







一、Mybatis
原始jdbc操作的分析:
原始jdbc开发存在的问题如下:
① 数据库连接创建、释放频繁造成系统资源浪费从而影响系统性能
② sql 语句在代码中硬编码,造成代码不易维护,实际应用 sql 变化的可能较大,sql 变动需要改变java代码。
③ 查询操作时,需要手动将结果集中的数据手动封装到实体中。插入操作时,需要手动将实体的数据设置到sql语句的占位
符位置
应对上述问题给出的解决方案:
① 使用数据库连接池初始化连接资源
② 将sql语句抽取到xml配置文件中
③ 使用反射、内省等底层技术,自动将实体与表进行属性与字段的自动映射
1.1、Mybatis框架介绍
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。
iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAOs)
mybatis 是一个优秀的基于java的持久层框架,它内部封装了jdbc,使开发者只需要关注sql语句本身,而不需要花费精力
去处理加载驱动、创建连接、创建statement等繁杂的过程。
mybatis通过xml或注解的方式将要执行的各种 statement配置起来,并通过java对象和statement中sql的动态参数进行
映射生成最终执行的sql语句。
最后mybatis框架执行sql并将结果映射为java对象并返回。采用ORM思想解决了实体和数据库映射的问题,对jdbc 进行了
封装,屏蔽了jdbc api 底层访问细节,使我们不用与jdbc api打交道,就可以完成对数据库的持久化操作。
1.2Mybatis官网介绍
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
总结: MyBatis 是一款优秀的持久层框架,利用ORM思想实现了数据库持久化操作.
补充说明: 也有人把mybatis称之为半自动化的ORM映射框架.
1.3ORM思想
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。如今已有很多免费和付费的ORM产品,而有些程序员更倾向于创建自己的ORM工具。
关系映射:
- 对象映射-------映射表
- 对象中有属性-------表中有字段
总结: 以对象的方式操作数据库.
举例说明:
- JDBC 方式完成入库操作
insert into xxxx(字段名称) values (字段的值…)
select * from xxxxx 结果集需要自己手动封装为对象 (繁琐) - ORM方式实现入库
userDao.insert(对象) - ORM方式的查询
List userList = userDao.selectList(对象);
2.1步骤
POJO说明:
1.必须有get/set方法
2.必须实现序列化接口 数据流传输/socket通讯
注解说明:
@Data 自动生成get/set/toString/equals/hashcode等方法
@Accessors(chain = true) 重写了Set方法
@NoArgsConstructor 无参构造
@AllArgsConstructor 全参构造
3.参数类型都是用包装类型,因为包装类型的默认值为null
项目步骤:
1、创建项目
2.导入jar包文件
<!--mybatis坐标-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.5</version>
</dependency>
<!--mysql驱动坐标-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
<scope>runtime</scope>
</dependency>
3.编辑mybatis-config.xml文件
(1)说明: Mybatis中需要定义核心配置文件, 在配置文件中 需要指定数据库. 相关接口等信息.
(2)configuration标签:环境配置标签, mybatis支持多个数据源的配置,default=“默认连接数据源”
(3)type=“POOLED” 创建一个数据源链接池,每次从池中获取链接.
(4)transactionManager type=“JDBC”:mybatis 采用jdbc的方式控制数据库事务
(5) type=“POOLED”: 创建一个数据源链接池,每次从池中获取链接.
(6) 如果数据源采用5.x的版本 value:com.mysql.jdbc.Driver; 如果数据源采用8.x的版本 value:com.mysql.cj.jdbc.Driver
(7)mappers:-Mybatis加载Mapper映射文件
**4.编辑UserMapper接口
5.编辑Mapper的映射文件**
(1)Mybatis根据接口的规范,需要在自己指定的映射文件中 添加sql语句. 从而时效内数据的操作.
特点: 一个接口对应一个映射文件(xml)
(2)namespace是mybaits映射文件的唯一标识,与接口对应
(3) 标签说明:
1.查询操作: select标签
2.新增操作: insert标签
3.更改操作:update标签
4.删除操作:delete标签
(4) select标签介绍:
- id属性 必须与方法名称一致.
