





摘要:
网络安全问题的传统方法通常在特定类型的攻击发生后保护用户免受攻击。此外,最近的网络攻击模式往往是多变的,这增加了它们的不可预测性。另一方面,机器学习作为一种新的入侵检测方法,正受到越来越多的关注。此外,通过共享本地培训数据,集中式学习方法已被证明可以提高模型的性能。本研究提出了一种分段联邦学习,不同于传统联邦学习模型中基于单个全局模型的协作学习,它保留了多个全局模型,允许每一段参与者单独进行协作学习,并动态地重新安排参与者的分段。此外,这些多个全局模型彼此交互以更新参数,从而适应于各种参与者的局域网。在局域网安全监控项目中,使用了一个涵盖20个参与者局域网两个月流量数据的数据集。我们采用三种基于知识的方法来标记网络事件,并基于数据集训练一个CNN模型。最后,我们用这些方法分别获得了0.923,0.813和0.877的验证准确率。
关键词—局域网,网络安全,机器学习,分段联邦学习,CNN
一、引言
在局域网安全监控项目[1]的前期研究中,设计了一种智能设备并将其连接到局域网中的路由器,从而安全地收集网络流量数据并将其传输到中央服务器。此外,收集的流量数据包括LAN中的广播数据和直接发送到设备的任何通信。然后,中央服务器上的算法根据这些数据检测局域网内的异常行为。总共有50多台设备主要安装在大学实验室和研究所的局域网中。此外,所有数据每天都被打包并传输到中央服务器,这意味着每个数据文件都包括局域网中一天的流量数据。
考虑到传输本地数据的参与者的隐私性和局域网的多样性,本研究提出了一种分段的联邦学习方法,允许参与者共享本地训练模型的参数而不是原始数据,并根据局域网的差异进行自我调整。通过参数共享和结构转换,该方案有望提高大规模网络入侵检测的整体性能。该方案包括两个主要部分:局域网中的入侵检测和分段联邦学习。
首先,为了检测网络中的恶意软件,在本研究中使用了一个由九种类型的协议信息组成的鉴别器,如下:ARP、IP、TCP、UDP、HTTP、HTTPS、mDNS、DHCP和其他。之后,我们使用一种称为希尔伯特曲线的结构,根据每种类型的通信频率,将这些不同类型的信息转换为特征图,代表128秒内定义的网络事件。然后,我们采用三种基于知识的方法来标记这些网络事件,包括检测到监控设备的SYN445、检测到来自频率超过三次的IP的TCP SYN、以及检测到监控设备的UDP单播(监控设备和中央服务器之间的NTP通信的情况和DNS通信的情况除外)
然后,采用由两个卷积层和两个全连接层组成的四层卷积神经网络模型,并基于本地数据集进行训练,以特征图作为输入数据,以基于知识的方法获得的网络事件类型作为标签。此外,我们在该模型中使用了一个名为RMSProp的学习函数和小批量学习。在训练之后,我们应该得到一个模型,通过对网络事件的特征图进行分类来判断网络事件是否是恶意的。
此外,本研究还采用了分段联邦学习方法,以实现参与者之间的参数共享以及自适应各种网络。在这里,每天,模型进行一个学习过程,称为一轮。对于每一轮,选定的参与者将使用本地数据集训练本地模型,这些数据集是根据参与者网络中特定一天的交通数据生成的。此外,对于每六轮,系统将使用最近六轮期间所有参与者的平均准确率的方差对当前全局分支下的每个参与者进行绩效评估,用于决定参与者是否继续留在当前分支。另一方面,如果它显示在特定阈值下的结果,这一个将被转移到另一个分支,该分支伴随着判断被初始化。因此,从下一轮开始,这些参与者将在不同的全局模型下对他们的数据集进行训练。
