






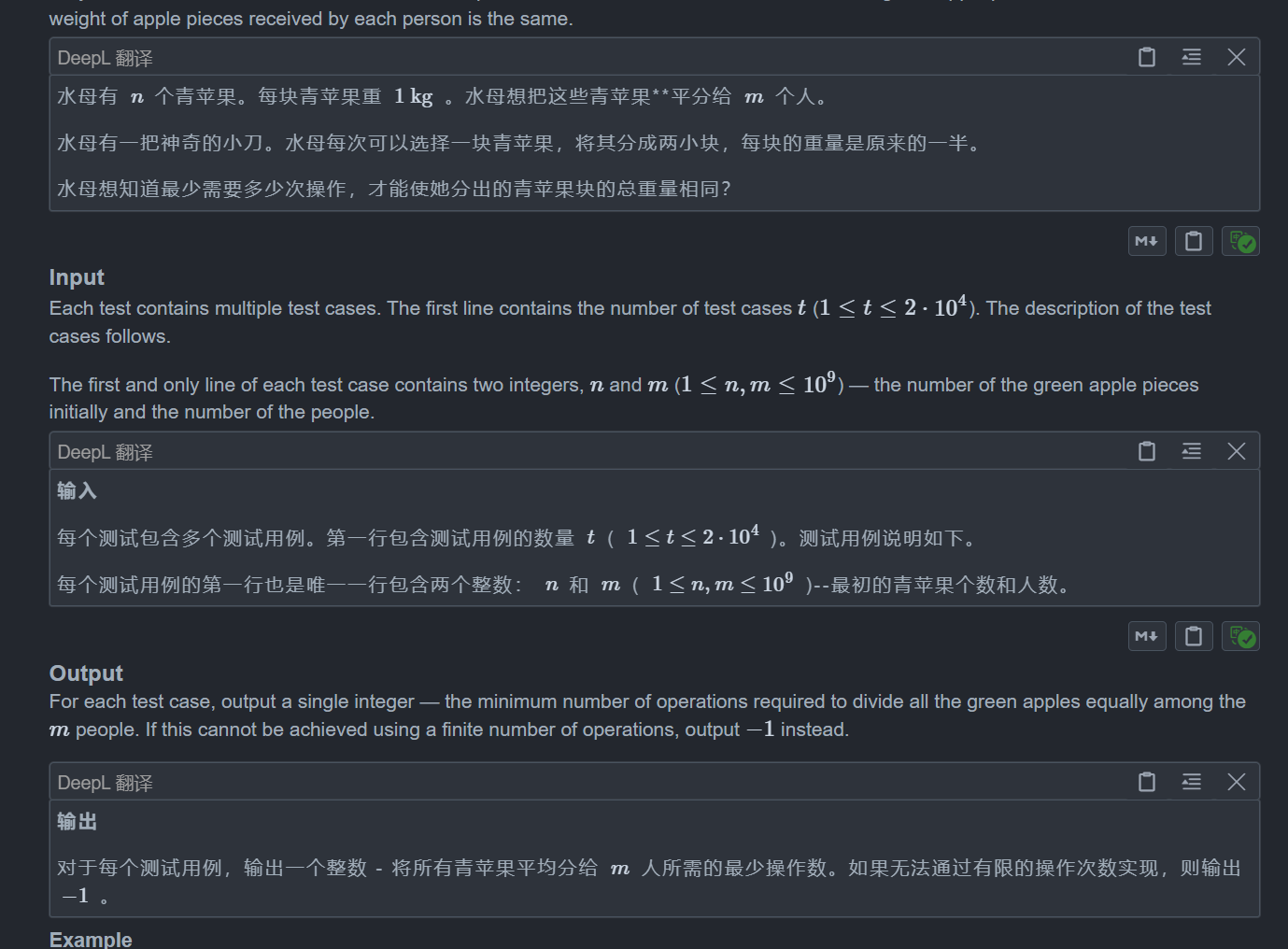
C. Jellyfish and Green Apple
题目:
思路:
思维题,但还考了一下代码实现能力
一个显然的最优方法就是每次将 n %= m,然后对剩下的 n 进行操作
那么直接模拟即可,但是如何判断无解呢?