- resultType 返回值的pojo类型
(5)里面的sql语句必须都为大写,防止出错,可以用快捷键全部小写 ctrl + shift + u来调整格式
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--核心配置文件-->
<configuration>
<typeAliases>
<!-- type为POJO对象的路径 alias为当前的pojo对象所起的别名-->
<!--<typeAlias type="com.jt.pojo.User" alias="User"></typeAlias>-->
<package name="com.jt.pojo"/>
</typeAliases>
<!--环境配置标签-->
<!--指定的默认的环境名称-->
<environments default="development">
<!--编辑开发环境-->
<!-- 指定当前环境的名称-->
<environment id="development">
<!-- 指定事务管理类型是JDBC-->
<transactionManager type="JDBC"/>
<!--指定当前数据源类型是连接池-->
<dataSource type="POOLED">
<!--数据源配置的基本参数-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/jt?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--Mybatis加载Mapper映射文件-->
<mappers>
<mapper resource="mybatis/mappers/UserMapper.xml"/>
</mappers>
</configuration>
1. environments标签:
其中,事务管理器(transactionManager)类型有两种:
• JDBC:这个配置就是直接使用了JDBC 的提交和回滚设置,它依赖于从数据源得到的连接来管理事务作用域。
• MANAGED:这个配置几乎没做什么。它从来不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如JEE
应用服务器的上下文)。 默认情况下它会关闭连接,然而一些容器并不希望这样,因此需要将 closeConnection 属性设置
为 false 来阻止它默认的关闭行为。
其中,数据源(dataSource)类型有三种:
• UNPOOLED:这个数据源的实现只是每次被请求时打开和关闭连接。
• POOLED:这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来。
• JNDI:这个数据源的实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置
一个 JNDI 上下文的引用。
2. mapper标签
该标签的作用是加载映射的,加载方式有如下几种:
• 使用相对于类路径的资源引用,例如:
• 使用完全限定资源定位符(URL),例如:
• 使用映射器接口实现类的完全限定类名,例如:
• 将包内的映射器接口实现全部注册为映射器,例如:
3. Properties标签
实际开发中,习惯将数据源的配置信息单独抽取成一个properties文件,该标签可以加载额外配置的properties文件

6.说明: 通过mybatis加载其它的Mapper的映射文件
7.编辑Mybatis测试类
**核心问题:**SqlSession 理解为Mybatis操作数据的连接
(1)定义核心配置文件的路径
String resource= “mybatis/mybatis-config.xml”;
(2)通过工具API读取资源文件
InputStream inputStream = Resources.getResourceAsStream(resource);
Resources导入的包为ibatis
(3)构建SqlSessionFactory
SqlSessionFactory sqlSessionFactory =new SqlSessionFactoryBuilder().build(inputStream);
(4)获取SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
(5)获取Mapper的接口对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
(6)调用接口方法 获取返回值数据
List userList = userMapper.findAll();
System.out.println(userList);
(7)关闭连接
sqlSession.close();
@Test
public void testMybatis01() throws IOException {
//1.定义核心配置文件的路径
String resource = "mybatis/mybatis-config.xml";
//2.通过工具API读取资源文件
InputStream inputStream = Resources.getResourceAsStream(resource);
//3.构建SqlSessionFactory
SqlSessionFactory sqlSessionFactory =
new SqlSessionFactoryBuilder().build(inputStream);
//4.获取SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
//5.获取Mapper的接口对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//6.调用接口方法 获取返回值数据
List<User> userList = userMapper.findAll();
System.out.println(userList);
//7.连接用完记得关闭
sqlSession.close();
}
简化测试操作
@BeforeEach
public void init() throws IOException {
String resource = "mybatis/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
3.1Mybatis CURD操作
1.关于对象参数传递说明: saveUser(User user);
2.mybatis取值语法: #{属性名}
3.insert/update/delete 自动返回影响的行 | select 必须有resultType
4.mybatis在执行"更新"操作时 需要提交事务,否则没有效果
sqlSession.commit();
- 如果有重名属性,一般使用Map集合封装数据
Map map = new HashMap();
map.put("minAge",100);
map.put("maxAge",1000);
- xml文件中个别的字母需要转义:
大于 > > 可以不转义
小于 < <必须转义
与号 & &
转义标签 <![CDATA[ 需要转义的内容 ]]>
<!--select * from demo_user where age > #{minAge}
and age < #{maxAge}
-->
<![CDATA[
select * from demo_user where age > #{minAge}
and age < #{maxAge}
]]>
7.@Param注解说明
(1)规则MApper中的接口方法 不能重名
(2)关于Mybatis参数封装说明
mybatis只支持单值传参
单值可以是具体的数字。字符串。对象
多值转化为单值,首选Map集合
@Param(“minAge”) int minAge 将参数封装为map
解析:Map={minAge=100,maxAge=1000}
List<User> findParam(@Param("minAge") int minAge,
@Param("maxAge") int maxAge);
8.openSession(true)表示:获取SqlSession,之后自动提交事务
SqlSession sqlSession = sqlSessionFactory.openSession(true);
9.模糊查询的%需要加上引号
select * from demo_user where name like "%"#{name}"%"
10.编辑映射文件 接口与映射文件必须一一对应
3.2简化Mybatis配置
1.esultType中的属性每次都需要添加全路径 比较繁琐.可以使用别名进行优化
2.(1)别名设置,在配置文件中Mybatis的核心配置文件有顺序,如果是不记得存放的位置,可以通过测试的办法来编写,位置不对会自动提示
<!-- type为POJO对象的路径 alias为当前的pojo对象所起的别名-->
<typeAlias type="com.jt.pojo.User" alias="User"></typeAlias>
(2)别名包:范围太小,不方便操作就可以使用别名包,包名不变
<package name="com.jt.pojo"/>
1.如果配置了别名包: 则映射时会自动的拼接包路径
