






 本文概述了SQL从1970年代的诞生、IBM的SystemR和Oracle的发展,到成为ANSI和ISO标准,以及在商业中的广泛应用。SQL以其简洁的语法和强大的功能,至今仍是商业数据存储和查询的主流语言。
本文概述了SQL从1970年代的诞生、IBM的SystemR和Oracle的发展,到成为ANSI和ISO标准,以及在商业中的广泛应用。SQL以其简洁的语法和强大的功能,至今仍是商业数据存储和查询的主流语言。
现在稍微懂点计算机知识的人应该都知道计算机所有的持久化信息都存在磁盘上面。可以简单想象的是上面密密麻麻布满了0和1。那这种不被一般人理解的信息是怎么发展成为现在支撑整个社会运转的科学呢。Sql功不可没,下面简单阐述下Sql的发展过程。
第一阶段:1970年代,由IBM公司Edgar Frank Codd(埃德加·弗兰克·科德)博士描绘的关系型数据库的模型,因此被称为"关系型数据库之父"。 第二阶段:1974年,IBM 希望把 Codd 的想法变成现实,着手开发一款名为 SystemR 的数据库,并研发出一套结构化查询语句 SEQUEL,这就是 SQL 的雏形。System R 数据库于 1978 年第一次发布,用于科研和实验。 第三阶段:1979年,Oracle 公司首先提供商用的 SQL,随后 IBM 公司也在 DB2 数据库中实现了SQL。 第四阶段:1986年,美国 ANSI 采用 SQL 作为关系型数据库管理系统的标准语言,紧接着国际标准组织(ISO)也将SQL 采纳为国际标准。 第五阶段:1989年,ANSI 发布了 SQL 标准的重大更新版本,以弥补旧版的不足,称为 ANSI SQL 89,该版本也被 ISO 采纳 目前市面上的主要关系型数据库都有自己SQL变异,但基本遵循ANSI SQL 89
1.伟大的开始

在科德的设计中,他提出了两种可能的关系数据库语言。这两种语言都具有数学特征,还包含许多希腊字母和注脚(类型线下面的数字和符号),只有经过训练的数学家才能读懂,而且无法在键盘上打出来。钱柏林说:“显然,如果完全听从科德的观点,只依靠这些符号,那么不可能在市场上大卖。”因此钱柏林和他的同事雷·博伊斯开始着手解决新数据库系统的用户界面问题。钱柏林和博伊斯早期曾在SQL语言上密切合作,但是项目刚开始一年,博伊斯就在1974年因为脑动脉瘤与世长辞了。他们想开发一种具有特殊用途、易于理解并能用计算机编译的语言。通过这种关系型的方法,人们能够以一种更加自然的方式向数据库提出问题,因为这与导航模式不同,问题本身并不包含通向数据的途径。
2.良好的继承
要想达到预期效果,这种语言就要经过精心设计和规划,达到一种平衡:有一定的构造使编译器能够翻译给计算机,并且像自然语言一样让人类觉得简单易用。钱柏林和博伊斯设计的语言类似于一种混杂英语。事实上,它起初被称为SEQUEL(Structured English Query Language,结构化英语查询语言),后来IBM的律师发现SEQUEL是一家英国飞行器制造商的注册商标。钱柏林说这样也好,用英语做参考就有些误导了。他解释说:“这不是英语,因为对于数据查询来说,英语简直糟透了,容易引起歧义。”
