







概论
谈到Docker原理,我们先来三板斧。
- Linux命名空间(namespace)
- 控制组(cgroups)
- 联合文件系统(UnionFS)
然后我们心中要明白一件事情:
容器是一种特殊的进程。容器技术的核心功能就是通过约束和修改进程的动态表现,从而为其创造出一个边界。
其中Namespace技术是用来修改进程视图的主要方法。
Cgroups技术是用来制造约束的主要手段。
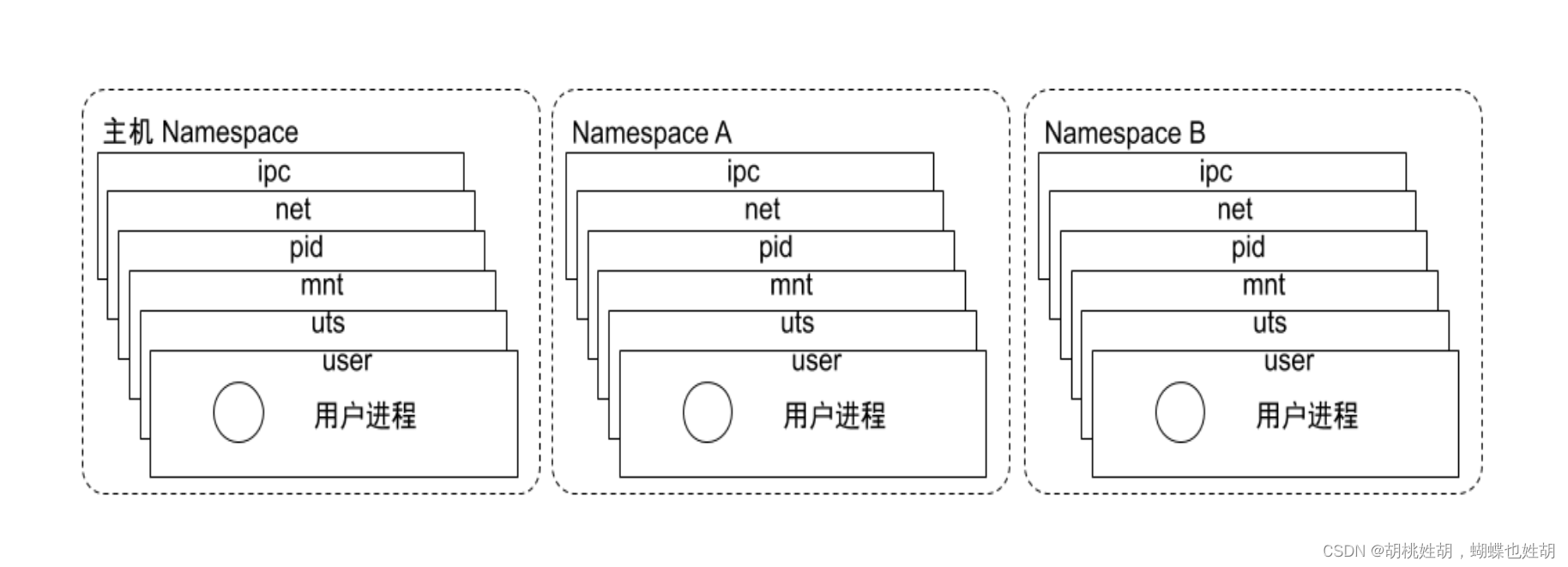
Namespace
Linux 的命名空间机制提供了以下8种不同的命名空间,包括 :
- CLONE_NEWCGROUP(用于隐藏进程所属的控制组的身份)
- CLONE_NEWIPC(隔离进程IPC,让只有相同IPC命名空间的进程之间才可以共享内存,信号量,消息队列通信)
- CLONE_NEWNET(隔离网络资源)
- CLONE_NEWNS(隔离文件目录)
- CLONE_NEWPID(隔离进程PID,每个命名空间都有自己的初始化进程,PID为1,作为所有进程的父进程)
- CLONE_NEWTIME(系统时间隔离)
- CLONE_NEWUSER(隔离用户)
- CLONE_NEWUTS(隔离主机名或者域名)
namespace系统调用接口
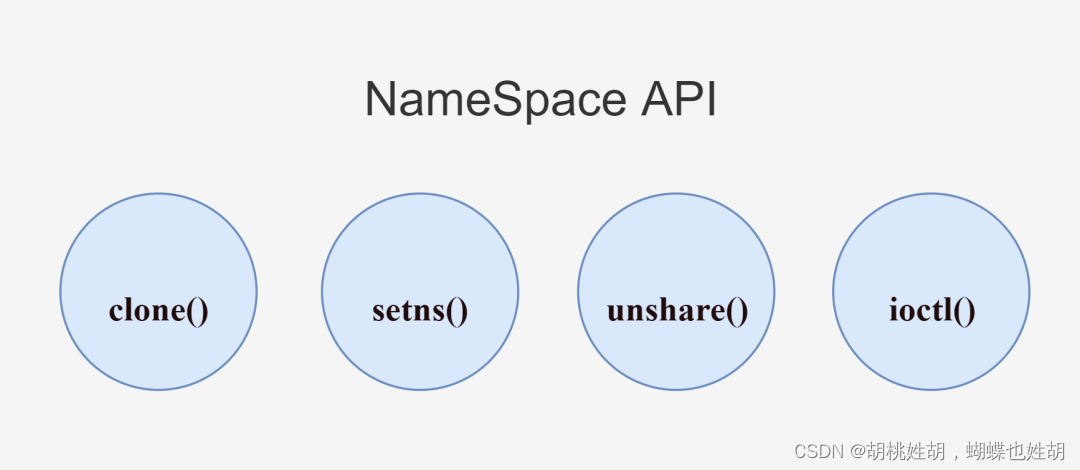
clone()
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
clone() 用于创建新进程,通过传入一个或多个系统调用参数( flags 参数)可以创建出不同类型的 NameSpace ,并且子进程也将会成为这些 NameSpace 的成员。
setns()
int setns(int fd, int nstype);
setns() 用于将进程加入到一个现有的 Namespace 中。其中 fd 为文件描述符,引用 /proc/[pid]/ns/ 目录里对应的文件,nstype 代表 NameSpace 类型。
unshare()
int unshare(int flags);
unshare() 用于将进程移出原本的 NameSpace ,并加入到新创建的 NameSpace 中。同样是通过传入一个或多个系统调用参数( flags 参数)来创建新的 NameSpace 。
ioctl()
int ioctl(int fd, unsigned long request, ...);
ioctl() 用于发现有关 NameSpace 的信息。
上面的这些系统调用函数,我们可以直接用 C 语言调用,创建出各种类型的 NameSpace ,对于 Go 语言,其内部已经帮我们封装好了这些函数操作,可以更方便地直接使用,降低心智负担。
使用Go实现简易的namespace隔离
package main
import (
"os"
"os/exec"
)
func main() {
switch os.Args[1] {
case "run":
run()
default:
panic("help")
}
}
func run() {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
我们需要在Linux系统下进行测试。
[root@localhost k8s]# go run main.go run echo hello
hello
当我们执行 go run main.go run echo hello 时,会创建出 main 进程, main 进程内执行 echo hello 命令创建出一个新的 echo 进程,最后随着 echo 进程的执行完毕,main 进程也随之结束并退出。
启动bash进程
先查看当前进程ID
[root@localhost ~]# ps
PID TTY TIME CMD
61779 pts/1 00:00:00 bash
62358 pts/1 00:00:00 ps
当前bash的pid为61779.
[root@localhost k8s]# go run main.go run /bin/bash
[root@localhost k8s]# ps
PID TTY TIME CMD
12429 pts/1 00:00:00 go
12447 pts/1 00:00:00 main
12450 pts/1 00:00:00 bash
13021 pts/1 00:00:00 ps
61779 pts/1 00:00:00 bash
[root@localhost k8s]# exit
exit
[root@localhost k8s]# ps
PID TTY TIME CMD
13611 pts/1 00:00:00 ps
61779 pts/1 00:00:00 bash
