






Spark笔记
一、Spark与MapReduce的区别
1、Spark的运行速度比MR快
-
spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的。
-
Spark在处理数据时构建了DAG有向无环图,减少了shuffle和数据落地磁盘的次数
-
spark是粗粒度申请资源指的是在提交资源时,spark会提前向资源管理器(yarn,mess)将资源申请完毕,如果申请不到资源就等待,如果申请到就运行task任务,而不需要task再去申请资源。
MapReduce是细粒度申请资源,提交任务,task自己申请资源自己运行程序,自己释放资源,虽然资源能够充分利用,但是这样任务运行的很慢。
2、Spark的代码比MR简洁
3、Spark的稳定性没有MR好,当数据达到TB级别以上的时候,容易出现内存溢出错误
二、Spark的简介
1、什么是Spark
- Apache Spark 是一个用于大规模数据处理的快速通用计算引擎,最初由加州大学伯克利分校的 AMPLab 开发,于 2010 年开源。Spark 提供了高效的分布式数据处理功能,支持多种数据处理任务,包括批处理、实时流处理、机器学习和图形处理等。
2、Spark的组件
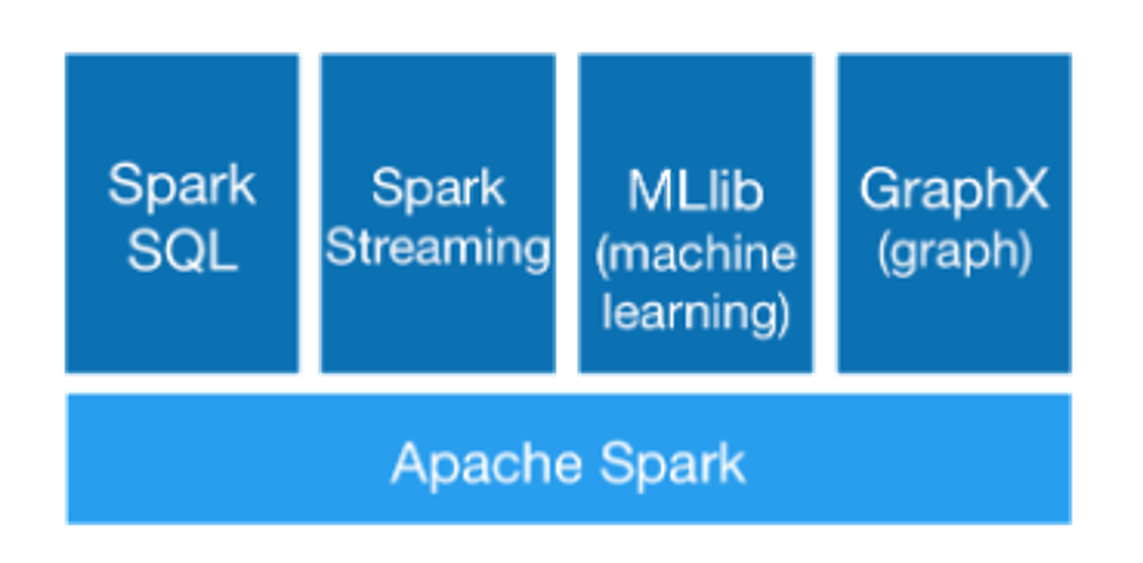
- **Spark Core:**包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:用于处理结构化数据。它允许用户通过SQL查询进行数据分析,并能将SQL查询和Spark的程序结合起来使用,提供高效的数据处理能力。
- Spark Streaming:用于实时数据流处理。它能够处理实时的数据流,支持将数据分成微批次进行处理,并与其他Spark组件无缝集成。
- MLlib (Machine Learning Library):用于机器学习。MLlib提供了一组常用的机器学习算法和工具,如分类、回归、聚类、协同过滤等,帮助用户在Spark上进行大规模机器学习任务。
- GraphX:用于图计算。GraphX是Spark的图计算库,提供了一系列API用于构建、操作和计算图数据结构,并支持图算法如PageRank、最短路径等。
3、Spark的运行模式
-
Standalone模式:
- 概述:Spark自带的集群管理模式,适用于小型集群。
- 特点:易于配置和设置,不依赖外部的集群管理工具。所有资源调度和任务管理都由Spark自身完成。
- 使用场景:适用于测试和开发环境,以及资源管理需求不高的小型集群。
/** * 将项目打包放到spark集群中使用standalone模式运行 * standalone client * spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar 100 * * standalone cluster * spark-submit --class com.shujia.core.Demo17SparkStandaloneSubmit --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 --deploy-mode cluster spark-1.0.jar 100 * */ -
YARN模式:
- 概述:使用Hadoop的YARN(Yet Another Resource Negotiator)作为资源管理器。
- 特点:与Hadoop生态系统深度集成,能够共享Hadoop集群的资源,支持多租户和高资源利用率。
- 使用场景:适用于已经有Hadoop集群的环境,特别是需要与Hadoop组件(如HDFS、Hive)紧密集成的情况。
- –master yarn-client
spark on yarn client模式 日志在本地输出,一班用于上线前测试
注意:如果在本地大量使用client模式提交任务,会导致本地节点网卡流量剧增
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client spark-examples_2.12-3.1.3.jar 100- –master yarn-cluster
spark on yarn cluster模式 Driver在yarn中随机的一个节点中启动,在本地看不到详细的执行日志,一般上线使用(每日调度使用)
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster spark-examples_2.12-3.1.3.jar 100 -
