







背景
对稀疏性矩阵消除变量顺序的选择,对于实现高性能算法至关重要,我们将在下面讨论如何选择消除顺序来有效降低计算复杂度。首先我们来看看如何计算复杂度成本。
复杂度成本计算
由于我们消除n个变量,设成本为f,消除每个变量的成本为g。
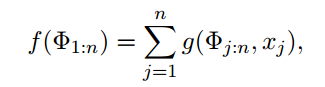
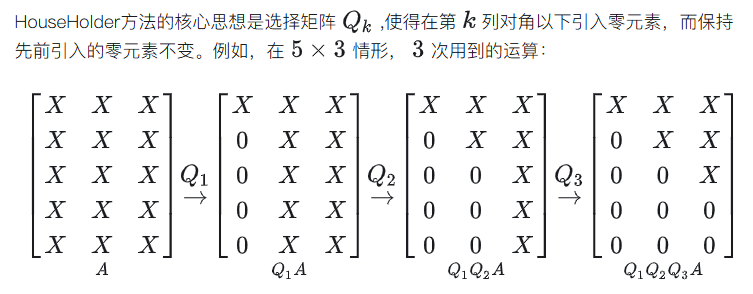
对于单个变量的成本计算,我们知道,消除变量是用的HouseHolder算法,这里我们回忆一下其原理,只每次变换时将对角线元素以下的变换为0。
HouseHolder的原理更直观的来看,可以理解为投影。对于向量x,要将其投影到指定y方向(y可以是[X 0 0 0 0],[X X 0 0 0]等)上,这里的限制条件是x和y长度相等,我们需要找到一个反射面(紫色平面),通过几何关系建立方程得到y的最终表达式。
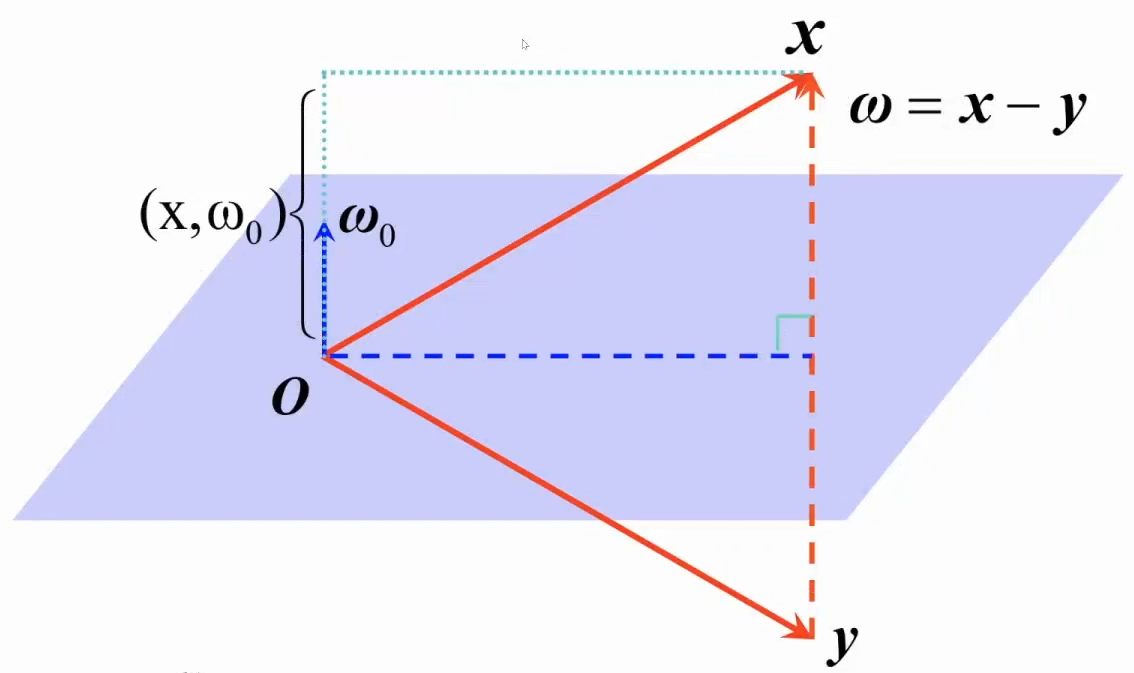
从图中,我们可以推导这样的等式
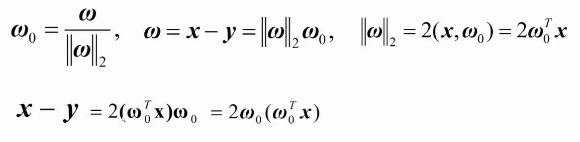
则
从式子中,我们可以计算出其复杂度:
内积运算 :
flops(每个对应元素相乘,共
次乘法。将所有乘积相加,需
次加法)
更新列元素 :
flops(乘加各一次)
于是单列总成本:,总复杂度:
。
其中,(每消除一个维度,行数递减),
(列数由变量和分离器共同决定),带入可得:
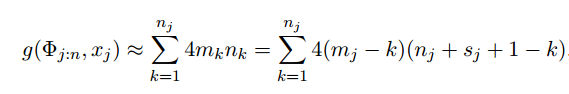
则消除n个变量总成本为:
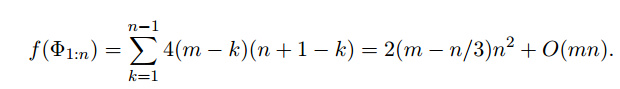
消除变量顺序对稀疏性的影响
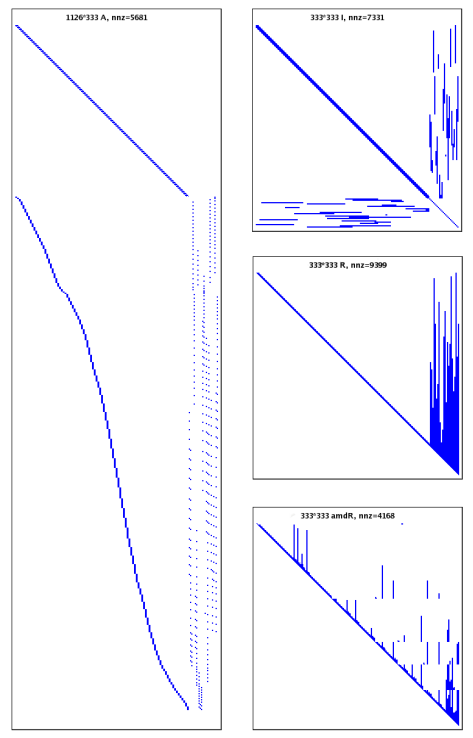
