







知识星球
一.上节遗珠
1.链式哈希表的实现(LinkedHashMap)
上节我们讲了哈希表的原理,具体的代码实现可以到我的代码仓库去看看为✔✔✔哈希表的实现。这里我们紧接着探讨一下哈希表的变形,链式哈希表。
🥳上节中我们了解到了哈希表的底层其实就是一个数组,我们从main()函数传入key和value哈希函数将key转化成相应的数组下标,将key value放入到对应数组空间中。这也体现的哈希表的另一个名称 散列表它的存取和输出都是散乱的没有顺序。如果我们的需求是将HashMap以输入的顺序输出,基本的哈希表已经无法满足要求了。所以此时我们通过链表将输入的元素链起来。
import java.util.LinkedList;
/**
* 在学完哈希表后,发现他添加是索引是根据哈希值随意生成的所以
* 他的添加是十分混乱的,输出也不能向我们预想的根据输入的顺序输出值
* 所以我们linkedMap去将节点根据先后添加的顺序进行串起来
*/
public class LinkedMap<K,V> extends HashMap<K,V> {
//新增首尾指针实现双段单链表
private LinkedNode<K,V> first;
private LinkedNode<K,V> last;
@Override
public void clear() {
super.clear();
//仅仅是父类的删除是远远不够的,因为那只是给红黑树层面的删除
//这里一定不要忘记销毁头尾,因为如果不销毁,他们之间的串联关系还是存在的
//导致空间都不会释放
first=null;
last=null;
}
//想要其按照输入顺序输出,所以还要重写遍历方法
@Override
public void traversal(Visitor<K, V> visitor) {
//由于规定输出为输入顺序所以遍历应该遵从链表的顺序
if(visitor==null)
{
return;
}
LinkedNode<K,V> node=first;
while(node!=null) {
if (visitor.visit(node.key, node.value)) return;
//next是链式哈希节点特有的
node = node.next;
}
}
/**
* 删除需要重新进行调整,因为之前的删除是从红黑树的角度断开了红黑树上之间的节点
* 但是链表之间的联系是依然存在的所以在打印额时候就会出现错误
* .那么我直接重写afterRemove不行吗?
* 不行:1.afterRemove传入的不一定是就是要删除的节点
* 2.afterRemove()有漏网之鱼
*
* 考虑到BUG1:对于链表删除一个节点就是确切的删除该节点
* 但对于红黑树度为2的节点删除的其实不是本身这个节点,而是删除它的后继节点
* bug2:删除时,给红黑树删除是后继节点覆盖,但是链表则是将这个节点直接删除
* 所以,打印顺序是不同的,所以补救:将删除节点node与它的前驱或者后继在链表中的顺序进行交换
*/
@Override
protected void afterRemove1(Node<K,V>willRemove,Node<K, V> newRemove) {
//交换当前要删除的和实际真正要删除的进行调整
LinkedNode<K,V> node1=(LinkedNode<K,V>)newRemove;
LinkedNode<K,V> node2=(LinkedNode<K,V>)willRemove;
//先交换prev
LinkedNode<K,V> tmp=node1.prev;
node1.prev=node2.prev;
node2.prev=tmp;
//看看交换后是不是到了头节点
if(node1.prev==null)
{
first=node1;
}else{
//把next线串上
node1.prev.next=node1;
}
if(node2.prev==null)
{
first=node2;
}else{
//把next线串上
node2.prev.next=node2;
}
//到此两个节点前后两根线都已经交换并且串上了
//以下串接后面两根线
tmp=node1.next;
node1.next=node2.next;
node1.next=tmp;
if(node1.next==null)
{
last=node1;
}else{
node1.next.prev=node1;
}
if(node2.next==null)
{
