(数据类型 临时变量 :被遍历的集合对象){
*
* }
* 将被遍历的集合对象通过循环,每次都会赋值给勤勉的临时变量(临时变量是局部变量)
*/
import java.util.ArrayList;
import java.util.Collection;
public class TestFor {
public static void main(String[] args) {
Collection<String> list = new ArrayList<String>();//这种形式是多态的一种体现
list.add("java");
list.add("Linux");
list.add("Mysql");
System.out.println(list);
System.out.println("*********************************");
for (String string : list) {
System.out.println(string);
}
}
}
集合中也能够存储对象
Person类
package com.abc.iterator;
public class Person {
private String name;//姓名
private int age;//年龄
//构造方法
public Person() {
}
public Person(String name,int age) {
this.name = name;
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
测试类:
package com.abc.iterator;
import java.util.ArrayList;
import java.util.Collection;
public class TestPerson {
public static void main(String[] args) {
Collection<Person> list = new ArrayList<Person>();
list.add(new Person("小明",15));
list.add(new Person("小兰",18));
list.add(new Person("小红",17));
System.out.println(list);
}
}
六、List接口
List接口继承了Collection接口,就意味着 List是Collection的子类。在java中 子类一定比父类功能强大 。从API官方文档发现,List接口下面的方法比Collection接口下面的方法多,所以开发中用List不用Collection。
6.1List的特征
有序的,在添加的时候与保存的数据一致,并且可以重复。
6.2List的常用方法
Collection下面的方法,在List下面都有的,因为是继承关系,,子类可以使用父类的方法,以下是List独有的方法。
增:
- boolean add(int index, E e);在指定的位置添加指定的数据
- boolean addAll(int index, Collection<? extends E> c);在指定的位置下面存入另外一个集合
删:
- boolean remove(E e);删除指定的元素 和索引没有关系
- E remove(int index); 通过索引删除指定的数据,并返回删除的数据
改:
- E set(int index, E element) 在指定位置替换指定的元素,并返回一个被替换的元素
查:
- E get(int index);通过索引把指定的元素取出来
- int indexOf(Object O);查找指定元素第一次下标,如果没有这个元素的话就返回-1
- int lastIndexOf(Object o);查找指定元素的最后一次下标
- List<E> subList(int startIndex, int endIndex); 从集合中通过索引截取一部分。这个索引是要头不要尾的(左闭右开)。
案例:
package com.abc.list;
import java.util.ArrayList;
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
list.add(12);//0
list.add(13);//2
list.add(14);//3
//在指定的位置添加指定的数据
//将13这个元素往后面挪一位
list.add(1, 25);//1
System.out.println(list);
List<Integer> list1 = new ArrayList<Integer>();
list1.add(1);
list1.add(2);
list1.add(3);
list.addAll(1, list1);
System.out.println(list);
System.out.println("========");
//默认是通过索引进行删除的
//如果集合中存的是int类型的数据的时候,
System.out.println(list.remove(1));//删除下标为1的元素
System.out.println(list);
//可以通过这种方式进行删除元素 不是通过索引删除的
list.remove(new Integer(1));
System.out.println(list);
System.out.println("---------");
System.out.println(list.set(0, 6666));
System.out.println(list);
}
}
package com.abc.list;
import java.util.ArrayList;
import java.util.List;
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("雪碧");//0
list.add("六个核桃");//1
list.add("康师傅");//2
list.add("农夫山泉");//3
list.add("六个核桃");//4
System.out.println(list);
//通过索引获取当前元素
System.out.println(list.get(1));
//咱们可以通过这个进行遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("======");
for (String string : list) {
System.out.println(string);
}
//获取指定元素在集合中索引下标
System.out.println(list.indexOf("康师傅"));
System.out.println(list.lastIndexOf("六个核桃"));
//截取的时候包含 1 不包含3 索引
List<String> newList = list.subList(1, 3);
System.out.println(newList);
}
}
6.3List接口下面的迭代器
package com.abc.listiterator;
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class Demo {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("紫色的贝壳");
list.add("越努力,越幸运");
list.add("努力努力再努力");
list.add("功到自然成");
ListIterator<String> iterator = list.listIterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
//以上的代码将指针移到了最后一位
System.out.println("---------------------------");
//以下代码是逆序输出
while(iterator.hasPrevious()) {
System.out.println(iterator.previous());
}
}
}
运行结果:

6.3ArrayList
ArrayList是一个类,有一个父接口 List, List父接口是Collection。
package com.abc.arrayList;
import java.util.ArrayList;
import java.util.ListIterator;
public class Demo1 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("柚子");
list.add("百香果");
list.add("柠檬");
//ArrayList的方法大部分和List接口一样
System.out.println(list);
//把单个元素取出来
System.out.println(list.get(1));//百香果
//遍历数据
//增强for循环
for (String string : list) {
System.out.println(string);
}
//for循环遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//迭代器进行遍历
ListIterator< String> iterator = list.listIterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
ArrayList的源码分析
几个重要的变量
/**
* Default initial capacity.
