






链表是一种物理存储单元上非连续、非顺序的存储结构。数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
线性表的顺序存储结构缺点是每一次插入和删除元素,大量元素的移动会导致时间效率低下。为了改进顺序存储结构的缺点,引入链式存储结构,即为链表。
我在这里讲实现链表的两种方法。
1.用指针实现。
2.用数组模拟链表。
一,指针实现链表。
我们先讲用指针来实现链表。
1.创建链表.
我们创建链表需要设置一个个结点,而这些结点由数据域和指针域构成,通过结构体讲之关联起来。
通过指针来实现访问各个结点。
next为指向该结构体的指针
typedef struct node{
int data;//int可以根据你的数据类型,从而变成其他类型。
node *next;//next为指向该结构体的指针。
};2.初始化链表.
这时我们需要生成一个头节点,为该头节点分配内存空间。
&表示引用L,通过使用malloc函数为该结点分配空间,空间大小为该结构体的大小
如果不知道malloc是干嘛的可以看这篇文章:malloc函数用法和意义
分配完空间后,再将头节点置空。
void init(node *&L){
L=(node*)malloc(sizeof(node));
L->next=NULL;
}3.实现链表的各种功能。
1.判断链表是否为空。
我们要判断该链表是否为空,就相当于是判断头节点的下一节点是否存在。
如果该链表为空,则返回true,否则返回false;
代码实现:
bool empty(node *&L){
if(L->next)
return false;
return true;
}2.求链表的长度。
我们要求链表的长度,实现的方法也不难,创建一个自由指针p,从链表的头节点开始计数,直到p指针为空。
