







前言
本文主要是分享个人的一些学习经历,请勿喷。
各位可按照以下步骤利用python实现对PDF的合并操作!
一、使用的编译器和包?
此次示例使用Spyder,其是一个对于数据分析来说比较好用的平台。使用的数据包是PyPDF2,第一次使用时在控制台键入 pip install PyPDF2导入环境内,然后就可以使用了。
二、使用步骤
1.对指定文件夹内所有的PDF进行合并
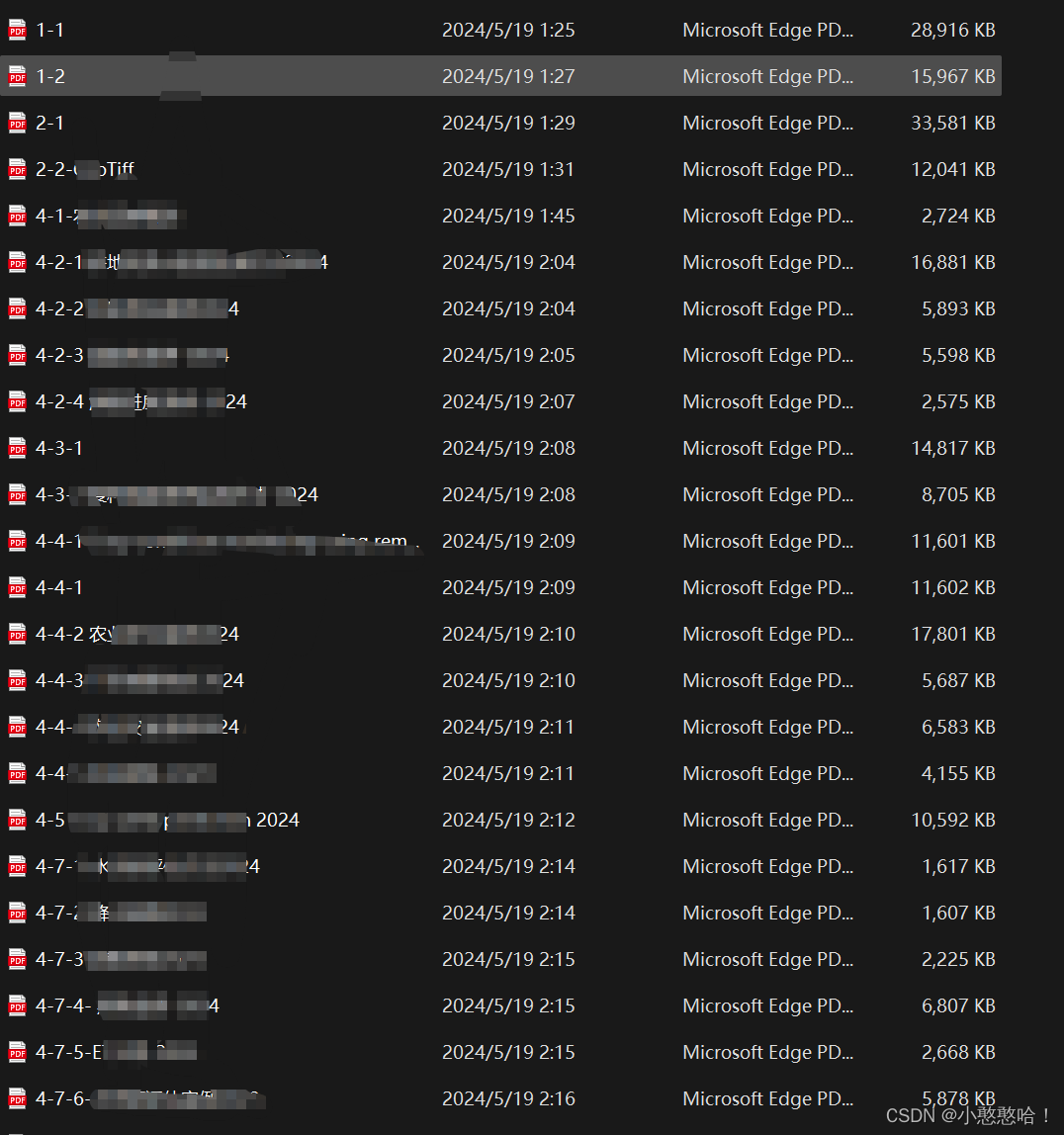
本文有两种合并方法。第一种是根据输入的文件夹名称,实现对文件夹内所有的PDF文件的合并(按照名称顺序,因此建议在合并前按照顺序进行重命名,如下图)
然后就是第一种方法的示例代码了:
import os
from PyPDF2 import PdfMerger
def merge_pdfs_in_folder(folder_path, output_filepath):
pdf_merger = PdfMerger()
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith(".pdf"):
full_filepath = os.path.join(folder_path, filename)
with open(full_filepath, 'rb') as pdf_file:
pdf_merger.append(pdf_file)
with open(output_filepath, 'wb') as output_file:
pdf_merger.write(output_file)
folder_path = r'D:\学习\雁栖湖\遥感地学分析' #文件夹名称
# 指定合并后的输出文件路径
output_floder=r'D:\学习\雁栖湖\遥感地学分析\合并后的文件'
output_file = r'D:\学习\雁栖湖\遥感地学分析\合并后的文件\遥感地学分析.pdf'
if not os.path.exists(output_floder):
os.makedirs(output_floder)
# 调用函数进行合并
merge_pdfs_in_folder(folder_path, output_file)
print(f"PDF文件合并完成,保存为:{output_file}")
代码中输出文件路径如果不存在,这个代码也会帮你创建一个新的文件夹。
运行后就可以实现合并了。
2.对指定PDF进行合并
如果你想指定特定的顺序或者特定的几个PDF文件,也可以按照以下示例代码实现:
import os
from PyPDF2 import PdfMerger
def merge_pdfs(filepaths, output_filepath):
pdf_merger = PdfMerger()
for filepath in filepaths:
# 添加共同的目录
full_filepath = os.path.join(filefloder, filepath)
with open(full_filepath, 'rb') as pdf_file:
pdf_merger.append(pdf_file)
with open(output_filepath, 'wb') as output_file:
pdf_merger.write(output_file)
# 指定要合并的PDF文件的文件夹路径
filefloder = r'D:\学习\雁栖湖\生态数据融合和与同化\原始ppt'
# 指定要合并的PDF文件名称
pdf_files = ["1.pdf", "2.pdf", "3.pdf", "4.pdf", "5.pdf", "6.pdf", "7.pdf", "8.pdf", "9.pdf", "10.pdf","11.pdf", "12.pdf", "13.pdf"]
# 指定合并后的输出文件路径
output_file = r'D:\学习\雁栖湖\生态数据融合和与同化\原始ppt\生态数据融合和与同化2.pdf'
# 调用函数进行合并
merge_pdfs(pdf_files, output_file)
print(f"PDF文件合并完成,保存为:{output_file}")
总结
本文是我的第一篇博客,介绍了使用python实现对PDF文件的合并,虽然比较简单,但也希望能帮助到有需要的人。















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