Mesos模式:
- 概述:使用Apache Mesos作为资源管理和调度框架。
- 特点:提供高度可扩展的资源管理,能够支持多种不同的应用框架(如Hadoop、Storm)在同一集群中运行。
- 使用场景:适用于需要在一个集群中运行多种不同的大数据处理框架的情况,提供灵活的资源共享和调度。
-
Kubernetes模式:
- 概述:使用Kubernetes作为集群管理工具,进行容器化部署和调度。
- 特点:利用Kubernetes的容器编排和管理能力,提供高可用性和易于扩展的部署方案。
- 使用场景:适用于已经采用Kubernetes进行容器化管理的环境,特别是需要微服务架构和动态资源分配的情况。
-
Local模式:
- 概述:在单机上运行,通常用于开发和调试。
- 特点:无需集群配置,运行在单个节点上,可以在本地快速进行开发和测试。
- 使用场景:适用于开发、调试和小规模数据处理任务,不适合生产环境的大规模数据处理。
4、Spark的连接
- 要编写 Spark 应用程序,您需要添加对 Spark 的 Maven 依赖项。Spark 可通过 Maven Central 获取:
groupId = org.apache.spark
artifactId = spark-core_2.12
version = 3.1.3
- 如果您希望访问 HDFS 集群,则需要
hadoop-client为您的 HDFS 版本添加依赖项。
groupId = org.apache.hadoop
artifactId = hadoop-client
version = <your-hdfs-version>
5、Spark的初始化
Spark 程序必须做的第一件事是创建一个SparkContext对象,该对象告诉 Spark 如何访问集群。要创建,SparkContext您首先需要构建一个包含有关应用程序的信息的SparkConf对象。
每个 JVM 只能有一个 SparkContext 处于活动状态。stop()在创建新的 SparkContext 之前,必须先激活 SparkContext。
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
三、RDD(弹性的分布式数据集)
1、什么是RDD
- Spark 提供的主要抽象是弹性分布式数据集(RDD),它是跨集群节点分区的元素集合,可以并行操作。
- 弹性分布式数据集
- 弹性:RDD将来在计算的时候,其中的数据可以是很大,也可以是很小
- 分布式:数据可以分布在多台服务器中,RDD中的分区来自于block块,而今后的block块会来自不同的datanode
- 数据集:RDD自身是不存储数据的,只是一个代码计算逻辑,今后触发作业执行的时候,数据会在RDD之间流动
2、RDD的五大特性
-
RDD是由一组的分区构成的,默认一个block对应一个分区
-
函数(算子)是作用在分区上的
-
RDD之间存在依赖关系,因为有了依赖关系,将整个作业划分了一个一个stage阶段,sumNum(stage) = Num(宽依赖) + 1
-
宽依赖
后一个RDD中分区数据来自于前一个RDD中的多个分区数据 1对多的关系 会产生shuffle
-
窄依赖
后一个RDD中分区数据对应前一个RDD中的一个分区数据 1对1的关系
-
**总结:**窄依赖的分区数是不可以改变,取决于第一个RDD分区数,宽依赖可以在产生shuffle的算子上设置分区数
-
-
分区类的算子只能作用在kv格式的RDD上,例如:reducebyKey,groupByKey, join
-
spark为task的执行提供了最佳执行位置,移动计算而不是移动数据,spark会尽量将task发送到数据所在的节点去执
3、算子
- 分为两大类转换算子 (Transformations) 和 行动算子(Actions)
3.1、Transformations
3.1.1、Map
- 通过将源中的每个元素传递给函数func,返回一个新的分布式数据集。
object Demo3Map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("map算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
/**
* map算子:将rdd中的数据,一条一条的取出来传入到map函数中,map会返回一个新的rdd,map不会改变总数据条数
*/
val splitRDD: RDD[List[String]] = studentRDD.map((s: String) => {
