






网页源码拷贝到文件后,
如果打开文件后,
使用了.read()读取文件的方法,那么后面的使用soup如果再读取文件的内容则会为空。

使用print(file.read) 后,soup有内容,但是后面的soup的find()等方法,返回为none,或空列表。
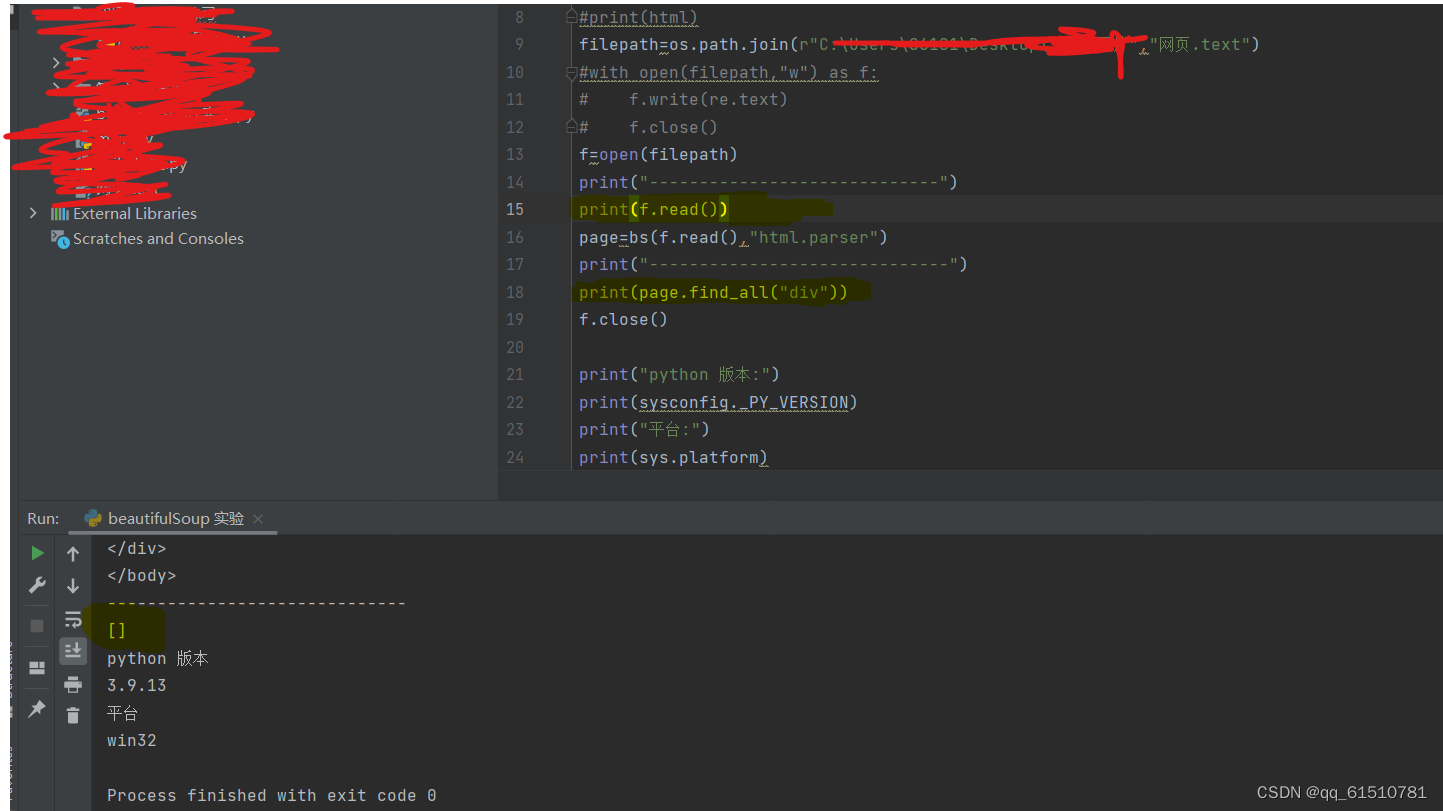
总结:如果后面soup要读取file内容,那在soup前不要使用f.read()方法,不然soup的方法失效。
下图为不使用的f.read()的情况

#怀疑可能是文件被read()占用。
网页源码拷贝到文件后,
如果打开文件后,
使用了.read()读取文件的方法,那么后面的使用soup如果再读取文件的内容则会为空。
使用print(file.read) 后,soup有内容,但是后面的soup的find()等方法,返回为none,或空列表。
总结:如果后面soup要读取file内容,那在soup前不要使用f.read()方法,不然soup的方法失效。
下图为不使用的f.read()的情况
#怀疑可能是文件被read()占用。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 3万+
3万+