在执行 go run main.go run /bin/bash 后,我们的会话被切换到了 PID 12450的 bash 进程中,而 main 进程也还在运行着(当前所处的 bash 进程是 main 进程的子进程,main 进程必须存活着,才能维持 bash 进程的运行)。当执行 exit 退出当前所处的 bash 进程后,main 进程随之结束,并回到原始的 PID 61779的 bash 会话进程。
容器的实质是进程,你现在可以把
main进程当作是 “Docker” 工具,把main进程启动的bash进程,当作一个 “容器” 。这里的 “Docker” 创建并启动了一个 “容器”。
但是这个 bash 进程中,我们可以随意使用操作系统的资源,并没有做资源隔离。
那么我们接下来随便挑选两个资源来做一些限制。
UTS隔离
要想实现资源隔离,在 run() 函数增加 SysProcAttr 配置,先从最简单的 UTS 隔离开始,传入对应的 CLONE_NEWUTS 系统调用参数,并通过 syscall.Sethostname 设置主机名:
func run() {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(syscall.Sethostname([]byte("mycontainer")))
must(cmd.Run())
}
然后我们运行:
go run main.go /bin/bash
进入到新的命令行,然后输入hostname指令。
发现我们的主机名被改成mycontainer了,一切符合正常。但是我们输入exit,退出改命令行,再次查看主机名,却发现,我main进程所在的原来的主机的主机名被改成mycontainer了。
因此我们需要改变我们的代码,我们来认识一个机制。
在 Linux 2.2 内核版本及其之后,/proc/[pid]/exe 是对应 pid 进程的二进制文件的符号链接,包含着被执行命令的实际路径名。如果打开这个文件就相当于打开了对应的二进制文件,甚至可以通过重新输入 /proc/[pid]/exe 重新运行一个对应于 pid 的二进制文件的进程。
对于 /proc/self ,当进程访问这个神奇的符号链接时,可以解析到进程自己的 /proc/[pid] 目录。
合起来就是,当进程访问 /proc/self/exe 时,可以运行一个对应进程自身的二进制文件。
package main
import (
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(cmd.Run())
}
func child() {
must(syscall.Sethostname([]byte("mycontainer")))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
在 run() 函数中,我们不再是直接运行用户所传递的命令行参数,而是运行 /proc/self/exe ,并传入 child 参数和用户传递的命令行参数。
同样当执行 go run main.go run echo hello 时,会创建出 main 进程, main 进程内执行 /proc/self/exe child echo hello 命令创建出一个新的 exe 进程,关键也就是这个 exe 进程,我们已经为其配置了 CLONE_NEWUTS 系统调用参数进行 UTS 隔离。也就是说,exe 进程可以拥有和 main 进程不同的主机名,彼此互不干扰。
进程访问 /proc/self/exe 代表着运行对应进程自身的二进制文件。因此,按照 exe 进程的启动参数,会执行 child() 函数,而 child() 函数内首先调用 syscall.Sethostname 更改了主机名(此时是 exe 进程执行的,并不会影响到 main 进程), 再次使用 exec.Command 运行用户命令行传递的参数。
总结一下就是,
main进程创建了exe进程(exe进程已经进行 UTS 隔离,exe进程更改主机名不会影响到main进程), 接着exe进程内执行echo hello命令创建出一个新的echo进程,最后随着echo进程的执行完毕,exe进程随之结束,exe进程结束后,main进程再结束并退出。
创建 exe 进程的同时我们传递了 CLONE_NEWUTS 标识符创建了一个 UTS NameSpace ,Go 内部帮我们封装了系统调用函数 clone() 的调用,我们也说过,由 clone() 函数创建出的进程的子进程也将会成为这些 NameSpace 的成员,所以默认情况下(创建新进程时无继续指定系统调用参数),由 exe 进程创建出的 echo 进程会继承 exe 进程的资源, echo 进程将拥有和 exe 进程相同的主机名,并且同样和 main 进程互不干扰。
因此,借助中间商 exe 进程 ,echo 进程可以成功实现和宿主机( main 进程)资源隔离,拥有不同的主机名。
现在再看。