我们发现,每次操作都是对 n 乘上 2,也就是说最后肯定是乘了 2 的 k 次幂
那么一个想法就是我们可以先将 m 除去 gcd(n,m) 如果这个数 不是 2 的 k 次幂,说明肯定无法达到,否则直接模拟即可
代码:
#include <iostream>
#include <algorithm>
#include<cstring>
#include<cctype>
#include<string>
#include <set>
#include <vector>
#include <cmath>
#include <queue>
#include <unordered_set>
#include <map>
#include <unordered_map>
#include <stack>
#include <memory>
using namespace std;
#define int long long
#define yes cout << "YES\n"
#define no cout << "NO\n"
int gcd(int a,int b)
{
return !b ? a : gcd(b, a % b);
}
void solve()
{
int n, m;
cin >> n >> m;
int g = gcd(n, m);
int mt = m / g;
if (mt & (mt - 1))
{
cout << "-1\n";
return;
}
int res = 0;
n %= m;
while (n % m)
{
n %= m;
res += n;
n *= 2;
}
cout << res << endl;
}
signed main()
{
cin.tie(0)->sync_with_stdio(false);
int t = 1;
cin >> t;
while (t--)
{
solve();
}
return 0;
}
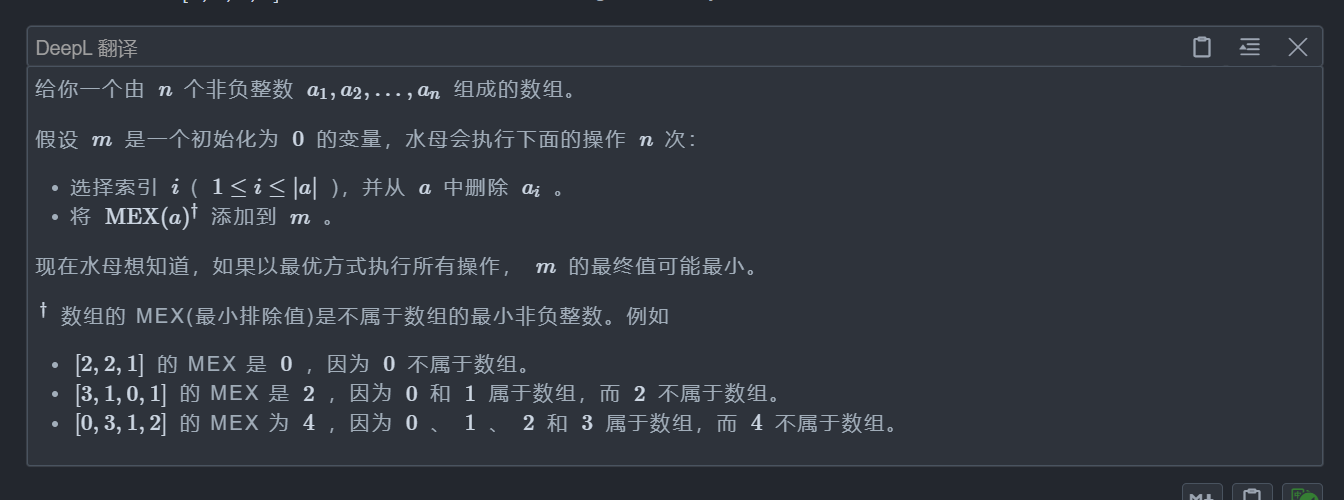
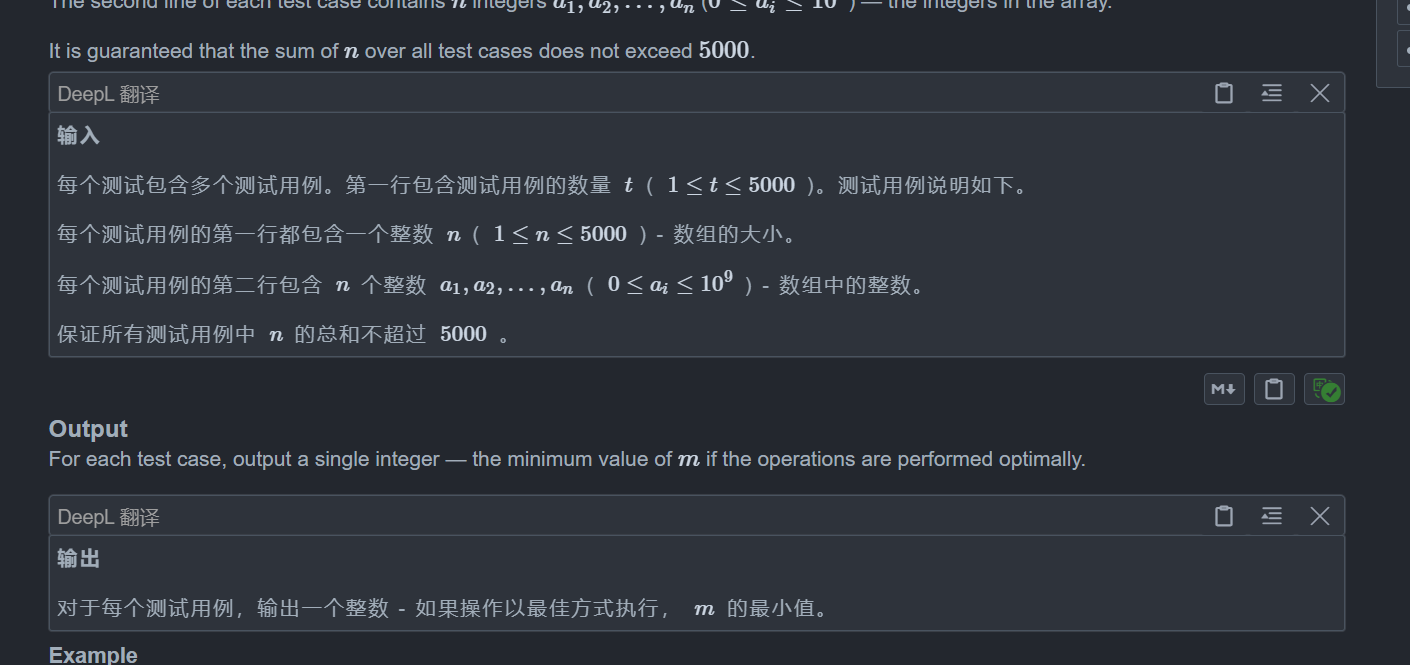
D. Jellyfish and Mex
题目:
思路:
动态规划好题
一个显然的想法就是先把0删掉,这样mex就是0了,但是试了后发现这肯定是错误的,比如 0 0 0 0 0 0 0 1,显然是把 1 删去后再删 0 更好