如下图所示,左侧图为测量雅可比矩阵 A,A的稀疏性源于机器人学问题的局部性(如SLAM中测量仅关联当前位姿与附近地标),这使得大规模优化问题可高效求解。
右侧上图为信息矩阵 ,非零元素表示变量间存在直接依赖,若变量排序不佳,Λ可能因填充变得密集,增加计算成本。
右中为自然排序的Cholesky因子 R,右下为用更好的变量排序(COLAMD排序)的Cholesky因子 amdR,nnz表示非零元素。通过对比可知,右下nnz的数量远小于右中的数量,故通过COLAMD智能排序,避免了不必要的依赖关系传播,使Cholesky因子更稀疏。
填充
不同的消除顺序会在整个消除过程中建立不同的连接关系,这就会使得稀疏R矩阵被填充。我们希望找到具有最小填充的消除排序,也即是达到因子分解算法的最小化成本。这里文章中介绍了两种启发式算法来消除变量。
最小度排序
最小度排序的核心思想是通过贪心策略优先消除当前因子图中度数最小的变量,以减少消除过程中引入的新依赖(填充)。变量的度数指其在因子图中直接连接的边数。选择度数最小的变量进行消除,从而保持后续步骤中矩阵的稀疏性,其简单高效,尤其适用于一般稀疏问题。
这里有两种实现方法:
精确最小度(MMD):每次选择所有度数最小的变量进行批量消除。
近似最小度(AMD):通过近似计算节点度数或合并不可区分的节点(indistinguishable nodes),避免频繁更新全局图结构,显著提升效率。例如,将节点聚类为团(clique),仅计算团的度数作为近似,从而减少计算开销。
嵌套分割排序
嵌套分割采用分治策略,通过递归划分图结构来减少全局填充,其适用于大规模结构化环境(平面图、城市),尤其是空间分离的场景。具体步骤如下:
-
分割图:将图划分为三个子集 A、B 和 C,其中 C 为分隔集(separator),切断 A 与 B 的直接连接。
-
递归处理子图:对 A 和 B 继续分割,直到子图足够小。
