






前言
ZipList在redis的集合和hash中被经常作为基层存储结构使用。
ZipList是一种特殊的“双向链表”,被设计为一系列连续内存经过特殊编码组成的数据结构。而抛弃了记录内存的指针的方法。即有效节省了内存开销,也可以在任意一端进行压入/弹出操作。且时间复杂度均为O(1)。
源码
其中redis源码中的解释如下
ziplist 是一个经过特殊编码的双向链表,旨在提高内存效率。 它存储字符串和整数值,其中整数被编码为实际整数而不是一系列字符。 它允许在 O(1) 时间内在列表的任一侧进行推送和弹出操作。 但是,由于每个操作都需要重新分配 ziplist 使用的内存,因此实际复杂性与 ziplist 使用的内存量有关
- 即 redis 对不同数据类型和不同大小的数据结构有着不同的编码方式。虽然redis会对数据进行压缩来减少内存的使用。但是随着数据级的扩大,redis的消耗也随着变大。
数据结构源码如下
/* 创建一个空的 ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
而ZipList的数据组成如下图

| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbyties | uint32_t | 4 字节 | 记录整个ZipList所占的内存空间 |
| zltail | uint32_t | 4 字节 | 记录表位节点的偏移量,即列表表尾的节点距离起始地址的字节数,用来确定为节点的地址 |
| zllen | unit16_t | 2 字节 | 记录ZipList中节点个数。最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表的各个节点,存储着具体数据和相关信息。节点长度由节点保存的内容决定 |
| zlend | unit8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ZipListEntry的数据组成
- ZipListEntry 中摒弃了传统的链表记录前后节点指针的方法,应为记录两个指针要16个字节,大大浪费了内存空间,其具体结构如下。

其中: - previous_entry_length:前一个节点的长度,占1个或者5个字节
- 如果前一个节点大于254个字节,则采用5个字节来保存长度值,第一个字节为0xfe,后四个字节才是真实长度。
- 如果前一个节点长度小于254个字节,则采用一个字节来保存长度。
- encoding:编码属性,记录 content 的数据类型(字符串还是整数等)以及长度,占1个、2个或者5个字节
- content:保存节点的数据,可以是字符串或者整数
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412
Encoding编码
ZipListEntry中存储的数据分为整数和字符串:
- 字符串:如果编码是由“01”、“00”、“10”开头,则证明 content 是字符串
| 编码 | 编码长度 | 字符串大小 | 补充 |
|---|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes | “pppppp”表示无符号的 6 位数据长度 |
| |01pppppp|qqqqqqqq | 2 byties | <= 16383 bytes | 14位数据采用 big endian 存储(有Little-Endian、Big-Endian两种) |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 byties | <= 4294967295 bytes | 采用 big endian 存储且可表示的字符串长度最大2^32-1,所以第一个字节没有用到,所以低6位没有用,所以都是0 |
例如存储字符串ab

- 整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占1个字节。
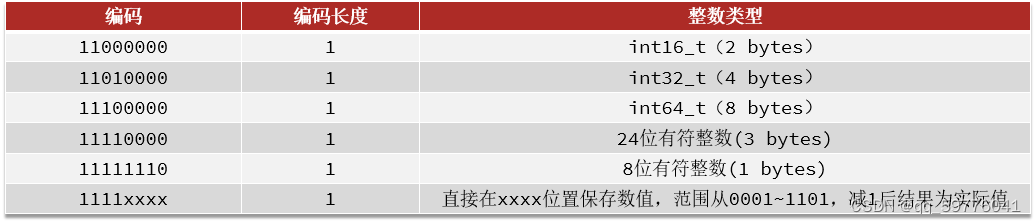
- 其中最后一个 0 到 12 的无符号整数。编码后实际上是1到13,因为0000个1111不能用(被其它编码方式标识占用),所以要从编码的4位值中减去1才能得到正确值。
例如列表中有“2”、“5”两个整数

- 结尾编码标识:表示ziplist的结尾,|11111111|
连锁更新问题
连锁更新是 ziplist 一个大的缺点,虽然是小概率事件,但是出现的话会严重影响性能。
ZipList中每一个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节
- 如果前一个节点长度小于254个字节,则采用1个字节保存长度值
- 如果前一个节点长度大于等于254个字节,则采用5个字节来保存长度值
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示:

- 在更新或新增时,如空间不够则要对整个列表重新分配来进行空间扩展。当插入元素较大的时候,导致后续元素的previous_entry_length占用的空间都在变化。导致每个元素的空间都要重新分配,照成性能大下降。
- ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
总结
- ziplist 为了节省内存,采用了紧凑的连续存储。所以在修改操作下并不能像一般的链表那么容易,需要从新分配新的内存,然后复制到新的空间。
- ziplist是一种特殊的双向链表,可以存在时间复杂度位O(1)的情况下从头部或者尾部进行pop、push
- 如果列表数据过多,导致链表过长,会影响查询性能
- 增加或删除大数据时可能会导致连锁更新问题















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