为了使SQL语言具备有规则的结构,能够被计算机处理,“动词”或者说数据操作指令被限制在了大约8个基本概念中,例如SELECT、FROM、WHERE、GROUPBY和ORDERBY等。被查询的数据也同样以一定的结构格式储存起来——如同特德·科德在他的文章中所描述的相关的数据表。这些表可以包括雇员(简称为EMP),在一张大的表单里面有他们的姓名、部门、工作地点、工作职责和薪酬。因此使用SQL语言查询“查找(FIND)员工玛丽·史密斯的工资”显示如下:
SELECT SALARY FROM EMP WHERE NAME="MARYSMITH"
再看另一个稍微复杂的例子,一家公司希望查看某些客户的信贷额度。客户数据储存在关系数据库中,其中包括他们每个人的姓名、居住的城市、州、邮政区号和信贷额度。因此用SQL语言查询“找到信贷额度高于1万美元的客户,并将他们按照从高到低的信贷额度的顺序排列”显示如下:
SELECT NAME,CITY,STATE,ZIPCODE FROM CUSTOMER WHERE CREDITLIMIT>10000 ORDER BY CREDITLIMIT DESC
IBM并没有很快地将SQL语言推向市场。1979年,位于硅谷的一家新成立的公司——关系软件有限公司(Relation Software, Inc.),推出了第一个SQL语言数据库产品,这家公司在三年后更名为甲骨文公司(Oracle Corporation),其中一部分原因就是IBM实验室发表了他们自己的研究成果。关系数据库的研究也取得了其他的一些成果,例如伯克利的迈克尔·斯通布雷克(Michael Stonebraker)和尤金·王负责的政府资助的Ingres项目也发表了研究成果。
但关系数据库思想的发展一直悬而未决,直到企业家劳伦斯·J·埃里森(Lawrence J. Ellison)将其价值挖掘出来。劳伦斯·J·埃里森是甲骨文公司的创建者和首席执行官,他富可敌国。埃里森很早就显示出了富有想象力的市场观念,他称自己首个产品为甲骨文第二版。但那实际上却是第一版,因为懂行的用户都尽量避免购买软件的第一版,认为里面的缺陷很多。
1978年的夏天,埃里森给钱柏林打电话,告诉钱柏林他发现一篇发表于1974年的文章是多么的有用。这篇论文就是钱柏林和博伊斯写的《SEQUEL:结构化英语查询语言》。“我们写了篇文章,而拉里·埃里森以此建立了一家公司”,钱柏林指出。埃里森致电的目的不仅仅是为了交际问候,他很想从钱柏林那里得到详细的技术信息——也就是所谓的“误码值”——这样他的产品就可以与IBM的产品完全兼容。IBM认为,即便对方是家新成立的公司,这在一定程度上也是在帮助竞争对手,因此他们拒绝了埃里森。IBM的管理层不愿意采用SQL语言关系数据库技术,因为在20世纪70年代后期,公司的IMS导航产品销售火爆。而来自甲骨文和其他公司的外部竞争者,让IBM公司对来自于自己实验室的、具有非凡意义的数据库研究成果刮目相看,这实在是太讽刺了。
由于使用了人们熟悉的术语,关注人类的提问形式,而非徘徊在计算机底层的数位,SQL语言极大地简化了建立数据库应用程序的过程。人们每天都在不知不觉中使用SQL系统。当商场里的机器读取信用卡时,或者人们在ATM机上按下数字时,这些数字都被SQL语言的语句用于存取数据库,更新用户的信用卡和银行账户信息。尽管SQL语言取得了这样的成功,它还是与其原本的目标有一点距离。当初,钱柏林和他的同事以为普通大众能够通过自行使用SQL语言,以一种全新的方式与数据互动。但是从很大程度上讲,事实并非如此。使用ATM机的用户确实直接进入了巨型数据库,但藏在按键或触摸屏背后的却是SQL语言。