[root@localhost k8s]# go run main.go run /bin/bash
[root@mycontainer k8s]# hostname
mycontainer
[root@mycontainer k8s]# ps
PID TTY TIME CMD
50603 pts/1 00:00:00 go
50621 pts/1 00:00:00 main
50624 pts/1 00:00:00 exe
50627 pts/1 00:00:00 bash
53616 pts/1 00:00:00 ps
61779 pts/1 00:00:00 bash
[root@mycontainer k8s]# exit
exit
[root@localhost k8s]# hostname
localhost.localdomain
完全成功了。
PID隔离
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
fmt.Println("[main]", "pid:", os.Getpid())
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func child() {
fmt.Println("[exe]", "pid:", os.Getpid())
must(syscall.Sethostname([]byte("mycontainer")))
must(os.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
must(syscall.Unmount("proc", 0))
}
func must(err error) {
if err != nil {
panic(err)
}
}
Cloneflags 参数新增了 CLONE_NEWPID 和 CLONE_NEWNS 分别隔离进程 pid 和文件目录挂载点视图,Unshareflags: syscall.CLONE_NEWNS 则是用于禁用挂载传播。
当我们创建 PID Namespace 时,exe 进程包括其创建出来的子进程的 pid 已经和 main 进程隔离了,这一点可以通过打印 os.Getpid() 结果或执行 echo $$ 命令得到验证。但此时还不能使用 ps 命令查看,因为 ps 和 top 等命令会使用 /proc 的内容,所以我们才继续引入了 Mount Namespace ,并在 exe 进程挂载 /proc 目录。
其他的就不一一展示了,我们的目标不是写出Docker,而是理解Docker而已。
我们之前讲解了Namespace,但是Linux Namespace的隔离机制相比于虚拟化技术也有很多不足,其中最主要的问题就是:隔离的不彻底。
既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。如果你的Linux版本不一样,那么隔离仍然是不彻底的。此外,容器的资源也没有隔离,因此我们引出了下一个概念:Cgroups。
Cgroups
主要功能:
- 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- 优先级控制,CPU利用和磁盘IO吞吐。
- 一些审计或一些统计,主要目的是为了计费。
- 挂起进程,恢复执行进程。
在Linux中,Cgroups给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的/sys/fs/cgroup路径下。我们可以用命令把它们展示出来:
[root@master cgroup]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
可以看到在/sys/fs/cgroup下面有很多诸如cpuset,cpu,memory这样的子目录,也叫子系统。这些都是我这台机器当前可用被Cgroups进行限制的资源种类。而在子系统对应的资源种类下,你可用看到该类资源具体可用被限制的方法。比如对CPU子系统来说,我们就可以看到如下几个配置文件,这个指令是:
[root@master cgroup]# ls /sys/fs/cgroup/cpu
cgroup.clone_children cgroup.sane_behavior cpuacct.usage_percpu cpu.rt_period_us cpu.stat notify_on_release tasks
cgroup.event_control cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us cpu_t release_agent user.slice
cgroup.procs cpuacct.usage cpu.cfs_quota_us cpu.shares kubepods.slice system.slice
那么这个配置文件怎么使用呢?
