









1、介绍最小二乘法
最小二乘法是一种常用的数学方法,用于拟合实验数据或者解决优化问题。它的基本思想是通过最小化观测值和估计值之间的差异,找到最能代表数据特征的模型参数。
在使用最小二乘法进行数据拟合时,通常需要选择一个函数形式作为模型,例如线性模型、多项式模型等。然后,通过比较观测值与模型预测值之间的差异,即残差,来确定最佳拟合参数。
具体应用最小二乘法的步骤如下:
(1)根据问题的特点选择适当的模型形式;
(2)收集和整理所需的观测数据;
(3)设置目标函数,通常为测量值与模型预测值之间差异的平方和;
(4)对目标函数进行求异,并将导数置零,求取使目标函数达到最小值的参数;
(5)利用得到的最优参数,计算拟合曲线或曲面;
(6)对拟合结果进行评估,查看拟合优度和模型可靠性。
最小二乘法具有很多优点,例如在数学上有解析解,可靠性高等。局限性有容易受到异常值的影响,需要谨慎选择合适的模型和参数。在实际应用中,最小二乘法通常与其他统计方法和评估指标结合使用,以获得更准确和可靠的拟合结果。
2、递归和动态规划的区别?
递归和动态规划是两种常见的问题解决方法,它们有以下主要区别:
-
解决问题的方式:递归是一种自相似的解决方法,通过将问题分解为多个相同或类似的子问题,并通过递归调用函数来解决这些子问题。而动态规划则是通过将问题拆分成多个重叠子问题,并使用记忆化技术(通常是数组或哈希表)来存储并复用已解决的子问题的解。
-
子问题的重叠性:递归中通常会存在大量的重复计算,即对同一个子问题进行了多次计算,这样会造成效率低下。而动态规划通过保存已经计算过的子问题的解,避免了重复计算,提高了效率。
-
时间复杂度:由于递归可能存在重复计算,因此其时间复杂度较高。而动态规划利用存储已解决子问题的解,减少了计算量,可以以较低的时间复杂度解决问题。
-
空间复杂度:递归通常需要消耗较多的栈空间来保存函数调用的上下文信息,尤其在递归深度较大的情况下。而动态规划则通过建立存储表格来保存已解决子问题的解,需要更多的额外空间。
总体而言,递归是自顶向下的解决方法,在解决问题时可能存在重复计算,但其思路通常较为直观简单。
动态规划是一种自底向上的解决方法,在解决问题时通过使用已解决子问题的解来构建并解。
3、你知道的排序?
-
冒泡排序(Bubble Sort): 从左到右逐步比较相邻的元素并交换,每轮循环结束后,最大的元素会“冒泡”到正确的位置。
-
插入排序(Insertion Sort): 逐个将元素插入已排序的部分列表中,形成一个有序的列表。对于未排序的元素,在排序列表中从右到左地找到适当的位置,并插入。
-
选择排序(Selection Sort): 遍历数组,选择最小的元素与第一个元素交换,然后再在剩下的元素中找到最小的元素与第二个元素交换,依次类推。
-
快速排序(Quick Sort): 选取一个基准元素,将小于等于基准的元素放在左边,大于基准的元素放在右边,然后对左右两个子数组进行递归快速排序。
-
归并排序(Merge Sort): 将数组不断一分为二,直到只剩一个元素,然后将有序的子数组合并为一个有序数组,利用递归实现。
-
堆排序(Heap Sort): 将待排序的数组构建成一个最大堆(或最小堆),然后逐个将根节点取出,再重新调整剩余元素构建新的堆。
4、快速排序是稳定的吗?
快速排序是一种不稳定的排序算法。在快速排序中,元素的比较和交换是无序的,并且根据选择的基准元素进行划分。由于不同的实现方式可能导致基准元素的选择不同,因此可能会出现相等元素的顺序发生变化的情况,从而使得快速排序不是稳定的。
5、说出你知道的分类器?