1975年,钱柏林终于意识到将SQL语言普及给除专业计算机程序员以外的普通大众并非易事。R系统项目招募了一批在圣何塞州立大学就读的大学生,来试验这些随机选择的学生们对于SQL语言的反应。结果并不令人满意。经过努力地学习,他们能够掌握SQL语言,但是这个过程耗时太长,而且学生们在使用中也错误百出。“我们在1975年的时候对于普通民众使用计算机语言过于乐观了。”一天,坐在自己IBM办公室里,俯瞰圣何塞郊外褐色山丘,钱柏林评指出:“计算机按照字面意思,逐字逐句地接受每一条指令,它们并没有常识。因此即使是像SQL这样含有英文单词的语言,也无法像自然语言一样通俗而灵活。”
3.丰富的未来

如今,世界上90%的商业数据储存在关系数据库中,而钱柏林的SQL语言是占据主导地位的数据库语言。这是很多人共同努力的成果,其中包括帕特·塞林格,她编写了“优化器”(optimizer),能将SQL语言翻译成详细的计划,用来重新找回数据。而吉姆·格雷发明了交易处理技术,使得SQL语言在现代电子商务中广泛应用。钱柏林将这一切融为一体,他知道怎样将这些碎片组合起来——数据定义、数据操作和数据表等。他看到了特德·科德观点的重大价值,并将其付诸实践。阿兰·凯伊曾经说:“观点的价值是80个智商分。” 钱柏林将一种精炼的、简化的视角带到了关系数据库软件领域。“钱柏林绝对是个优秀的程序员,他知道怎样将这些想法变成现实”,吉姆·格雷评论说:“所有这些对钱柏林来说是显而易见的,直到他把这些展示给我们看的时候,我们才明白过来。”
4.我们为什么仍然在使用SQL?
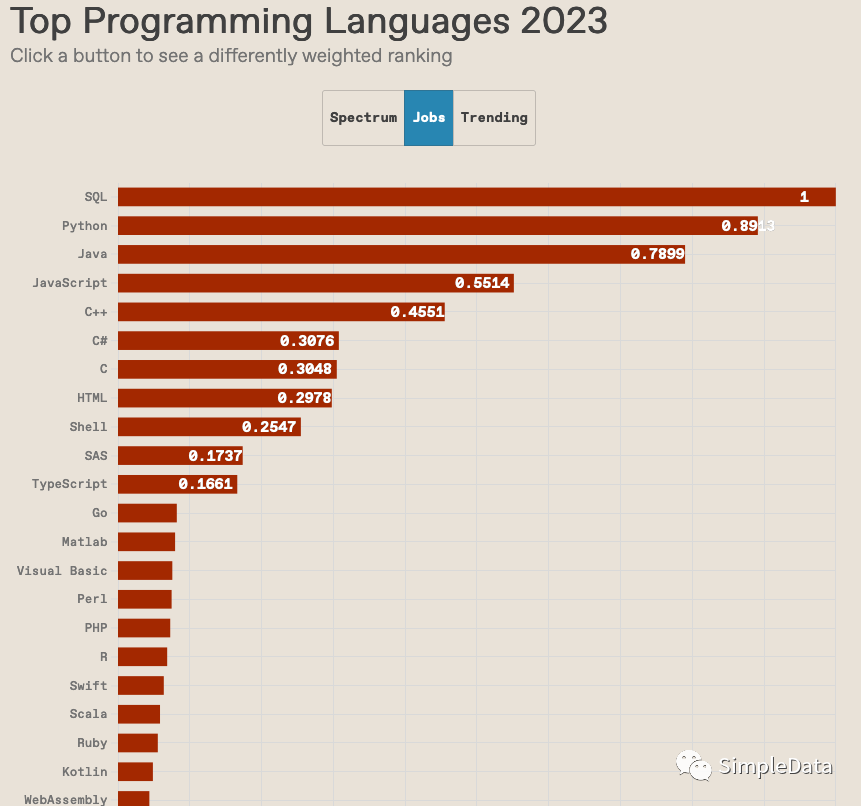
近日,IEEE Spectrum 重磅发布了 2023 年度编程语言榜单,该调查中间有一项结论让我们非常惊讶:SQL是这个世界上排名第一广泛使用的就业程序设计语言
对于一个已经43岁高龄的语言,这是一种了不起的成就,尤其是在指数级变化(摩尔定律)在软件技术和产业中非常普遍的今天。
就像是MailChimp如何成为“发送newsletter邮件”的近义词一样,如果你希望在工作中与数据打交道,你就需要使用SQL和RDBMS。实际上,当你不打算不使用他们时,必须要找到一个很好的理由才行,就像找理由解释你为什么不使用MailChimp发送newsletter,或者使用Stripe来进行银行卡支付一样。
但是人们还是会去使用别的自动邮件程序以及支付的解决方案,就像人们使用非SQL数据库一样。即使其他的数据库是可用的并且有很多成熟的技术,SQL仍然一直处于统治地位。
最后,我们有8种理由在43年以后继续使用SQL:
1、 简单的数学运算
SQL原生基于关系代数(relational algebra)以及元组关系运算(tuple relational calculus)——这两种数学运算形式都是由Mr. Codd专门为关系数据库开发的。所以说,SQL是一种专门为数据设计的语言——非常的好!