println("============数加防伪码================")
s.split(",").toList
})
// splitRDD.foreach(println)
}
}
3.1.2、Filter
- 返回通过选择源数据中函数返回true的元素而形成的新数据集。
object Demo4Filter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("map算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
/**
* filter: 过滤,将RDD中的数据一条一条取出传递给filter后面的函数,如果函数的结果是true,该条数据就保留,否则丢弃
*
* filter一般情况下会减少数据的条数
*/
val filterRDD: RDD[String] = studentRDD.filter((s: String) => {
val strings: Array[String] = s.split(",")
"男".equals(strings(3))
})
filterRDD.foreach(println)
}
}
3.1.3、FlatMap
- 类似于map,但每个输入项可以映射到0个或多个输出项(因此func应该返回一个Seq而不是单个项)。
object Demo5flatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("flatMap算子演示")
val context = new SparkContext(conf)
//====================================================
val linesRDD: RDD[String] = context.textFile("spark/data/words.txt")
/**
* flatMap算子:将RDD中的数据一条一条的取出传递给后面的函数,函数的返回值必须是一个集合。最后会将集合展开构成一个新的RDD
*/
val wordsRDD: RDD[String] = linesRDD.flatMap((line: String) => line.split("\\|"))
wordsRDD.foreach(println)
}
}
3.1.4、Sample
- 使用给定的随机数生成器种子,对数据的一小部分进行采样,无论是否进行替换
object Demo6sample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("flatMap算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
/**
* sample算子:从前一个RDD的数据中抽样一部分数据
*
* 抽取的比例不是正好对应的,在抽取的比例上下浮动 比如1000条抽取10% 抽取的结果在100条左右
*/
val sampleRDD: RDD[String] = studentRDD.sample(withReplacement = true, 0.1)
sampleRDD.foreach(println)
}
}
3.1.5、GroupBy
- 按照指定的字段进行分组,返回的是一个键是分组字段,值是一个存放原本数据的迭代器的键值对 返回的是kv格式的RDD, key: 是分组字段,value: 是spark中的迭代器,迭代器中的数据,不是完全被加载到内存中计算,迭代器只能迭代一次,groupBy会产生shuffle
object Demo7GroupBy {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("groupBy算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
val splitRDD: RDD[Array[String]] = studentRDD.map((s: String) => s.split(","))
//需求:求出每个班级平均年龄
//使用模式匹配的方式取出班级和年龄
val clazzWithAgeRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, age: String, _, clazz: String) => (clazz, age.toInt)
}
