







1. 在Java中,一些数据类型为引用类型,当引用类型的值为()时,表明没有引用任何对象
A. Empty B. null C. Nothing D. 0
所有引用类型的默认值都是null
2. 关于接口和基类描述正确的是
A. 基类是 as a的关系
B. 接口方法可以定义为public类
C. 接口可以支持多继承
D. 基类一定是抽象类
A. 基类:是对接口/抽象类默认方法的一般实现,使得子类不需要对接口/抽象类的方法完全重写,更方便使用 。
基类,父类,超类是指被继承的类,派生类,子类是指继承于基类的类。
派生类和基类一定要满足“is-a”关系,即派生类和基类有类属关系,或者说派生类是基类的一种具体化。
is-a:表示继承关系,表示类与类之间的继承关系、接口与接口之间的继承的关系以及类对接口实现的关系。比如:苹果是一种特定的水果。
as-a:表示属于同类,用于在兼容的引用类型之间执行某些类型的转换。比如:苹果和梨都属于水果。
has-a:表示组成关系,是关联关系的一种,是整体和部分(通常为一个私有的变量)之间的关系,指一个类中包含另一个类的对象。比如:午餐中包含有苹果。
B. 接口中的方法默认访问级别是public。 在编写接口的时候通常用public关键字,但是如果我们不显式地将接口中的方法声明为public,它仍然将是public的。
C. 一个接口不能继承其他的类,但是可以继承多个别的接口。
D. 基类可以是具体类、虚类和抽象类三种。
3. TCP协议中TIME_WAIT要等待几个MSL时间
A. 1 B. 2 C. 3 D. 4
MSL:Maximum Segment Lifetime报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
在TCP调用connect建立socket的连接后,主动关闭socket连接的过程中有一个状态为Time_Wait(也就是2MSL等待机制,需要停留2MSL的时间)
4. 哪个协议不是基于TCP/IP协议的?
A. HTTP1.1 B. FTP C. SSH D. DNS
这四个协议都是应用层。所以这道题到底选什么?有没有大佬可以解答一下?
查到的资料:
SSH是一种建立在应用层基础上的安全协议,它通过对密码进行加密传输验证,提供安全的传输环境,可以在不安全的网络中对网络服务进行安全传输。SSH协议是应用层协议,它的传输层协议是TCP。
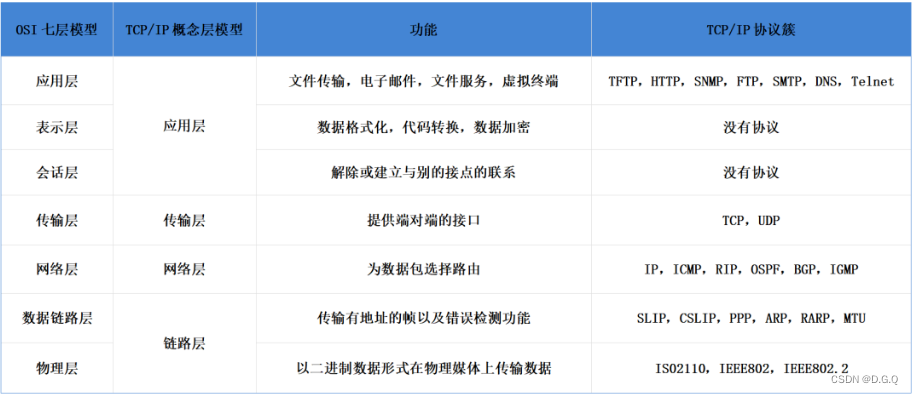
5. 关于TCP和UDP描述错误的是
A. TCP和UDP都属于传输层协议
B. TCP有序,UDP无序
C. TCP有状态,UDP无状态
D. TCP需要握手,UDP不需要
我感觉这四个选项都对啊!这题是不是没有正确答案??
TCP 和 UDP 的区别在于:
- 连接:TCP 面向连接的传输层协议,UDP是 无连接的传输层协议。
- 服务对象:TCP点对点的两点间服务,即一条TCP连接只能有两个端点;UDP支持一对一、一对多、多对一、多对多的交互通信。
- 可靠性:TCP 保证数据的可靠性和完整性,UDP 尽最大努力交付,不保证数据的可靠性和完整性。
- 有序性:TCP 保证数据的有序传输,UDP 不保证数据的有序传输。
- 是否有状态:TCP 传输是有状态的,它会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等,而 UDP 是无状态的传输协议。
- 流量控制:TCP 有流量控制和拥塞控制,UDP 没有流量控制和拥塞控制。
- 数据格式:TCP 报文格式包括头部和数据,UDP 报文格式只包括头部和数据。
- 首部开销:TCP首部开销大,首部20个字节,UDP首部开销小,8字节(源端口、目的端口、数据长度、校验和)。
- 适应场景:数据完整性需让位于通信实时性,则应该选择TCP协议(如文件传输、重要状态的更新等);反之,则使用UDP协议(如视频传输、实时通信等)。
- TCP面向连接, 传输数据时,需先进行三次握手,建立连接。UDP无连接,传输数据时无需建立连接,即无需三次握手直接发送数据
6. 下列哪一种叙述是正确的?