同时我们还能知道一个事实,就是如果要删一个数那么就要一直删到底,如果中途去删别的数的话显然不会更优
那我们再观察一下,由于我们每次删除一个数mex都会变化,且mex之间是有联系的,我们可以尝试一下动态规划
我们定义 dp[i] 为将 mex 变为 0 的最小代价,那么显然 dp[j] = dp[i] + cost,其中cost是使mex变为j的代价,其值为 cost = (cnt[j] - 1) * i + j,因为没完全删去 j 前之前的mex一直都是 i
那么这是显然可以的,双重循环,一层枚举之前的mex,一层枚举现在的mex,由于mex不可能超过n,而n最大只有 5000,所以时间复杂度是可以过的,因此这个方法可行
代码:
#include <iostream>
#include <algorithm>
#include<cstring>
#include<cctype>
#include<string>
#include <set>
#include <vector>
#include <cmath>
#include <queue>
#include <unordered_set>
#include <map>
#include <unordered_map>
#include <stack>
#include <memory>
using namespace std;
#define int long long
#define yes cout << "YES\n"
#define no cout << "NO\n"
void solve()
{
int n;
cin >> n;
vector<int> a(n+5);
vector<int> has(n+5, 0);
for (int i = 1; i <= n; i++)
{
cin >> a[i];
if (a[i] <= n)
{
has[a[i]]++;
}
}
int mex = 0;
while (has[mex])
{
mex++;
}
//将 此时的 mex 变成 i 的最小代价
vector<int> dp(n + 5, 1e18);
dp[mex] = 0;
//枚举之前的mex