默认的容量 10
ArrayList底层是一个数组 这个数组容量默认的为10 只能存10个数据
*/
private static final int DEFAULT_CAPACITY = 10;//常量
/**
* Shared empty array instance used for empty instances.
EMPTY_ELEMENTDATA 数组Object类型的
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
elementData 数组的变量的名字
transient 被这个关键字修饰的不能被序列化,后面会讲序列化
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;//数组中元素的个数
三个构造方法
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
这个无参构造方法默认的初始化的容量是10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//DEFAULTCAPACITY_EMPTY_ELEMENTDATA初始化的容量是0,但是一旦往里面赋值时,它的默认容量是10
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();//把集合转换成数组
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
构造方法的目的是对属性进行初始化添加方法
public boolean add(E e) {
//确保容量能再次放进新的数据,如果放不下就立马扩容 10 调用add调用了10次
//再调用add方法,发现容量不够了,就开始进行扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = //elementData空的数组elementData[0] = "狗蛋"
//elementData[1] = "小翠" elementData[2]= "dahuang"
return true;
}
/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
rangeCheckForAdd(index);//校验索引
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
扩容方法grow()
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//老的容量 10
//oldCapacity >> 1 位运算符 ===》oldCapacity / 2
int newCapacity = oldCapacity + (oldCapacity >> 1);//新的容量 扩容的时候扩是原来容量的1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//要保证原来的10个数据还在 copyOf
//[1,2,3,4,5,6,7,8,9,10]
//[1,2,3,4,5,6,7,8,9,10, 11,12,13,14,15] 调用copyof方法的上
//扩容 [1,2,3,4,5,6,7,8,9,250,10, 11,12,13,14,15, 0,0,0,0,0,0]
elementData = Arrays.copyOf(elementData, newCapacity);
}ArrayList总结:
ArrayList底层是一个Object数组,这个数组默认初始值的容量为10。如果添加数据超过了10个,会自动进行扩容。底层代码有一个叫grow方法,是专门进行扩容的方法。每次只要需要扩容原来的1.5倍。ArrayList有一些特征:
- 增加数据,删除数据 效率慢:
1.可以会涉及到数组的扩容,牵涉到数组的复制问题
2.增加数据或者删除数据的时候,可能牵涉到数组的数据整体右移或者左移
删除一个数据 ,被删除后面数据整体前移 (底层是for循环)
在指定的位置添加一个数据 , 整体后移一位 (底层是for循环)
- 查询快:
底层是数组,一般使用数组名字 + 索引进行直接定位(类似于书的目录) 时间复杂度是1
一次就可以把指定一个元素给查询出来。
6.4LinkedList
Java中的LinkedList类实现了List接口和Deque接口,是一种链表类型的数据结构,支持高效的插入和删除操作,同时也实现了Deque接口,使得LinkedList类也具有队列的特性。LinkedList类的底层实现的数据结构是一个双端的链表。 LinkedList类中有一个内部私有类Node,这个类就代表双端链表的节点Node。这个类有三个属性,分别是前驱节点,本节点的值,后继节点。
Node源码:
private static class Node<E> {
//分别:前驱节点,本节点的值,后继节点
E item;//本节节点
Node<E> next;//后置节点
Node<E> prev;//前置节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
双端链表由node组成,每个节点有两个引用指向前驱节点和后继节点,第一个节点的前驱节点为null,最后一个节点的后继节点为null。
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
first和last需要维持一个不变量,分别指向头结点和尾节点,也就是first和last始终都要维持两种状态:如果双端链表为空的时候,两个都必须为null;如果链表不为空,那么first的前驱节点一定是null,first的item一定不为null,同理,last的后继节点一定是null,last的item一定不为null。
添加方法:
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
//在最后面添加元素
linkLast(e);
return true;
}
/**
* 插入到last节点的后面
* Links e as last element.
*/
void linkLast(E e) {
//取到添加前的最后一个元素
final Node<E> l = last;
//创建一个新的节点,并且将此节点之前的一个元素,新元素的传入
//由于是最后一个元素,所以其后面的元素时空的,因此后一个元素为null
final Node<E> newNode = new Node<>(l, e, null);
//更新最后一个元素的引用
last = newNode;
if (l == null)//f == null,表示此时LinkedList为空
first = newNode;//将新创建的节点赋值给first
else
l.next = newNode;
size++;//刷新总数
modCount++;
}
/**
* 插入第一个节点
* Links e as first element.
