







目录
数据是计算机处理的对象。从不同的处理角度来看,数据有不同的表现形态。
从外部形式来看,计算机可处理数值、文字,图,声音、视频以及各种模拟信息。从算法描述的角度来看,有图、表、树、队列,矩阵等结构类型的数据。从高级语言程序员的角度来看,有数组、结构、指针﹑实数﹑整数、布尔数、字符和字符串等类型的数据。不管以什么形态出现,在计算机内部数据最终都由机器指令来处理。从计算机指令集体系结构(ISA)角度来看,计算机中底层的机器级表示数据只有几类简单的基本数据类型。
本章重点讨论计算机内部数据的机器级表示方式。主要内容包括进位记数制、二进制定点数的编码表示、无符号整数和带符号整数的表示,IEEE754浮点数表示标准、西文字符和汉字的编码表示、十进制数的二进制编码表示(即 BCD码)、C语言中各种类型数据的表示和转换、数据的宽度和存放顺序以及几种常用检/纠错码的编码表示与使用方法。
数制和编码
信息的二进制编码
计算机内部处理的所有数据都必须是“数字化编码”了的数据。
现实世界中的感觉媒体信息(如声音、文字,图画,活动图像等)由输人设备转化为二进制编码表示,因此,输入设备必须具有“离散化”和“编码”两方面的功能。因为计算机中用来存储、加工和传输数据的部件都是位数有限的部件,所以,计算机中只能表示和处理离散的信息。“数字化编码”过程,就是指对感觉媒体信息进行定时采样,将现实世界中的连续信息转换为计算机中的离散的“样本”信息,然后对它们用0和1进行数字化编码的过程。
所谓编码,就是用少量简单的基本符号对大量复杂多样的信息进行一定规律的组合。基本符号的种类和组合规则是信息编码的两大要素。例如,电报码中用4位十进制数字表示汉字;从键盘上输入汉字时用汉语拼音(即26个英文字母)表示汉字等,都是编码的典型例子。
输入涉设备对采样的信息转换为离散的样本,在用0,1编码。
在计算机系统内部,所有信息都是用二进制进行编码的。也就是说计算机内部采用的是二进制表示方式。这样做的原因有以下几点。
- 二进制只有两种基本状态,使用有两个稳定状态的物理器件就可以表示二进制数的每一位,而制造有两个稳定状态的物理器件要比制造有多个稳定状态的物理器件容易得多。例如,用高、低两个电位﹐或用脉冲的有无,或脉冲的正负极性等都可以很方便、很可靠地表示0和1。
- 二进制的编码和运算规则都很简单。可用开关电路实现,简便易行。
- 两个符号1和О正好与逻辑命题的两个值“真”和“假”相对应,为计算机中实现逻辑运算和程序中的逻辑判断提供了便利的条件,特别是能通过逻辑门电路方便地实现算术运算。
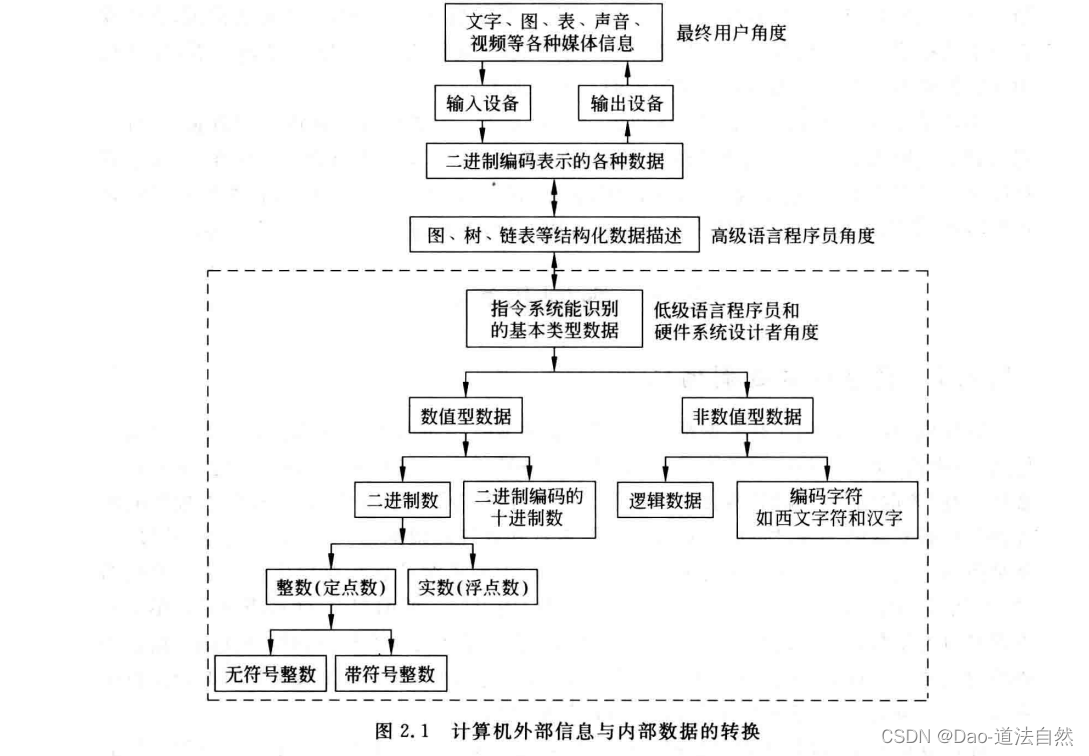
采用二进制编码将各种媒体信息转变成数字化信息后,可以在计算机内部进行存储、处理和传送。在高级语言程序中,可以用图,树、表和队列等进行算法描述,并能以数组、结构、指针和字符串等数据类型来说明处理对象,但将高级语言程序转换为机器语言程序后,每条指令的操作数就只能是某种简单的基本数据类型。如图虚线框内所示,指令所处理的基本数据类型分为两种:数值型数据和非数值型数据。数值型数据可用来表示数量的多少,可比较其大小,分为整数和实数﹐整数又分为无符号整数和带符号整数。在计算机内部,整数用定点数表示,实数用浮点数表示。非数值型数据没有大小之分,不表示数量的多少,主要包括字符数据和逻辑数据。
日常生活中,常使用带正负号的十进制数表示数值数据,例如6.18、一127等。但这种形式的数据在计算机内部难以直接存储、运算和传输。通常的十进制数仅仅是一种数值数据的输入输出形式,而不是计算机内部的表示形式。
在计算机内部,数值数据的表示方法有两种:一种是直接用二进制数表示,另一种是采用二进制编码的十进制数(Binary Coded Decimal Number,BCD)表示。