此外,我们使用与用于分段联合学习的数据集分离的数据集来初始化全局模型,学习速率为0.00001,批量大小为200,训练周期为5。该数据集包括782个良性特征地图和1186个恶意特征图。另一方面,我们在每一轮训练局部模型,学习率为0.00001,批量为50,学习周期为1。然后,对于每一轮,被选择的参与者的模型的参数将被上传到中央服务器。然后,相应的全局模型基于这些参数进行聚合,包括以前的全局模型的参数,以及其他全局模型的参数,每个参数具有不同的比率,以更新全局模型。之后,该全局模型下的所有参与者将下载更新的全局模型来替换他们的本地模型。
为了对该监控系统进行评估,我们使用每种基于知识的标记方法记录了所有入侵检测参与者的准确性,并在全局模型下可视化了当遇到表现相对较差的参与者时系统的分割。
本文的结构如下。第二节讨论了机器学习方法在入侵检测方面的相关工作,以及联邦学习在网络安全问题上的应用。第3节提供了该方案的概述,包括网络事件的表示、CNN的分类以及分段联合学习的参数共享。第4节介绍了该系统的性能评估的基础上的精度,可视化全球模型的分割与各种基于知识的标记方法。第五部分,对论文进行了总结,并对本研究的未来工作进行了展望。
二、相关工作
入侵检测已经成为当今网络安全领域的新趋势。特别是在局域网(LAN)中,被监控的入侵的数量正在增加。解决这个问题的传统方法包括对网络通信应用几个基于知识的规则,一旦满足这些规则,网络事件将被认为是恶意的。此外,一些传统的机器学习方法,如支持向量机(SVM)和神经网络(神经网络)已被用来解决个人计算机和关键基础设施中的网络攻击检测问题[2][3]。然而,由于这些方法在处理大数据和适应各种网络环境方面的局限性,它们在解决复杂的检测问题时表现出了不足。
另一方面,由于近年来深度学习的进步,对网络流量数据的大规模数据分析已经成为可能,并且也表现出很好的性能。例如,Salama等人[4]提出了一种使用深度信念网络(DBN)和SVM的入侵检测混合方案,将入侵分为两类:正常或攻击。他们采用DBN降低特征维数,SVM作为分类器。他们用NSL-KDD数据集[5]评估了他们的方案,最终达到了0.9以上的准确率。此外,在杨等人[6]进行的另一项研究中,他们使用受限玻尔兹曼机()提取交通数据的高级特征表示,并使用随机梯度下降(SGD)训练对其进行分类。Duy等人[7]基于NSL-KDD数据集区分了前馈神经网络(FFNN)在网络入侵检测中的应用。他们的模型在评估中获得了0.962的F1分数。此外,该FFNN模型包括四个60个神经元的隐藏层,使用ReLU的激活函数和0.001的学习率进行训练。此外,Saxe等人[8]提出了一种基于深度神经网络(DNN)的恶意软件检测器,该检测器采用二维二进制程序特征来检测恶意软件。优塞菲-阿扎尔等人[9]给出了一种基于生成特征学习的恶意软件分类方法,其中来自自动编码器(AE)隐藏层的潜在特征被用于异常检测。
此外,如以前的研究,集中学习,其中参与者的本地训练数据被传输到中央服务器进行集中学习,被用于通过机器学习来提高入侵检测的性能[10]。然而,伴随运输进展的几个隐私问题已被放弃。相比之下,联合学习(FL)被提出来访问这些问题,通过允许参与者实现协作学习的目的,而不共享他们的私有本地数据,而是共享本地模型参数。此外,有几项研究侧重于联合学习在网络安全问题上的应用。例如,Abeshu等人[11]提出了一个使用FL的网络攻击检测模型,边缘节点作为参与者。在该模型中,为了提高检测攻击的准确性,每个参与者将其基于本地数据集训练的模型发送到服务器进行参数共享。通过这种方法,他们旨在增强参与者的隐私,并在传输的同时减少网络的流量负载。Nguyen等人[12]提出了一种方法,采用物联网(IoT)网关作为参与者,物联网安全服务提供商作为机器学习模型参数聚合的服务器节点。最后,他们在真实的智能家居部署环境中实现了0.956的入侵检测准确率。