*/
//在first节点的前面插入一个节点,插入完之后,还要更新first节点为新插入的节点,并且同时维持last节点的不变量。
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
分析代码,首先用f来临时保存未插入前的first节点,然后调用的node的构造函数新建一个值为e的新节点,这个节点插入之后将作为first节点,所以新节点的前驱节点为null,值为e,后继节点是f,也就是未插入前的first节点。 然后就是维持不变量,首先第一种情况,如果f==null,那就说明插入之前,链表是空的,那么新插入的节点不仅是first节点还是last节点,所以我们要更新last节点的状态,也就是last现在要指向新插入的newNode。 如果f!=null那么就说明last节点不变,但是要更新f的前驱节点为newNode,维持first节点的不变量。 最后size加一就完成了操作。
删除方法:
//删除指定节点
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next; //获取指定节点的后继
final Node<E> prev = x.prev; //获取指定节点的前驱
if (prev == null) {
first = next; //如果前驱为null, 说明此节点为头节点
} else {
prev.next = next; //前驱结点的后继节点指向当前节点的后继节点
x.prev = null; //当前节点的前驱置空
}
if (next == null) { //如果当前节点的后继节点为null ,说明此节点为尾节点
last = prev;
} else {
next.prev = prev; //当前节点的后继节点的前驱指向当前节点的前驱节点
x.next = null; //当前节点的后继置空
}
x.item = null; //当前节点的元素设置为null ,等待垃圾回收
size--;
modCount++;
return element;
}
查询方法:
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}查询方法使用的是二分法查找,比如1 ,6 ,7,9,12,89,105, 678,897在查询时可以看出使用二分查找来看 index 离 size 中间距离来判断是从头节点正序查还是从尾节点倒序查。 node()会以O(n/2)的性能去获取一个结点 如果索引值大于链表大小的一半,那么将从尾节点开始遍历 这样的效率是非常低的,特别是当 index 越接近 size 的中间值时。
LinkedList总结:
LinkedList 是以双向链表实现,链表无容量限制(但是双向链表本身需要消耗额外的链表指针空间来操作),其内部主要成员为 first 和 last 两个 Node 节点,在每次修改列表时用来指引当前双向链表的首尾部位,所以 LinkedList 不仅仅实现了 List 接口,还实现了 Deque 双端队列接口(该接口是 Queue 队列的子接口),故 LinkedList 自动具备双端队列的特性,当我们使用下标方式调用列表的 get(index)、set(index, e) 方法时需要遍历链表将指针移动到位进行访问(会判断 index 是否大于链表长度的一半决定是首部遍历还是尾部遍历,访问的复杂度为 O(N/2)),无法像 ArrayList 那样进行随机访问。(如果i>数组大小的一半,会从末尾移起),只有在链表两头的操作(譬如 add()、addFirst()、removeLast() 或用在 iterator() 上的 remove() 操作)才不需要进行遍历寻找定位。
6.5ArrayList、LinkedList、List的区别
List 是集合列表接口,ArrayList 和 LinkedList 都是 List 接口的实现类。ArrayList 是动态数组顺序表,顺序表的存储地址是连续的,所以查找比较快,但是插入和删除时由于需要把其它的元素顺序移动,所以比较耗时。LinkedList 是双向链表的数据结构,同时实现了双端队列 Deque 接口,链表节点的存储地址是不连续的,每个存储地址通过指针关联,在查找时需要进行指针遍历节点,所以查找比较慢,而在插入和删除时比较快。
七、Object类
Object类是java中所有类的超类或者叫基类。它只有一个构造方法 Object()。
7.1Object类下面的equals方法
boolean equals(Object obj)指示一些其他对象是否等于此对象。 |
public boolean equals(Object obj) {
return (this == obj);
}Object类下面使用的==,就意味着Object类下面使用的equals方法比较的是地址和内容,如果地址和内容都相等的话,才会返回true,否则会返回false。
7.2String类下面的equals方法
所有类都是Object类的子类,String类也是Object类下面的子类,String类下面有一个方法叫equals()。重写了父类的equals方法,所以我们在使用String类的时候,调用equlas方法时,如果地址相等就返回true(因为地址相等,那么指向的一定是同一个对象,所以内容也一定相同),如果地址不同则判断内容。
案例:
public boolean equals(Object anObject) {
//String类下面如果两个对象的地址一样的话,也是返回true
//如果内存地址一样,那么内容一定是一样的
//先比较的是地址
if (this == anObject) {
return true;
}
//如果地址不一样的情况,下面就开始比较内容
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
//如果两个字符串的长度都不相等,还有必要去比较内容吗?没有
//如果长度长度相等的话,才进行字符串的内容的比较
if (n == anotherString.value.length) {
// "abce".equals("abcd")
//String 类下面的一个方法 叫toCharArray() 将字符串转为一个字符数组
char v1[] = value;//将字符串转为字符数组['a', 'b', 'c', 'e']
char v2[] = anotherString.value;//['a', 'b', 'c', 'd']
int i = 0;