last=node2;
}else{
node2.next.prev=node2;
}
//-------------以上是交换节点------------------
LinkedNode<K,V> prev=node1.prev;
LinkedNode<K,V> next=node1.next;
//断开链表的线
if(prev==null)
{
first=next;
}else{
prev.next=next;
}
if(next==null)
{
last=prev;
}else{
next.prev=prev;
}
}
/**
* 因为希望所有创建的节点都是LinkedNode类型,所以需要在父类创建 创建节点的接口
* 因为每创建一个节点必然会调用creatNode所以
* 我们在creatNode里串接链表的线
*/
@Override
protected Node<K, V> creatNode(K key, V value, Node<K, V> parent) {
//注意这里的一些类型转化问题:暗含向上转型
LinkedNode<K,V> node=new LinkedNode<>(key,value,parent);
if(first==null)
{
first=node;
last=node;
}else{
//不是第一次添加将其串接到链表尾部
last.next=node;
node.prev=last;
last=node;
}
return node;
}
private static class LinkedNode<K,V> extends HashMap.Node<K,V> {
LinkedNode<K,V> prev;
LinkedNode<K,V> next;
public LinkedNode(K key, V value, HashMap.Node<K,V> parent) {
super(key, value, parent);
}
}
}
二. 二叉堆的引入背景
假如现在要实现设计一种数据结构,用来存放整数,要求提供 3 个接口
1.添加元素
2.获取最大值
3.删除最大值
针对这个问题其实实现的方式有很多种:
 这种问题有一种十分合适的方法:用二叉堆实现
这种问题有一种十分合适的方法:用二叉堆实现
用二叉堆实现这个需求的复杂度为:获取最大值:O(1)、删除最大值:O(logn)、添加元素:O(logn)
这种方法不会造成过大的复杂度,而且不会显得”杀鸡用了牛刀“
三.二叉堆的定义与性质
◼ 堆(Heap)也是一种树状的数据结构(不要跟内存模型中的“堆空间”混淆),常见的堆实现有
二叉堆(Binary Heap,完全二叉堆)
多叉堆(D-heap、D-ary Heap)
索引堆(Index Heap)
二项堆(Binomial Heap)
斐波那契堆(Fibonacci Heap)
左倾堆(Leftist Heap,左式堆)
斜堆(Skew Heap)
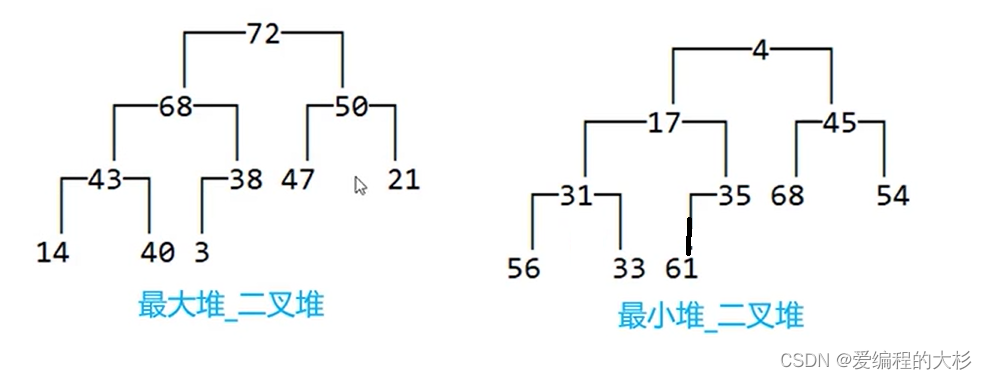
这里我们主要讨论二叉堆,二叉堆又分为最大堆和最小堆。
最大堆是任意一个节点的元素都大于它的子节点,最小堆是任意一个节点的元素都小于它的节点元素。
四.二叉堆实现的接口
◼ int size(); // 元素的数量
◼ boolean isEmpty(); // 是否为空
◼ void clear(); // 清空
◼ void add(E element); // 添加元素
◼ E get(); // 获得堆顶元素
◼ E remove(); // 删除堆顶元素
◼ E replace(E element); // 删除堆顶元素的同时插入一个新元素
五.二叉堆的本质与性质
二叉堆的本质是一个完全二叉树,所以也叫完全二叉堆。
鉴于二叉树的一些特性,我们二叉堆的底层用数组来实现
二叉堆因为底层是用数组的形式完全二叉树的思想实现的所以二叉堆的性质与完全二叉树的性质是一样的。
◼ 索引 i 的规律( n 是元素数量)
如果 i = 0 ,它是根节点
如果 i > 0 ,它的父节点的索引为 floor( (i – 1) / 2 )
如果 2i + 1 ≤ n – 1,它的左子节点的索引为 2i + 1
如果 2i + 1 > n – 1 ,它无左子节点
如果 2i + 2 ≤ n – 1 ,它的右子节点的索引为 2i + 2
如果 2i + 2 > n – 1 ,它无右子节点
六.最大堆的添加
我们以下图的添加为为例,将80添加到数组的的尾部在二叉堆中显然已经违背了最大堆的性质.
