







一、实验目的:
1
、掌握
MLP
和
BP
神经网络流程,并实现分类任务
2
、掌握
K-means
算法流程,并实现聚类任务
二、实验任务
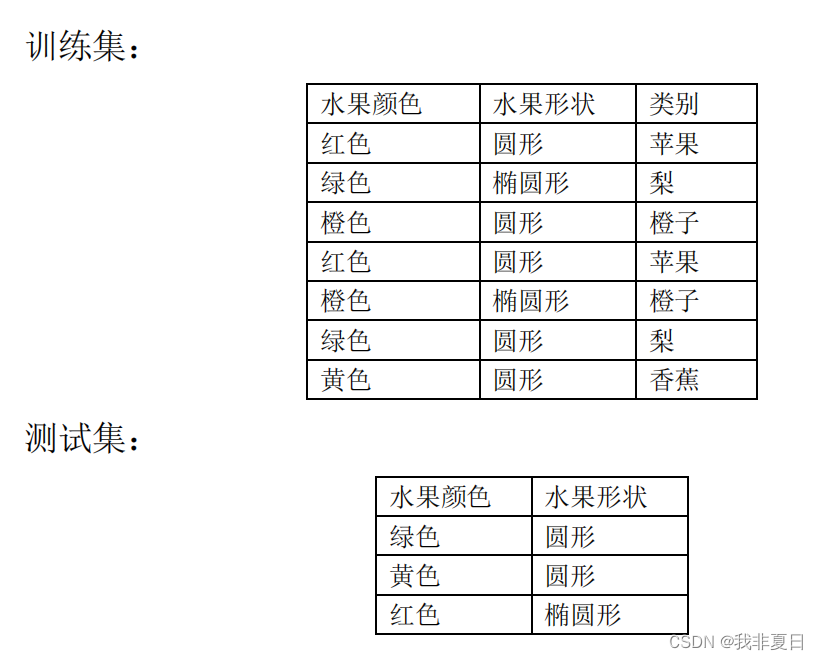
1.使用MLP实现水果分类:
实验描述:
有一个关于水果的数据集,其中包含两个特征:水果的颜色和形状, 使用多层感知机(MLP
)对水果进行分类。数据集分为训练集和测试 集,使用训练集训练 MLP
神经网络模型,使用测试集评估模型的性能,预测给定水果的类别。
实验思路:
准备数据集,然后使用多层感知机(MLP)来训练一个模型,并使用测试集来评估模型的性能。首先,将文本数据转换为数值形式。使用独热编码(One-Hot Encoding)来处理颜色和形状特征。使用scikit-learn的OneHotEncoder或LabelEncoder与pandas库来准备数据。构建MLP模型:使用scikit-learn的MLPClassifier来构建多层感知机模型。使用训练数据来训练MLP模型。使用测试数据来评估模型的性能,通常使用准确率作为评价指标。最后预测给定水果的类别。
实验代码:
#MLP 实现水果分类
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据
train_data = pd.DataFrame({
'水果颜色': ['红色', '绿色', '橙色', '红色', '橙色', '绿色', '黄色'],
'水果形状': ['圆形', '椭圆形', '圆形', '圆形', '椭圆形', '圆形', '圆形'],
'类别': ['苹果', '梨', &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









