







目录
一、对象的概念
我们知道程序都是由"数据变量+功能函数"构成的,在学习面向对象编程之前,程序中的数据变量和功能函数都是分开的,如下:
# 数据:name、age、sex
name='lili'
age=18
sex='female'
# 功能:tell_info
def tell_info(name,age,sex):
print('<%s:%s:%s>' %(name,age,sex))
# 此时若想执行查看个人信息的功能,需要同时拿来两样东西,一类是功能tell_info,另外一类则是多个数据name、age、sex,然后才能执行,非常麻烦
tell_info(name,age,sex)
而在学习了面向对象编程之后,其实所谓的对象:就将一些相关的"数据变量和功能函数"整合在一起存放到某个盒子里面(即所谓的一块内存空间)。
例如:映射到生活中类似于某个小姐姐的化妆盒。如果把”数据”比喻为”睫毛膏”、 ”眼影”、 "唇彩”等化妆所需要的原材料;把"功能’比喻为眼线笔、眉笔等化妆所需要的工具,那么”对象”就是一个彩妆盒, 彩妆盒可以把"原材料"与"工具”都装到一起。
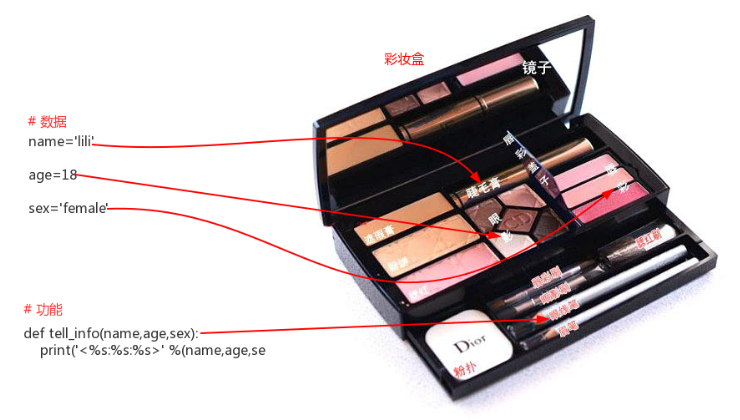
如果我们把”化妆”比喻为要执行的业务逻辑,此时只需要拿来一样东西即可, 那就是彩妆盒,因为彩妆里整合了化妆所需的所有原材料与功能,这比起你分别拿来原材料与功能才能执行,方便的多。
二、类与对象关系
所谓的类其实就是将多个对象中相同部分的"数据变量和功能函数"存放到类的内存空间中,这样各对象就不用都重复保存相同的数据,而只需通过类的内存地址访问到类内存空间就可以获得相同的数据部分,从而一定程度上减少了代码的冗余和内存空间的浪费。
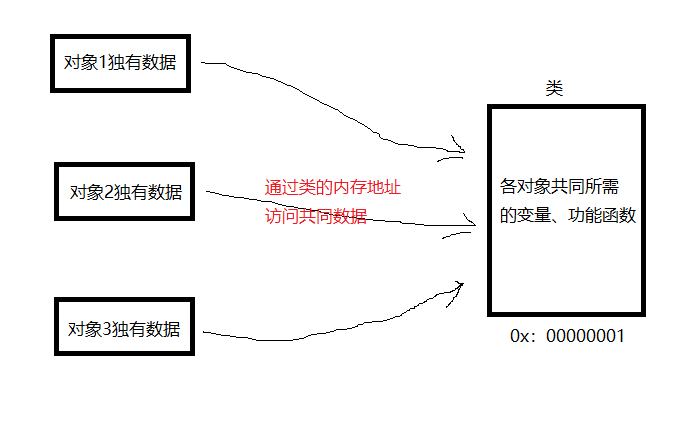
我们可以将类理解为从某种事物中提炼出来的普遍性、共有的特征;而对象就相当于许多事物中它们各自独有的、特殊性的特征。我们可以通过具有特殊性的对象访问到保存着各事物普遍性的类中数据。
三、面向对象编程
3.1 类的定义和实例化
下面我们以湖北工程学院的选课系统为例,来理解如何以面向对象的思维编写程序。首先我们知道所谓的面向对象就是将程序中用到的、相关联的数据和功能函数整合到对象中,然后再通过对象使用数据。
因此,首先选课系统中用到的角色有:学生、老师、课程等。很明显学生有学生的数据和函数部分、老师有老师所需的数据和功能函数。那么我们以学生分析:
# 学生1:
数据:
学校=湖北工程学院
姓名=李建刚
性别=男
年龄=28
功能:
选课
# 学生2:
数据:
学校=湖北工程学院
姓名=王大力
性别=女
年龄=18
功能:
选课
# 学生3:
数据:
学校=湖北工程学院
姓名=牛嗷嗷
性别=男
年龄=38
功能:
选课
从上面可以看出学生的共有数据有:
#数据:
学校=湖北工程学院
#功能:
选课
因此我们可以定义一个类来将各学生共同的数据保存起来:
class Student: #类名采用驼峰体
school="湖北工程学院" #数据
def schoose(self): #功能
print("%s is choosing a course!"%self.name)
pass
通过类来创建各学生对象(类实例化):
stu1=Studnet() #每调用一次类,就会在内存中申请一块新的内存空间供类对象使用
stu2=Student()
stu3=Student()此时,stu1、stu2、stu3都可以通过其内存中保留的类指针访问到类内存中的共同的数据。如果stu1、stu2、stu3想拥有其各自的数据,则需使用__init__()对象初始化函数:
class Student: #类名采用驼峰体
school="湖北工程学院" #数据
#该方法会在对象产生之后自动执行,专门为对象进行初始化操作,可以有任意代码,但一
定不能返回非None的值
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
pass
def schoose(self): #功能
print("%s is choosing a course!"%self.name)
pass
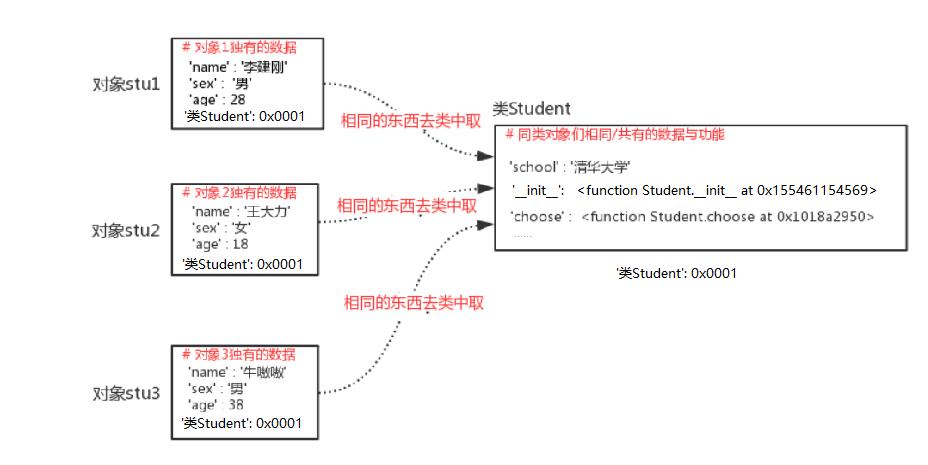
然后我们在重新实例出三个学生对象:
stu1=Studnet("李建刚",28,"男") #每调用一次类,就会在内存中申请一块新的内存空间供类对象使用
stu2=Student("王大力",18,"女")
stu3=Student("牛嗷嗷",38,"男")说明:
