







任务描述
1、Flume介绍
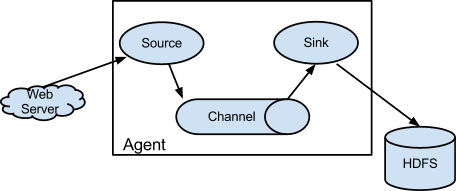
Flume是一种分布式、可靠且可用的服务,用于高效地收集、聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有健壮性和容错性,具有可调的可靠性机制和许多故障切换和恢复机制。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
2. Flume的一些核心概念
Client:Client生产数据,运行在一个独立的线程;简单的说就是生产数据的源头,例如Nginx、Tomcat、Apache等Web服务器。
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 Avro 对象等。)
Flow: 简单的说就是一条数据(Event)从起点到终点的抽象
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个Agent,但是可以在一个Agent中包含多个Source和Sink。)
Source: 数据收集组件。(Source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 Sources 和 Sinks ,这个有点像一个队列。)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
任务实现
1. 背景介绍
随着互联网的发展,在互联网上产生了大量的Web日志或移动应用日志,日志中包含大量用户的重要信息,通过日志分析,用户可以获取网站或应用的访问量,以及网页访问人数、网页价值、用户特征、用户兴趣、购买力分布等。
一般中型的网站(10万的PV以上),每天会产生1GB以上的Web日志文件。大型的网站,甚至可能每小时会产生500GB—1TB的数据量。对于这种规模的日志数据,使用Spark进行大规模的日志分析与日志处理,能够达到很好的效果。
Web日志由Web服务器产生,现在互联网公司使用的主流的服务器包括:Nginx、Apache、Tomcat等。从Web日志中可以获取网站每类页面的PV值(页面浏览)、UV(独立IP数)。更复杂的应用场景是,利用这些日志信息可以计算得出用户所检索的关键词排行榜、用户停留时间最高的页面、构建广告点击模型、分析用户行为特征等。
2. 常见日志格式
目前常见的Web日志格式主要由两类:一种日志格式是Apache的NCSA日志格式,另一种日志格式是IIS的W3C日志格式。
Nginx日志格式
Nginx的log日志分为access log和error log,其中access log记录了哪些用户访问了哪些页面、IP地址和其他的访问信息;error log则是记录服务器的错误日志。
错误日志的格式如下:
10.1.1.1 - - [22/Aug/2014:16:48:14 +0800] "POST /ajax/MbpRequest.do HTTP/1.1" 200 367 "-" "Dalvik/1.6.0 (Linux;U;Android 4.1.1;ARMM7K Build/JRO03H)" "119.189.56.175"127.0.0.1:8090 0.022 0.022主要参数说明(本次实验中涉及的一些要素):
- remote_addr:记录客户端的IP地址。如:202.34.173.11 。
- remote_user:记录客户端用户名称,如:- - 表示为空。
- time_local:记录访问时间与时区,如:[16/Sep/2013:06:49:57 +0000]。
- request:记录请求的UTL与HTTP协议,如:"GET /images/abc.jpg HTTP/1.1"。
- status:记录请求状态码,如:200(成功)。
- body_bytes_sent:记录发送给客户端文件主体内容的大小,如:19939。
- http_referer:用来记录从哪个页面链接访问过来的,如:http://www.abc.com/B00M。
- http_user_agent:记录客户端浏览器相关信息,如:"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/29.0.1547.66 Safari/537.36"。
Nginx的access log的格式是可以自定义的,只需要在Nginx的nginx.conf配置文件中找到:log_format 进行修改即可。
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"'
'$upstream_addr $upstream_response_time $request_time ';
access_log logs/access.log main;
W3C日志格式
W3C扩展日志格式(ExLF)具备了更为丰富的输出信息,主要是微软IIS(Internet Information Services)中应用。下面是一段常见的IIS生产的W3C扩展Web日志:
2011-09-01 16:02:22 GET /Enterprise/detail.asp 70.25.29.53 http://www.example.com /searchout.asp 202 17735 369 4656这个日志可以解读为:IP是70.25.29.53,来自http://www.example.com /searchout.asp的访客,在2011-09-01 16:02:22,以GET请求方式访问了主机的 /Enterprise/detail.asp,访问成功,得到17735字节的数据。