然而,上述研究在各种网络环境下的入侵检测以及稳定和有弹性的学习过程方面存在局限性。与以往的研究不同,我们提出了一种分段的联邦学习,系统结构根据每个参与者的表现自动调整,因此对各种网络具有很强的适应性。同时,不同于采用传统的机器学习方法,我们使用卷积神经网络,这是一种深度学习,用于提取高层特征表示和网络事件分类。因此,该系统应该具有处理网络流量大数据的能力,以及稳定、健壮的协作学习能力。
三、基于分段联邦学习的局域网入侵检测
在本研究中,我们扩展了传统的联邦学习方法,并基于局域网安全监控项目[1]中的20个参与者的数据集将其应用于局域网中的入侵检测。我们允许参与者在本地初始化和训练机器学习模型,而不是将本地交通数据上传到中央服务器。此外,通过上传这些训练模型的参数,中央服务器执行聚合功能以生成全局模型,用于所有参与者之间的智能共享。对于每一轮,只有选定的参与者重新训练他们的本地模型,并且对于每六轮,系统基于本地模型的验证准确性的最近六次记录对每个参与者进行表现评估。表现出相对较差性能的那些被从当前全局模型中移除,并被转移到新的初始化全局模型(图1)。
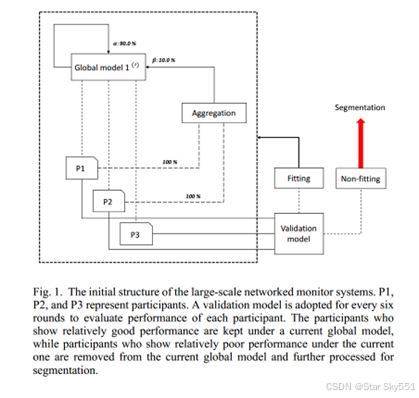
考虑到参与者网络之间的多样性,独立训练的本地模型彼此之间有很大的不同。通过聚合这些局部模型以及其他全局模型的参数,旨在生成对各种网络环境中的入侵检测问题具有弹性和适应性的模型。此外,由于原始流量数据保存在本地,基于联合学习的方法的应用也证明了在大规模网络系统中增强参与者的隐私。
A.实验数据
在本研究中,我们采用了局域网安全监控项目中20个参与者的局域网的实验数据。在这个项目中,一个智能设备(一个节点)连接到局域网中的一个路由器,用于收集网络流量数据。然后,这些数据被打包并传输到中央服务器,以便每天进行异常检测。收集的网络流量数据包括LAN中的所有广播流量和直接发送到设备的任何通信。此外,所有数据都以pcap捕获文件的格式收集,NTP(网络时间协议)用于本项目中节点和中心服务器之间的时钟同步。
对于本研究中的实验数据,我们从局域网安全监控项目的20名参与者中提取了两个月的网络流量数据,从2019年10月1日到11月29日,共60天。因此,对于这些参与者,在本研究中采用了相同时间段的相同数量的交通数据。
B.特征表示
为了表示网络流量数据的特征,我们采用九种协议的通信频率作为鉴别器,包括IP、ARP、TCP、HTTP、HTTPS、UDP、mDNS、DHCP和其他。具体来说,我们使用在0.5秒内每种协议发送或接收了多少个数据包来计算每个记录。此外,总共256条记录用于生成特定协议的一个特征图,并且采用称为精细度的参数来调整我们考虑网络流量数据中隐藏的信息的精细程度。由每个特征图表示的时间段如(1)中所示。通过利用这些参数(精细度和大小),我们将不同记录周期和精细度的交通数据特征带入到相同大小的图像中。在本研究中,我们将协议的通信频率信息放入一个特征图中,周期为128秒。
其中,𝑇是由特征图表示的周期,(时间标准)是每个记录的标准间隔,这里的值为1秒,s是每个协议的生成特征图的大小。在这项研究中,fitness的值为0.5,s的值为16。
此外,我们进一步使用(2)将这些频率信息转换成像素值。然后,我们采用一种称为希尔伯特曲线的结构,将这256条像素值格式的记录投影到宽和高为16像素的特征图中的特定位置,同时考虑到生成的特征图对机器学习模型的适应性。这里,希尔伯特曲线是一种用于转换数据结构的方法,以便它填充图像中的所有空间。
其中,代表对应的像素值,
显示每个协议的通信频率,𝑐代表一幅特征地图中128秒期间该频率的所有记录。结果,c_i / max(c)的值在(0,1)的区间内,
的值在(0,255)的区间内。