<select id="findUser" resultType="User">
3.简化Sql语句
在查询一些字段的时候如果是查询的字段太多了可以通过sql标签来简化sql语句
<!--说明:
include refid="引用SqlID"
refid表示引用的意思
-->
<select id="findUser" resultType="User">
select <include refid="user_cloumn"/> from demo_user
</select>
<!--2.简化Sql-->
<sql id="user_cloumn">
id,name,age,sex
</sql>
4.1Mybatis中集合操作
mybatis的集合操作
说明:如果遇到集合参数传递,需要将集合遍历
标签: foreach 循环遍历集合
标签说明:
标签属性说明:
1.collection 表示遍历的集合类型
(1) 数组 关键字 array
(2) List集合 关键字 list
(3) Map集合 关键字 Map中的key
2. open 循环开始标签
close 循环结束标签 包裹循环体
3. separator 分割符
4. item 当前循环遍历的数据的变量
4.1 array集合操作
编辑测试代码:
UserMapper2 userMapper2 = sqlSession.getMapper(UserMapper2.class);
//将数据封装为数组
int[] ids = {1,2,4,5,7};
List<User> userList = userMapper2.findIn(ids);
System.out.println(userList);
sqlSession.close();
编辑Mapper接口:
List<User> findIn(int[] ids);
编辑Mapper.xml映射文件:
<select id="findIn" resultType="User">
select * from demo_user where id in
<foreach collection="array" open="(" close=")"
separator="," item="id">
#{id}
</foreach>
</select>
4.2List集合操作
- 数组转化时,需要使用包装类型
原因: 基本类型没有get/set方法,包装类型是对象 对象中有方法
测试代码:
Integer[] ids = {1,2,4,5,7};
List list = Arrays.asList(ids);
List<User> userList = userMapper2.findInList(list);
System.out.println(userList);
sqlSession.close();
映射文件:
<select id="findInList" resultType="User">
select * from demo_user where id in
<foreach collection="list" open="(" close=")"
separator="," item="id">
#{id}
</foreach>
</select>
4.3Map集合操作
测试代码:
UserMapper2 userMapper2 = sqlSession.getMapper(UserMapper2.class);
int[] ids = {1,3,5,6,7};
String sex = "男";
/* Map map = new HashMap();
map.put("ids",ids);
map.put("sex",sex);
如此写的话下面传的也需要是一个map集合,
这样写的话对于我们而言不利于了解map里面的数据,所以下面传的参数*/
List<User> userList = userMapper2.findInMap(ids,sex);
System.out.println(userList);
sqlSession.close();
}
编辑Mapper接口:
//多值封装为map集合
List<User> findInMap(@Param("ids") Integer[] ids,
@Param("sex") String sex);
编辑Mapper xml映射文件:
<select id="findInMap" resultType="User">
select * from demo_user where id in (
<foreach collection="ids" item="id" separator=",">
#{id}
</foreach>
)
and sex = #{sex}
</select>
5.动态Sql
Mybatis 的映射文件中,有些时候业务逻辑复杂时,SQL是动态变化的,此时就需要用动态 sql
核心思想: 自动判断是否为null,
如果为null,该字段不参与sql
动态Sql规则:
1.
true: 会拼接 字段条件
false: 不会拼接字段条件
2. 多余的关键字
由于动态sql拼接必然会导致多余的and 或者 or
3. where标签说明 可以去除 where后边多余的and 或者 or
4. set标签用法: 去除set条件中多余的,号
5. choose-when-otherwise 标识都是互斥事件,只有一个有效.
5.1动态 sql-where-if
其中:User对象中的数据可能为null.但是如果sql不做处理,则将会把null当做参数.导致程序查询异常
测试类:
User user = new User(null,"黑熊精",3000, "男");
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper2 userMapper2 = sqlSession.getMapper(UserMapper2.class);
List<User> userList = userMapper2.findSqlWhere(user);
System.out.println(userList);
sqlSession.close();
映射文件:
<select id="findSqlWhere" resultType="User">
select * from demo_user
<where>
<if test="id != null"> id = #{id}</if>
<if test="name != null">and name = #{name}</if>
<if test="age != null ">and age = #{age}</if>
<if test="sex != null ">and sex = #{sex}</if>
</where>
</select>
5.2动态 sql-set-if
根据对象中不为null的数据完成修改操作
测试类:
UserMapper2 userMapper = sqlSession.getMapper(UserMapper2.class);
User user = new User(1,"守山使者",3000, null);
int rows = userMapper.updateSqlSet(user);
System.out.println("影响"+rows+"行");
sqlSession.close();
映射文件:
<update id="updateSqlSet">
update demo_user
<set>
<if test="name !=null"> name=#{name}, </if>
<if test="age !=null"> age = #{age}, </if>
<if test="sex !=null"> sex = #{sex} </if>
</set>
where id = #{id}
</update>
5.3动态 sql-分支结构语法
如果只需要一个条件有效,则使用分支结构用法
如:根据属性查询数据, 如果name有值 按照name查询,否则按照年龄查询,如果name,age都没有 按照sex查询
根据对象中不为null的数据完成修改操作
测试类:
User user = new User(null,null,null,"男");
List<User> userList = userMapper.findChoose(user);
System.out.println(userList);
sqlSession.close();
映射文件:
<select id="findChoose" resultType="User">
select * from demo_user
<where>
<choose>
<when test="name !=null">
name = #{name}
</when>
<when test="age !=null">
age = #{age}
</when>
<otherwise>
sex = #{sex}
</otherwise>
</choose>
</where>
</select>
SQL片段抽取:
Sql 中可将重复的 sql 提取出来,使用时用 include 引用即可,最终达到 sql 重用的目的
6.resultType 和resultMap
resultType:
要求: 对象的属性名称与表中的字段一一对应.