//通过while循环来比较两个字符数组中的每个字符
/*
代码运行分析:
n=4 4!=0 v1[0] != v2[0] 'a'!= 'a' false i=1 n--
n=3 3!=0 v1[1]!=v2[1]'b'!='b' false i=2 n--
n=2 2!=0 v1[2]!=v2[2] 'c'!='c' false i=3 n--
n=1 1!=0 v1[3]!=v2[3] 'e'!='d' true return false
*/
while (n-- != 0) {
if (v1[i] != v2[i]){
return false;
}
i++;
}
return true;
}
}
return false;
}
7.3比较对象的内容是否一样
如果想要比较两个对象的内容是否一致。直接使用equals方法的时候,是用的Object类下面的equals方法,==比较的是地址。只能在当前类中重写equals方法,才能只比较内容。两点需要注意:
1.先判断地址,如果地址一样,肯定一样;
2.如果内存地址不一样,再判断内容,内容如果一样,那就返回true。
package com.abc.a_object;
public class Person {
int id;//编号
String name;//名字
int age;//年龄
public Person() {
}
public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
//自己定义不让它只比较内存地址,如果内容相等也返回true
//person1.erquals(person2);
//this.equals(obj)
if (this == obj) {
//== 地址一样,肯定是同一个对象
return true;
}
//对象中比较内容,内容一样的话也是返回一个true
//1.Object obj = person2; 先向上转型 自动的
//2.Person p = (Person)obj;再向下转型 强转不会报错
Person p = (Person)obj; //p 就是person2
//判断 id name age 如果一样就返回true
//person1.equals(person2)
//p就是person2 this 就是person1
return (p.id == this.id) && (p.age == this.age) &&(p.name.equals(this.name));
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", age=" + age + "]";
}
}
package com.abc.a_object;
public class Demo3 {
public static void main(String[] args) {
String string = "123";//常量池中
//自己定义的Person类也是默认继承的Object
Person person1 = new Person(1, "张三", 18);
Person person2 = new Person(1, "张三", 18);
boolean ret = person1.equals(person2);
//任何类都是继承的Object
//就意味着任何类调用equlas方法的时候 重写的Object类
//下面的equals方法
//person1和person2对象也是使用的Object类下面的equals
//Object 类下面的equals方法比较的是地址
//person1和person2的地址一样吗?不一样,所以是一个false
//你没重写调用的就是object的equals
System.out.println(ret);//false
//你的眼睛看到这个两个对象内容是一样。但是地址不一样
//如果内容一样,就判定是同一个对象,调用equlas方法应该返回一个true
//父类(Object类)equals方法是==,重写以后,子类只需要看内容即可,String重写了equals方法
}
}
7.4Object类下面的hashCode方法
hashCode方法返回的是int类型,这个返回的int类型的数据是对象的内存地址(十六进制)转为十进制的值。
package com.abc.a_object;
public class Demo{
public static void main(String[] args) {
Person person1 = new Person(1,"张三", 18);
Person person2 = new Person(1,"张三", 18);
//获取hash值,两个对象的地址不一样,因为Object类下面的hash码是内存地址转为十进制的一个值
//hash值肯定不一样
//person1.hashCode() 子类调用了父类的方法
System.out.println(person1.hashCode());
System.out.println(person2.hashCode());
}
}
对于Object只要对象的内存地址不一样,hash值肯定不一样。
7.5String类下面的hashCode方法
在String类中,重写了equals方法也重写了hashCode方法
目的:是比较两个字符串的对象的时候(比较的是内容),只要equals方法返回的是一个true,那hash值也得相等,所以只能重写hashCode方法。
package com.abc.b_object;
public class Demo {
public static void main(String[] args) {
String str1 = new String("a");
String str2 = new String("a");
System.out.println(str1.hashCode());
System.out.println(str2.hashCode());
//str1 str2 两个不同的内存地址的,为啥还一样啊?因为String类里面重写了Object的equals(),此时进比较字符串的内容,不比较地址
//String 类重写了Object类下面的hashCode方法了
//返回值是ASSIC码,不再是内存地址转为十进制的值了
//只要你字符串一样,那么你的ASSIC一样的,String类下面的hash值就是一样的
//为啥两个对象的内容一样了,hash也要求一样啊?