此外,我们通过数组交换将上述九种协议的特征映射到上层图像的不同区域,并增加一个区域用于记录其他协议,以一个图像表示局域网中网络流量数据的特征(图2)。因此,认为局域网中网络流量数据的特征可以用一系列与时间相关的特征图来表示,每幅特征图的大小为48 × 48。并且使用来自20个参与者的网络的数据集生成的特征图如下所示(图3)。

C.基于知识的标注
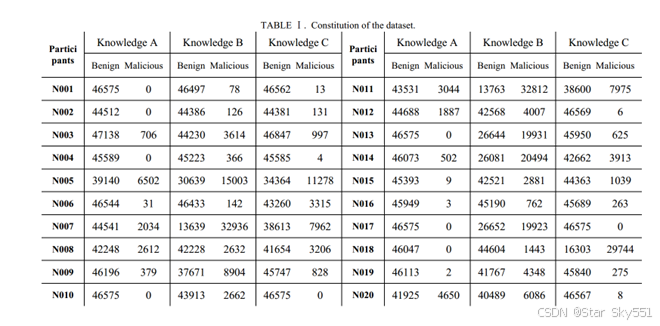
在本研究中,我们采用基于知识的方法来标记这些网络事件的特征图,从而将它们分为良性和恶意两类。在局域网安全监控项目中,我们根据以往对参与者网络流量数据的监控和分析,考虑并选择了三种入侵检测模式。我们采用的标注模式如下:
知识A:检测监控设备的任何SYN445
知识B:来自同一个IP的TCP SYN,频率超过三次
知识C:检测任何到监控设备的UDP单播(除了源端口为123的NTP和源端口为53的DNS的通信)
然后,我们利用这些基于各种模式的标签和生成的网络事件特征图作为本地训练数据集。此外,基于三种标记模式的每个节点数据集的构成如上所示(表1)
D.卷积神经网络分类
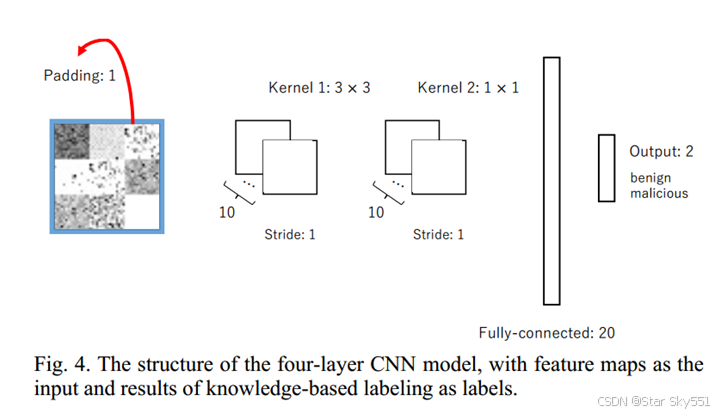
我们采用一个四层CNN模型,由两个卷积层和两个全连接层组成,每个卷积层后面都有一个最大池层,以训练上述本地数据集,其中特征地图用作输入,网络事件标签用作输出(图4)。此外,在这个CNN模型中使用了值为1的填充。对于第一卷积层,采用10个大小为3 × 3的核,步长为1。对于第二卷积层,采用10个大小为1 × 1的核,步长为1。全连接层由200个神经元组成。该模型采用两个神经元组成的输出层来区分良性和恶性。
此外,我们在该模型中采用了一个名为RMSProp均方根传播的学习函数,它在下面的(3) (4)中定义。它具有一个特征,即与过去的梯度信息相比,更强调最新的梯度信息,并且逐渐地过去的梯度信息被遗忘,取而代之的是新的梯度信息被极大地反映。此外,softmax被用作最后一层的激活函数,以获得每个聚类的可能性,从而对特征图(5)的输入进行分类。
其中l是损失,w是节点的权重,𝜌是值为0.9的衰减率。
其中标准指数函数被应用于输入向量x的每个元素x8,从而通过除以所有指数的和来归一化这些值。然后,包括负数、大于1或总和可能不为1的每个分量将位于区间(0,1)中,总和为1。
E.分段联邦学习
分段联合学习模型由两部分组成,中央服务器和参与者。与需要参与者上传本地数据的集中式学习模型不同,在分段式联合学习方案中,参与者在本地进行训练,并与中央服务器共享训练好的本地模型的参数,以达到协作学习的目的。另一方面,采用中央服务器中的聚集器来基于上传的参数以及先前的全局模型获得全局模型。此外,获得的全局模型用于更新参与者的局部模型。
详细地说,首先,中心服务器用预先训练的初始化参数初始化全局模型。然后,所有参与者将初始化的全局模型下载到他们的本地网络。之后,在每一轮中,所有的参与者都在中央服务器下载一个全球模型来替换他们的本地模型。然后,选定的参与者使用算法1中基于滚动的方法,使用当天的数据集执行本地模型的再训练。在所有选择的参与者完成再训练之后,本地模型的这些更新的参数被上传到中央服务器用于汇总。这里,一轮被定义为一天的处理部分,从所有参与者更新他们的本地模型到中央服务器完成聚集。这样,在下一轮,所有参与者用新的处理部分的更新的全局模型替换他们的本地模型。
此外,由于每两轮,所有参与者完成一轮再培训,我们每六轮(三轮再培训)进行一次绩效评估,以达到更精确的结果。以及定义为(6)和(7)的验证模型,用于评估最近六轮中相同全局模型下所有参与者的表现。
计算参与者在最后六轮中的平均准确度。然后,我们计算参与者的这些平均准确率之间的差异,以评估参与者的表现。最后,我们采用Sigmoid函数,从而将评估结果转换为(0,1)区间.