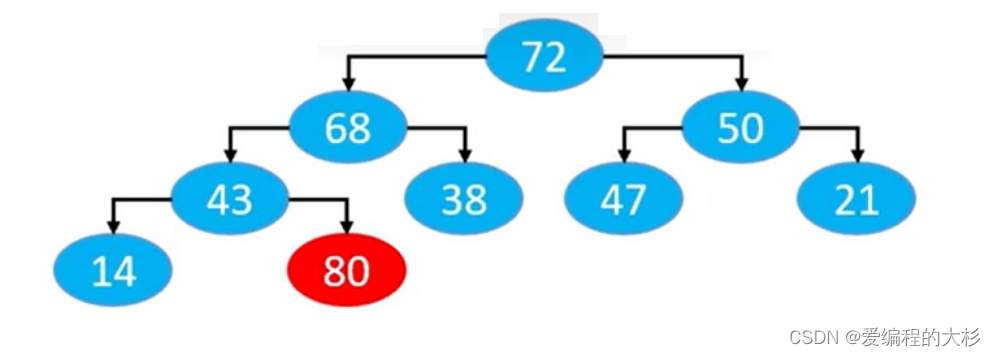
所以我们应该设计上滤方法将80按照大小放在指定位置.
添加:
public void add(E element) {
elementCheckNull(element);
ensureCapacity(size+1);
elements[size++]=element;
//传入上滤节点的下标(也就是新添加的节点)
shiftUp(size-1);
}
上滤
对于上滤操作我们需要找出需要上滤节点的父节点,记录当前节点的值,比较当前节点与父节点的大小,
如果当前节点比父节点放到大,则父节点向下覆盖当前节点的值.然后继续向上检索.
直到当前节点的值小于父节点的值.
private void shiftUp(int index)
{
//以数组的角度理解数的上滤
//记录当前节点的值
E element=elements[index];
while(index>0){
//根据完全二叉堆的性质找出父节点的下标
int parentIndex=(index-1)>>1;
E parent =elements[parentIndex];
//比较子父节点的值
if(compare(parent,element)>=0)
{
break;
}
//这样上滤可以避免避免过多的交换操作
//父节点下来(走到这里就是父节点比子节点小)
elements[index]=parent;
//索引index指向父节点索引,继续向上检索
index=parentIndex;
}
//如果本身新添加节点后子节点就小于等于父节点,直接添加或者覆盖
elements[index]=element;
}
抽象类实现共性部分
mport java.util.Comparator;
@SuppressWarnings("unchecked")
public class abstractHeap<E>{
protected int size;
Comparator<E> comparator;
protected int compare(E e1,E e2){
return comparator!=null?comparator.compare(e1,e2):((Comparable<E>)e1).compareTo(e2);
}
public abstractHeap(Comparator<E> comparator) {
this.comparator = comparator;
}
public abstractHeap() {
this(null);
}
public int size() {
return size;
}
public boolean isEmpty() {
return size==0;
}
}
七.最大堆的删除堆顶元素
最大堆删除堆顶元素就是先找到 堆底元素(也就是数组的最后一个元素) 覆盖堆顶元素,然后删除堆尾元素,让堆顶元素下滤.