//官方手册API要求的!!!
//如果根据equals(Object)方法两个对象相等,则在两个对象中的每个对象上调用hashCode方法必须产生相同的整数结果。
}
}
Java中规定:如果重写equals方法比较的是两个对象,如果这两个对象的内容一样,那么hash值也必须要一样。所以重写equal方法,还要重写hashCode方法。
7.6比较两个对象内容的时候也要重写hashCode()
package com.abc.a_object;
public class Person {
int id;//编号
String name;//名字
int age;//年龄
public Person() {
}
public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override//重写的,子类的参数一定和父类的参数保持一致
public boolean equals(Object obj) {
// TODO Auto-generated method stub
//自己定义别让他只比较内存地址,如果内容相等也返回一个true
//person1.erquals(person2);
//this.equals(obj)
System.out.println("调用了equals方法");
if (this == obj) {
//== 地址一样,肯定是同一个对象
return true;
}
//对象中比较内容,内容一样的话也是返回一个true
//1.Object obj = person2; 先向上转型 自动的
//2.Person p = (Person)obj;再向下转型 强转不会报错,
Person p = (Person)obj; //p 就是person2
//判断 id name age 如果一样就返回true
//person1.equals(person2)
//p就是person2 this 就是person1
return (p.id == this.id) && (p.age == this.age) &&(p.name.equals(this.name));
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
//这个hashCode方法返回的值是我自己的定义的
System.out.println("调用lhashCode方法");
//找一个属性当成咱们的hash值
return id;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", age=" + age + "]";
}
}
以上代码块是为了保证equals是true的时候,hashCode的值也是一样的,重写equals()和hashCode()。
八、Set接口
Set是一个接口,它的直接父类是Collection。Set集合也是用来存放数据的,特点是无序的、不可重复的。Set接口下面有两个实现类,分别是HashSet和TreeSet。
8.1HashSet:
存值的时候,底层是依靠hash值进行存储的,只要hash值不一样就可以存进去,hash值一样的话,就不能存进去,所以Set集合不可以重复的存数据。

HashSet存储String、Integer类型数据时的案例:
package com.abc.a_set;
import java.util.HashSet;
import java.util.Set;
public class Demo {
public static void main(String[] args) {
//Set集合是无序的,不可重复的
Set<String> set = new HashSet<String>();
set.add("b");
set.add("a");
set.add("d");
set.add("c");
//往里面add的时候,添加在第一个,就应该放在第一个位置,但是现在不是,从这个角度来看, 是无序的
//[a, b, c, d] 底层是按照hash值进行排的
//hash值在底层的时候是没有顺序可言的
System.out.println(set);
Set<Integer> set1 = new HashSet<Integer>();
set1.add(10);
set1.add(20);
set1.add(30);
//[99, 89, 76] Integer类型存的时候随机的
System.out.println(set1);
}
}
HashSet存储对象的案例:
package com.abc.b_set;
import java.util.HashSet;
import java.util.Set;
class Person {
private int id;
private String name;
//有参构造,有参构造的目的是为了给属性赋值
public Person(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//重写equals方法
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
System.out.println("equals调用");
if(this == obj) {
return true;
}
//判断内容 person 两个属性 id name
Person p = (Person)obj;
return (p.id == this.id) && (p.name.equals(this.name));
}
//重写hashCode方法
@Override
public int hashCode() {
// TODO Auto-generated method stub
System.out.println("hashCode被调用");
return id;
}
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + "]";
}
}
public class Demo2 {
public static void main(String[] args) {
Set<Person> set = new HashSet<Person>();
set.add(new Person(1, "张三"));
set.add(new Person(1, "张三"));
set.add(new Person(2, "李四"));
//[Person [id=2, name=李四], Person [id=1, name=张三], Person [id=1, name=张三]]
//为啥可以存 两个1 张三?HashSet底层是hash值进行排的如果发现hash值一样就不再向里存了
//但是person对象尽管你的内容一样,但是hash值是不一样(因为是new了2个对象,其内存地址是不一样的,,哈希值也就不一样),也可以存,不符合开发要求
//眼睛看到的内容只要一样的就不能往里面存的,怎么办?