在执行如stu3=Student("牛嗷嗷",38,"男")实例化对象时:
1、解释器首先会自动调用__new__(cls)函数来为对象申请一个空的内存空间,并将地址返回给对象stu3。
2、然后解释器在通过括号中的参数stu3=Student("牛嗷嗷",38,"男"),自动调用类中的Student.__init__(stu3,38,“男”)函数来初始化实例对象,使对象拥有自身独自的数据变量
至此,我们已经成功创建了三个类对象啦!其内存中的保存形式如下:
3.2 属性访问
说明:
Student.__dict__: 里面以列表的形式保存着类内存中包含的数据。
stu1.__dict__: 里面以列表的形式保存着对象内存中包含的数据。
访问类属性和方法:
1 >>>Student.school #访问数据属性,等同于Student._ dict__ [ 'school']
2 '清华大学'
3 >>> Student. choose #访问函数属性,等同于Student._ dict__ [ ' choose']
4 <function Student . choose at 0x1018a2950>#说明:通过“类名.函数(self)"调用函数时,此种形式解释器并不会自动给self形参传值需要用户手动传递即函数的所有形参都要手动传值。
操作类对象属性:
1 >>>stu1.name #查看,等同于obj1._ _dict__ [ 'name']
2 >>> '李建刚'
3 >>> stu1. course=' python' #新增,等同于obj1.__ dict_ [ ‘course' ]= ' python'
4 >>> stu1.age=38 #修改,等同于obj1._ dict_ [ 'age']=38
5 >>> del obj1.course #删除,等同于del obj1._ dict_ [ ' course']
实例方法绑定对象:
实例方法绑定了哪个对象、则此方法就应该由哪个对象来调用,则就会将哪个对象当做第一个参数自动传递给方法中的首个参数(如:__init__(self)对象初始化函数方法)。
1 stu1. choose() # 等同于Student . choose(stu1)
2 stu2. choose() #等同于Student . choose(stu2)
3 stu3. choose() #等同于Student . choose(stu3)说明:
在执行 stu3. choose() 时,即将choose(self)函数绑定给了stu3对象,此时在调用stu3.choose(self)函数时,解释器会自动将stu3作为首个参数自动传递给self形参,用户无需手动显示传入。
因此在以 “对象.函数名()”的形式调用类中的实例方法时,类中函数的定义必须有一个形参来接收自动传递过来的值,其通常命名为self。
四、总结
1、类的定义形式:
class 类名:
变量=value
def __init__(self):
....
pass
def func(self):
....
pass
2、类中保存的是各对象共有的属性和方法,对象中保存着各自独特的属性和方法。
3、在通过"对象=类名(传给__init__()函数的实参)"形式实例化对象时,会先自动调用__new__(cls)函数为对象生成一个空内存并将地址返回给对象;然后解释器会自动调用类中的__init__(self)来初始化对象即为对象创建各自独特的属性。
4、除__init__()函数中的变量外,类中定义的其它所有变量和函数都保存在类所在的内存中,在定义类的时候,类中的代码会自动执行。
5、在通过“对象.函数(self)”调用类中的实例方法时,解释器会自动将对象地址作为首个参数传递给形参self。“对象.函数(cls)”调用类方法时,解释器会自动将类的地址作为首个参数自动传递给cls即cls表示类的地址。“对象.函数( )”调用静态方法时,解释器不会自动给形参传值。
6、当类属性变量名和1实例属性变量名相同时,解释器会先使用实例属性,如果没有实例属性则在使用类属性即先从:“对象.__dict__”中查找,如果没有在从 “类名.__dict__”中查找。
声明:
@此文章参考了Egon林海锋老师的Python讲解。
@“山月润无声”博主专业水平有限,文章如有不妥之处欢迎广大IT爱好者批正。
















 1360
1360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











