






学习视频:【YOLOv8小白入门09】目标检测模型性能指标_哔哩哔哩_bilibili
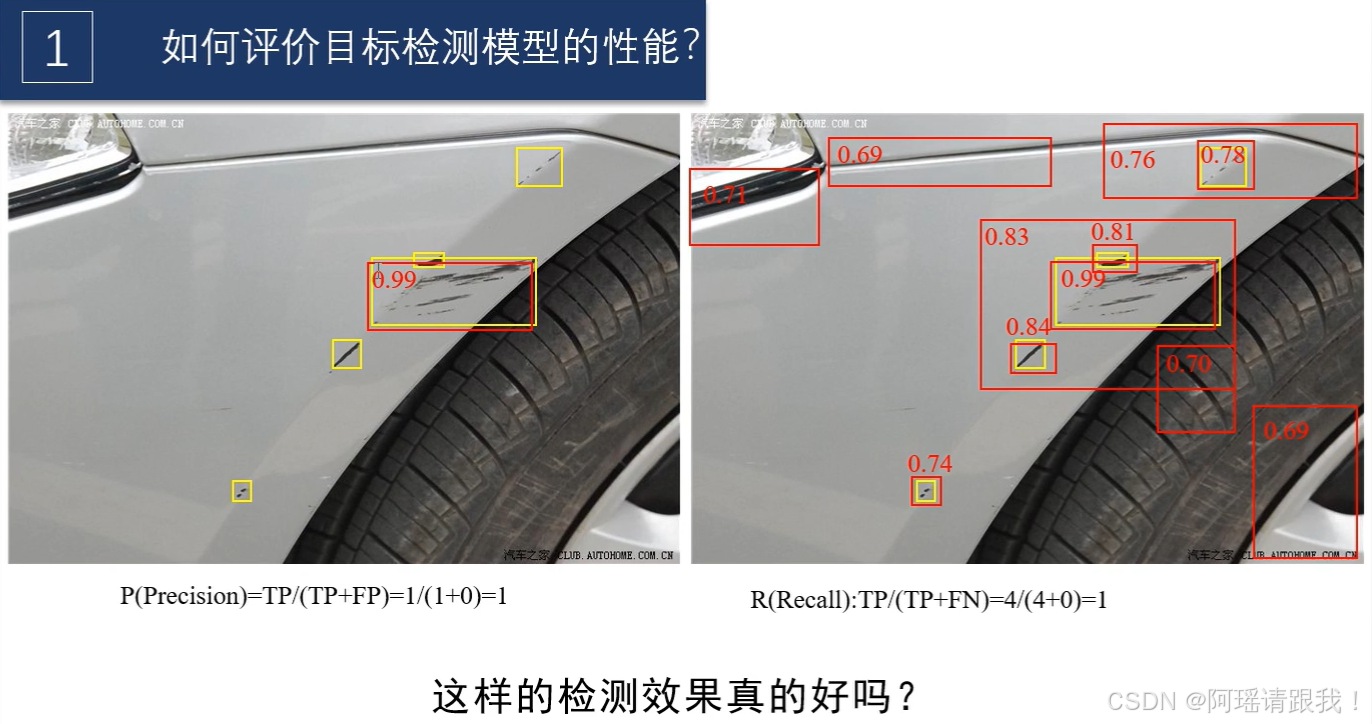
性能三要素:类别、置信度(confidence)、交并比(IOU)
TP:IOU>0.5的预测框的数量(一个GT只参与一次比较)
FP:OU<=0.5的预测框的数量(一个GT只参与一次比较)
FN:没有检测到的GT的数量
P(精准度) = TP / (TP + FP) # 所有预测框中预测正确的比例
R(查全率) = TP / (TP + FN) # 所有GT框中被正确预测的比例
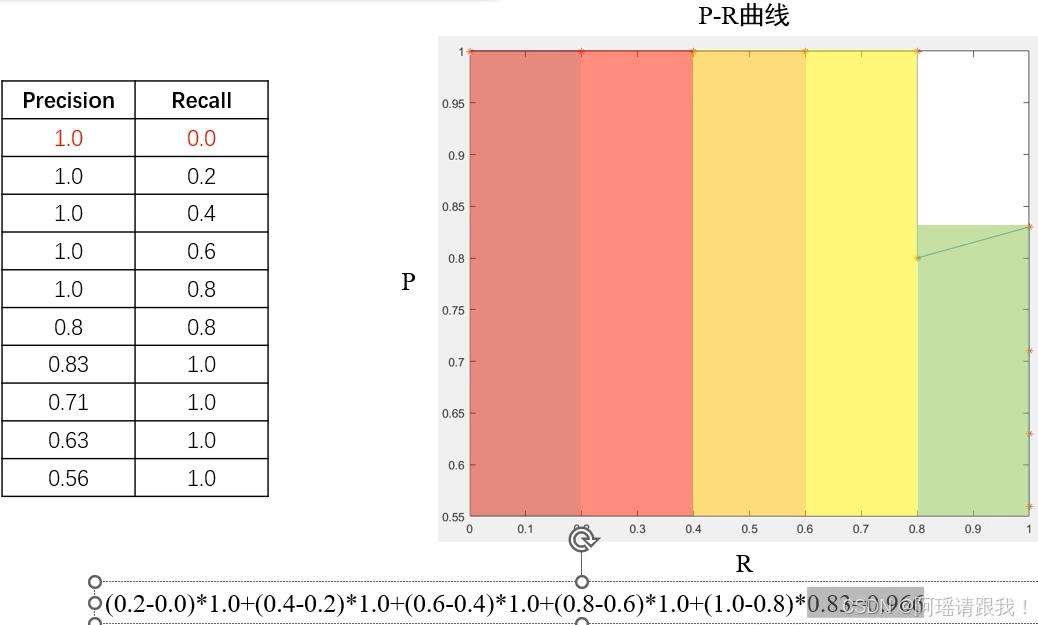
P-R图:
将所有训练集的预测框按照置信度从大到小排列:
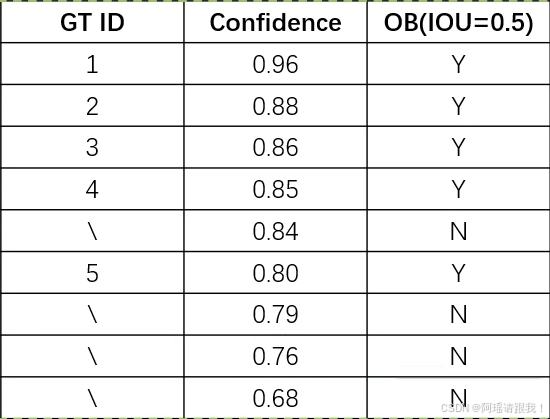
从第一个数据开始逐个计算当前所有行的PR值:

计算出区域内曲线(凹处可以拉平):
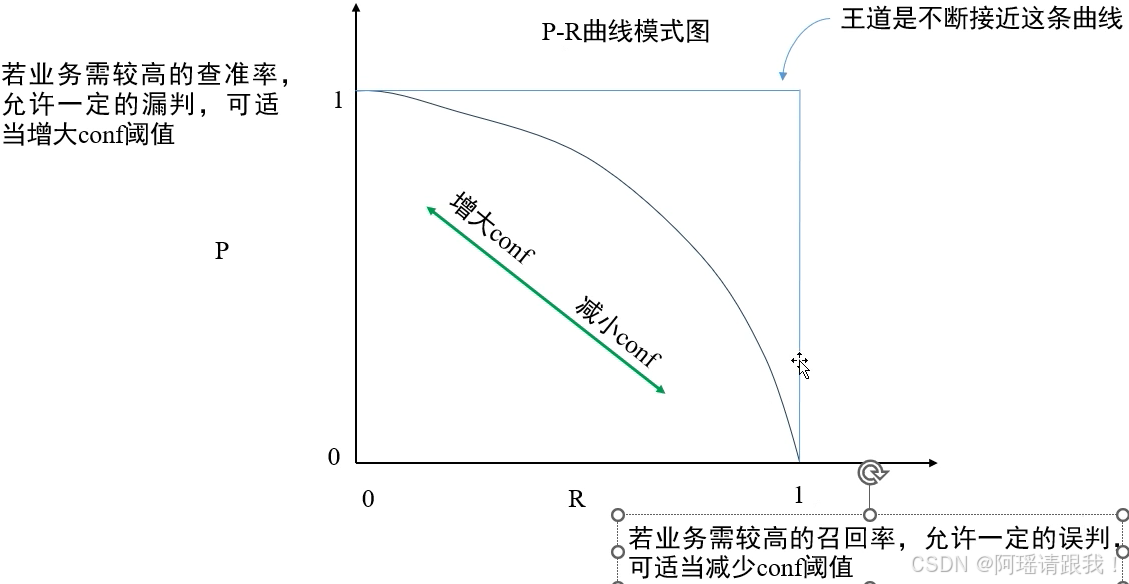
总结:
对比多个模型生成的csv文件数据:
import os
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import UnivariateSpline
import numpy as np
def get_csv_files(directory):
"""
获取指定目录下的所有CSV文件
"""
csv_files = []
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith('.csv'):
csv_files.append(os.path.join(root, file))
return csv_files
def read_csv_files_to_dict(csv_files):
"""
将每个CSV文件的内容读入字典,键为文件名,值为DataFrame
"""
csv_dict = {}
file_names = []
for file in csv_files:
file_name = os.path.basename(file)
file_names.append(file_name)
df = pd.read_csv(file)
csv_dict[file_name] = df
return csv_dict, file_names
def print_mAP50_95(csv_dict, file_names):
# 提取指定列
column_name = ' metrics/mAP50-95(B)'