表示一个数值数据要确定3个要素:进位记数制、定点/浮点表示和编码规则。任何给定的一个二进制0/1序列,在未确定它采用什么进位记数制、定点还是浮点表示以及编码表示方法之前,它所代表的数值数据的值是无法确定的。
进位计数制
日常生活中基本上都使用十进制数,其每个数位可用十个不同符号0,1,2,…,9来表示,每个符号处在十进制数中不同位置时,所代表的数值不一样。例如,2585.62代表的值是


扩展到一般情况,在R进制数字系统中,应采用R个基本符号(0,1,2,… ,R-1)表示各位上的数字,采用“逢R进一”的运算规则,对于每一个数位i,该位上的权为Ri。R被称为该数字系统的基数。

一般用B(Binary)表示二进制,用O(Octal)表示八进制,用D(Decimal)表示十进制(十进制数的后缀可以省略),而H(Hexadecimal)则是十六进制数的后缀﹐例如,二进制数10011B,十进制数56D(或56),十六进制数308FH,3C.5H等。
计算机内部所有的信息采用二进制编码表示。但在计算机外部,为了书写和阅读的方便,大都采用八、十或十六进制表示形式。因此,计算机在数据输入后或输出前都必须实现这些进位制数和二进制数之间的转换。
定点与浮点表示
日常生活中所使用的数有整数和实数之分,整数的小数点固定在数的最右边,可以省略不写,而实数的小数点则不固定。计算机中只能表示0和1,无法表示小数点,因此,要使得计算机能够处理日常使用的数值数据,必须要解决小数点的表示问题。通常计算机中通过约定小数点的位置来实现。小数点位置约定在固定位置的数称为定点数,小数点位置约定为可浮动的数称为浮点数。
1、定点表示
定点表示法用来对定点小数和定点整数进行表示。对于定点小数,其小数点总是固定在数的最左边,一般用来表示浮点数的尾数部分。对于定点整数,其小数点总是固定在数的最右边,因此可用“定点整数”来表示整数。
2、浮点表示

定点数的编码表示
定点/浮点表示解决了小数点的表示问题。但是,对于一个数值数据来说,还有一个正负号的表示问题。计算机中只能表示0和1,因此,正负号也用0和1来表示。这种将数的符号用0和1表示的处理方式称为符号数字化。一般规定0表示正号,1表示负号。
数字化了的符号能否和数值部分一起参加运算呢?为了解决这个问题,就产生了把符号位和数值部分一起进行编码的各种方法。因为任意一个浮点数都可以用一个定点小数和一个定点整数来表示,所以,只需要考虑定点数的编码表示。
定点数编码表示方法主要有以下4种:原码、补码,反码和移码。通常将数值数据在计算机内部编码表示的数称为机器数,而机器数真正的值(即现实世界中带有正负号的数)称为机器数的真值。
根据定义可知,机器数一定是一个0/1序列,通过缩写成16进制形式

原码
如果机器字长为n,那么一个数的原码就是用一个n位的二进制数,其中最高位为符号位:正数为0,负数为1。剩下的n-1位表示概数的绝对值。
例如: X=+101011 , [X]原= 00101011 X=-101011 , [X]原= 10101011
位数不够的用0补全。
PS:正数的原、反、补码都一样:0的原码跟反码都有两个,因为这里0被分为+0和-0。
反码
反码就是在原码的基础上,符号位不变其他位按位取反(就是0变1,1变0)就可以了。
例如:X=-101011 , [X]原= 10101011 ,[X]反=11010100
补码
补码也非常的简单就是在反码的基础上按照正常的加法运算加1。
例如:X=-101011 , [X]原= 10101011 ,[X]反=11010100,[X]补=11010101
PS:0的补码是唯一的,如果机器字长为8那么[0]补=00000000。
移码
移码最简单了,不管正负数,只要将其补码的符号位取反即可。
例如:X=-101011 , [X]原= 10101011 ,[X]反=11010100,[X]补=11010101,[X]移=01010101
相关的理论说明可以看书,讲的很精彩!!!在这里简要做一下总结。