代码实现:
int size(node *&L){
node *p;
int sum=0;
p=L;
while(p){
sum++;
p=p->next;
}
return sum;
}3.清空链表。
清空链表的方式也不难,创建两个自由指针,一个来保持循环,一个来释放结点空间。
用q来暂存需要释放的结点,随后用free函数对结点空间进行释放。
切记:
不可以free(p);p=p->next;
代码实现:
void clear(node *L){
node *p;
node *q;
p=L;
while(p){
q=p;
p=p->next;
free(q);
}
L->next=NULL;
}4.在第k个结点后插入数据。
插入数据是链表与顺序表的不同之一,链表可以在指定位置插入或删除结点,时间复杂度为O(1).
我们要实现在指定位置插入数据要做三件事。
1.找到结点插入的位置。
2.将该结点的next指向k的下一个结点。
3.将k的next指向该结点。
如图: 
假设我们想在B和C之间插入一个结点D,我们找到B点,然后先将D点指向C
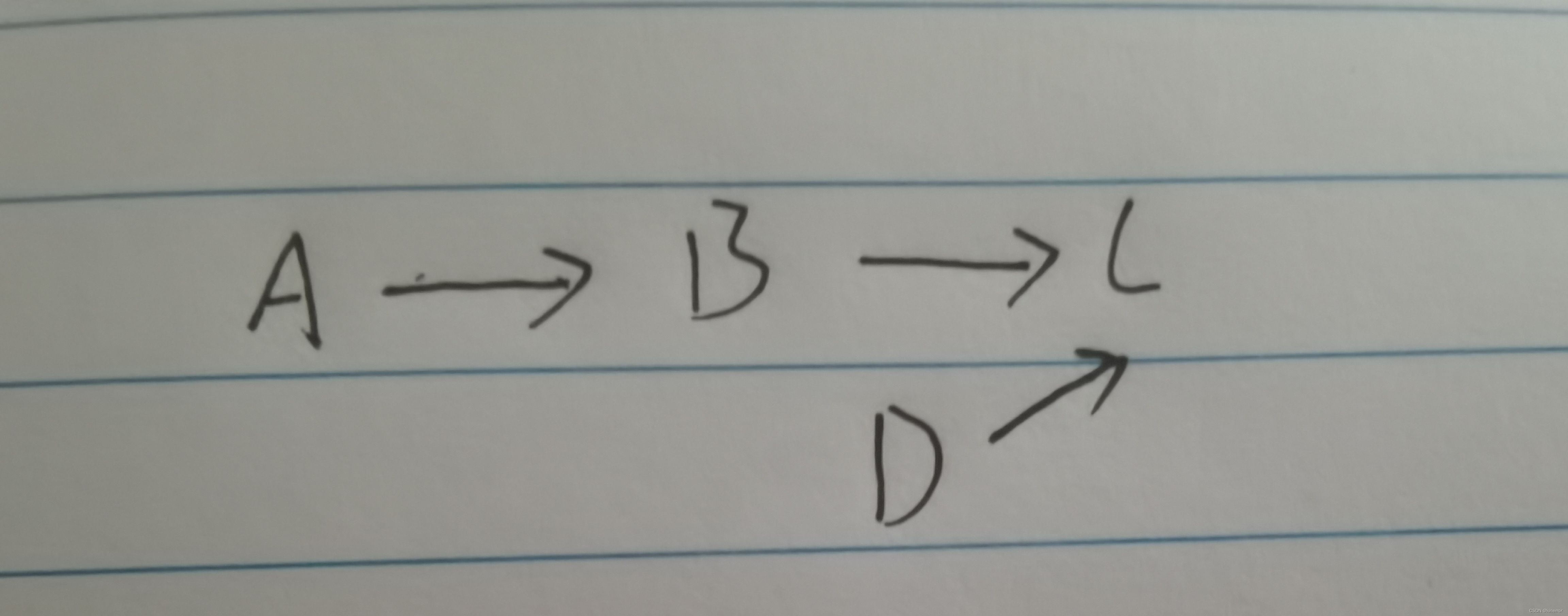
接着把B指向D,即可插入完成。
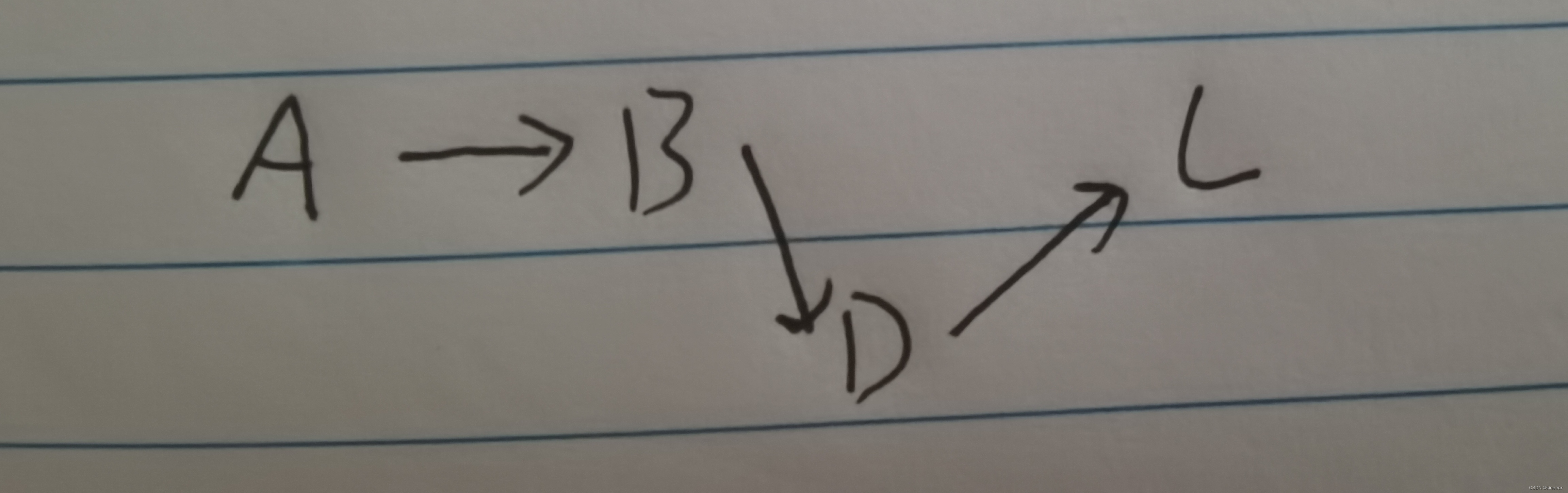

代码实现:
void insert(node *L,int k,int x){
node *p;
p=L;
int sum=0;//用来记录结点id,找到需要插入的节点。
while(sum<k-1&&p!=NULL){//找结点,而且要防止结点为空喔。
sum++;
p=p->next;
}
node *s;
s=(node*)malloc(sizeof(node));//这步用来创建结点。