对象: User(id,name,age,sex)
表: demo_user(id,name,age,sex)
总结: resultType适合单表映射,并且属性名称一致.
resultMap:
功能: 如果发现表中的字段与属性名称不一致时,使用resultMap映射
对象: Dog(dogId,dogName)
表: dog(dog_id,dog_name) 属性不匹配.所以映射失败
案例:
<select id="findAll" resultMap="dogRM">
select * from dog
</select>
<!--
id: rm的唯一标识 type:封装之后的POJO对象
-->
<resultMap id="dogRM" type="com.jt.pojo.Dog">
<!--1.标识主键-->
<id column="dog_id" property="dogId"/>
<!--2.映射其它属性-->
<result column="dog_name" property="dogName"/>
</resultMap>
7.关于Mybatis 注解开发说明
1.注解使用规则:
(1)注解标识接口方法. 接口方法调用,直接注解的内容.
(2)注解将查询的结果集,根据方法的返回值类型动态映射.
查询@Select(“sql”)
新增 @Insert(“sql”)
修改 @Update(“sql”)
删除 @Delete(“sql”)
2.修改MyBatis的核心配置文件,我们使用了注解替代的映射文件,所以我们只需要加载使用了注解的Mapper接口即可
<mapper class="com.jt.mapper.UserAnnoMapper"></mapper>
3.关于Mybatis的注解开发说明
(1)注解开发 只适用于 单表CURD操作. 多表操作一定出问题
(2)如果设计到复杂标签时 where/set/foreach 等标签时,不可以使用注解.
(3)所以应该熟练掌握xml映射文件的写法,注解开发只是辅助的作用.
Mybatis的Dao层实现
7.常见表关系
秘诀: 从一头出发,看向另一头. 所在位置不同,得到的结果不同.
1.一对一 例子: 一个老公对应一个老婆 , 一个员工对应一个部门
2.一对多 例子: 一个部门对应多个员工.
3.多对多 例子: 一个学生对应多个老师, 一个老师对应多个学生.
一个角色对应多个权限, 一个权限对应多个角色
多对多,其实就是双向的一对多
4.多对一 实质: 站在一头出发 所以 就是一对一
固定用法:
1.association: 将结果集封装为单独的对象 dept
2.property 需要封装的属性名称
3.javaType 固定写法: 属性的类型
如现在需要完成业务:
一个员工对应一个部门
Mybatis中映射规则: 结果集不允许出现重名字段.
Sql:
/*内连接的另外的一种表现形式.*/
SELECT e.emp_id,e.emp_name,
d.dept_id,d.dept_name
FROM emp e,dept d
WHERE e.dept_id = d.dept_id
7.1Mybatis 一对一封装
测试类:
EmpMapper empMapper = sqlSession.getMapper(EmpMapper.class);
List<Emp> list = empMapper.findAll();
System.out.println(list);
sqlSession.close();
}
映射文件:
<resultMap id="empRM" type="Emp">
<!--1.主键字段 -->
<id property="empId" column="emp_id"></id>
<!--2.映射其它属性字段-->
<result property="empName" column="emp_name"></result>
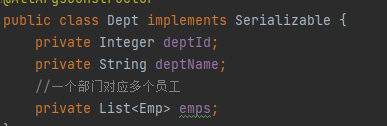
<association property="dept" javaType="Dept">
<!--3.完成dept对象的封装-->
<id property="deptId" column="dept_id"/>
<result property="deptName" column="dept_name"/>
</association>
</resultMap>
7.2 Mybatis一对多
说明: 一个部门有多个员工

SQL:
/*内连接的另外的一种表现形式.*/
SELECT d.dept_id,d.dept_name,e.emp_id,e.emp_name
FROM dept d,emp e
WHERE e.dept_id = d.dept_id
测试类:
DeptMapper deptMapper = sqlSession.getMapper(DeptMapper.class);
List<Dept> list = deptMapper.findAll();
System.out.println(list);
sqlSession.close();
映射文件:
<mapper namespace="com.jt.mapper.DeptMapper">
<select id="findAll" resultMap="deptRM">
select d.dept_id,d.dept_name,e.emp_id,e.emp_name
from dept d,emp e
where e.dept_id = d.dept_id
</select>
<!--Mybatis的映射,一般都是一级封装 -->
<resultMap id="deptRM" type="Dept">
<!--指定主键-->
<id column="dept_id" property="deptId"/>
<!--封装其它的属性字段-->
<result column="dept_name" property="deptName"/>
<!--封装集合 属于同一个部门下的员工,封装到一个集合中 -->
<collection property="emps" ofType="Emp">
<id column="emp_id" property="empId"/>
<result column="emp_name" property="empName"/>
</collection>
</resultMap>
</mapper>
7.3Mybatis的子查询
矛盾点:
- 如果想简化Sql,则映射文件肯定复杂.