你需要在对应的子系统下面创建一个目录,比如我们现在进入/sys/fs/cgroup/cpu目录下:
[root@master cpu]# mkdir container
[root@master cpu]# cd container/
[root@master container]# ll
total 0
-rw-r--r-- 1 root root 0 Feb 27 16:35 cgroup.clone_children
--w--w--w- 1 root root 0 Feb 27 16:35 cgroup.event_control
-rw-r--r-- 1 root root 0 Feb 27 16:35 cgroup.procs
-r--r--r-- 1 root root 0 Feb 27 16:35 cpuacct.stat
-rw-r--r-- 1 root root 0 Feb 27 16:35 cpuacct.usage
-r--r--r-- 1 root root 0 Feb 27 16:35 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 Feb 27 16:35 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Feb 27 16:35 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Feb 27 16:35 cpu.rt_period_us
-rw-r--r-- 1 root root 0 Feb 27 16:35 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 Feb 27 16:35 cpu.shares
-r--r--r-- 1 root root 0 Feb 27 16:35 cpu.stat
-rw-r--r-- 1 root root 0 Feb 27 16:35 notify_on_release
-rw-r--r-- 1 root root 0 Feb 27 16:35 tasks
这个目录就被成为一个控制组。你会发现,操作系统会在你新创建的container目录下,自动生成该子系统对应的资源限制文件。
现在我们后台执行一条这样的脚本:
[root@node1 container]# while : ; do : ; done &
[1] 58358
它执行了一个死循环,然后PID号是58358。
我们使用top命令查看一下它的CPU使用情况。
[root@node1 container]# top
top - 16:41:14 up 10:26, 2 users, load average: 0.23, 0.07, 0.06
Tasks: 131 total, 2 running, 129 sleeping, 0 stopped, 0 zombie
%Cpu(s): 51.2 us, 0.4 sy, 0.0 ni, 48.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3861296 total, 2650804 free, 648408 used, 562084 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2976548 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
58358 root 20 0 115544 576 168 R 100.0 0.0 0:13.19 bash
可用看到CPU的使用率是100%.
此时我们可以通过查看container目录下的文件,看到container控制组里面CPU quota还没有做任何限制,CPU period则是默认是100ms。
[root@node1 container]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
[root@node1 container]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
cfs_quota和cfs_period两者需要搭配起来使用:可以用来限制进程在长度cfs_period的一段时间内,只能被分配到总理为cfs_quota的CPU时间。
因此我们做一个修改,添加一些限制。
[root@node1 container]# echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
那么我们怎么让这个限制生效呢?
[root@node1 container]# echo 58358 > /sys/fs/cgroup/cpu/container/tasks
我们把这个进程PID写入tasks里面。然后使用top看生效了没有。
[root@node1 container]# top
top - 16:42:35 up 10:28, 2 users, load average: 0.78, 0.30, 0.14
Tasks: 132 total, 2 running, 130 sleeping, 0 stopped, 0 zombie
%Cpu(s): 10.6 us, 0.5 sy, 0.0 ni, 88.8 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 3861296 total, 2651128 free, 648016 used, 562152 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2976908 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
58358 root 20 0 115544 576 168 R 20.0 0.0 1:29.58 bash