/**
* groupBy:按照指定的字段进行分组,返回的是一个键是分组字段,值是一个存放原本数据的迭代器的键值对 返回的是kv格式的RDD
*
* key: 是分组字段
* value: 是spark中的迭代器
* 迭代器中的数据,不是完全被加载到内存中计算,迭代器只能迭代一次
*
* groupBy会产生shuffle
*/
//按照班级进行分组
//val stringToStudents: Map[String, List[Student]] = stuList.groupBy((s: Student) => s.clazz)
val kvRDD: RDD[(String, Iterable[(String, Int)])] = clazzWithAgeRDD.groupBy(_._1)
val clazzAvgAgeRDD: RDD[(String, Double)] = kvRDD.map {
case (clazz: String, itr: Iterable[(String, Int)]) =>
//CompactBuffer((理科二班,21), (理科二班,23), (理科二班,21), (理科二班,23), (理科二班,21), (理科二班,21), (理科二班,24))
//CompactBuffer(21,23,21,23,21,21,24)
val allAge: Iterable[Int] = itr.map((kv: (String, Int)) => kv._2)
val avgAge: Double = allAge.sum.toDouble / allAge.size
(clazz, avgAge)
}
clazzAvgAgeRDD.foreach(println)
while (true){
}
}
}
3.1.6、GroupByKey
- 当对(K, V)对的数据集调用时,返回(K, Iterable)对的数据集。注意:如果您分组是为了对每个键执行聚合(例如求和或求平均值),那么使用reduceByKey或aggregateByKey将产生更好的性能。注意:默认情况下,输出中的并行度级别取决于父RDD的分区数量。您可以传递一个可选的numPartitions参数来设置不同数量的任务。
object Demo8GroupByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("groupByKey算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
val splitRDD: RDD[Array[String]] = studentRDD.map((s: String) => s.split(","))
//需求:求出每个班级平均年龄
//使用模式匹配的方式取出班级和年龄
val clazzWithAgeRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, age: String, _, clazz: String) => (clazz, age.toInt)
}
/**
* groupByKey: 按照键进行分组,将value值构成迭代器返回
* 将来你在spark中看到RDD[(xx, xxx)] 这样的RDD就是kv键值对类型的RDD
* 只有kv类型键值对RDD才可以调用groupByKey算子
*
*/
val kvRDD: RDD[(String, Iterable[Int])] = clazzWithAgeRDD.groupByKey()
val clazzAvgAgeRDD: RDD[(String, Double)] = kvRDD.map {
case (clazz: String, ageItr: Iterable[Int]) =>
(clazz, ageItr.sum.toDouble / ageItr.size)
}
clazzAvgAgeRDD.foreach(println)
while (true){
}
/**
* groupBy与groupByKey的区别(spark的面试题)
* 1、代码上的区别:任意一个RDD都可以调用groupBy算子,只有kv类型的RDD才可以调用groupByKey
* 2、groupByKey之后产生的RDD的结构比较简单,方便后续处理
* 3、groupByKey的性能更好,执行速度更快,因为groupByKey相比较与groupBy算子来说,shuffle所需要的数据量较少
*/
}
}