2、 经过实战检验
RDBMS已经存在很长的时间,所以被使用在海量的不同场景下面。从Web出现之前的线下数据库,一直到被深度优化过的SQL数据库被当作核心角色运行在全球性的Web应用(比如Facebook)上。SQL和RDBMS是被实战检验过的,在各个不同的产品线中间不间断地运行了百万小时。
其实对于一个软件可用还有很多可以说道的地方,尤其是你面对的数据中间存在缺陷、冲突、丢失等情况。边界情况通常有一些成熟的解决方案,比如备份、变更管理、操作验证等等。所以SQL基本上是最优的选择。
3、知识和社区
当任何一个事物存在一定的时间以后,一个围绕它的知识体系就能够被建立起来。SQL也是一样的。这么多年来,各种各样的知识、经验,以文档、兴旺的社区、以及数也数不清的技术牛人的形式一直传承着。如此大量的信息以及围绕着的活跃社区为维持这个技术的存在做了很多很多的事情。由于社区非常的活跃、文档非常的丰富,人们被这种技术强大基础所吸引。同时,正是因为大量的人群被吸引,造就了更多、更广博的文档和更活跃的社区。这么多年,SQL正经历这种良性循环。
4、简易性
跟随程序设计语言一路走来,SQL的学习一直是这么的简单。只需要几天的时间,一个人就能够学习到SQL不少的函数,并且使用它们去查询数据并返回数据,方便!
甚至连市场销售、产品经理等非技术人员也能够学会SQL并使用一些简易的查询来获取用于支持他们工作的数据结果。
“SQL - it’s so easy marketers can learn it.”
深入地了解SQL所运行的关系数据库系统相比与使用SQL完全是另一回事情。但对于绝大部分查询所存在的场景,SQL非常的好。
5、普适性
半数以上的SQL和RDBMS的开发者会毫不犹豫地说,SQL是一门普适性极高的语言。这不是坏事。就像上面说的,在支持文档和社区非常发达的情况下,加之简易性,SQL已经成为了开发者和与他们共事的人们中一个通用的基础知识。
这意味着这种技术可以在不同的公司甚至产业领域相互移植,而人才一直是充足的,就像是燃料一样不断给社区加油。
SQL数据库的普适性形成了一个非常强大的良性循环。非常的强大。
6、开源和协同性
通常,SQL并不能说的彻底地可协同。供应商并没有严格地遵循相同的标准(参考Oracle和MS SQL Server),不同主要来自于语法的区别。但是在不同供应商的SQL版本中,SQL语言本身变化并不大,只需要做一些小修改,复用SQL代码就成为可能。当然这不是最理想的状态,毕竟有供应商不希望自己的语法能够支持复用。
在最近的一些年(1995年至今),开源的SQL解决方案(MySQL和PostgreSQL)成为了行业的首选。DB-Engines网站近年榜单。

7、 当你能够使用SQL的时候,为什么还要写代码?