可以看到资源确实被成功的限制了。
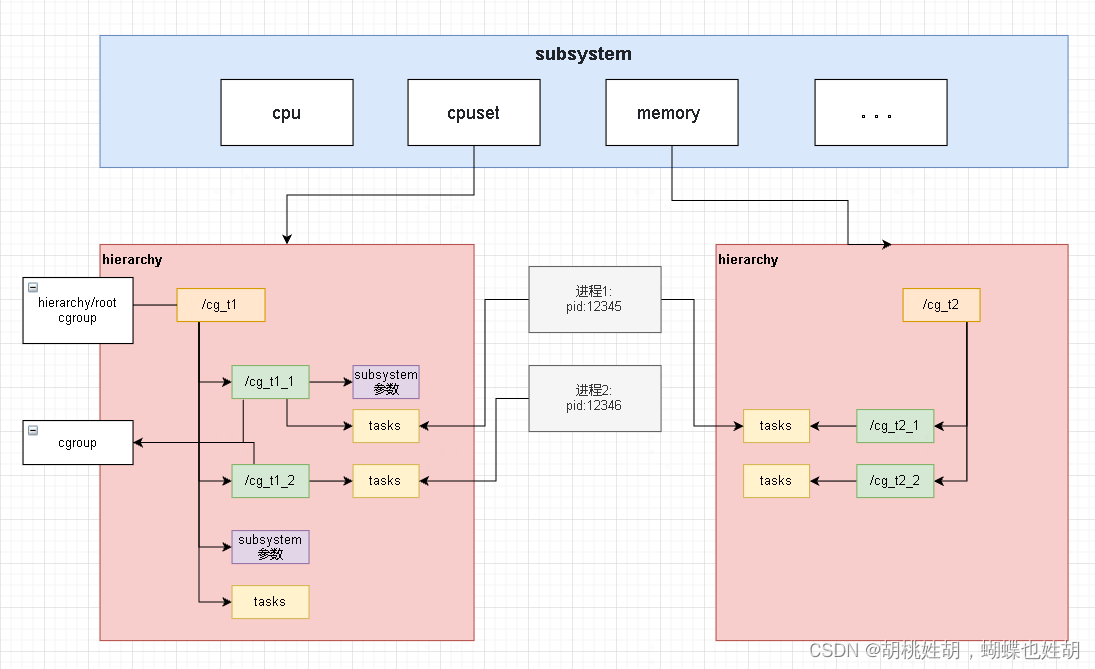
相关概念解析
-
task: 在cgroups中,任务就是系统的一个进程。我们刚才把进程PID加入到task里面去。
-
control group: 控制组,指明了资源的配额限制。进程可以加入到某个控制组,也可以迁移到另一个控制组。
-
hierarchy: 层级结构,控制组有层级结构,子节点的控制组继承父节点控制组的属性(资源配额、限制等)
-
subsystem: 子系统,一个子系统其实就是一种资源的控制器,比如memory子系统可以控制进程内存的使用。子系统需要加入到某个层级,然后该层级的所有控制组,均受到这个子系统的控制。
drwxr-xr-x 5 root root 0 Feb 26 13:28 blkio lrwxrwxrwx 1 root root 11 Feb 26 13:28 cpu -> cpu,cpuacct lrwxrwxrwx 1 root root 11 Feb 26 13:28 cpuacct -> cpu,cpuacct drwxr-xr-x 6 root root 0 Feb 26 13:28 cpu,cpuacct drwxr-xr-x 3 root root 0 Feb 26 13:28 cpuset drwxr-xr-x 5 root root 0 Feb 26 13:28 devices drwxr-xr-x 3 root root 0 Feb 26 13:28 freezer drwxr-xr-x 3 root root 0 Feb 26 13:28 hugetlb drwxr-xr-x 5 root root 0 Feb 26 13:28 memory lrwxrwxrwx 1 root root 16 Feb 26 13:28 net_cls -> net_cls,net_prio drwxr-xr-x 3 root root 0 Feb 26 13:28 net_cls,net_prio lrwxrwxrwx 1 root root 16 Feb 26 13:28 net_prio -> net_cls,net_prio drwxr-xr-x 3 root root 0 Feb 26 13:28 perf_event drwxr-xr-x 5 root root 0 Feb 26 13:28 pids drwxr-xr-x 5 root root 0 Feb 26 13:28 systemd [root@node1 cgroup]# pwd /sys/fs/cgroup这个就是子系统。进入了某一个子进行里面的那些指标就是控制组。
内存限制Go实例
//go:build linux
// +build linux
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
fmt.Println("[main]", "pid:", os.Getpid())
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func child() {
fmt.Println("[exe]", "pid:", os.Getpid())
cg()
must(syscall.Sethostname([]byte("mycontainer")))
must(os.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
must(syscall.Unmount("proc", 0))
}
func cg() {
mycontainer_memory_cgroups := "/sys/fs/cgroup/memory/mycontainer"
os.Mkdir(mycontainer_memory_cgroups, 0755)
must(ioutil.WriteFile(filepath.Join(mycontainer_memory_cgroups, "memory.limit_in_bytes"), []byte("100M"), 0700))
must(ioutil.WriteFile(filepath.Join(mycontainer_memory_cgroups, "notify_on_release"), []byte("1"), 0700))
must(ioutil.WriteFile(filepath.Join(mycontainer_memory_cgroups, "tasks"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func must(err error) {
if err != nil {
panic(err)
}
}
UnionFS
我们使用C语言来编写一个简单的创建容器的程序。
#define _GNU_SOURCE
#include <sys/mount.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("Container - inside the container!\n");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
printf("Parent - start a container!\n");
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWNS | SIGCHLD, NULL);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
这个main程序的功能很简单,就是通过clone()系统调用创建了一个新的子进程container_main,并且声明要为它启动Mount Namespace。
然后我们运行程序。
[root@VM-24-15-centos LDocker]# ./docker
Parent - start a container!