public E remove() {
empty();
int lastIndex=size--;
elements[0]=elements[lastIndex];
elements[lastIndex]=null;
shiftDown(0);
return null;
}
public void empty()
{
if(this.size==0)
{
throw new UnsupportedOperationException("数组为空异常");
}
}
下滤
下滤和上滤的逻辑相似,就是记录堆顶元素然后与自己最大的子节点进行比较如果当前节点比子节点小则子节点覆盖当前节点,继续向下检索.直到当前节点比大于子节点.
注意叶子节点没有子节点是不能下滤的所以,下滤最终是到最后一个非叶子节点.根据二叉堆的性质可以知道第一个叶子节点的下标为size(节点数量)/2.
private void shiftDown(int index){
//下滤:注意:如果下滤的节点是叶子节点没有子节点所以没必要下滤
//完全二叉树第一个叶子节点的下标为size/2;
int half=size>>1;
//第一个叶子节点的索引=非叶子节点的数量
E element = elements[index];
while(index<half)//第一个叶子节点的索引
{
//现在的任务:选出最大的子节点
//默认为左子节点
int childIndex=(index<<1)+1;
E child=elements[childIndex];
int rightIndex=childIndex+1;
if(rightIndex<size&&compare(elements[rightIndex],child)>0)
{
child=elements[rightIndex];
childIndex=rightIndex;
}
if(compare(elements[index],child)>0){
//已经符合最大堆的性质了吗,不用在下滤了
break;
}
//把更大的数放到上面
elements[index]=child;
index=childIndex;
}
elements[index]=element;
}
八.replace()实现
replace()的功能是删除堆顶元素的同时插入一个新元素
// 删除堆顶元素的同时插入一个新元素
public E replace(E element) {
elementCheckNull(element);
E root =null;
if(size==0)
{
elements[0]=element;
size++;
}else{
//root记录一开始堆顶的元素
root=elements[0];
//直接覆盖堆顶元素,就默认删了
elements[0]=element;
//此时堆顶元素是心添加的节点,直接让他执行下滤操作
shiftDown(0);
}
//返回最初的堆顶的元素
return root;
}
九.批量建堆
1.批量建堆的实现