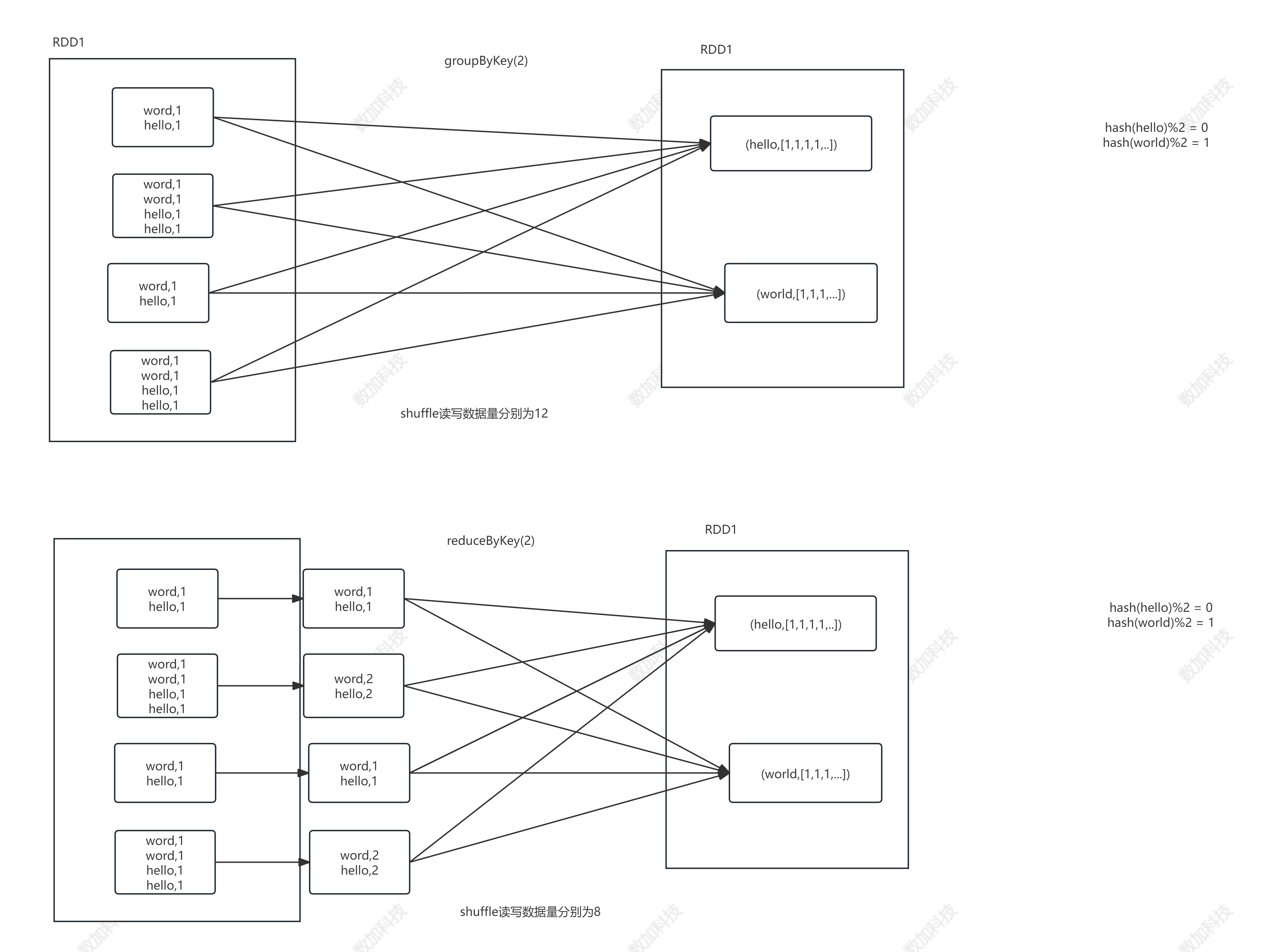
3.1.7、ReduceByKey
- 当在(K, V)对的数据集上调用时,返回(K, V)对的数据集,其中每个键的值使用给定的reduce函数func聚合,该函数必须是类型(V,V) => V。与groupByKey一样,reduce任务的数量可以通过可选的第二个参数配置。
object Demo9ReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("reduceByKey算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
val splitRDD: RDD[Array[String]] = studentRDD.map((s: String) => s.split(","))
//求每个班级的人数
val clazzKVRDD: RDD[(String, Int)] = splitRDD.map {
case Array(_, _, _, _, clazz: String) => (clazz, 1)
}
/**
* 利用groupByKey实现
*/
// val kvRDD: RDD[(String, Iterable[Int])] = clazzKVRDD.groupByKey()
// val clazzAvgAgeRDD: RDD[(String, Double)] = kvRDD.map {
// case (clazz: String, n: Iterable[Int]) =>
// (clazz, n.sum)
// }
// clazzAvgAgeRDD.foreach(println)
/**
* 利用reduceByKey实现:按照键key对value值直接进行聚合,需要传入聚合的方式
* reduceByKey算子也是只有kv类型的RDD才能调用
*
*
*/
val countRDD: RDD[(String, Int)] = clazzKVRDD.reduceByKey((x: Int, y: Int) => x + y)
countRDD.foreach(println)
// clazzKVRDD.groupByKey()
// .map(kv=>(kv._1,kv._2.sum))
// .foreach(println)
while (true){
}
/**
* reduceByKey与groupByKey的区别
* 1、reduceByKey比groupByKey在map端多了一个预聚合的操作,预聚合之后的shuffle数据量肯定是要少很多的,性能上比groupByKey要好
* 2、从灵活角度来看,reduceByKey并没有groupByKey灵活
* 比如reduceByKey无法做方差,groupByKey后续可以完成
*
*/
}
}
- ReduceByKey和GroupByKey的区别
3.1.8、Union
- 返回一个新数据集,其中包含源数据集和参数中元素的并集。
object Demo10Union {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Union算子演示")
val context = new SparkContext(conf)
//====================================================
val w1RDD: RDD[String] = context.textFile("spark/data/ws/w1.txt") // 1
val w2RDD: RDD[String] = context.textFile("spark/data/ws/w2.txt") // 1
/**
* union:上下合并两个RDD,前提是两个RDD中的数据类型要一致,合并后不会对结果进行去重
*
* 注:这里的合并只是逻辑层面上的合并,物理层面其实是没有合并
*/
val unionRDD: RDD[String] = w1RDD.union(w2RDD)
println(unionRDD.getNumPartitions) // 2
unionRDD.foreach(println)
while (true){
}
}
}
3.1.9、Join
- 当对类型为(K, V)和(K, W)的数据集调用时,返回(K, (V, W))对的数据集,其中每个键的所有元素对。通过支持外部连接
leftOuterJoin,rightOuterJoin, andfullOuterJoin.