Parent - container stopped!
Container - inside the container!
我们此时就已经进入了一个容器内部了。
然后我们查看一下ls /LDocker里面的内存,我们惊奇的发现,这个跟我宿主机里面的内容不是一样的吗?隔离了一个寂寞!
这是怎么回事儿呢?
Mount Namespace修改的,是容器进程对文件系统挂载点的认知。只有在挂载这个操作发生之后,进程的视图才会被改变。在此之前,新创建的容器都会直接集成宿主机的各个挂载点。
因此我们想到的方法是,在创建新进程的时候,同时告诉容器挂载的点。于是我们修改一下这个代码:
int container_main(void* arg)
{
printf("Container - inside the container!\n");
mount("", "/LDocker", NULL, MS_PRIVATE, "");
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
什么是挂载?
指的就是将设备文件中的顶级目录连接到 Linux 根目录下的某一目录(最好是空目录),访问此目录就等同于访问设备文件。
可以发现代码修改之后,操作是成功的。
这就是Mount Namespace跟其他Namespace的使用策略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作才能生效。
然而用户希望看到的是一个独立的隔离环境,是所有的文件系统都是隔离的,而不是只有一部分,因此我们想到的是挂载整个根目录。
挂载在容器根目录上,用来为容器进程提供隔离后执行环境的文件系统,就是所谓的容器镜像。它还有一个更专业的名字,叫做rootfs(根文件系统)。
但是需要明确的是:
rootfs只是一个操作系统所包含的文件,配置和目录,并不包括操作系统的内核。在Linux操作系统中,这两部分是分开存放的,操作系统只有在开机启动的时候才会加载指定版本的内核镜像。
因此rootfs只包括了操作系统的躯壳,并没有包括操作系统的灵魂。
那么对于容器来说,这个操作系统的灵魂在哪里呢?
实际上,同一台机器上的所有的容器都共享主机操作系统的内核。
有了rootfs(容器镜像之后),容器便解决了一致性问题,那么什么是一致性问题呢?
一致性问题就是:云端和本地服务器环境不同,应用的打包过程不一致。
由于rootfs里面打包的不仅仅是应用,而是整个操作系统的文件和目录,也就意味着应用以及它运行所需要的依赖,都被封装在了一起,这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
但是这个时候出现了一个非常麻烦的问题:难道我每次开发一个应用,或者升级一下现有的应用,都要重复只做一次rootfs吗?
比如,我现在用 Ubuntu 操作系统的 ISO 做了一个 rootfs,然后又在里面安装了 Java 环境,用来部署我的 Java 应用。那么,我的另一个同事在发布他的 Java 应用时,显然希望能够直接使用我安装过 Java 环境的 rootfs,而不是重复这个流程。
一种比较直观的解决办法是,我在制作 rootfs 的时候,每做一步“有意义”的操作,就保存一个 rootfs 出来,这样其他同事就可以按需求去用他需要的 rootfs 了。
但是,这个解决办法并不具备推广性。原因在于,一旦你的同事们修改了这个 rootfs,新旧两个 rootfs 之间就没有任何关系了。这样做的结果就是极度的碎片化。
那么,既然这些修改都基于一个旧的 rootfs,我们能不能以增量的方式去做这些修改呢?
这样做的好处是,所有人都只需要维护相对于 base rootfs 修改的增量内容,而不是每次修改都制造个“fork”。
答案当然是肯定的。
这也正是为何,Docker 公司在实现 Docker 镜像时并没有沿用以前制作 rootfs 的标准流程,而是做了一个小小的创新:
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作(Dockerfile),都会生成一个层,也就是一个增量 rootfs。
当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union FileSystem)的能力。
因此,我们现在绕了一大圈,终于引出了docker原理的最后一个点,联合文件系统。
什么是联合文件系统呢?
[root@VM-24-15-centos union]# tree .
.
|-- A
| |-- a
| `-- x
`-- B
|-- b
`-- x
6 directories, 0 files
[root@VM-24-15-centos union]# mkdir C
[root@VM-24-15-centos union]# mount -t aufs -o dirs=./A:./B none ./C
./C
|-- a
|-- b
`-- x
3 directories, 0 files
联合文件系统在docker中的应用
我们现在来启动一个容器,比如:
docker run -d ubuntu:latest sleep 3600
这个时候Docker会从Docker Hub上面拉取一个Ubuntu镜像到本地。
这个所谓的“镜像”,实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu操作系统的所有文件和目录。不过,与之前我们讲述的 rootfs 稍微不同的是,Docker 镜像使用的 rootfs,往往由多个“层”组成:
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
可以看到,这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的“/C”目录)。
这个挂载点就是 /var/lib/docker/aufs/mnt/,比如:
不出意外的,这个目录里面正是一个完整的 Ubuntu 操作系统:
1 $ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce
2 bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
那么,前面提到的五个镜像层,又是如何被联合挂载成这样一个完整的 Ubuntu 文件系统的呢?