# 曲线平滑
def moving_average(interval, windowsize):
p = k // 2
# 首尾元素重复 p 次
new_arr = np.concatenate((np.repeat(interval[0], p), interval, np.repeat(interval[-1], p)))
window = np.ones(int(windowsize)) / float(windowsize)
re = np.convolve(new_arr, window, "same")
return re
# 一个一个模型的数据进行循环
num = 0
for filename in file_names:
# 颜色列表
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
sp = csv_dict[filename][column_name].values
# sp = sp[:195]
# 方法1:使用 split 方法
parts = filename.split('.')
if len(parts) > 1:
name = parts[0]
else:
name = ""
plt.xlim(0, len(sp))
plt.ylim(0, max(sp+0.05))
plt.plot(sp, linestyle='--', color=colors[num])
# 曲线平滑
k = 19
y_av = moving_average(sp, k)
p = k//2
sp_smooth = y_av[p:-p]
# 绘制平滑后的曲线
plt.plot(sp_smooth, color=colors[num], label=name)
num += 1
# 添加图例
plt.legend()
plt.grid(True)
plt.xlabel('epoch')
plt.ylabel('mAP50-95')
plt.show()
def print_mAP50(csv_dict, file_names):
# 提取指定列
column_name = ' metrics/mAP50(B)'
# 曲线平滑
def moving_average(interval, windowsize):
p = k // 2
# 首尾元素重复 p 次
new_arr = np.concatenate((np.repeat(interval[0], p), interval, np.repeat(interval[-1], p)))
window = np.ones(int(windowsize)) / float(windowsize)
re = np.convolve(new_arr, window, "same")