//如果只重写hashCode hashCode 相同 内容不一定相等
//所以equals方法和hashCode都要重写
System.out.println(set);
/*
* hashCode被调用
* hashCode被调用
* equals调用
*hashCode被调用
[Person [id=1, name=张三], Person [id=2, name=李四]]
* */
//从这个结果可以看出来,hashSet在数据进行添加的时候
//先判断hashCode如果发现hashCode一样,再通过equals
//仔判断内容,如果内容一样的话,就不能向set集合中添加数据
//调用了hashCode和equals方法
}
}
总结:

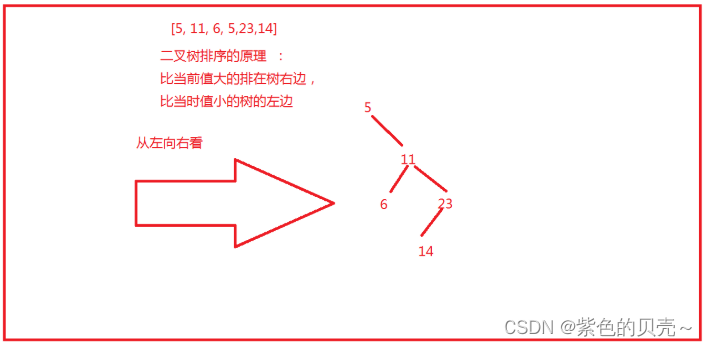
8.2TreeSet:
存值的时候,可以存八大基本数据类型的包装类数据、String类型、存对象 。底层依赖的是二叉树进行存储的。
案例:
package com.abc.b_set;
import java.util.Set;
import java.util.TreeSet;
public class Demo {
public static void main(String[] args) {
//无序的,不可重复的
Set<Integer> set = new TreeSet<Integer>();
set.add(2);
set.add(1);
set.add(25);
set.add(34);
set.add(34);//存不进去
System.out.println(set);
//存字符串的
Set<String> set1 = new TreeSet<String>();
set1.add("b");
set1.add("a");
set1.add("c");
System.out.println(set1);
//TreeSet集合从小到大进行排序的
}
}
TreeSet画图举例分析:
TreeSet存储对象案例:
package com.abc.b_set;
import java.util.Set;
import java.util.TreeSet;
class Student implements Comparable<Student>{
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student o) {
// TODO Auto-generated method stub
//实现comparTo方法实现自然排序。按照年龄进行排序
//如果是int类型的数据就使用 -
int num = this.age - o.age;
//如果年龄相等,再去比较名字
if (num == 0) {
//如果是字符串就使用compareTo这个方法比较字符串的自然顺序
return this.name.compareTo(o.name);
}
return num;
}
}
public class Demo4 {
public static void main(String[] args) {
//使用TreeSet存student
Set<Student> stus = new TreeSet<Student>();
stus.add(new Student("张三", 23));
stus.add(new Student("李四", 34));
stus.add(new Student("王五", 25));
stus.add(new Student("赵六", 30));
stus.add(new Student("小明", 30));
stus.add(new Student("小红", 30));
//这个地方报错了,TreeSet比较排序进行操作的 对象能排序不?不能
//为啥在存Integer和String 没有报错,是因为这两个类实现了Comparable这个接口
//Student 报错了 咋解决?在Student类去实现Comparable接口 implements Comparable<Student>
System.out.println(stus);
}
}
注意:
- 如果使用HashSet存对象的时候,一定记得重写equals方法和hashCode方法。
- 如果使用TreeSet存对象的时候,一定在当前类实现Comparebale接口,重写compareTo方法,对类属性进行自然排序。
九、Map集合
Map和List,Set 没有关系, 数据形式都不一样。键是不能重复的,是唯一的、 值可以重复的。
举例:身份证号叫键 (唯一的),名字叫值(可以重复)。
Map<K, V>接口它有2个实现类:
---|HashMap<K, V> 基于hash值进行存储的,依靠key;
---|TreeMap<K, V> 基于二叉树进行存储的,存储的形式也是key。
9.1Map下面常用的方法
增:
- put(K key, V value);存放的是一个键值对的数据
- putAll(Map<? extends K> k, Map<? extends V> v);将一个map集合存放到另外一个map集合中
删:
- remove(Object k);通过键删除整个键值对,并返回被删除的值
改:
- put(K key, V value); 当key存在的时候,就修改。当key不存在的时候,就添加
查:
- int size();键值对有效的个数
- boolean isEmpty();是否为空,map集合为空就返回true,不为空就返回false
- boolean containsKey();是否包含这个键
- boolean containsValue();是否包含这个值
- Set <k> keySet()获取map集合中键,返回是set集合(返回值是一个Set集合为啥不是一个List集合,因为Map集合中键是无序的不可以重复。)
- V get(Object k);通过键获取值
- Collection<V> values();获取map集合中所有的value值,返回的是Collection集合
- Set<Map.entry<K, V>>entrySet()`;将键值对实体成一个Set集合
9.2HashMap
HashMap数据结构图(HashMap底层的存储结构:Node 数组+Node链表+红黑树)

案例:
