






导包
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import re
通过封装函数用正则对输入的语句进行处理
def find_name(line):
# 在输入行中查找名字
match = re.search(r'\bmy name is (\w+)\b', line, re.IGNORECASE)
if match:
return match.group(1)
else:
return ""
re.IGNORECASE是compile函数中的一个匹配模式,忽略大小写
ssc=StreamingContext(sc,4)
# 创建一个DStream,从nc模拟器接收数据
lines = ssc.socketTextStream('localhost',9999)
# 在DStream中查找名字
names = lines.map(find_name).filter(lambda x: x != "")
# 输出名字
names.pprint()
运行上面的代码,然后在终端输入nc -lk 9999 回车运行下面的代码的同时输入my name is lihua回车就可看见捕捉到的姓名单词
ssc.start()
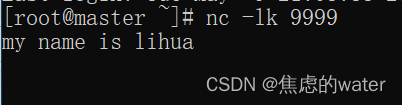
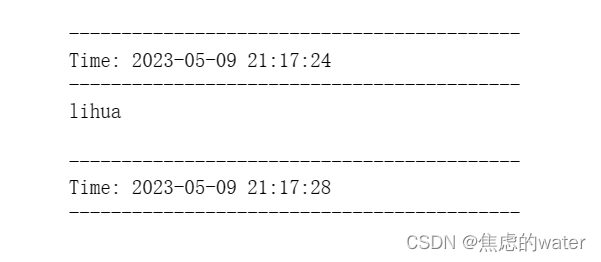
同时,如果觉得上面封装函数比较复杂,可以采取以下方式,同样是正则处理

















 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