s->data=m;
s->next=p->next;//将该结点指向k的下一个结点
p->next=s;//k指向该结点
}5.删除第k个结点。
这和插入差不多,就是步骤改成找到结点,再将该结点的上一个结点指向该结点的下一个结点即可。
代码实现:
void delete(node *&L,int n){
node *p;
p=L;
int sum=0;//老样子,表示结点id。
while(sum<n-2&&p->next!=NULL){
sum++;
p=p->next;
}
//ok啊,到这里咱们是已经找到了需要删除的结点的前一位结点了,准备开始删除咯。
node *s;//这里多建一个指针是为了方便释放被删除的结点空间。
q=p->next;
p->next = p->next->next;
free(q);//删除结点空间
}二,通过数组来模拟链表。
通过上文对链表的实现,相信大家肯定会觉得这要实现的方式太复杂,写的代码太长了。
没错,但是对于工程来说,用指针实现链表是必须的,但对于我们比赛啊,做题啊这些根本不需要如此复杂的方式,这种方式不仅代码量大,而且速度慢,所以我们通常采用数组的方式来模拟链表。
具体步骤也分为以下几步。
1.初始化。
我们先来说一下原理吧,我们要通过数组来模拟链表的话同样需要数据域和指针域,要实现这两个我们不妨用两个数组。
用data[id]来存放数据,point[id]来表示指针,我们通过下标来将这两个东西关联起来
头节点初始为-1,这时id为0;
代码实现:
void init(){
head = -1;
id = 0;
}2.从头节点来插入数据。
我们用id来代表该结点,在插入时,我们将令point[id] = head,相当于是该结点指向head所表示的值。
随后令head=id,让head变化,以此实现插入数据。