这个信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面
首先,通过查看 AuFS 的挂载信息,我们可以找到这个目录对应的 AuFS 的内部 ID(也叫:si):
1 $ cat /proc/mounts| grep aufs
2 none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba
即,si=972c6d361e6b32ba。
然后使用这个 ID,你就可以在 /sys/fs/aufs 下查看被联合挂载在一起的各个层的信息:
1 $ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]*
2 /var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw
3 /var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh
4 /var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh
5 /var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
6 /var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
7 /var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
8 /var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
从这些信息里,我们可以看到,镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被联合挂载在 /var/lib/docker/aufs/mnt 里面。
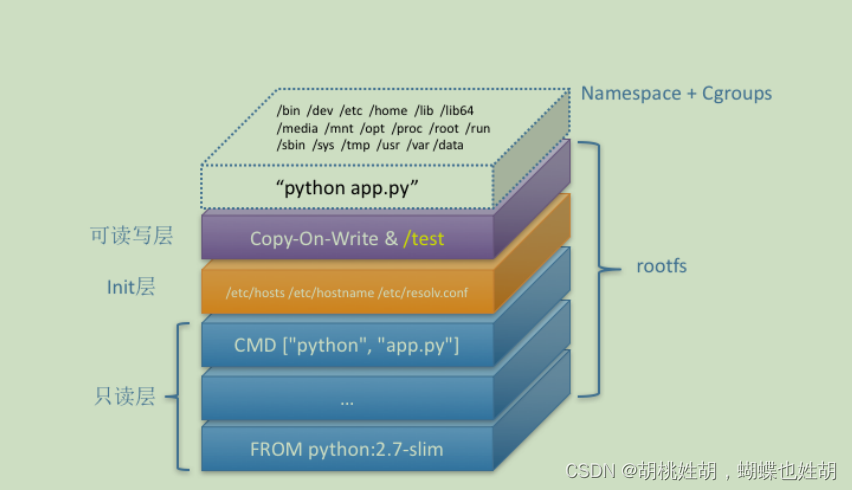
从这个接口可以看出容器的rootfs由如图的三个部分构成:
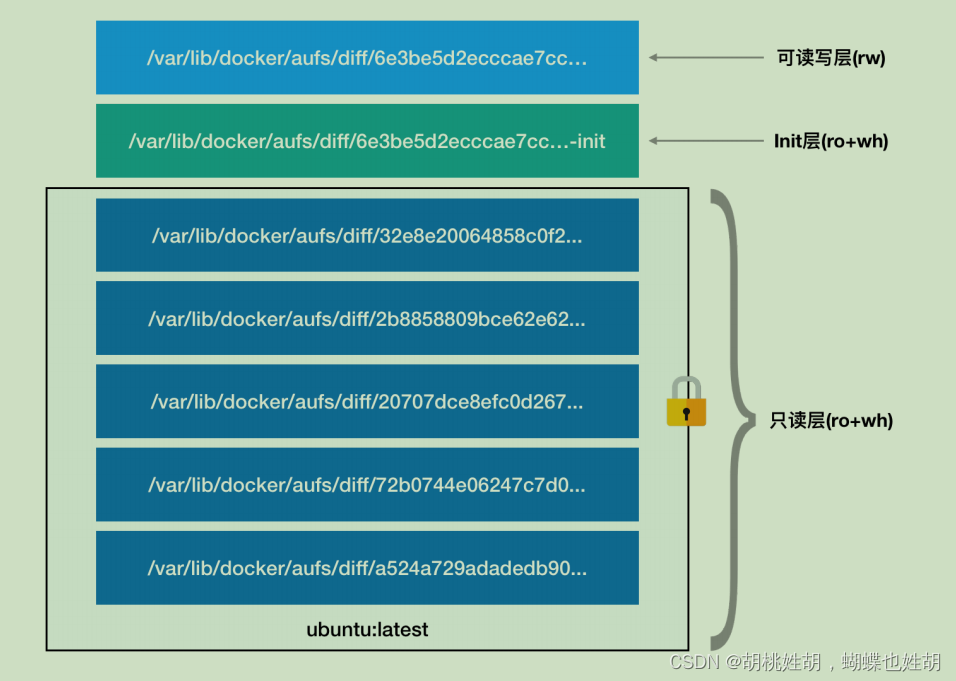
第一部分:只读层
它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout,至于什么是whiteout,我下面马上会讲到)
我们可以看一下:
1 $ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0...
2 etc sbin usr var
3 $ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2...
4 run
5 $ ls /var/lib/docker/aufs/diff/a524a729adadedb900...
6 bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
这些层都是以增量的方式分布包含了Ubuntu操作系统的一部分。
第二部分:可读可写层
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题:如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量rootfs 的好处。
第三部分:Init层
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行docker commit 只会提交可读写层,所以是不包含这些内容的。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的Ubuntu 操作系统供容器使用。
重新认识docker容器
docker exec原理
我们知道docker有一个命令叫做docker exec。在了解了Linux Namespace之后,你应该很自然的会想到一个问题:docker exec是怎么进入到容器内部的?