for (int i = mex; i >= 1; i--)
{
//枚举现在的mex
for (int j = 0; j < i; j++)
{
dp[j] = min(dp[j], dp[i] + (has[j] - 1) * i + j);
}
}
cout << dp[0] << endl;
}
signed main()
{
cin.tie(0)->sync_with_stdio(false);
int t = 1;
cin >> t;
while (t--)
{
solve();
}
return 0;
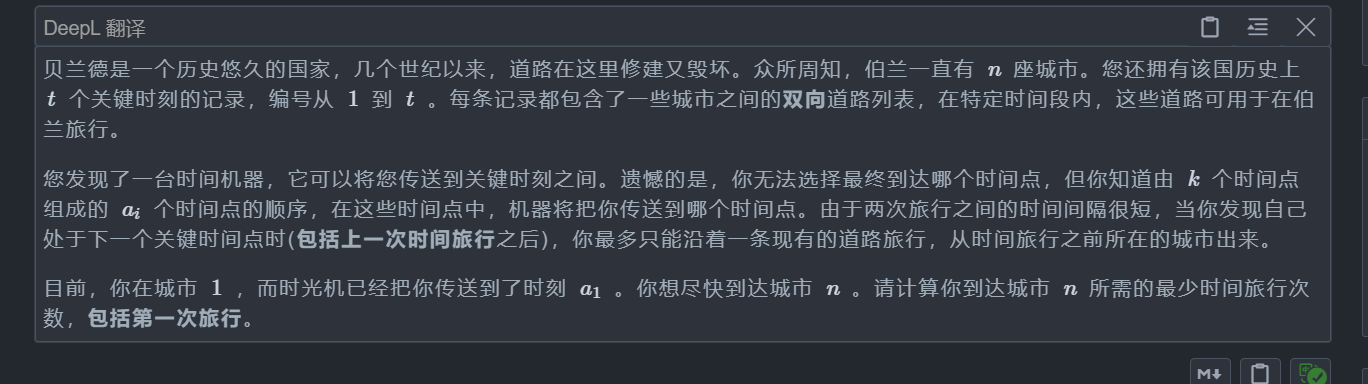
}E. Time Travel
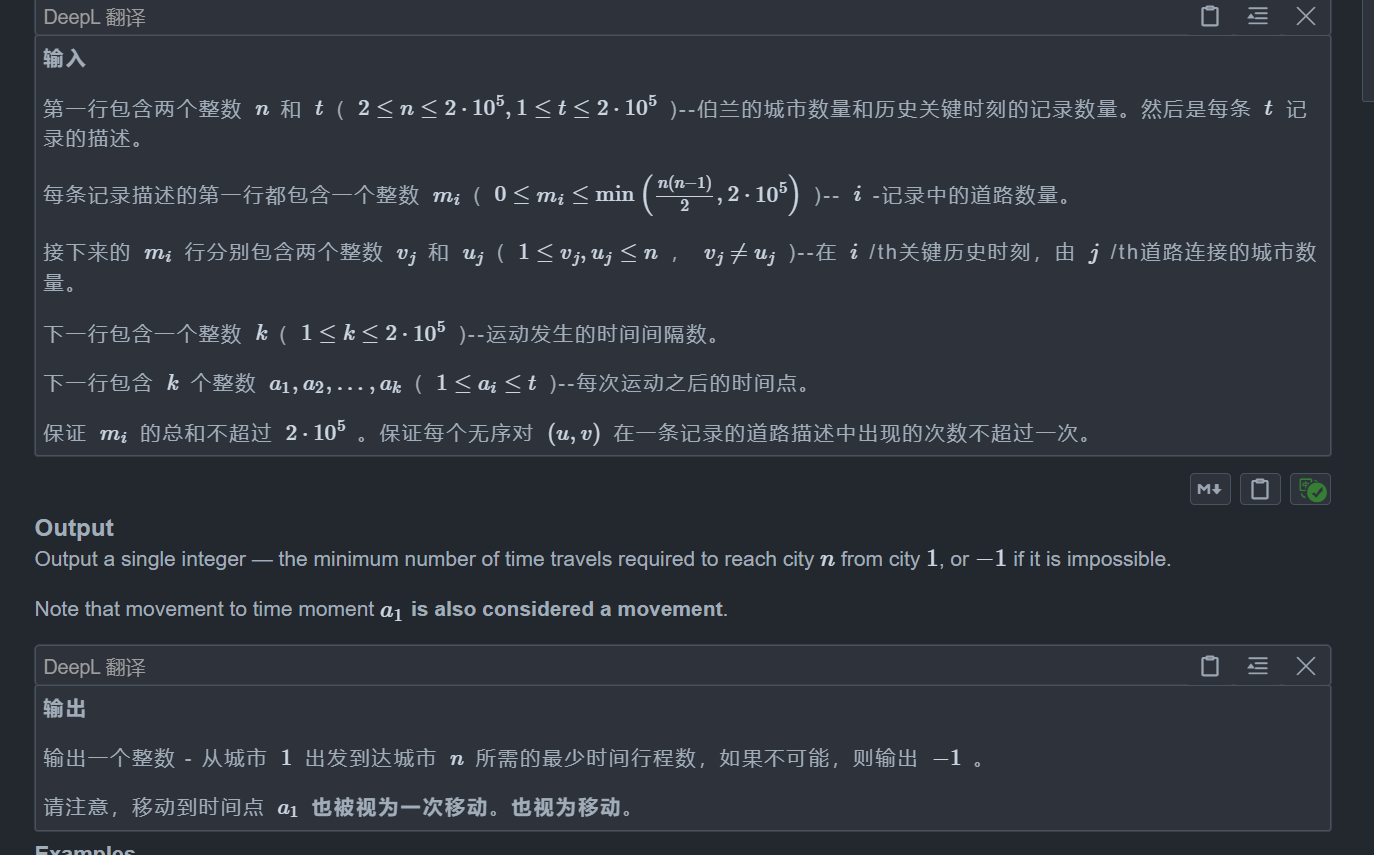
题目:
思路:
迪杰斯特拉变种,挺好的,吃代码实现能力
题目翻译一下就是:每次都能走一条边或者不走,操作完后需要等待1s,同时在第 i 秒时你只能走第 a[i] 张图上的边
如果这一题没有图的变换,那么就是一道很简单的每条边奉献为1的迪杰斯特拉模板题,但是由于多了这个限制,那我们就要增加一下思维了
我们还是以迪杰斯特拉的思想进行,但是这里面就要多一点技巧了,由于我们要知道在第 i 秒能不能走这条边,所以对于每条边我们还要存储一下他是第几张图的,那么根据堆优化的迪杰斯特拉算法,这里面的元素就是 耗时 + 此时的位置 了
那么还是一样的操作,如果能走,那么就放进队列里,这样最后一定是最优的,但是这里的判断就要多一点考虑了,由于我们的思路是要走最短的路,但是这里的最短和平常不一样,这里只能走指定图的路,所以我们还要判断一下什么时候能走这张图
如何判断呢?我们可以用一个数组存储每张图什么时候是开启的,当我们检测边的时候,我们先获取这条边是哪个图的,然后在 time[i] 中找一个最早时间点即可,对于找这个最早时间点我们可以使用二分,这样又是一个优化
那么这样的话思路就没问题了,具体实现看代码
代码:
#include <iostream>
#include <algorithm>
#include<cstring>
#include<cctype>
#include<string>
#include <set>
#include <vector>
#include <cmath>
#include <queue>