-
后序消除:按后序遍历顺序(子图内部变量优先,分隔集变量最后)消除变量。
这里我理解的嵌套分割排序是:首先先确定分隔集C(相邻区域间的边界点如门廊、交叉路口、道路和绿化带等可以作为分隔集),由C分割开的A、B两区域互不相连,接着,在A、B区域分别再进行分割,直到分割到最小单元,然后从最小单元开始进行消除变量,最后消除分隔集中的变量。
Schur补技巧
在SLAM中,一个简单的排序策略是首先消除地标,然后是姿势。这通常被称为“舒尔补充技巧”。其原理是将变量分为两组(如地标和位姿),通过块消元法先消除一组变量,适用于地标数量远多于位姿时。但若直接应用,可能导致位姿图完全稠密(图右测密集红色区域),计算效率反下降。在运动结构中,若有数十万个点,使用Schur补码技巧是有利的,它在缓存一致性和局部性方面是有益的。
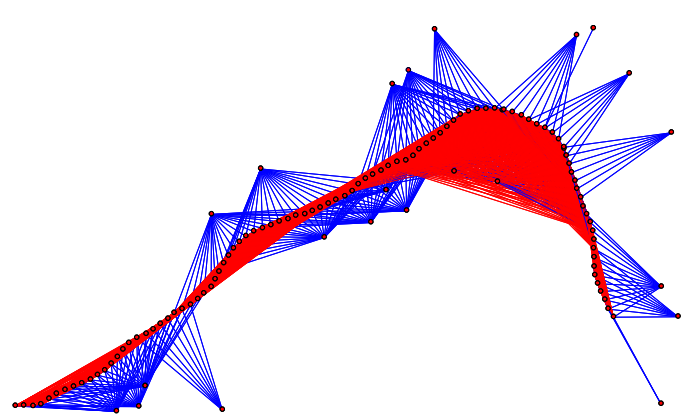
如在此处使用最小度排序,可优化得到下图,最小度排序产生更少的填充和更快的线性求解步骤。

嵌套分割排序与SLAM
基于子地图的方法的一个优点是计算可以以核外方式完成,使得可以将大部分工作分布在多个计算资源上,从而增加了时间和存储器方面的可伸缩性。
分而治之方法的另一个实际优点是,它也导致了一个很好的初始化计划的批优化方法,通过采用分而治之方法,我们可以递归地计算初始化从优化的子映射。
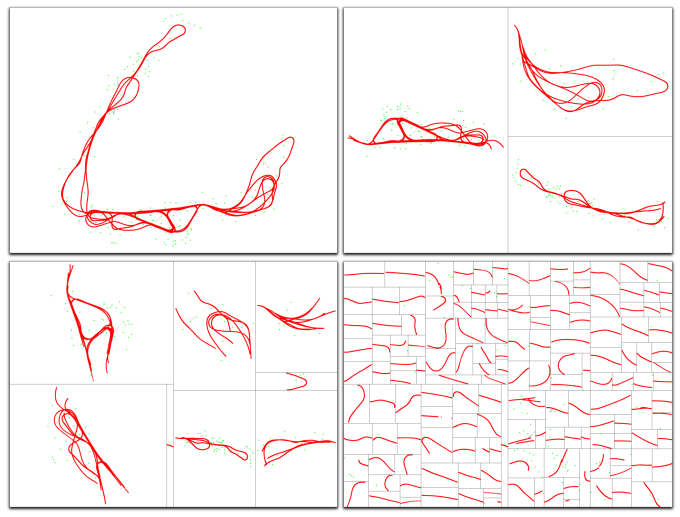
以下是一个递归分割的例子,对每一次的分割再进行分割。下面这幅图将原图分割为三块,之后对每一块都进行了再次分割,以此递归下去。
参考
1、《Factor Graphs for Robot Perception》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