实际上,Namespace创建的隔离空间虽然看不见摸不着,但是一个进程的Namespace信息在宿主机上是确确实实存在的,并且是以一个文件的方式。
比如,通过如下指令,你可以看到当前正在运行的Docker 容器的进程号(PID)是25686:
1 $ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d
2 25686
这时,你可以通过查看宿主机proc文件,看到这个25686进程的所有Namespace对应的文件。
1 $ ls -l /proc/25686/ns
2 total 0
3 lrwxrwxrwx 1 root root 0 Aug 13 14:05 cgroup -> cgroup:[4026531835]
4 lrwxrwxrwx 1 root root 0 Aug 13 14:05 ipc -> ipc:[4026532278]
5 lrwxrwxrwx 1 root root 0 Aug 13 14:05 mnt -> mnt:[4026532276]
6 lrwxrwxrwx 1 root root 0 Aug 13 14:05 net -> net:[4026532281]
7 lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid -> pid:[4026532279]
8 lrwxrwxrwx 1 root root 0 Aug 13 14:05 pid_for_children -> pid:[4026532279]
9 lrwxrwxrwx 1 root root 0 Aug 13 14:05 user -> user:[4026531837]
10 lrwxrwxrwx 1 root root 0 Aug 13 14:05 uts -> uts:[4026532277]
可以看到,一个进程的每种 Linux Namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
这个操作所依赖的,就是一个叫做setns()的Linux系统调用。
#define _GNU_SOURCE
#include <sys/mount.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE);} while (0)
int main(int argc, char *argv[])
{
int fd;
fd = open(argv[1], O_RDONLY);
if (setns(fd, 0) == -1)
{
errExit("setns");
}
execvp(argv[2], &argv[2]);
errExit(argv[2], &argv[2])
return 0;
}
这段代码功能非常简单:它一共接收两个参数,第一个参数是 argv[1],即当前进程要加入的 Namespace 文件的路径,比如 /proc/25686/ns/net;而第二个参数,则是你要在这个Namespace 里运行的进程,如/bin/bash。
这段代码的的核心操作,则是通过 open() 系统调用打开了指定的 Namespace 文件,并把这个文件的描述符 fd 交给 setns() 使用。在 setns() 执行后,当前进程就加入了这个文件对应的 Linux Namespace 当中了。
docker commit原理
docker commit,实际上就是在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成了一个新的镜像。当然,下面这些只读层在宿主机上是共享的,不会占用额外的空间。
而由于使用了联合文件系统,你在容器里对镜像 rootfs 所做的任何修改,都会被操作系统先复制到这个可读写层,然后再修改。这就是所谓的:Copy-on-Write。
而正如前所说,Init 层的存在,就是为了避免你执行 docker commit 时,把 Docker 自己对 /etc/hosts 等文件做的修改,也一起提交掉。
Volume原理
前面我已经介绍过,容器技术使用了 rootfs 机制和 Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统环境。这时候,我们就需要考虑这样两个问题:
- 容器里面进程新建的文件,怎么让宿主机获取到?
- 宿主机上面的文件和目录,怎么才能让容器里面的进程访问到?
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
我们之前已经说过:当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。
而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保在/var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在/var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了.
更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
注意:这里提到的 " 容器进程 ",是 Docker 创建的一个容器初始化进程(dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
Linux绑定挂载机制原理
我们之前提到了很多次挂载,这个挂载实际上就是Linux的绑定挂载机制。它的主要作用就是允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上,并且这时你在该挂在带你上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
绑定挂载的本质是inode替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。

正如上图所示,mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
这样,进程在容器里对这个 /test 目录进行的所有操作,都实际发生在宿主机的对应目录(比如,/home,或者 /var/lib/docker/volumes/[VOLUME_ID]/_data)里,而不会影响容器镜像的内容。
那么,这个 /test 目录里的内容,既然挂载在容器 rootfs 的可读写层,它会不会被 docker commit 提交掉呢?
不会。
这个原因其实我们前面已经提到过。容器的镜像操作,比如 docker commit,都是发生在宿主机空间的。而由于 Mount Namespace 的隔离作用,宿主机并不知道这个绑定挂载的存在。所以,在宿主机看来,容器中可读写层的 /test 目录(/var/lib/docker/aufs/mnt/[可读写层 ID]/test),始终是空的。
不过,由于 Docker 一开始还是要创建 /test 这个目录作为挂载点,所以执行了 docker commit 之后,你会发现新产生的镜像里,会多出来一个空的 /test 目录。毕竟,新建目录操作,又不是挂载操作,Mount Namespace 对它可起不到“障眼法”的作用。
总结















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