- 如果想简化映射文件, 则Sql语句复杂.
案例说明: 需求 简化Sql, 那么映射文件复杂.
子查询本质特点: 将多表关联查询, 转化个多个单表查询.
测试类:
DeptMapper deptMapper = sqlSession.getMapper(DeptMapper.class);
List<Dept> list = deptMapper.selectChildren();
System.out.println(list);
sqlSession.close();
映射文件:
<!--
子查询本质特点: 将多表关联查询, 转化个多个单表查询.
-->
<select id="selectChildren" resultMap="cRM">
select * from dept
</select>
<!--子查询:
1.标签: select 进行二次查询
2.关联字段信息: column="dept_id" 将字段的值作为参数 传递给子查询
-->
<resultMap id="cRM" type="Dept">
<id column="dept_id" property="deptId"/>
<result column="dept_name" property="deptName"/>
<!--数据集合封装-->
<collection property="emps" ofType="Emp" select="findEmp" column="dept_id"></collection>
</resultMap>
<select id="findEmp" resultMap="empRM">
select * from emp where dept_id = #{dept_id}
</select>
<resultMap id="empRM" type="Emp">
<id column="emp_id" property="empId"/>
<result column="emp_name" property="empName"/>
</resultMap>
8.Mybatis-驼峰映射
1.问题说明: 工作中使用驼峰规则的定义的场景比较多的.但是如果每个属性都需要自己手动的封装,则比较繁琐. 所以框架应该提供自动映射的功能.
2.官网描述:

3.驼峰规则映射说明
resultType:
1.适用与单表查询,同时要求属性名称与字段相同.
2.如果属性与字段满足驼峰命名规则,开启驼峰映射之后,
可以使用resultType
resultMap:
1.如果字段不一致时使用
2.多表关联查询时使用.
3.如果开启了驼峰映射规则, 则自动映射的属性可以省略,最好标识主键
4.如果使用驼峰规则映射时,需要映射封装对象时(一对一/一对多),默认条件下.驼峰规则失效.
可以使用: autoMapping=“true” 要求开启驼峰映射.
5.默认条件下 一对一,一对多不会自动完成驼峰规则映射.
需要配置 autoMapping="true"才能自动映射
**在核心配置文件里面设置settings:**
<settings>
<!--开启驼峰映射规则-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
**开启驼峰映射规则:**
<select id="getAll" resultMap="getEmpMap">
select e.emp_id,e.emp_name,
d.dept_id,d.dept_name
from emp e,dept d
where e.dept_id = d.dept_id
</select>
<resultMap id="getEmpMap" type="Emp" autoMapping="true">
<id column="emp_id" property="empId"/>
<!--其它属性自动映射-->
<!--实现部门映射-->
<association property="dept" javaType="Dept" autoMapping="true">
<id column="dept_id" property="deptId"/>
</association>
</resultMap>
9.Mybatis 缓存机制
如果有大量相同的请求查询数据库,则数据库需要执行多次重复的sql,那么并发压力高,查询效率低. 如果引入缓存机制,则可以极大的提升用户的查询的效率

9.2Mybatis 提供缓存机制
1.Mybatis中有2级缓存
2…一级缓存 SqlSession 在同一个sqlSession内部 执行多次查询 缓存有效. 一级缓存默认开启状态.
3.二级缓存 SqlSessionFactory级别. 利用同一个工厂,创建的不同的SqlSession 可以实现数据的共享(缓存机制). 二级缓存默认也是开启的.

9.1一级缓存测试
结论: 利用同一个SqlSession,执行多次数据库操作, 则缓存有效.sql只执行一次.
@Test
public void testCache(){
SqlSession sqlSession = sqlSessionFactory.openSession();
EmpMapper empMapper = sqlSession.getMapper(EmpMapper.class);
List<Emp> list1 = empMapper.getAll();
List<Emp> list2 = empMapper.getAll();
List<Emp> list3 = empMapper.getAll();
sqlSession.close();
}
9.2 二级缓存测试
语法: 在各自的xml 映射文件中 指定缓存标签.

注意事项: sqlSession关闭之后,二级缓存才能生效
//测试二级缓存
@Test
public void testCache2(){
SqlSession sqlSession1 = sqlSessionFactory.openSession();
EmpMapper empMapper = sqlSession1.getMapper(EmpMapper.class);
List<Emp> list1 = empMapper.getAll();
sqlSession1.close(); //sqlSession使用之后必须关闭.否则二级缓存不生效.
//利用同一个SqlSessionFactory 创建不同的SqlSession
SqlSession sqlSession2 = sqlSessionFactory.openSession();
EmpMapper empMapper2 = sqlSession2.getMapper(EmpMapper.class);
List<Emp> list2 = empMapper2.getAll();
sqlSession2.close();
}
注意事项
如果需要使用一级/二级缓存,则POJO对象必须实现序列化接口. 否则数据不可以被缓存.
图解序列化规则:

二、Mybatis-Plus
1.1 MP介绍
MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
说明: 使用MP将不会影响mybatis的使用.