其中n是参与者的数量,代表参与者I在最后六轮中的平均测试准确度,𝑑_i显示了每个参与者的准确度与他们的平均值之间的差异程度,𝑒_i是Sigmoid函数的输出。
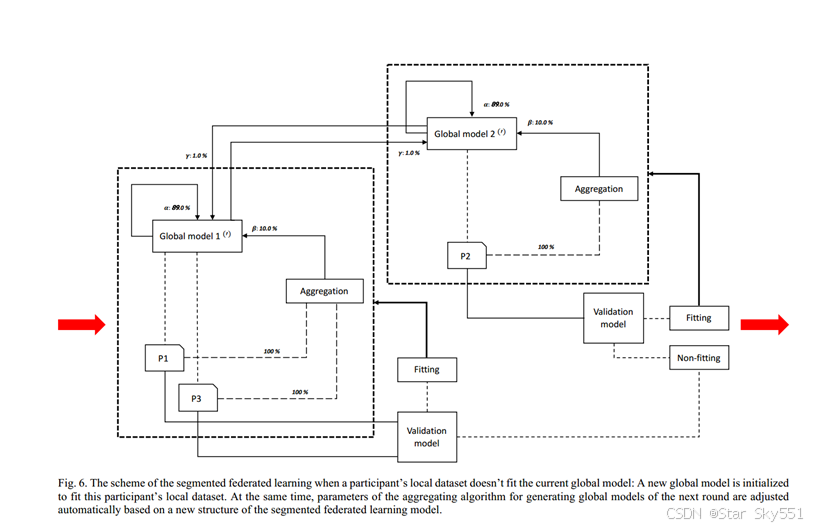
通过这种方法,参与者在当前全局模型下的绩效用(0,1)区间中的值来表示。然后,根据评估结果,我们移除结果低于阈值的这些参与者,阈值被调整为值0.47。用来自这些参与者的局部模型的平均值的参数来初始化新的全局模型。然后,这些参与者被移动到这个新初始化的全局模型,用于下一轮的处理(图6)。此外,考虑到相对较小的阈值导致少数参与者具有被移植到新的全局模型的可能性,而相对较大的阈值导致参与者的过度分割,因此对这里的阈值进行了调整和细化。
此外,对于中央服务器中的聚集,我们采用(8)来计算全局模型的参数,基于各种源的参数,包括先前的全局模型、所选参与者的上传的本地模型和其他全局模型(图6)
其中,“𝑝”表示全局模型的新参数,𝑝",表示以前的全局模型的参数,𝑝$表示进行当前轮训练的参与者的上传参数,𝑞_i表示其他全局模型的参数,n是进行本地训练的参与者的数量,m是其他全局模型的数量。𝛼、𝛽和𝛾代表各组成部分的合计比率,总和为1。这里,考虑到关于各个分量的参数更新的平衡,𝛽是0.1,𝛾是0.01,结果,𝛼具有(0.9-0.01)𝑚).的值分段联邦学习的完整算法被定义为算法1。

四、评价
在本研究中,我们采用200的批量和1的周期来训练局部模型。我们采用了一个由局域网安全监控项目的20个参与者收集的60天流量数据组成的数据集来评估我们的方案。此外,如上所述,以一天的周期进行一轮,因此在本研究中,对于分段联合学习总共进行六十轮。
对于分段联邦学习的性能评估,我们采用定义为(9)的精度来表示每个局部模型对相应的全局模型的适应性。此外,验证的结果都是在每一轮开始时计算的。20个参与者在采用三种基于知识的标注方法时对应的测试准确率如下(图7、图8、图9)。此外,如上所述,这些结果也用于每六轮的分割判断.