袁春风老师在讲解补码时引入了模运算的概念。以钟表为例:12点,当前时间是1点,将时针顺时针波动3和逆时针波动9都会让时针停留在4这个位置。这就是一个模运算系统,模是12。在这个系统中-4和+8等是等效的。这样可以把减法转换为加法。

在模运算系统中,通过对负数求其补码,加上这个负数就可转换为等效的加上正数。减法就被转为加法。举例:在模为12的系统中,1-3=1+9=10
移码暂时没看明白。
整数的表示
整数的小数点隐含在数的最右边,故无须表示小数点,因而整数也被称为定点数。计算机中处理的整数可以用二进制表示,也可以用二进制编码的十进制数(BCD码)表示。二进制整数分为无符号整数(unsigned integer)和带符号整数(signed integer)两种。
无符号整数的表示
当一个编码的所有二进位都用来表示数值而没有符号位时,该编码表示的就是无符号整数。此时,默认数的符号为正,所以无符号整数就是正整数或非负整数。
一般在全部是正数运算且不出现负值结果的场合下,使用无符号整数表示。例如,可用无符号整数进行地址运算,或用来表示指针。通常把无符号整数简单地说成无符号数。
由于无符号整数省略了一位符号位,所以在字长相同的情况下,它能表示的最大数比带符号整数所能表示的大,n位无符号整数可表示的数的范围为0~(2^n - 1)。例如,8位无符号整数的形式为00000000B~11111111B,对应的数的取值范围为0~(2^8 - 1),即最大数为255,而8位带符号整数的最大数是127。
带符号整数的表示
带符号整数也称为有符号整数,它必须用一个二进位来表示符号,虽然前面介绍的各种二进制定点数编码表示(包括原码,补码,反码和移码)都可以用来表示带符号整数,但是补码表示有其突出的优点,主要体现在以下几方面。
- 与原码和反码相比,数О的补码表示形式唯一。
- 与原码和移码相比,补码运算系统是一种模运算系统,因而可用加法实现减法运算,且符号位可以和数值位一起参加运算。
- 与原码和反码相比,补码比原码和反码多表示一个最小负数。(4)与反码相比,补码不需要通过循环进位来调整结果。
现代计算机中带符号整数都用补码表示,故n位带符号整数可表示的数值范围为 -2^(n-1) ~ 2^(n-1) - 1。例如,8位带符号整数的表示范围为-128~+127。
C语言的整数类型
C语言支持多种整数类型。无符号整数在C语言中对应unsigned short, unsigned int(unsigned) , unsigned long 等类型,常在数的后面加一个u或U来表示,例如12345U、0x2B3Cu等;带符号整数在C语言中对应short, int , long 等类型。C语言中允许无符号整数和带符号整数之间的转换,转换后数的真值是将原二进制机器数按转换后的数据类型重新解释得到。例如,考虑以下C代码:

上述C代码中,r为带符号整数,u为无符号整数,初值为2 147483648(即2^31)。函数printf用来输出数值,指示符%u、%d分别用来以无符号整数和带符号整数的形式输出十进制数的值。当在一个32位机器上运行上述代码时,它的输出结果如下:

x的输出结果说明如下:因为一1的补码表示为11…1,所以当作为32位无符号数来解释(格式符为%u)时,其值为23一1= 4 294 967296-1=4 294 967295。
u的输出结果说明如下:23的无符号数表示为100…0,当这个数被解释为32位带符号整数(格式符为%d)时,其值为最小负数:一232-1= —231= —2 147483648(参见例2.12)。
在C语言中,如果执行一个运算时同时有无符号数和带符号整数参加,那么,C编译器会隐含地将带符号整数强制类型转换为无符号数,因而会带来一些意想不到的结果。
实数的表示
