







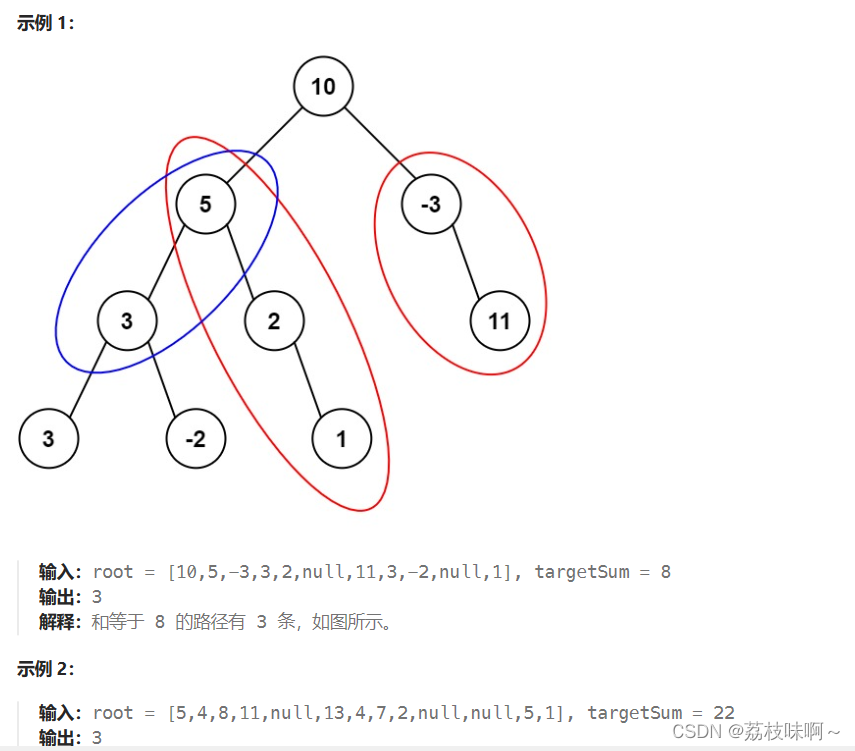
看完题目我就拿直接用递归写了如下代码:
class Solution {
private int ans;
public int pathSum(TreeNode root, int targetSum) {
ans =0;
dfs(root, targetSum, 0);
return ans;
}
public void dfs(TreeNode root, int targetSum, int sum){
if(root == null)return;
sum += root.val;
if(sum == targetSum)ans++;
dfs(root.left, targetSum, sum);
dfs(root.left, targetSum, 0);
dfs(root.right, targetSum, sum);
dfs(root.right, targetSum, 0);
return;
}
}dfs方法中的参数sum表示从前面某个节点到上一个节点的和,拿这个sum加上当前节点的值如果等于targetSum那么答案数+1,然后可以把现在的sum往下面传递,也可以传一个0下去表示从下一个节点开始计算和,然后示例过了,测试用例没过,因为这样的话重复计算了多个答案,比如一个全右的树1,2,3,4,5,target=3,那么在dfs1的时候,传了sum等于0,然后dfs2的时候又传了sum等于0,然后dfs3,这条1,2,3的路径给算进去了,所以这样是不行的。然后自己想了一会没思路就直接看了题解,
题解的第一种做法用的就是深度优先,但和我的不一样,他用了两层递归。
首先定义第一个递归方法:
public int rootSum(TreeNode root, int targetSum)它表示以root为起点的路径中,和为target的个数。在主函数中递归遍历每个节点,把这些节点的rootSum加起来。以下是方法一的代码:
class Solution {
public int pathSum(TreeNode root, int targetSum) {
if(root == null)return 0;
int ans =0;
ans+=rootSum(root,targetSum);
ans+= pathSum(root.left, targetSum);
ans+=pathSum(root.right, targetSum);
return ans;
}
public int rootSum(TreeNode root, long targetSum){
if(root == null)return 0;
int ret = 0;
if(root.val == targetSum) ret++;
ret+= dfs(root.left, targetSum-root.val);
ret+= dfs(root.right, targetSum-root.val);
return ret;
}
}
在rootSum()方法中要算以root为起点和为targetSum的路径数,就是算以root.left为起点和为targetSum-root.val的路径数加上以root.right为起点,和为targetSum-root.val的路径数。当root.val=targetSum时+1。然后主函数递归遍历每个节点,使得每个节点都调用一遍rootSum()方法。
方法一的时间复杂度时O(n2)很高,做了很多重复的计算。方法二是利用了HashMap里面存放前缀和来减少遍历次数。以下是方法二代码:
class Solution {
public int pathSum(TreeNode root, int targetSum) {
Map<Long, Integer> prefix = new HashMap<Long, Integer>();
prefix.put(0L, 1);
return dfs(root, prefix, 0, targetSum);
}
public int dfs(TreeNode root, Map<Long, Integer> prefix, long curr, int targetSum) {
if (root == null) {
return 0;
}
int ret = 0;
curr += root.val;
ret = prefix.getOrDefault(curr - targetSum, 0);
prefix.put(curr, prefix.getOrDefault(curr, 0) + 1);
ret += dfs(root.left, prefix, curr, targetSum);
ret += dfs(root.right, prefix, curr, targetSum);
prefix.put(curr, prefix.getOrDefault(curr, 0) - 1);
return ret;
}
}
Map<Long, Integer> prefix里面存的是,路径和为key的数量value,long curr表示从根节点到当前节点的和,这一点必须明白。
假如根节点是root,我们正在访问的节点是node,这条路径就是root->p1->p2->..->pk..->node。计算到node的时候从root到node的和是curr,那么我们只要找到前面的一个节点pk,它的curr1是curr-targetNum,那么从pk到node的和就是tagetNum。我们不需要找到这个pk,只需要知道这条路径上有多少个这样的pk就行。所以我们的HashMap中存放的是和为key的数量而不是节点。
理解了这个看dfs方法就比较容易了。
ret = prefix.getOrDefault(curr - targetSum, 0);这个HashMap的getOrDefault方法是先去get这个key这里是curr-targetSum。如果没有这个key就返回默认值这里是0。这样就拿到了以当前节点为终点和为target的路径的数量,
prefix.put(curr, prefix.getOrDefault(curr, 0) + 1);然后再把从root到当前节点的和放进map里面,然后递归遍历子节点。因为这个prefix的map是全局都在用的,所以当你把当前节点遍历完了你得回溯,把自己给移出去,因为递归回到前面的时候,前面的节点不能用后面节点的前缀和,所以要把这个前缀和的数量-1。
















 5131
5131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