#include <unordered_set>
#include <map>
#include <unordered_map>
#include <stack>
#include <memory>
using namespace std;
#define int long long
#define yes cout << "YES\n"
#define no cout << "NO\n"
//first储存边 second储存他是第几张图中的边
vector<vector<pair<int,int>>> g(200005);
vector<int> dis(200005,-1);
//存储什么时候能走 i 图
vector<vector<int>> timemp(200005);
void dijstra()
{
priority_queue<pair<int, int>,vector<pair<int, int>>,greater<>> pq;
//消耗的时间 当前节点
pq.push({ 0,1 });
while (!pq.empty())
{
auto t = pq.top();
pq.pop();
int s = t.first;
int now = t.second;
//走过了(省一个vis)
if (dis[now] != -1)
{
continue;
}
dis[now] = s;
for (auto son : g[now])
{
//看看这条边是哪张图里的
int s2 = son.second;
//寻找一下最早的能走的图
auto it = lower_bound(timemp[s2].begin(), timemp[s2].end(), s);
if (it != timemp[s2].end())
{
pq.push({ *it + 1,son.first });
}
}
}
}
void solve()
{
int n, t;
cin >> n >> t;
for (int i = 1; i <= t; i++)
{
int m; cin >> m;
for (int j = 0; j < m; j++)
{
int u, v;
cin >> u >> v;
g[u].push_back({v,i});