计算机内部进行数据存储、运算和传送的部件位数有限,因而用定点数表示数值数据时,其表示范围很小。对于n位带符号整数,其表示范围为 -2^(n-1) ~ (2^(n-1)-1),运算结果很容易溢出,此外,用定点数也无法表示大量带有小数点的实数。因此,计算机中专门用浮点数来表示实数。
浮点数的表示格式

需设置偏置常数



根据浮点数的表示格式,只要尾数为0,指数为任何值其值都为0,这样的数被称为机器零,因此机器零不唯一。通常用阶码和尾数同时为0来唯一表示机器零。即当结果出现尾数为0时,不管阶码是什么,都将阶码取为0。也有的计算机将下溢区(指数过小)的数近似成机器零。机器零有+0和一0之分。
浮点数的规格化
浮点数尾数的位数决定浮点数的有效数位,有效数位越多,数据的精度越高。为了在浮点数运算过程中尽可能多地保留有效数字的位数,使有效数字尽量占满尾数数位,必须在运算过程中对浮点数进行“规格化”操作。对浮点数的尾数进行规格化,除了能得到尽量多的有效数位以外,还可以使浮点数的表示具有唯一性。
从理论上来讲,规格化数的标志是真值的尾数部分中最高位具有非零数字。也就是说,若基数为R,则规格化数的标志是,尾数部分真值的绝对值大于等于1/R。若浮点数的基数为2,则尾数规格化的浮点数形式应为士0.1bb…b×2E(这里b是0或1)。
规格化操作有两种:“左规”和“右规”。当有效数位进到小数点前面时,需要进行右规。右规时,尾数每右移一位,阶码加1,直到尾数变成规格化形式为止,右规时指数会增加,因此有可能溢出;当出现形如±0.0…0bb…b×2F的运算结果时,需要进行左规,左规时,尾数每左移一位,阶码减1,直到尾数变成规格化形式为止。
IEEE 754浮点数标准
1985年完成了浮点数标准IEEE 754 的制定。其主要起草者是加州大学伯克利分校数学系教授William Kahan,他帮助Intel公司设计了8087浮点处理器(FPU),并以此为基础形成了IEEE 754标准,Kahan教授也因此获得了1987年的图灵奖。
目前几乎所有计算机都采用IEEE 754标准表示浮点数。在这个标准中,提供了两种基本浮点格式:32位单精度和64位双精度格式,如图所示。
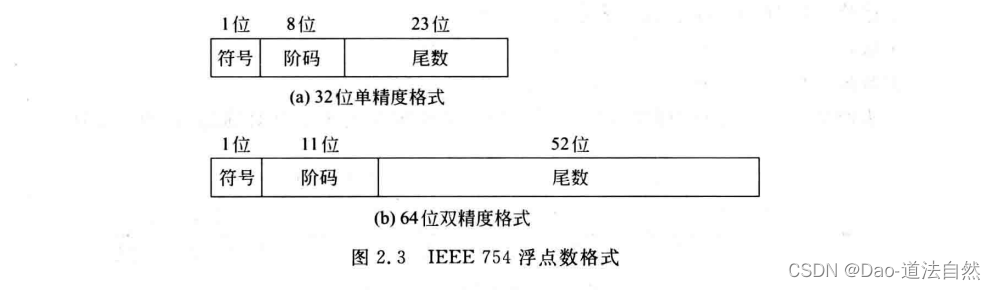
32位单精度格式中包含1位符号s,8位阶码e和23位尾数f;64位双精度格式包含1位符号s,11位阶码e和52位尾数f。其基数隐含为⒉;尾数用原码表示,第一位总为1,因而可在尾数中省略第一位的1,称为隐藏位,使得单精度格式的23位尾数实际上表示了24位有效数字,双精度格式的52位尾数实际上表示了53位有效数字。IEEE 754规定隐藏位1的位置在小数点之前。
IEEE 754标准格式中,指数用移码表示,偏置常数并不是通常n位移码所用的2^(n-1),而是2^(n-1) - 1,因此,单精度和双精度浮点数的偏置常数分别为127和1023。IEEE 754的这种“尾数带一个隐藏位,偏置常数用2^(n-1) - 1”的做法,不仅没有改变传统做法的计算结果,而且带来以下两个好处:
- 尾数可表示的位数多一位,因而使浮点数的精度更高。
- 指数的可表示范围更大,因而使浮点数范围更大。
对于IEEE 754标准格式的数,一些特殊的位序列(如阶码为全0或全1)有其特别的解释。表2.3给出了对各种形式的数的解释。


C语言中的浮点数类型
C语言中有float和double两种不同浮点数类型,分别对应IEEE754单精度浮点数格式和双精度浮点数格式,相应的十进制有效数字位数分别为7位和17位。
C语言对于扩展双精度的相应类型是long double,但是long double的长度和格式随编译器和处理器类型的不同而有所不同。例如, Microsoft Visual C++ 6.0.版本以下的编译器都不支持该类型,因此,用其编译出来的目标代码中long double和 double 一样,都是64位双精度;在IA-32上使用gcc编译器时, long double类型数据采用2.3.3节中所述的Intel x87 FPU的80位双精度扩展格式表示;在SPARC和PowerPC处理器上使用gcc编译器时, long double类型数据采用2.3.3节中所述的128位双精度扩展格式表示。