主要参数说明:
- 日期:date 动作发生时的日期。
- 时间:time 动作发生时的时间(默认为UTC标准)。
- 客户端IP地址:c-ip 访问服务器的客户端IP地址。
- 用户名:cs-username通过身份验证的访问服务器的用户名,匿名用户(用‘-’表示)。
- 服务名:s-sitename 客户所访问的Internet服务名以及实例号。
- 服务器名:s-computername 产生日志条目的服务器的名字。
- 服务器IP 地址:s-ip 产生日志条目的服务器的IP地址。
- 方法:cs-method 客户端执行的行为(主要是GET与POST行为)。
- URI Stem:cs-uri-stem 被访问的资源,如Default.asp等。
- URI Query:cs-uri-query 客户端提交的参数(包括GET与POST行为)。
- 协议状态:sc-status 用HTTP或者FTP术语所描述的、行为执行后的返回状态。
- 发送字节数:sc-bytes 服务端发送给客户端的字节数。
- 接受字节数:cs-bytes 服务端从客户端接收到的字节数。
- 花费时间:time-taken 执行此次行为所消耗的时间,以毫秒为单位。
- 协议版本:cs-version 客户端所用的协议(HTTP、FTP)版本。
- 主机:cs-host 客户端的HTTP报头(host header)信息。
- 用户代理:cs(User-Agent) 客户端所用的浏览器版本信息。
- Cookie:cs(Cookie) 发送或者接受到的cookie内容。
- Referrer:cs(Referer) 用户浏览的前一个网址,当前网址是从该网址链接过来的。
如果用户相要更多多的信息,则需要使用其他手段去获取,例如,通过JS代码单独发送请求,并使用cookies记录用户的访问信息。
本次实验使用的是Nginx的日志数据,利用这些日志信息,我们就可以深入分析用户行为或网站状况了。
3. 传统单机日志数据分析示例:
当数据量较小时(10GB以内),单机处理能够解决,可以通过各种Unix/Linux命令或者工具,awk、grep、sort、join等都是日志分析的利器,再配合Perl、Python、正则表达式,基本上可以解决常见日志分析的问题。
- 使用Linux Shell进行单机日志分析
例:从前面的nginx日志中得到访问量最高的前10个IP,通过下面的Shell进行分析。
cat access.log.10 | awk '{a[$1]++} END {for(b in a) print b"\t"a[b]}' | sort -k2 -r | head -n 10运行上述命令,可得到类似下面的结果:
163.177.71.12 972
10.226.68.137 927
183.195.232.138 917
50.116.27.194 97
61.135.216.104 94
......
202.181.51.212 9- 使用Python进行单机日志分析
例:使用前面的nginx日志,统计基于每个独立IP地址的点击率。
#!/usr/bin/env python
# coding:utf8
import re
import sys
contents = sys.argv[1]
def NginxIpHite(logfile_path):
#IP:4个字符串,每个字符串为1—3个数字,由点连接
ipadd = r'\.'.join([r'\d{1,3}']*4)
re_ip = re.compile(ipadd)
iphitlisting = {}
for line in open(logfile_path):
match = re_ip.match(line)
if match:
ip = match.group()
#如果IP存在则增加1,否则设置点击率为1
iphitlisting[ip]=iphitlisting.get(ip,0)+1
print iphitlisting
NginxIpHite(contents)
运行并打印结果【./nginx_ip.py access_20180314.log】可得到类似下面的结果:
{'163.177.71.12':1, '163.177.71.12':2, '163.177.71.12':1, '163.177.71.12':1,
'163.177.71.12':2, '163.177.71.12':3, '163.177.71.12':26, '163.177.71.12':9,
'163.177.71.12':4, '......, ......, ......, '163.177.71.12':20,}
- 大规模分布式日志分析情况分析
当数据量每天以10GB以上增长时,单机处理能力已经不能满足需求。此时就需要增加系统的扩展性,用大数据分析和并行计算来处理。在Spark之前,海量数据存储和海量数据分析都是基于Hadoop、Hive等数据分析系统的。Spark的出现,使得全栈数据分析更加容易。并且,Spark非常适合构建多范式日志分析流水线。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