package com.abc.a_hashMap;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class Demo1 {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
//向里面存数据 通过hash值来决定key
map.put("0001", "黄焖大虾");
map.put("0002", "小葱拌豆腐");
map.put("0003", "酱鸭");
map.put("0003", "固始鹅块");
System.out.println(map);
HashMap<String, String> map1 = new HashMap<String, String>();
//向里面存数据 通过hash值来决定key
map1.put("007", "大盘鸡拌面");
map1.put("0008", "铁锅炖大鹅");
map1.put("0009", "王婆炖大虾");
map1.put("0001", "黄焖大虾1");
//map集合中的泛型一定和另外一个集和中的泛型保持一致
//每个键下面数据,都会调用自己的hashCode方法
//现在的键是String 那么调用的是String类下面的hashCode方法
map.putAll(map1);
System.out.println(map);
//真实的开发键肯定是不一样的
System.out.println(map.remove("007"));
System.out.println(map);
map.put("0001", "油焖大虾");
System.out.println(map);
System.out.println(map.isEmpty());//false
System.out.println(map.size());//5
System.out.println(map.containsKey("0008"));//true
System.out.println(map.containsValue("油焖大虾78"));//false
Set<String> set = map.keySet();
System.out.println(set);
System.out.println(map.get("0001"));//"油焖大虾"
Collection<String> collection = map.values();
System.out.println(collection);
//另外一种获取键获取值的方式
//[0002=小葱拌豆腐, 0003=固始鹅块, 0001=油焖大虾, 0008=铁锅炖大鹅, 0009=王婆炖大虾]
Set<Map.Entry<String, String>> set1 = map.entrySet();
//[] Set
//Map.Entry<String, String> 0003=固始鹅块
System.out.println(set1);
for (Entry<String, String> entry : set1) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
HashMap的六种遍历方式:







源码分析
核心属性分析
核心常量:
//缺省table长度,就是没有给你的数组指定长度 就按这个 1左移4位=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//数组table 最大长度 不能超过这个数 左移30位=1073741824;10亿多
static final int MAXIMUM_CAPACITY = 1 << 30;
//缺省负载因子大小 (负载因子:用于表示哈希表中元素填满的程度) 你不给你的hashMap传这个负载因子的值,就取0.75;
//它是用来计算扩容阈值的;下面会说
//建议 不要自己去设置这个值;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//树化 阈值;就是上面提到的当链表长度达到8就会树化;
static final int TREEIFY_THRESHOLD = 8;
//树 降级称为链表的阈值;当树的存储元素经过删除达到这个阈值的时候就会转换为链表的数据结构
static final int UNTREEIFY_THRESHOLD = 6;
//当你hash表中的所有元素个数达到64的时候,才能让达到8长度的链升级为树;也属于树化的一个阈值
static final int MIN_TREEIFY_CAPACITY = 64;
属性:
//散列表/哈希表维护的结构 Node类型的数组;就是一个散列表;目前是null;
transient Node<K,V>[] table;
//当前哈希表中元素个数
transient int size;
//当前哈希表的结构修改次数;插入或者删除都叫结构修改,你如果是替换覆盖不算;
transient int modCount;
//扩容阈值,当你的哈希表中的元素超过这个阈值时 触发扩容;(扩容的意义上面说过)
int threshold;
//就是负载因子 threshold = Capacity * loadFactor; 扩容阈值=数组长度 *负载因子;
final float loadFactor;
//内部类Node里面的属性 前面已经讲过了
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
}
4个构造方法分析
1.第一个构造器
//int 的数组初始化大小 负载因子大小
public HashMap(int initialCapacity, float loadFactor) {
//判断你传入的数组初始化大小 小于0 不合法 抛异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//判断你传入的数组初始化大小 是否大于了数组规定的最大值
if (initialCapacity > MAXIMUM_CAPACITY)
//超过最大值的化 就给你设置为最大值,
initialCapacity = MAXIMUM_CAPACITY;
//你传进来的负载因子不能小于=0,也不能是一个非数;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//上面的三个if语句是对你传进来的参数进行一个合法化的校验;
//传进来的值赋值给属性
this.loadFactor = loadFactor;
//这个为什么不直接赋值给属性呢?