当在int、float和 double等类型数据之间进行强制类型转换时,程序将得到以下数值转换结果(假定int为32位)。
- 从int转换为float时,不会发生溢出,但可能有数据被舍入。
- 从int或float转换为double时,因为double的有效位数更多,故能保留精确值。
- 从double转换为float时,因为float表示范围更小,故可能发生溢出,此外,由于有效位数变少,故可能被舍入。
- 从float或double转换为int时,因为int没有小数部分,所以数据可能会向0方向被截断。例如,1.9999被转换为1,一1.9999被转换为一1。此外,因为int的表示范围更小,故可能发生溢出。将大的浮点数转换为整数可能会导致程序错误,这在历史上曾经有过惨痛的教训。
十进制数的表示
人们日常使用和熟悉的是十进制,使用计算机来处理数据时,在计算机外部(如键盘输人,屏幕显示或打印输出)看到的数据基本上是十进制形式,因此,有时需要计算机内部能够表示和处理十进制数据,以方便直接进行十进制数的输入输出或直接用十进制数进行计算。
在计算机内部,可以采用数字0~9对应的ASCII码字符来表示十进制数,也可以采用二进制编码的十进制数(BCD)来表示十进制数。
用 ASCII 码字符表示
为方便十进制数输入输出(如打印或显示),可以把十进制数看成字符串,直接用ASCII码表示,0~9分别对应30H~~39H。这种表示方式下,一位十进制数对应8位二进制数。一个十进制数在计算机内部需占用多个连续字节,因此,在存取一个十进制数时,必须说明该十进制数在内存的起始地址和字节个数。
根据不同的数符表示方式,可以分为前分隔数字串和后嵌入数字串两种格式。前分隔数字串方式是:将符号位单独用一个字节来表示,位于数字串之前。正号用字符“+”的ASCII 码(2BH)表示;负号用字符“一”的ASCII码(2DH)表示。例如,十进制数+236表示为0010 1011-0011 0010 0011 0011 0011 0110B(2B 32 33 36H),在内存中占用4个字节。后嵌入数字串方式为:符号位不单独用一个字节来表示,而是嵌入到最低一位数字的ASCII码中。正数的最低一位数字编码不变;负数的最低一位数字编码的高4位由原来的0011变为0111。例如,十进制数一236表示为0011 0010 0011 0011 0111 0110B(32 3376H),在内存中占用3个字节。
用ASCII码字符串方式来表示十进制数﹐方便了十进制数的输人输出,但是,由于这种表示形式中含有非数值信息(高4位编码),所以对十进制数的运算很不方便。如果要对这种形式的十进制数进行计算,则必须先转换为二进制数或用BCD码表示十进制数。
用 BCD 码表示
这种十进制数用二进制编码的形式,通过专门的十进制数运算指令进行处理。计算机中可有专门的逻辑线路在BCD码运算时使每4位二进制数按十进制进行处理。
每位十进制数的取值可以是0~9这10个数之一,因此,每一个十进制数位必须至少由4位二进制位来表示。而4位二进制位可以组合成16种状态,去掉10种状态后还有6种冗余状态,所以从16种状态中选取10种状态来表示十进制数位0~9的方法很多,可以产生多种 BCD码。
1.有权BCD码
十进制有权码是指表示每个十进制数位的4个二进制数位(称为基2码)都有一个确定的权。最常用的一种编码就是8421码,它选取4位二进制数按计数顺序的前10个代码与十进制数字相对应,每位的权从左到右分别为8、4,2、1,因此称为8421码,也称自然BCD码,记为NBCD码。
2.无权BCD码