有一句俗话说到:
“Don’t do in code what you can get the SQL server to do well for you”
这话背后的逻辑是,在绝大多数的情况下面,数据库软件能够在发现最有效解决问题的方案上比任何人使用代码要有效的多。
换句话说,SQL是针对数据的拼接、过滤、字段提取等操作设计的。当你使用代码去实现这些功能,而不是使用数据库软件常常会导致将时间浪费在没有意义的代码上。
我们看一个例子,我们需要做一份“加利福尼亚Q3的收入报表”。
具体的需求是:“将所有的用户从表格“加利福尼亚”取出来,排序、加总最后生成一栏叫“加利福尼亚Q3的收入”的列”
SQL代码如下:
SELECT SUM(Value_USD) AS California_Revenue_Q3 FROM Transactions WHERE Location = 'California' AND DATEPART(q, Date) = 3 AND YEAR(Date) = 2017;
如果你想统计所有州的收入情况,只要改成:
SELECT Location, SUM(Value_USD) AS Revenue_Q3 FROM Transactions WHERE DATEPART(q, Date) = 3 AND YEAR(Date) = 2017 GROUP BY Location ORDER BY Location;
如果我们希望选择前五个区域,只要改成:
SELECT TOP 5 Location, SUM(Value_USD) AS Revenue_Q3 FROM Transactions WHERE DATEPART(q, Date) = 3 AND YEAR(Date) = 2017 GROUP BY Location ORDER BY SUM(Value_USD) DESC;
而如果我们使用其他语言对这个功能进行实现,则会是非常复杂、耗时的一个过程。SQL就是为了对数据进行剖析设计的,并且确实很擅长。更不要说SQL的主旨是将计算施加给数据而不是将数据填充给计算。
“Bring the computation to the data rather than bringing the data to the computation”
8、 SQL/RDBMS 和 非SQL/RDBMS 是不同的角色
数据库软件是各种工具,并不都是锤子。他们可以是螺丝刀、扳手、锯子等等。每一种数据库扮演一种不同的角色解决不同的问题。在实际使用中,有SQL、键值对、时序、块链、嵌入等等。每一个都擅长一个领域而在其他领域表现不佳。
当您无法预见数据组合、聚合或使用的所有可能排列时,需要在系统中表达关系时,关系数据库就变得非常棒。而且,老实说,大多数系统属于这一类。此外,SQL语言本身提供了一种用户友好的方法来按照需要来组织数据。
SQL / RDBMS只是特定工作的许多工具之一,而且恰好是许多工作中完美可行的工具。当数据完整性是一致的(例如,在金融领域),它们是最好的。
SQL数据库有其缺点,不是某些作业的最佳选择。但是绝大多数情况下,他们能够打败其他所有非SQL解决方案。
而如果您将要扩大规模,实际上只有一小部分人将需要担心扩展RDBMS——你不是Facebook或Google。你仍然可以拥有数百万用户的SQL数据库,没有任何问题。
此外,你还是可以扩展RDBMS,只要你知道你需要做什么样的trade-off。
另一个43年?
尽管无数其他的数据库系统和技术日益普及,SQL数据库毫无疑问仍然会继续存在——至少在可预见的将来。随着大数据,深度学习和物联网的出现,不出以外,数据库技术仍然会再茁壮成长另一个43年。
SQL数据库确实有其缺点。但是对于大多数用例而言,兴旺的社区、语言的简单性和RDBMS的基本结构使其成为数据库技术的更好选择之一。
为什么说43年后仍然会使用SQL,因为它确实有效并且可以减少90%的工作时间。作为一个开发人员,面对日益复杂的技术蓝图和大量的技术整合,对于SQL,你不会要求更多了。
 https://mp.weixin.qq.com/s/yP1CYdcWS4OtZBoNfD2TMA
https://mp.weixin.qq.com/s/yP1CYdcWS4OtZBoNfD2TMA

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