-
朴素贝叶斯分类器(Naive Bayes Classifier):基于贝叶斯定理和特征性假设,常用于文本分类、垃圾邮件过滤等。
-
决策树分类器(Decision Tree Classifier):通过对数据集进行递归地划分,形成一系列决策层级,常用于数据挖掘和问题解决。
-
支持向量机(Support Vector Machine,SVM):通过在特征空间中构建超平面来实现分类,可用于线性和非线性分类问题。
-
随机森林(Random Forest):由多个决策树组成的集成学习方法,通过投票或平均的方式进行分类。
-
k最近邻算法(k-Nearest Neighbors,KNN):基于样本之间的距离度量,将新数据标记为其k个最近邻居中最多的类别。
-
神经网络(Neural Networks):模拟人脑神经元通信的网络结构,可以用于复杂的非线性分类问题。
6、SpringBoot是什么?
Spring Boot 是一个用于快速创建、可运行的、生产级的 Spring 应用程序的框架。它简化了 Spring 应用程序的配置和部署过程,使开发者能够更加专注于业务逻辑的实现。Spring Boot 提供了自动配置、嵌入式服务器以及各种依赖库的便捷集成,提高了开发效率并减少了繁琐的配置工作。它还支持各种应用类型,包括 Web 应用、批处理应用、集成测试和云原生应用等。
Spring Boot 是一个基于 Spring 框架的轻量级 Web 应用程序开发框架,主要用于快速构建基于 Spring 框架的应用程序。它本身并不是前端或后端,而是一个用于快速构建应用程序的开发框架。
在开发 Spring Boot 应用程序时,通常需要使用前端技术和后端技术。前端技术包括 HTML、CSS、JavaScript、React、Vue.js 等,用于构建用户界面和交互;后端技术包括 Java、Spring Boot、MySQL、Redis 等,用于构建应用程序的业务逻辑和数据存储。
开发 Spring Boot 应用程序的一般过程如下:
-
确定应用程序的业务逻辑和功能需求,设计应用程序的架构和模块。
-
根据业务逻辑和功能需求,编写 Java 代码实现应用程序的业务逻辑和功能。
-
使用 Spring Boot 框架构建应用程序的依赖关系和配置文件。
-
使用前端技术构建用户界面和交互,例如使用 HTML、CSS、JavaScript、React、Vue.js 等。
-
将前端技术和后端技术集成在一起,实现应用程序的完整功能。
-
进行测试和调试,确保应用程序的稳定性和可靠性。
-
部署和发布应用程序到生产环境中,并进行监控和维护。
7、深度学习
深度学习(DL,Deep Learning)是机器学习(ML,Machine Learning)领域中一个新的研究方向。深度学习是学习样本数据的内在规律和表示层次。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别等方面取得的效果,远远超过先前相关技术。深度学习在搜索技术、数据挖掘、机器学习、机器翻译、自然语言处理、多媒体学习、语音。推荐和个性化技术以及其他相关领域都取得了很多成功。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题。
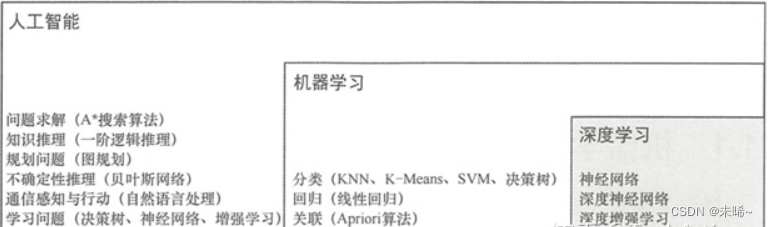
机器学习按照方法主要分为两大类:监督学习和无监督学习。
监督学习主要由分类和回归等问题组成,无监督学习主要由聚类和关联分析等问题组成。深度学习则属于监督学习中的一种。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