最后将id++,等待下一个数据。
代码实现:
void add_head(int x){
data[id] = x;
point[id] = head;
head = id;
id++;
}这里我强烈建议画图来理解,非常形象。
3.在第k个结点后插入数据。
实现这个也相当简单,我们画图来说明,首先,我们通过从头插入的方式得到一个链表
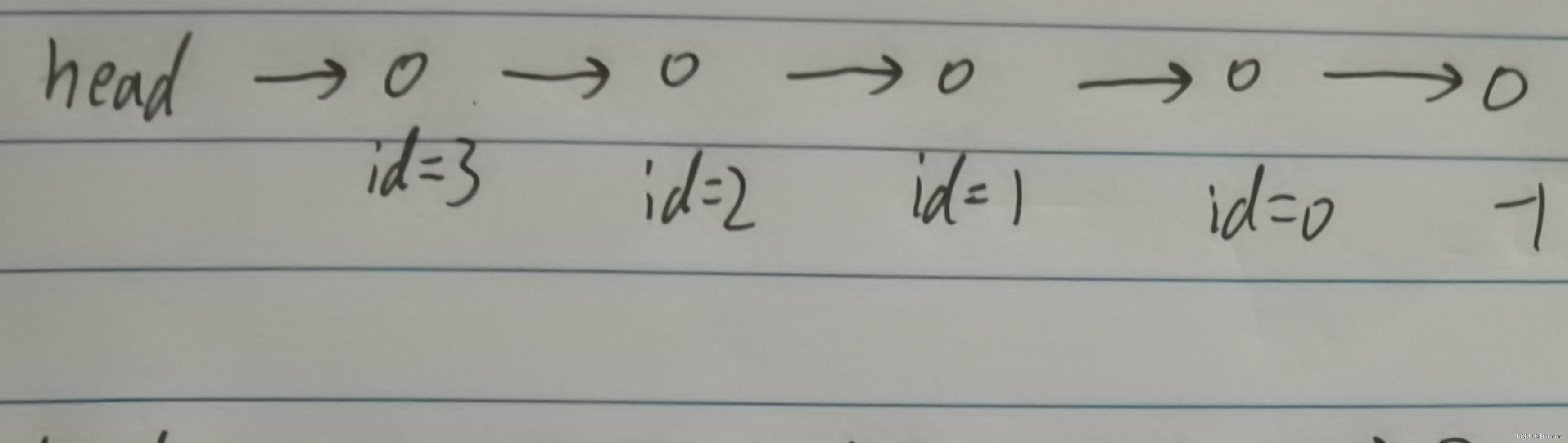
假设我们想要在id为2之后插入一个结点,因为id++,所以目前我们id的值为4,所以我们即将创建的结点的id值为4;
我们画图可知,目前我们的point[2]指向的为id=1;
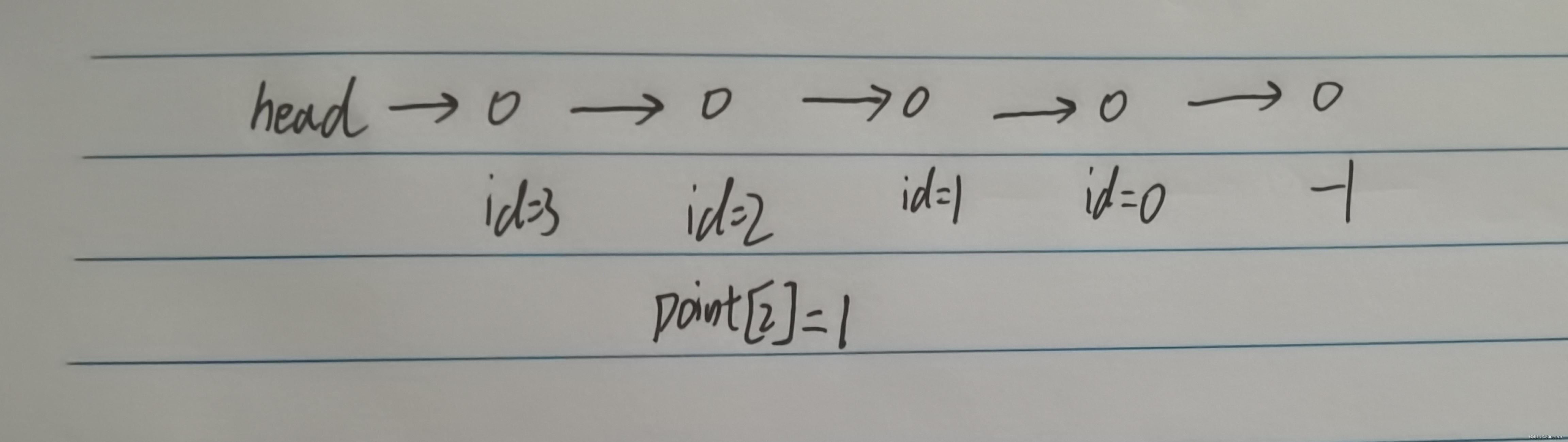
所以我们想要插入结点,就需要将point[4]等于1,即指向id为1的结点,然后再将point[2]=4;
即让id为二的结点指向我们新加的结点的id,最终得到这样的链表。

代码实现:
void insert(int k,int x){
data[k]=x;
point[id]=point[k];
point[k]=id;
id++;
}4.删除id为k结点的后一个结点。
实现这个功能就更简单了,我们只用把k指向的结点的point指向k的下下一个结点。
即point[k]=point[point[k]]
代码实现:
void delete(int k){
point[k]=point[point[k]]
}至此,我们用数组实现链表就到此为止了,对于模拟双链表的实现,题主有空的时候再补充吧















 1803
1803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