1.2 MP特性无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
1.3 Mybatis 特点
1.Mybaits 是一个半自动化的ORM映射框架
(1)结果集可以实现自动化的映射. 自动
(2)Sql语句需要自己手动完成. 手动
2.如果设计到单表的操作,如果每次都手写,则特别的啰嗦. 所以想办法优化.
1.4 MP入门案例
1.4.1 导入jar包
说明: MP内部添加了mybatis的包,所以添加MP的包之后,应该删除原来的mybatis的包.
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
1.4.2 编辑POJO对象
@Data
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@TableName("demo_user")
//对象与表一一对应 如果对象名和表名一致则表名可以省略
public class User implements Serializable {
@TableId(type = IdType.AUTO) //主键自增
private Integer id;
//@TableField(value = "name") //如果名称与属性一致则注解可以省略
private String name;
private Integer age;
private String sex;
}
1.4.3 继承BaseMapper
//注意事项: 继承时必须添加泛型
public interface UserMapper extends BaseMapper<User> {
List<User> findAll();
}
1.4.4 修改YML配置文件

1.4.5 MP入门案例测试
/**
* MP新增操作测试
* 思想: 全自动的ORM 映射是自动的, sql自动生成的
*/
@Test
public void insertUser(){
User user = new User(null,"猴子",18, "男");
userMapper.insert(user);
System.out.println("新增入库成功!!!!");
}
1.5 MP工作原理
实质: MP动态生成Sql语句.
铺垫:
1. insert into 表名(字段名…) value (属性值…)
工作原理:
- 用户执行userMapper.insert(user); 操作
- 根据UserMapper的接口找到父级BaseMapper.根据BaseMapper的接口查找泛型对象User.
- 根据User.class 获取注解@TableName(“demo_user”),获取表名
- 根据User.class 获取所有的属性,根据属性获取指定的注解@TableField(value = “name”),获取字段名称
- 根据属性获取属性的值.之后动态拼接成Sql语句
- 将生成的Sql交给Mybatis执行入库操作.
1. insert into demo_user(id,name,age,sex) value (null,xx,xx,xx)
MP使用特点: 根据其中不为null的属性进行业务操作!!!
1.6 MP案例练习
@SpringBootTest //Spring专门为测试准备的注解 启动了Spring容器
class JtApplicationTests {
@Autowired
private UserMapper userMapper;
@Test
void findAll() {
List<User> userList = userMapper.findAll();
System.out.println(userList);
}
/**
* MP新增操作测试
* 思想: 全自动的ORM 映射是自动的, sql自动生成的
*/
@Test
public void insertUser(){
User user = new User(null,"猴子",18, "男");
userMapper.insert(user);
System.out.println("新增入库成功!!!!");
}
/*
* 关于MP编码的思想:
* 根据其中不为null的属性进行业务操作!!!!
*/
//1.根据Id查询用户 id=1的用户
@Test
public void testFindById(){
User user = userMapper.selectById(1);
System.out.println(user);
}
//1.查询name="黑熊精"的数据
//QueryWrapper条件构造器 动态拼接where条件的
//select * from demo_user where name=#{xxx}
@Test
public void testFindByName(){
User user = new User();
user.setName("黑熊精");
QueryWrapper queryWrapper = new QueryWrapper(user);
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);
}
//1.查询age > 18岁的用户 age=18!!!!
// > gt, < lt, = eq, >= ge, <= le, <> ne
@Test
public void testFindByAge(){
QueryWrapper queryWrapper = new QueryWrapper();
queryWrapper.gt("age",18);
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);
}
//1.查询age > 18岁的并且 name 包含"乔"的用户
//select * from demo_user where age > 18 and name like "%乔%"
//select * from demo_user where age > 18 and name like "%乔"
//条件构造器如果多个条件时,默认使用and
//链式加载得指定对象
@Test
public void testFindByLike(){
QueryWrapper<User> queryWrapper = new QueryWrapper();
queryWrapper.gt("age",18)
.likeLeft("name","乔");
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);
}
/**
* 查询id=1,3,4,6,7的数据,并且根据年龄降序排列
* Sql: select * from demo_user where id in (1,3,4,6,7)
* order by age desc
*/
@Test
public void testFindByOrder(){
Integer[] ids = {1,3,4,6,7};
QueryWrapper<User> queryWrapper = new QueryWrapper();
queryWrapper.in("id",ids)
.orderByDesc("age", "sex");
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);
}
/**
* 动态sql的查询
* 根据name/sex查询数据. 但是name/sex可能为null
* Sql: select * from demo_user where name=xxx and sex=xxx
* 关于condition的说明:
* condition=true 负责拼接条件
* condition=false 不拼接条件
* StringUtils导入得包为Springframework
*/
@Test
public void testFindByIf(){
String name = null;
String sex = "女";
QueryWrapper<User> queryWrapper = new QueryWrapper();
//判断字符串是否为null
boolean nameFlag = StringUtils.hasLength(name);
boolean sexFlag = StringUtils.hasLength(sex);
//动态Sql的写法
queryWrapper.eq(nameFlag,"name",name)
.eq(sexFlag,"sex",sex);
List<User> userList = userMapper.selectList(queryWrapper);
System.out.println(userList);
}
/**
* 需求: 动态查询主键字段(第一列数据) 适用范围 进行关联查询时使用.