g[v].push_back({u,i});
}
}
int k;
cin >> k;
for (int i = 0; i < k; i++)
{
int x;
cin >> x;
//x 图在 i 时间可被走
timemp[x].push_back(i);
}
dijstra();
cout << dis[n] << endl;
}
signed main()
{
cin.tie(0)->sync_with_stdio(false);
int t = 1;
//cin >> t;
while (t--)
{
solve();
}
return 0;
}F. Minimum Array
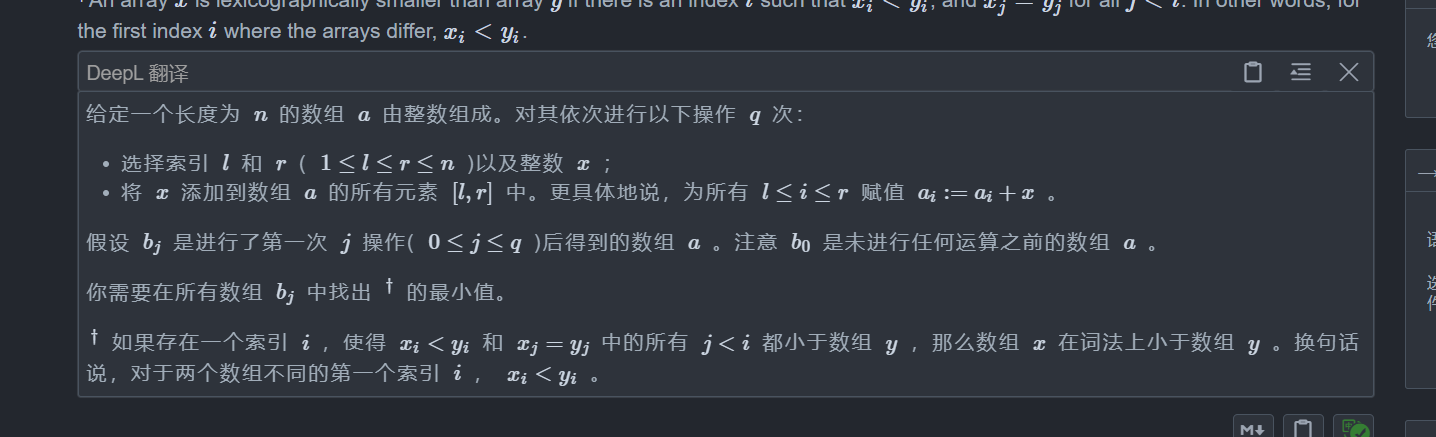
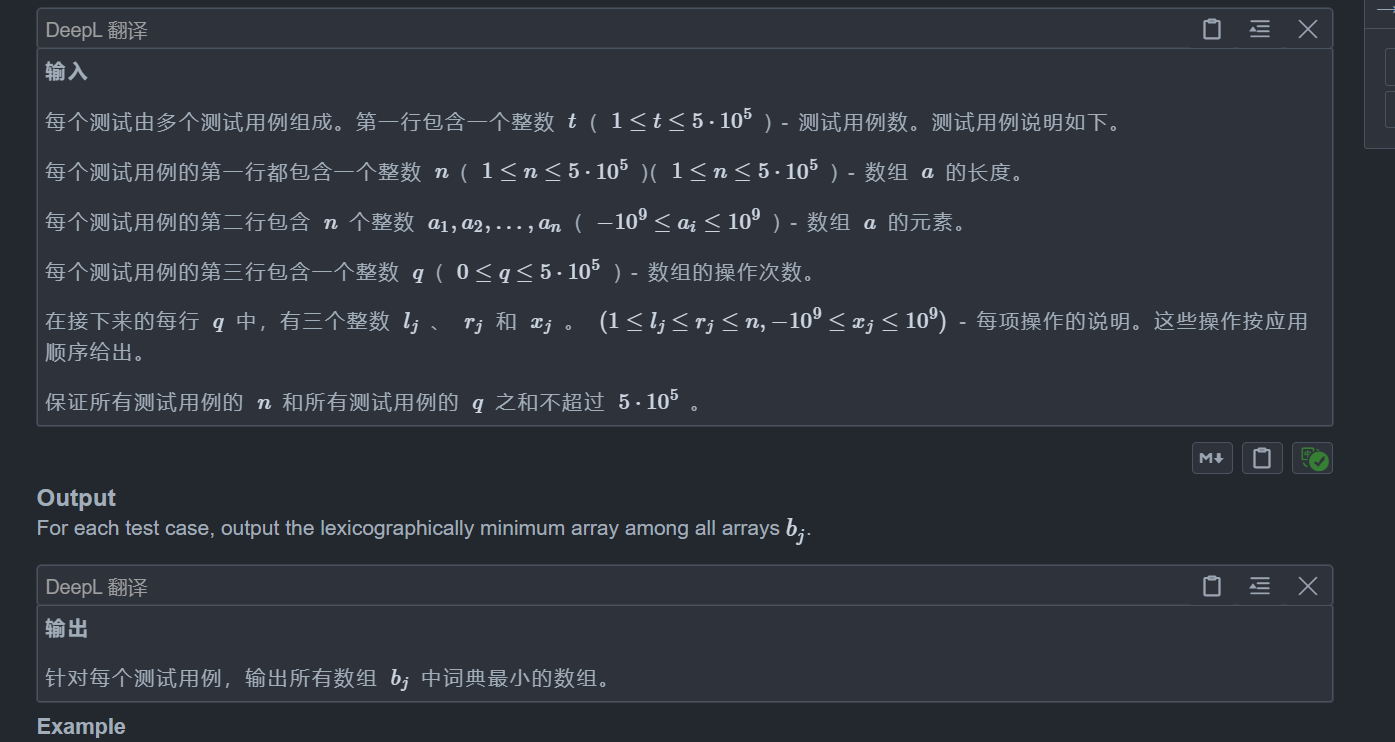
题目:
思路:
思维+技巧
题目让我求q次操作中字典序最小的那一个,那么我们就要搞清楚什么时候字典序会变小
显然,只有当某一个数变小时,字典序才会变小
那么q次操作怎么办?
对于这种区间修改我们可以想到差分数组,我们定义一个差分数组 d,只要第一个不为 0 的位置是负数,就说明这里的字典序比最开始的小
但是我们如何获取呢,或者说如何维护呢?
这里我们可以使用map,我们利用map来时刻维护,同时使用一个指针qindex来保存什么时候字典序最小,这样到时候我们只需要执行操作到qindex次就能构造出最小字典序的数组了
那么具体我们怎么维护呢?
我们可以这样,我们先把差分中前面为0的数删了,一直到第一个数不为0,如果它不是负数,那就继续下一次操作,否则就令 qindex = i,同时清空 map
为什么要清空map呢?
因为当我们找到第一个 qindex 时,说明此时字典序已经变小了,那么之后的操作都在此基础上进行即可,这样就能保证下一次的 qindex 比上次还小,也就满足最小的条件了
代码:
#include <iostream>
#include <algorithm>
#include<cstring>
#include<cctype>
#include<string>
#include <set>
#include <vector>
#include <cmath>
#include <queue>
#include <unordered_set>