object Demo11Join {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Join算子演示")
val context = new SparkContext(conf)
//====================================================
//两个kv类型的RDD之间的关联
//通过scala中的集合构建RDD
val rdd1: RDD[(String, String)] = context.parallelize(
List(
("1001", "小平"),
("1002", "义杰"),
("1003", "昊宇"),
("1004", "旭"),
("1005", "大牛"),
("1006","权")
)
)
val rdd2: RDD[(String, String)] = context.parallelize(
List(
("1001", "崩坏"),
("1002", "原神"),
("1003", "王者"),
("1004", "修仙"),
("1005", "学习"),
("1007", "敲代码")
)
)
/**
* 内连接:join
* 左连接:leftJoin
* 右连接:rightJoin
* 全连接:fullJoin
*/
//内连接
// val innerJoinRDD: RDD[(String, (String, String))] = rdd1.join(rdd2)
// //加工一下RDD
// val innerJoinRDD2: RDD[(String, String, String)] = innerJoinRDD.map {
// case (id: String, (name: String, like: String)) => (id, name, like)
// }
// innerJoinRDD2.foreach(println)
//左连接
val leftJoinRDD: RDD[(String, (String, Option[String]))] = rdd1.leftOuterJoin(rdd2)
//加工一下RDD
val leftJoinRDD2: RDD[(String, String, String)] = leftJoinRDD.map {
case (id: String, (name: String, Some(like))) => (id, name, like)
case (id: String, (name: String, None)) => (id, name, "无爱好")
}
leftJoinRDD2.foreach(println)
println("=================================")
//右连接自己试
//TODO:自己试右连接
//全连接
val fullJoinRDD: RDD[(String, (Option[String], Option[String]))] = rdd1.fullOuterJoin(rdd2)
//加工一下RDD
val fullJoinRDD2: RDD[(String, String, String)] = fullJoinRDD.map {
case (id: String, (Some(name), Some(like))) => (id, name, like)
case (id: String, (Some(name), None)) => (id, name, "无爱好")
case (id: String, (None, Some(like))) => (id, "无姓名", like)
}
fullJoinRDD2.foreach(println)
}
}
3.1.10、MapValues
- 作用在kv型RDD上,只对值进行处理,键不动
object Demo11Join {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Join算子演示")
val context = new SparkContext(conf)
//====================================================
//两个kv类型的RDD之间的关联
//通过scala中的集合构建RDD
val rdd1: RDD[(String, String)] = context.parallelize(
List(
("1001", "尚平"),
("1002", "丁义杰"),
("1003", "徐昊宇"),
("1004", "包旭"),
("1005", "朱大牛"),
("1006","汪权")
)
)
val rdd2: RDD[(String, String)] = context.parallelize(
List(
("1001", "崩坏"),
("1002", "原神"),
("1003", "王者"),
("1004", "修仙"),
("1005", "学习"),
("1007", "敲代码")
)
)
/**
* 内连接:join
* 左连接:leftJoin
* 右连接:rightJoin
* 全连接:fullJoin
*/
//内连接
// val innerJoinRDD: RDD[(String, (String, String))] = rdd1.join(rdd2)
// //加工一下RDD
// val innerJoinRDD2: RDD[(String, String, String)] = innerJoinRDD.map {
// case (id: String, (name: String, like: String)) => (id, name, like)
// }
// innerJoinRDD2.foreach(println)
//左连接