* Sql: select id from demo_user
* 设计: 关联查询 修改为 多张单表查询
*/
@Test
public void testFindByObjs(){
List<Object> idList = userMapper.selectObjs(null);
System.out.println(idList);
}
/**
* MP更新操作
* 说明: 将id=354 的名称改为"六耳猕猴"
*/
@Test
public void updateUserById(){
User user = new User(354,"六耳猕猴",null,null);
int rows = userMapper.updateById(user);
System.out.println("响应了"+ rows +"行");
}
/**
* MP更新操作
* 说明: 将名称为"猴子"的数据改为"齐天大圣"
* 用法:
* 1. 参数1, 将修改的数据封装.
* 2. 参数2, 将修改的条件封装
* Sql: update demo_user set name="齐天大圣" where name="猴子"
*/
@Test
public void updateUserByName(){
//1.利用pojo对象封装修改数据
User user = new User(null,"齐天大圣",null,null);
//1.利用UpdateWrapper封装where条件
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name","猴子");
userMapper.update(user,updateWrapper);
System.out.println("修改操作成功!!!");
}
}
未归类的笔记:
1、在远程仓库了里面,并不是所有的jar包都有,有的只是开源的,像oracle驱动就因为可能版本问题而没有,但本地仓库里面有就行了
2、在打包类型中,pom知识一个标识符,并不能打包
3、jar包在运行软件以外运行的话需要环境,比如目录下的jar包文件要运行就通过cmd的java命令来运行
4、dependencyManagement是用于管理jar包的版本号,
所以在denpendency当中就不需要再次指定jar包的版本号了
比如是springcloud就不用指定jar班版本了,而另外像其他的第三方的jar包文件就需要指定jar包的版本
5、RestController是有两个功能且@Controller和@ResponseBody的结合体
@Controller: 把当前的类交给spring容器管理
@ResponseBody:前后端交互时,将后端服务器返回的对象转化为JSON
前后端交互媒介 http协议 传输的数据都是字符串
// JSON: 有特殊格式的字符串
6、在请求路径中,写绝对路径更加容易,更加直观,
绝对路径
相对路径,背后的springMvc在解析代码路径的时候,会自己拼一个
7、JDBC
功能和作用: java中操作数据库中最为直接的方式。
表述: JDBC开发效率高? 开发效率低
JDBC运行效率高? 操作数据库最快的就是JDBC
8、前端
核心知识:
1.html
2.javascript JS 学一学
3.CSS 美化
4、Ajax
前端的内容属于静态页面。
动态页面: JSP html + java代码 tomcat负责解析。
9、框架说明
SpringBoot 核心是Spring,简化框架的开发
理解:SpringBoot是框架的框架
SpringMVC 理念: 主要负责实现前后端交互.
媒介: http(不安全)/https(安全) 秘钥:证书(公钥私钥) 协议
TCP/IP协议 (3次握手规则) 速度是很快的
常用工具: Ajax
Spring框架
主要作用: 主要整合第三方框架,使得程序可以以一种统一的方式进行管理.
概念:
1. 控制反转/依赖注入 IOC/DI
2. 面向切面编程 AOP(1-2年)
10、 Maven介绍
Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件。
Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于 Maven 的缺省构建规则有较高的可重用性,所以常常用两三行 Maven 构建脚本就可以构建简单的项目。由于 Maven 的面向项目的方法,许多 Apache Jakarta 项目发文时使用 Maven,而且公司项目采用 Maven 的比例在持续增长。
11、 maven坐标作用
maven的坐标主要标识项目,并且标识 唯一标识.
maven项目操作时,与本地仓库一一对应.
12、maven 命令
clean 清空项目中的target文件目录的. xxx.class文件信息
install 将项目打包处理
每次打包 会在2个位置生成jar包文件.
位置1: target文件目录中.
位置2: 根据坐标,在本地仓库中生成具体的jar包文件,该文件可以被其它项目依赖.
14、打包类型
jar包文件 springboot项目/工具API项目/框架的项目
war包文件 动态web项目 JSP类型 tomcat服务器.
pom类型(标识符) POM类型表示聚合工程 微服务架构设计一般采用pom类型.
15、说明: 根据坐标可以在本地仓库的指定位置 查找到jar包文件
作用: 可以被其它项目依赖
16、maven jar包依赖的传递性
案例说明1: 用户只需要引入特定的jar包文件,则maven可以通过依赖的传递性,实现其它jar包文件的引入.
数据结构说明:
A.jar 依赖 B.jar, B.jar 依赖 C.jar 如果只导入A.jar 则自动依赖B/C
17、Jar传递性的实现原理
实现原理:
1. 当maven扫描依赖信息时,会根据坐标找到对应的jar包文件.
2. 之后扫描当前目录下的xxx.pom文件
3. 根据pom文件中的依赖项dependency 再次查找其它的依赖jar包,直到所有jar包依赖完成为止.