A. abstract修饰符可以修饰字段、方法和类
B. 抽象方法的body部分必须使用一对大括号{}包住
C. 声明抽象方法,大括号可有可无
D. 声明抽象方法不可写出大括号
abstract只能修饰类和方法,不能修饰属性和其他的
用abstract关键字来修饰一个方法时,这个方法就叫抽象方法。格式如下:
访问修饰符 abstract 返回类型 方法名(参数列表);//没有方法体
没有方法体,所以没有大括号。
7. 对HTTP的描述错误的是
A. HTTP请求是无状态的
B. HTTP请求必须包含请求头和请求体
C. HTTP返回中必须包含状态码
D. HTTP请求可以认证用户身份
HTTP的连接很简单,是无状态的。(无状态是指通信双方都不长久的维持对方的任何信息)
请求报文(请求行/请求头/请求体)
请求行的组成: 请求方式、本次请求路径(资源)、协议/版本
响应报文(状态行/消息报头/响应正文)
响应行的组成:本次响应采用的协议;状态码: 协议设计之初, 用一些数字描述了本次响应;状态描述: 用文字对本次响应进行简短描述
D我不清楚,排除法只剩D
8. 一个字节几位?
A. 2 B. 4 C. 6 D.8
一个字节由8个二进制位组成。
9. 以下关于异常正确的是
A. 一旦出现异常,程序运行就终止了
B. 如果一个方法申明将抛出某个异常,它就必须真的抛出那个异常
C. 在catch子句中匹配异常是一种精确匹配
D. 可能抛出系统异常的方法是不需要申明异常的
A. 发生一个异常不一定会导致程序终止运行。若程序中没有异常处理,发生一个异常一定会导致程序终止运行。若程序中有异常处理,发生一个异常并被捕获,则异常处理后,程序会继续运行。
B. Java 语言中所有错误或异常都是通过Throwable进行描述,而异常又分为两种,一种是可处理的也就是Exception,一种是不可处理的也就是Error
C. catch匹配时,不仅运行精确匹配,也支持父类匹配,因此,如果同一个try块下的多个catch异常类型有父子关系,应该将子类异常放在前面,父类异常放在后面,这样保证每个catch块都有存在的意义。
D. 系统异常是Error了,这类异常不能捕获,因为是Java调用了系统底部功能出现了问题,系统就是返给Jvm了Error异常,这时就必须修改代码了,例如内存溢出
10. 下面哪个不能用来实现多线程的互斥?
A. lock关键字 B. Monitor C. Mutex类 D. Process类
lock 关键字将语句块标记为临界区,方法是获取给定对象的互斥锁,执行语句,然后释放该锁。
Monitor 的重要特点是:同一个时刻,只有一个 进程/线程 能进入 monitor 中定义的临界区,这使得 monitor 能够达到互斥的效果
“mutex”是术语“互相排斥(mutually exclusive)”的简写形式,也就是互斥量。互斥量跟临界区中提到的Monitor很相似,只有拥有互斥对象的线程才具有访问资源的权限,由于互斥对象只有一个,因此就决定了任何情况下此共享资源都不会同时被多个线程所访问。当前占据资源的线程在任务处理完后应将拥有的互斥对象交出,以便其他线程在获得后得以访问资源。
Process类是一个抽象类(所有的方法均是抽象的),封装了一个进程(即一个执行程序)。 Process 类提供了执行从进程输入、执行输出到进程、等待进程完成、检查进程的退出状态以及销毁(杀掉)进程的方法。
11. 静态变量通常存储在进程哪个区?