十进制无权码是指表示每个十进制数位的4个基2码没有确定的权。在无权码方案中,用得较多的是余3码和格雷码。
一个十进制数用多个对应的BCD码组合表示,每个数字对应4位BCD码,两个数字占一个字节,数符可用1位二进制表示,1表示负数,0表示正数;也可用4位二进制表示,并放在数字串最后,通常用1100表示正号,用1101表示负号。例如, Pentium处理器中的十进制数占80位,第一个字节中的最高位为符号位,后面的9个字节可表示18位十进制数。
非数值数据的编码表示
逻辑值、字符等数据都是非数值数据,在机器内部它们也用二进制表示。下面分别介绍这些非数值数据的编码表示。
逻辑值
正常情况下,每个字或其他可寻址单位(字节、半字等)是作为一个整体数据单元看待的。但是,某些时候还需要将一个n位数据看成由n 个1位数据组成,每个取值为0或1。例如,有时需要存储一个布尔或二进制数据阵列,阵列中的每项只能取值为1或0;有时可能需要提取一个数据项中的某位进行诸如“置位”或“清零”等操作。当数据以这种方式看待时,就被认为是逻辑数据。因此n位二进制数可表示n个逻辑值。逻辑数据只能参加逻辑运算,并且是按位进行的,如按位“与”、按位“或”、逻辑左移、逻辑右移等。
逻辑数据和数值数据都是一串0/1序列,在形式上无任何差异,需要通过指令的操作码类型来识别它们。例如,逻辑运算指令处理的是逻辑数据,算术运算指令处理的是数值数据。
西文字符
西文由拉丁字母,数字、标点符号及一些特殊符号所组成,它们统称为字符(character)。所有字符的集合叫做字符集。字符不能直接在计算机内部进行处理,因而也必须对其进行数字化编码,字符集中每一个字符都有一个代码(即二进制编码的0/1序列),构成了该字符集的代码表,简称码表。码表中的代码具有唯一性。
字符主要用于外部设备和计算机之间交换信息。一旦确定了所使用的字符集和编码方法后,计算机内部所表示的二进制代码和外部设备输人、打印和显示的字符之间就有唯一的对应关系。
字符集有多种,每个字符集的编码方法也多种多样。目前计算机中使用最广泛的西文字符集及其编码是 ASCII 码,即美国标准信息交换码(American Standard Code forInformation Interchange),ASCII字符编码
汉字字符
西文是一种拼音文字,用有限的几个字母可以拼写出所有单词。因此西文中仅需要对有限个少量的字母和一些数学符号,标点符号等辅助字符进行编码,所有西文字符集的字符总数不超过256个,所以使用7个或8个二进位就可表示。中文信息的基本组成单位是汉字,汉字也是字符。但汉字是表意文字,一个字就是一个方块图形。计算机要对汉字信息进行处理,就必须对汉字本身进行编码,但汉字的总数超过6万字,数量巨大,给汉字在计算机内部的表示、汉字的传输与交换,汉字的输入和输出等带来了一系列问题。为了适应汉字系统各组成部分对汉字信息处理的不同需要,汉字系统必须处理以下几种汉字代码:输人码、内码、字模点阵码。
1.汉字的输入码
由于计算机最早是由西方国家研制开发的,最重要的信息输人工具——键盘是面向西文设计的,一个或两个西文字符对应着一个按键,非常方便。但汉字是大字符集,专门的汉字输入键盘由于键多、查找不便、成本高等原因而几乎无法采用。目前来说,最简便、最广泛采用的汉字输人方法是利用英文键盘输入汉字。由于汉字字数多,无法使每个汉字与西文键盘上的一个键相对应,因此必须使每个汉字用一个或几个键来表示,这种对每个汉字用相应的按键进行的编码表示就称为汉字的输入码,又称外码。因此汉字的输入码的码元(即组成编码的基本元素)是西文键盘中的某个按键。
2.字符集与汉字内码
汉字被输人到计算机内部后﹐就按照一种称为内码的编码形式在系统中进行存储、查找、传送等处理。对于西文字符,它的内码就是ASCII码。
3.汉字的字模点阵码和轮廓描述
经过计算机处理后的汉字,如果需要在屏幕上显示出来或用打印机打印出来,则必须把汉字机内码转换成人们可以阅读的方块字形式。