#include <map>
#include <unordered_map>
#include <stack>
#include <memory>
using namespace std;
#define int long long
#define yes cout << "YES\n"
#define no cout << "NO\n"
void solve()
{
int n;
cin >> n;
vector<int> a(n + 1);
for (int i = 1; i <= n; i++)
{
cin >> a[i];
}
int q;
cin >> q;
map<int, int> d;
vector<int> l(q+1), r(q+1), x(q+1);
int qindex = 0;
for (int i = 1; i <= q; i++)
{
cin >> l[i] >> r[i] >> x[i];
d[l[i]] += x[i];
d[r[i] + 1] -= x[i];
while (!d.empty() && d.begin()->second == 0)
{
d.erase(d.begin());
}
if (!d.empty() && d.begin()->second < 0)
{
qindex = i;
d.clear();
}
}
vector<int> b(n + 2,0);
for (int i = 1; i <= qindex; i++)
{
b[l[i]] += x[i];
b[r[i] + 1] -= x[i];
}
for (int i = 1; i <= n; i++)
{
b[i] += b[i - 1];
a[i] += b[i];
}
for (int i = 1; i <=n; i++)
{
cout << a[i] << " ";
}
cout << endl;
}
signed main()
{
cin.tie(0)->sync_with_stdio(false);
int t = 1;
cin >> t;
while (t--)
{
solve();
}
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