A. 栈区 B. 堆区 C. 全局区 D. 代码区
链接:静态变量通常存储在进程哪个区?_快手笔试题_牛客网
来源:牛客网
c++程序内存布局: 1)全局区(静态区)(static)存放全局变量、静态数据,const常量。程序结束后有系统释放 2)栈区(stack) 函数运行时分配,函数结束时释放。由编译器自动分配释放 ,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等。其操作方式类似于数据结构中的栈。 3)堆区(heap) 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS(操作系统)回收。分配方式类似于链表。 4)文字常量区 常量字符串就是放在这里的。 程序结束后由系统释放。 5)程序代码区存放函数体(类成员函数和全局函数)的二进制代码。
12. 关于进程和线程,下列哪些说法是正确的?(多选)
A. 线程是操作系统分配处理器时间的基本单位
B. 进程是操作系统分配处理器时间的基本单位
C. 一个线程可以属于多个进程
D. 一个进程可以有多个线程
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
13. 从逻辑上可以把数据结构分为哪两大类?(多选)
A. 顺序结构 B. 线性结构 C. 非线性结构 D. 链式结构
按照存储方式分为链式存储和顺序存储 。顺序表、栈、队列都属于顺序存储。
按照逻辑结构分为线性和非线性。集合、树形结构、图形结构都属于非线性。
14. 关于线程的描述正确的是 (多选)
A. 线程是CPU调度的基本单位
B. 线程起到资源的隔离作用
C. 每个线程执行都有一个线程栈
D. 一个线程同一时间可以在多个CPU上运行
D选项我不确定,有大佬能讲一下这个是对还是错的?
线程隔离:使用该方式,HystrixCommand将会在单独的线程上执行,并发请求受线程池中线程数量的限制。
堆栈是保证线程独立运行所必须的。线程函数可以调用函数,而被调用函数中又是可以层层嵌套的,所以线程必须拥有自己的函数堆栈,使得函数调用可以正常执行,不受其他线程的影响。(堆在windows共享,在塞班系统独立)
15. SqlServer默认的隔离级别是Read Commited
A. 对 B. 错
16. 32位系统可以使用5G内存
A. 对 B. 错
32位操作系统最大支持4GB内存
17. 类是属于值类型分配在内存的栈上,而Struct属于引用类型,分配在内存堆上
A. 对 B. 错
Class可以被实例化,属于引用类型,是分配在内存的堆上的;
Struct属于值类型,是分配在内存的栈上的
18. RAID 0 需要至少一块硬盘,而RAID 1需要至少两块
A. 对 B. 错
Raid0 :最少需要两块盘, 没用冗余数据,不做备份,任何一块磁盘损坏都无法运行。n块磁盘(同类型)的阵列理论上读写速度是单块磁盘的n倍(实际达不到),风险性也是单一n倍(实际更高),是磁盘阵列中存储性能最好的。适用于安全性不高,要求比较高性能的图形工作站或者个人站。
Raid1:至少需要两块盘,磁盘数量是2的n倍,每一块磁盘要有对应的备份盘,利用率是50%,只要有一对磁盘没有损坏就可以正常使用。n组磁盘(2n块同类型磁盘)的阵列理论上读取速度是单块磁盘的n倍(实际达不到),风险性是单一磁盘的n分之一(实际更低)。换盘后需要长时间的镜像同步,不影响外界访问,但整个系统性能下降。磁盘控制器负载比较大。适用于安全性较高,且能较快恢复数据的场合。
Raid0+1: 至少需要四块盘,磁盘数量也是2的n倍。既有数据镜像备份,也能保证较高的读写速度。成本比较大。
Raid3:至少需要3块盘(2块盘没有校验的意义)。将数据存放在n+1块盘上,有效空间是n块盘的总和,最后一块存储校验信息。数据被分割存储在n块盘上,任一数据盘出现问题,可由其他数据盘通过校正监测恢复数据(可以带伤工作),换数据盘需要重新恢复完整的校验容错信息。对阵列写入时会重写校验盘的内容,对校验盘的负载较大,读写速度相较于Raid0较慢,适用于读取多而写入少的应用环境,比如数据库和web服务器。使用容错算法和分块的大小决定了Raid3在通常情况下用于大文件且安全性要求较高的应用,比如视频编辑、硬盘播出机、大型数据库等。
Raid5:至少需要3块盘,读取速度接近Raid0,但是安全性更高。安全性上接近Raid1,但是磁盘的利用率更高。可以认为是Raid0和Raid1的一个折中方案。只允许有一块盘出错,可以通过另外多块盘来计算出故障盘的数据,故障之后必须尽快更换。比Raid0+1的磁盘利用率高,是目前比较常用的一种方案。
————————————————
版权声明:本文为CSDN博主「柠^木」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44082342/article/details/131231693
19. Linux中的一个文件只能归属于一个用户
A. 对 B. 错
通常情况下,一个文件只能归属于一个用户和组
20. 不妨设树的根节点深度为0,那么深度为5的满4叉树(最后一层没有子节点,其他层上每个节点都有4个子节点)一共有几个节点?
A. 9987 B. 768 C. 1365 D. 256
公式:(k^(h+1)-1) /(k-1)















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