每一个汉字的字形都必须预先存放在计算机内,一套汉字(例如GB 2312国标汉字字符集)的所有字符的形状描述信息集合在一起称为字形信息库,简称字库(font)。不同的字体(如宋体,仿宋、楷体、黑体等)对应不同的字库。在输出每一个汉字时,计算机都要先到字库中去找到它的字形描述信息﹐然后把字形信息送到相应的设备输出。
汉字的字形主要有两种描述方法:字模点阵描述和轮廓描述。字模点阵描述是将字库中的各个汉字或其他字符的字形(即字模)用一个其元素由0和1组成的方阵(如16×16,24×24、32×32甚至更大)来表示,汉字或字符中有黑点的地方用1表示,空白处用0表示,这种用来描述汉字字模的二进制点阵数据称为汉字的字模点阵码。汉字的轮廓描述方法比较复杂,它把汉字笔画的轮廓用一组直线和曲线来勾画,记下每一直线和曲线的数学描述公式。目前已有两类国际标准:Adobe Typel和TrueType。这种用轮廓线描述字形的方式精度高,字形大小可以任意变化。
数据的宽度与存储
数据宽度和单位
计算机内部任何信息都被表示成二进制编码形式。二进制数据的每一位(0或1)是组成二进制信息的最小单位,称为一个比特(bit),或称位元,简称位。比特是计算机中处理、存储和传输信息的最小单位。
每个西文字符需要用8个比特表示,而每个汉字需要用16个比特才能表示。在计算机内部,二进制信息的计量单位是字节(byte),也称位组。一个字节等于8个比特。
计算机中运算和处理二进制信息时使用的单位除了比特和字节之外,还经常使用字( word)作为单位。必须注意,不同的计算机,字的长度和组成不完全相同,有的由两个字节组成,有的由4个、8个甚至16个字节组成。
在考察计算机性能时,一个很重要的性能参数就是机器的字长。平时所说的“某种机器是16位机或是32位机”中的16、32就是指字长。所谓字长通常是指CPU内部用于整数运算的数据通路的宽度。CPU内部数据通路是指CPU内部的数据流经的路径以及路径上的部件,主要是CPU内部进行数据运算﹑存储和传送的部件,这些部件的宽度基本上要一致,才能相互匹配。因此,字长等于CPU内部用于整数运算的运算器位数和通用寄存器宽度。
字和字长的概念不同,这一点请注意。字用来表示被处理信息的单位,用来度量各种数据类型的宽度。通常系统结构设计者必须考虑一台机器将提供哪些数据类型,每种数据类型提供哪几种宽度的数,这时就要给出一个基本的字的宽度。例如, Intel x86微处理器中把一个字定义为16位。所提供的数据类型中,就有单字宽度的无符号数和带符号整数(16位)、双字宽度的无符号数和带符号整数(32位)等。而字长表示进行数据运算、存储和传送的部件的宽度,它反映了计算机处理信息的一种能力。字和字长的长度可以一样,也可不一样。例如,在Intel微处理器中,从80386开始就至少都是32位机器了,即字长至少为32位,但其字的宽度都定义为16位,32位称为双字。
表示二进制信息存储容量时所用的单位要比字节或字大得多,主要有以下几种。


在描述距离、频率等数值时通常用10的幂次表示,因而在由时钟频率计算得到的总线带宽或外设数据传输率中,度量单位表示的也是10的幂次。为区分这种差别,本书中用K表示1024,用k表示1000,而其他前缀字母均为大写,表示的大小由其上下文决定。
由于程序需要对不同类型、不同长度的数据进行处理,所以,计算机中底层机器级的数据表示必须能够提供相应的支持。比如,需要提供不同长度的整数和不同长度的浮点数表示,相应地需要有处理单字节,双字节,4字节甚至是8字节整数的整数运算指令﹐以及能够处理4字节、8字节浮点数的浮点数运算指令等。