return re
# 一个一个模型的数据进行循环
num = 0
for filename in file_names:
# 颜色列表
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
sp = csv_dict[filename][column_name].values
sp = sp[:192]
# 方法1:使用 split 方法
parts = filename.split('.')
if len(parts) > 1:
name = parts[0]
else:
name = ""
plt.xlim(0, len(sp))
plt.ylim(0, max(sp+0.05))
plt.plot(sp, linestyle='--', color=colors[num])
# 曲线平滑
k = 25
y_av = moving_average(sp, k)
p = k//2
sp_smooth = y_av[p:-p]
# 绘制平滑后的曲线
plt.plot(sp_smooth, color=colors[num], label=name)
num += 1
# 添加图例
plt.legend()
plt.grid(True)
plt.xlabel('epoch')
plt.ylabel('mAP50')
plt.show()
if __name__ == '__main__':
csv_files = get_csv_files("./data")
csv_dict, file_names = read_csv_files_to_dict(csv_files)
print_mAP50_95(csv_dict, file_names)
# modelnum = len(csv_dict)
# # 提取指定列
# column_name = ' metrics/mAP50-95(B)'
# name = file_names[0]
# mat = csv_dict[name]
# mAP_values = mat[column_name]
#
# # 绘制曲线图
# plt.plot(mAP_values, marker='o')
# plt.title('Metrics mAP50-95(B) Over Time')
# plt.xlabel('Index')
# plt.ylabel('mAP50-95(B)')
# plt.grid(True)
# plt.show()
# print(csv_dict)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