val leftJoinRDD: RDD[(String, (String, Option[String]))] = rdd1.leftOuterJoin(rdd2)
//加工一下RDD
val leftJoinRDD2: RDD[(String, String, String)] = leftJoinRDD.map {
case (id: String, (name: String, Some(like))) => (id, name, like)
case (id: String, (name: String, None)) => (id, name, "无爱好")
}
leftJoinRDD2.foreach(println)
println("=================================")
//右连接自己试
//TODO:自己试右连接
//全连接
val fullJoinRDD: RDD[(String, (Option[String], Option[String]))] = rdd1.fullOuterJoin(rdd2)
//加工一下RDD
val fullJoinRDD2: RDD[(String, String, String)] = fullJoinRDD.map {
case (id: String, (Some(name), Some(like))) => (id, name, like)
case (id: String, (Some(name), None)) => (id, name, "无爱好")
case (id: String, (None, Some(like))) => (id, "无姓名", like)
}
fullJoinRDD2.foreach(println)
}
}
3.1.11、MapPartitions
- 与map类似,但在RDD的每个分区(块)上分别运行,因此在类型为T的RDD上运行时,func必须为类型Iterator => Iterator。
object Demo14mapPartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("mapPartition算子演示")
val context = new SparkContext(conf)
//====================================================
//需求:统计总分年级排名前10的学生的各科分数
//读取分数文件数据
val scoreRDD: RDD[String] = context.textFile("spark/data/ws/*") // 读取数据文件
println(scoreRDD.getNumPartitions)
/**
* mapPartition: 主要作用是一次处理一个分区的数据,将一个分区的数据一个一个传给后面的函数进行处理
*
* 迭代器中存放的是一个分区的数据
*/
// val mapPartitionRDD: RDD[String] = scoreRDD.mapPartitions((itr: Iterator[String]) => {
//
// println(s"====================当前处理的分区====================")
// //这里写的逻辑是作用在一个分区上的所有数据
// val words: Iterator[String] = itr.flatMap(_.split("\\|"))
// words
// })
// mapPartitionRDD.foreach(println)
scoreRDD.mapPartitionsWithIndex{
case (index:Int,itr: Iterator[String]) =>
println(s"当前所处理的分区编号是:${index}")
itr.flatMap(_.split("\\|"))
}.foreach(println)
}
}
3.2、Actions
3.2.1、reduce(func)
- 使用函数func(接受两个参数并返回一个参数)聚合数据集的元素。函数应该是可交换的和可关联的,这样才能正确地并行计算。
3.2.2、collect()
- 在驱动程序中以数组的形式返回数据集的所有元素。这通常在过滤器或其他返回足够小的数据子集的操作之后非常有用。
object Demo15Actions {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Action算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
/**
* 转换算子:transformation 将一个RDD转换成另一个RDD,转换算子是懒执行的,需要一个action算子触发执行
*
* 行动算子(操作算子):action算子,触发任务执行。一个action算子就会触发一次任务执行
*/
println("$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$")
val studentsRDD: RDD[(String, String, String, String, String)] = studentRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
println("**************************** 数加防伪码 ^_^ ********************************")
(id, name, age, gender, clazz)
}
println("$$$$$$$$$$$$$$$$$$$$$$***__***$$$$$$$$$$$$$$$$$$$$$$$$$")
// foreach其实就是一个action算子
// studentsRDD.foreach(println)