C语言支持多种格式的整数和浮点数表示。数据类型char表示单个字节,能用来表示单个字符,也可用来表示8位整数。类型int之前可加上 long 和 short,以提供不同长度的整数表示。表2.7给出了在典型的32位机器和64位的Compaq Alpha机器上C语言中数值数据类型的宽度。大多数32位机器使用“典型”方式。从表2.7可以看出,短整数为2个字节,普通int型整数为4个字节,而长整数的长度与机器字长的宽度相同。指针(例如一个声明为类型char *的变量)和长整数的宽度一样,也等于机器字长的宽度。一般机器都支持float和double两种类型的浮点数,分别对应IEEE 754单精度和双精度格式。
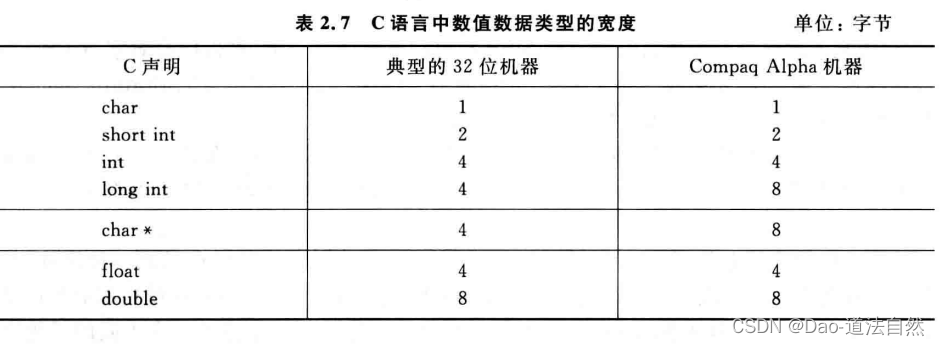
由此可见,同一类型的数据并不是所有机器都采用相同的数据宽度﹐分配的字节数随机器和编译器的不同而不同。
数据的存储和排列顺序
任何信息在计算机中用二进制编码后,得到的都是一串0/1序列,每8位构成一个字节,不同的数据类型具有不同的字节宽度。在计算机中存储数据时,数据从低位到高位可以按从左到右排列,也可以按从右到左排列。
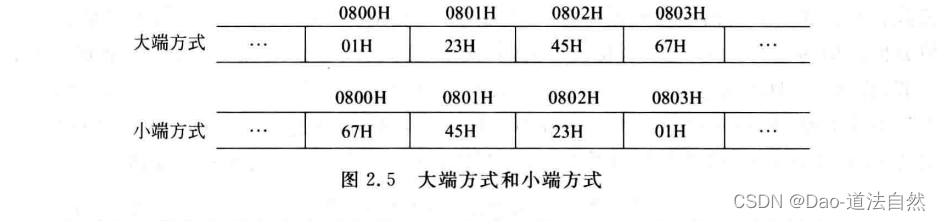
如果以字节为一个排列基本单位,那么LSB表示最低有效字节(Least SignificantByte),MSB表示最高有效字节(Most Significant Byte)。现代计算机基本上都采用字节编址方式,即对存储空间的存储单元进行编号时,每个地址编号中存放一个字节。计算机中许多类型的数据由多个字节组成,例如, int和 float型数据占用4个字节, double型数据占用8个字节等,而程序中对每个数据只给定一个地址。例如,在一个按字节编址的计算机中,假定int型变量i的地址为08 00H,i的机器数为01 23 45 67H,这4个字节01H、23H、45H,67H应该各有一个内存地址,那么﹐地址08 00H对应4个字节中的哪个字节的地址呢?这就是字节排列顺序问题。
在所有计算机中,多字节数据都被存放在连续的字节序列中。根据数据中各字节在连续字节序列中的排列顺序的不同,可有两种排列方式:大端( big endian)和小端( littleendian),如图所示。
数据校验码
数据在计算机内部进行计算、存取和传送过程中,由于元器件故障或噪音干扰等原因会出现差错。为了减少和避免这些错误,一方面要从计算机硬件本身的可靠性入手,在电路、电源、布线等各方面采取必要的措施,提高计算机的抗干扰能力;另一方面要采取相应的数据检错和校正措施,自动地发现并纠正错误。
目前为止提出的数据校验方法大多采用一种冗余校验的思想,即除原数据信息外,还增加若干位编码,这些新增的代码称为校验位。当数据被存入存储器或从源部件传输时,对数据M进行某种运算(用函数F来表示),以产生相应的代码P=F(M),这里Р就是校验位。这样原数据信息M和相应的校验位P一起被存储或传送。当数据被读出或传送到目标部件时,和数据信息一起被存储或传送的校验位也被得到,用于检错和纠错。假定读出后的数据为M',通过同样的运算F对M'也得到一个新的校验位P'=F(M'),假定原来被存储的校验位Р取出后其值为P" ,将校验位P与新生成的校验位P'进行某种比较,根据其比较结果确定是否发生了差错。比较的结果为以下3种情况之一:
- 没有检测到错误,得到的数据位直接传送出去。
- 检测到差错,并可以纠错。数据位和比较结果一起送入纠错器,然后将产生的正确的数据位传送出去。
- 检测到错误,但无法确认哪位出错,因而不能进行纠错处理,此时,报告出错情况。
常用数据校验方式有3种。奇偶校验根据数据的奇偶性变化来检错,只能检测奇数个错。海明校验是分组奇偶校验,SEC只能纠正一位错,SEC-DED可纠正一位错并检测两位错。循环冗余码校验通过某种数学运算在数据和校验位之间建立约定关系,它可以对较长数据块进行校验而不增加校验位开销,因此,主要用于对大批量数据的存储或传输校验。

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