//这个比较特殊,table数组的初始化的大小有个要求:必须是2得到次方;就是因为这个方法;
this.threshold = tableSizeFor(initialCapacity);
}
1.1第一个构造器里面调用的 tablleSizeFor(initialCapacity);
//作用就是返回一个大于等于当前值cap 的一个值,并且这个值一定是2的次方数
//就是让你传进来任何的数都转换2的次方数
//0001 0100 1100 =》 0001 1111 1111 +1 =》0010 0000 000 一定是2的次方
//假设 cap=10;
//经过测试传入最小的0 ,返回为1
static final int tableSizeFor(int cap) {
//n=9 这里你不减一,有可能会得到你想要的值大了一倍 比如传入16 return32;
int n = cap - 1;
//1001 | 0100 = 1101 (不会二进制的位运算 看我上面的java入门基础语法里面的位运算)
n |= n >>> 1;
//1101 | 0011 =1111
n |= n >>> 2;
//1111 | 0000=1111
n |= n >>> 4;
//1111 | 0000=1111
n |= n >>> 8;
//1111 | 0000 =1111 =15
n |= n >>> 16;
// n=15 return n+1=16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2.第二个构造器
//初始化数组大小
public HashMap(int initialCapacity) {
//就是套娃还是调用的第一个的,
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
3.第三个构造器
//我们经常用的
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
4.第四个构造器
//根据一个Map 构建一个HashMap
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
总结:

关于HashMap的面试题 :

9.3TreeMap
package com.abc.b_treeMap;
import java.util.TreeMap;
class Student implements Comparable<Student>{
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//不写的话打印的对象是地址,写上的话打印的字符串
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student o) {
// TODO Auto-generated method stub
int n1 = this.age - o.age;
int n2 = this.name.compareTo(o.name);
//如果年龄相等,我就比较名字排序
//如果n1==0 年龄相等的话 执行n2 比较名字
//如果n1 == 0 false 执行n1 比较年龄
if (n1 == 0) {
return n2;
} else {
return n1;
}
//return n1 == 0? n2: n1;
}
}
public class Demo2 {
public static void main(String[] args) {
//大家都已经知道了 按照K来排序的
//按照Student对象这个年龄进行排序的
Student stu1 = new Student("小明", 12);
Student stu3 = new Student("小兰", 2);
Student stu2 = new Student("张三", 3);
Student stu4 = new Student("李四", 13);
Student stu5 = new Student("王五", 13);
TreeMap<Student, String> treeMap = new TreeMap<Student, String>();
treeMap.put(stu1, "比较聪明");
treeMap.put(stu2, "比较勤奋");
treeMap.put(stu3, "比较刻苦");
treeMap.put(stu4, "比较不靠谱");
treeMap.put(stu5, "比较懒");
System.out.println(treeMap);
}
}
十、匿名内部类
匿名内部类仅应用于接口和抽象类。之前说过抽象类不能被实例化,今天开始就可以操作类似于实例化的东西。
10.1基于抽象类的匿名内部类
案例:
package com.abc.c_anno;
//定义一个抽象类
abstract class Animal{
public abstract void eat();
}
//之前再新建一个类去继承Animal,然后重写eat方法
public class Demo1 {
public static void main(String[] args) {
//现在直接可以这样来写 (方法1)
// Animal animal = new Animal() {//实例化抽象类的时候顺便把未实现的方法实现了
// @Override
// public void eat() {
// // TODO Auto-generated method stub
// System.out.println("吃饭");
// }
// };
// animal.eat();
//方法2
new Animal() {
@Override
public void eat() {
// TODO Auto-generated method stub
System.out.println("正在津津有味地吃饭");
}
}.eat();//匿名对象.方法();
}
//官方文档中关于匿名内部类说过英文的 减少代码的量
}
对象作为参数使用案例:
package com.abc.anno;
abstract class Dog {
abstract void sleep();
}
public class Demo2 {
public static void main(String[] args) {
test(new Dog() {
@Override
void sleep() {
// TODO Auto-generated method stub
System.out.println("狗在睡觉,千万不要打扰它");
}
});
}
//开发中使用的情况
public static void test(Dog dog) {
dog.sleep();
}
}
10.2基于接口的匿名内部类
package com.abc.anno;
interface Pig {
public void eat();
}
//不用再单独写一个类去实现这个接口
public class Demo3 {
public static void main(String[] args) {
new Pig() {
@Override
public void eat() {
// TODO Auto-generated method stub
System.out.println("小猪正在吃饭呢");
}
}.eat();
}
}














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