如果给定一个顺序十分混乱的数组,如何快速实现堆结构(快速建堆)。对于这个需求主要有三种方法:
1、方法一:直接利用已经写好的最大堆代码的添加方法将数组元素直接添加的最大堆(构建一个最大堆)
public static void main(String[] args) {
BinaryHeap<Integer> bin=new BinaryHeap<Integer>();
int [] date={13,423,1,2321,1,2,423,43};
for (int i = 0; i <date.length ; i++) {
bin.add(date[i]);
}
System.out.println(bin);
}
方法二:自上而下的上滤
从上到下进行检索,让更大的元素不断上滤直到达到最大堆的要求
//数组第一个元素也就是根节点没必要上滤,所以从第二个元素开始进行检索上滤操作
for (int i = 1; i < size; i++) {
siftUp(i);
}
方法三:自下而上的下滤
叶子节点没有必要进行下滤操作,索引从第一个非叶子节点直接向上检索进行下滤
for (int i = (size >> 1) - 1; i >= 0; i--) {
siftDown(i);
}
2.批量建堆方法效率对比
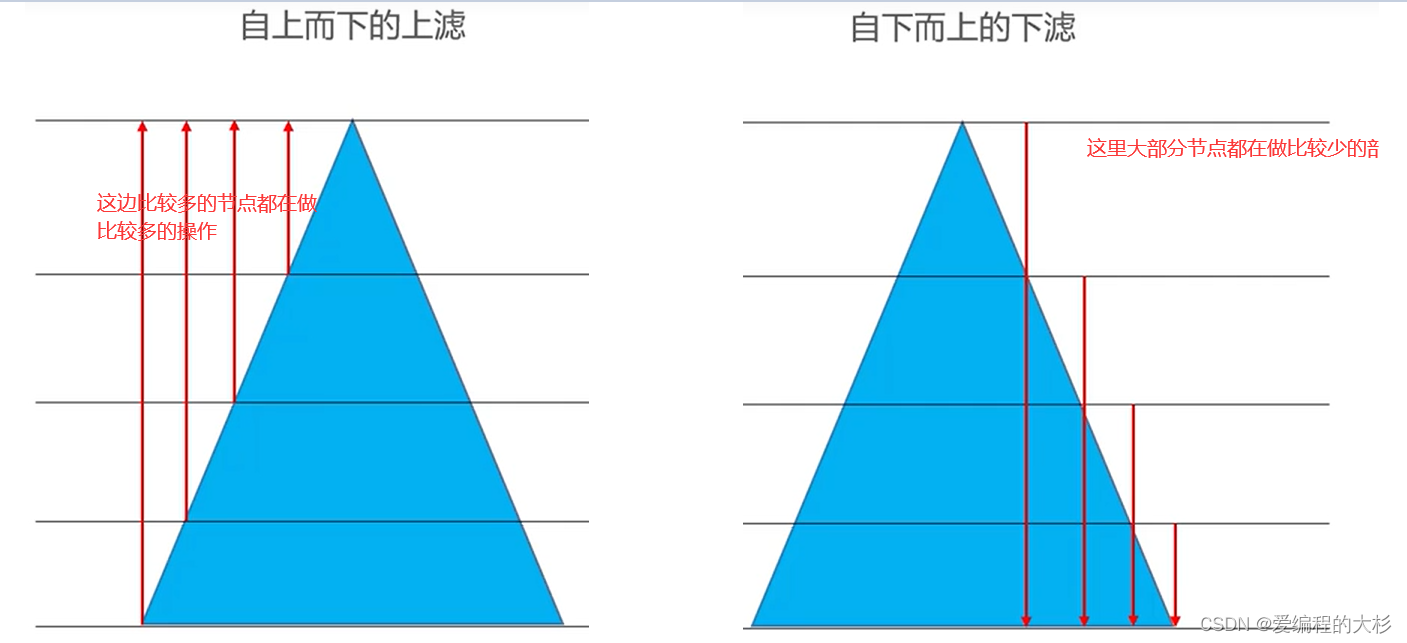
如图是二叉堆的结构,由这张图中我们可以得出。二叉堆的结构是上尖下宽的所以越往下走节点数越多,对于自上而下的上滤,大多数节点都在做比较多的操作(图中表示为从下到上的箭头很长)。而对于自下而上的下滤,根据图中的箭头可以得知大多数的节点都在执行比较少的操作,所以自下而上的下滤显然效率更高。
十.Top K问题
TopK问题又叫海量数据处理问题:
例如:从n个数中找出最大的前k个数(k远远小于n)
我们用小顶堆实现这个需求:
我们先将前K个元素直接放入小顶堆。然后检索k个元素后面的元素,如果比堆顶元素大则直接执行replace()删除堆顶元素,新的元素入堆。(因为堆顶元素就是最小的元素如果元素比最小的元素大则入堆,循环往复最后剩下的就是前k个最大的元素)
// 找出最大的前k个数
int k = 3;
Integer[] data = {51, 30, 39, 92, 74, 25, 16, 93,
91, 19, 54, 47, 73, 62, 76, 63, 35, 18,
90, 6, 65, 49, 3, 26, 61, 21, 48};
for (int i = 0; i < data.length; i++) {
if (heap.size() < k) { // 前k个数添加到小顶堆
heap.add(data[i]); // logk
} else if (data[i] > heap.get()) { // 如果是第k + 1个数,并且大于堆顶元素
heap.replace(data[i]); // logk
}
}
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