18、 jar包传递安全性问题(扩展知识)
问题: jar包文件都是通过网络下载而来的,如何保证文件不被篡改???
3.1.5.3 sha1算法介绍
SHA-1(英语:Secure Hash Algorithm 1,中文名:安全散列算法1)是一种密码散列函数,美国国家安全局设计,并由美国国家标准技术研究所(NIST)发布为联邦数据处理标准(FIPS)。SHA-1可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常的呈现形式为40个十六进制数。
3.1.5.4 关于hash基本常识
如果数据相同,相同的hash算法 问 hash值是否相同?? 必定相同!!!
如果数据不同,相同的hash算法 问hash值是否相同?? 可能相同!!!
(hash碰撞)
常见hash 一般 8位16进制数组成
3.1.5.5 工作原理
说明: 对原始数据进行hash计算 得到摘要信息, 获得数据时 采用hash计算 比较2个的摘要信息,如果相同则数据相同,如果不同则数据必然被篡改.
19、关于Springboot版本管理说明
说明: spring-boot-dependencies 是SpringBoot官网进行调试之后,将所有的关联的jar包进行了定义.从根本上解决了jar包版本冲突的问题.
说明2: 如果需要引入其它的jar包文件,只需要添加jar包名称即可.
说明3: 特殊的jar包文件 需要手动添加版本号
20、说明: 当springboot项目需要打包时,springBoot中的build标签会起作用,将springBoot按照可以执行的方式打成jar包文件.
21、properties语法说明
语法说明:
1. 数据结构 key=value
2. value中前后不要有空格
3. properties文件 程序默认读取采用ISO-8859-1编码结构 中文必定乱码.
4. pro文件中key的名称不能复用.
22、
23、YML语法说明
语法说明:
1. 数据结构 key:(空格)value
2. key的关键字有层级缩进效果, 注意缩进.
3. YML文件默认采用UTF-8编码格式 所以对中文友好.
4. value中不要有多余的空格
5. YML文件中key的前缀可以复用. 注意层级
3.5 动态为属性赋值
24、springboot项目 默认配置文件的名称 application.properties 名称一般固定,不会随意更改.
25、问题: YML文件是Spring的核心配置文件. 主要的目的是为了整合第三方框架而使用的. 如果将
大量的业务数据写到YML文件中,则会导致代码结构混乱.
解决方案: 可以使用pro文件实现业务数据处理.
26、关于IOC的说明
IOC: 控制反转
具体含义: 将对象创建的权利交给Spring容器管理.
原因: 如果将对象自己管理,则必然出现耦合性高的现象. 不方便扩展
容器: 是一种数据结构类型 Map<K,V>集合
KEY: 类名首字母小写
Value: Spring为当前的类创建的对象.
只要程序启动成功,则Map集合中(容器),里边包含了所有的IOC管理的对象
27、测试方法有固定的位置,需要在测试包下面写,同包及子bao,
如果写在主包(java)下的话@Test注解可能不给写
28、使用高版本的驱动时需要添加CJ
29、mybatis的前身是ibatis
30、引入插件lombok 自动的set/get/构造方法插件
31、POJO写法说明:
1.必须有get/set方法
2.必须实现序列化接口 数据流传输/socket通讯
32、 表示: 表示将User对象交给Spring容器管理
类似于: new User();
问题: 如果直接new User(), 其中的属性都为null.
需求: 准备User对象 id=100,name=“tomcat” age=18 sex=“男” 交给Spring容器管理!!!
注意事项: 在进行测试时 将@Component删除
33、要求: 必须有返回值.
功能: 被@Bean修饰的方法,将方法名当做key–user,将返回值对象当做值value
根据Key-value 存储到Map集合中 交给Spring容器管理
Map<user,User对象>
@return
34、需求: 有时在执行测试方法时,必须编辑大量的Controller等代码,虽然可以测试成功,但是显得繁琐.
核心机制: 让Spring容器启动并且为对象提供服务.
35、@SpringBootTest用法说明:
只要在该类中 执行@Test测试方法,则就会启动Spring容器.
36、测试方法要求:
1.不能有返回值 必须为void
2.不能携带参数
3.测试方法名称 不能叫test
37、在虚拟机里面lombok用法,在虚拟机里面不用安装lombok插件,在编译期,会自动将方法都写好(get,set方法),所以在先上部署的时候这些东西都有,所以不需要加插件
38、@ReestController和@Component注解的区别:
都是把对象交给容器管理
本质区别:提供注解的来源不一样,与web进行交互的时候行该用@RestController,
在除了web以外的用@Component注解(万能的注解)
39、mybatis中在操作多个字段的时候要记得把字段加上 表名(字段1,字段2…)
如果不加的话就是有由程序来自动查找这些字段,效率比较低,
数据量少的时候差距不大,数据量高的时候差距比较大
40、其他步骤都是对的,但是返回没有结果集,那可能是接受结果集的参数或者方法,或者需要打印的地方写错 了
41、
42、
43、
44、
45、
46、
47、
48、
49、
50、















 7893
7893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