其中TP(真阳性)表示由本地CNN模型成功分类的网络事件的特征图的数量,而FN(假阴性)表示未成功分类的特征图的数量。
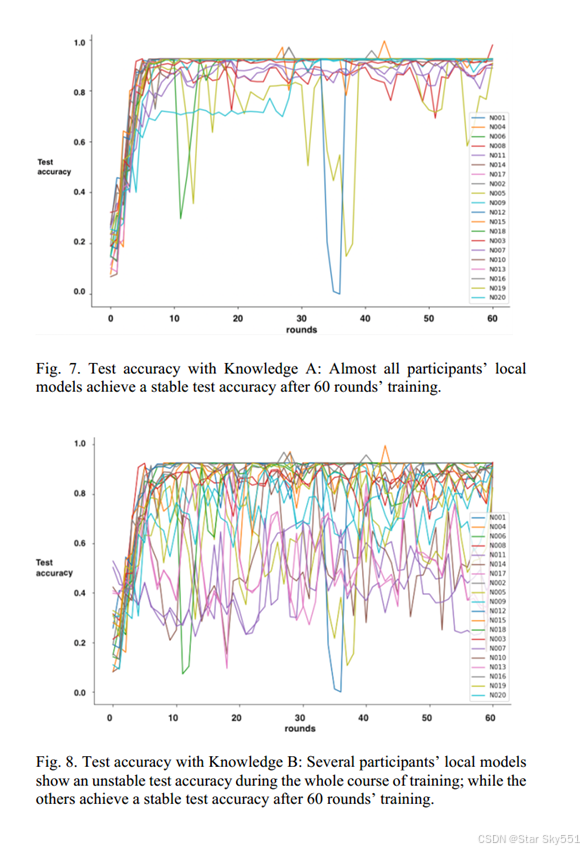

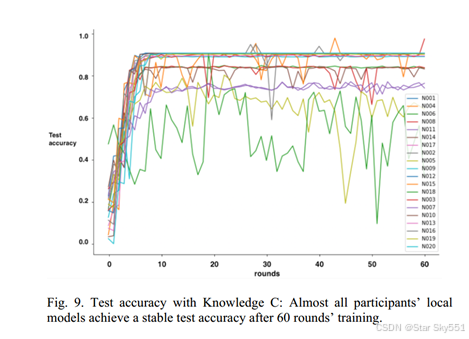
从图表中,我们可以看到大多数参与者在知识A和知识C方面保持了稳定的学习进度,而一些参与者在知识B方面给出了相对较低的准确度,然而20名参与者中的14名参与者达到了超过0.800的准确度。最后,采用三种不同的基于知识的标记方法计算了所有参与者的平均验证准确率,对于入侵检测的结果分别为0.923、0.813和0.877。
此外,我们使用三种类型的标记方法来可视化学习模型的分段过程,并给出分段联合学习方案中参与者的最终分段(图10)。
五、结论
在该研究中,采用分段联邦学习来解决参与者的网络对中心服务器处的全局模型的各种适应性问题以及参与者的本地数据的隐私问题。我们使用LAN security Monitoring局域网安全监控项目的20个参与者的60天流量数据。然后根据九种协议的通信频率生成特征图。此外,三种基于知识的方法被用于标记。
此外,采用四层CNN模型作为局部机器学习模型和全局模型。我们采用学习率为0.00001,训练批量为200,周期为1,总共进行60轮学习。每六轮执行一次性能评估,并根据结果自动调整学习模型的结构。分段联邦学习在局域网入侵检测任务中表现出良好的性能。对于未来的工作,讨论了各种训练参数对学习模型的精度和稳定性的影响,如周期、学习率和批量大小。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