// println("="*100)
// studentsRDD.foreach(println)
// while (true){
//
// }
/**
* collect()行动算子 主要作用是将RDD转成scala中的数据结构
*
*/
val tuples: Array[(String, String, String, String, String)] = studentsRDD.collect()
}
}
3.2.3、count()
- 返回数据集中元素的个数。
3.2.4、first()
- 返回数据集的第一个元素(类似于take(1))。
3.2.5、take(n)
- 返回一个包含数据集的前n个元素的数组。
3.2.6、takeSample(withReplacement, num, [seed])
- 返回一个数组,其中包含数据集的num个元素的随机样本,可替换或不替换,可选择预先指定随机数生成器种子。
3.2.7、takeOrdered(n, [ordering])
- 使用自然顺序或自定义比较器返回RDD的前n个元素。
3.2.8、saveAsTextFile(path)
- 将数据集的元素作为文本文件(或文本文件集)写入本地文件系统、HDFS或任何其他hadoop支持的文件系统的给定目录中。Spark将对每个元素调用toString,将其转换为文件中的一行文本。
3.2.9、countByKey()
- 仅在(K, V)类型的rdd上可用。返回(K, Int)对的哈希映射,其中包含每个键的计数。
3.2.10、foreach(func)
- 对数据集的每个元素运行函数function。这通常是为了处理诸如更新Accumulator或与外部存储系统交互等副作用。
注意:在foreach()之外修改累加器以外的变量可能会导致未定义的行为。有关详细信息,请参见理解闭包。
4、累加器(Accumulators)
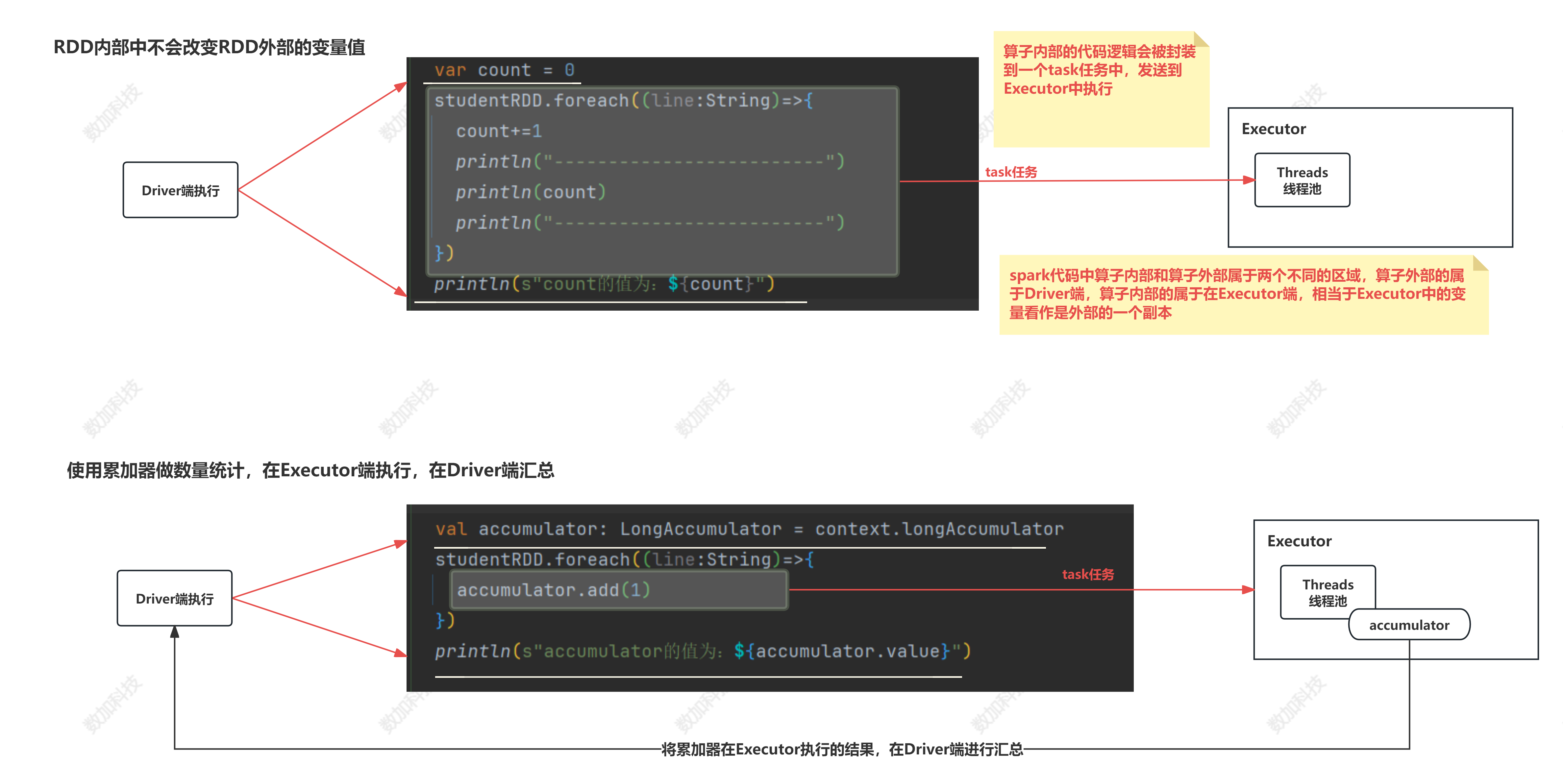
- spark代码分为算子内的代码和算子外的代码,算子内的代码在Executor端执行,算子外的代码在Driver端执行,如果在算子内对算子外的变量进行修改,是不会生效的,所以需要使用spark的累加器进行全局累加。
object Demo20Accumulator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("map算子演示")
val context = new SparkContext(conf)
//====================================================
val studentRDD: RDD[String] = context.textFile("spark/data/students.csv")
val scoreRDD: RDD[String] = context.textFile("spark/data/score.txt")
// var count = 0
// studentRDD.foreach((line:String)=>{
// count+=1
// println("-------------------------")
// println(count)
// println("-------------------------")
// })
// println(s"count的值为:${count}")
/**
* 累加器
*
* 由SparkContext来创建
* 注意:
* 1、因为累加器的执行实在RDD中执行的,而RDD是在Executor中执行的,而要想在Executor中执行就得有一个action算子触发任务调度
* 2、sparkRDD中无法使用其他的RDD
* 3、SparkContext无法在RDD内部使用,因为SparkContext对象无法进行序列化,不能够通过网络发送到Executor中
*/
// val accumulator: LongAccumulator = context.longAccumulator
// studentRDD.foreach((line:String)=>{
// accumulator.add(1)
// })
// studentRDD.map((line:String)=>{
// accumulator.add(1)
// }).collect()
// println(s"accumulator的值为:${accumulator.value}")
// val value: RDD[RDD[(String, String)]] = studentRDD.map((stuLine: String) => {
// scoreRDD.map((scoreLine: String) => {
// val strings: Array[String] = scoreLine.split(",")
// val strings1: Array[String] = stuLine.split(",")
// val str1: String = strings.mkString("|")
// val str2: String = strings1.mkString("|")
// (str1, str2)
// })
// })
// value.foreach(println)
// val value: RDD[RDD[String]] = studentRDD.map((stuLine: String) => {
// val scoreRDD: RDD[String] = context.textFile("spark/data/score.txt")
// scoreRDD
// })
// value.foreach(println)
}
}
5、广播变量
- 可以将Driver端的一个变量广播到Executor,可以减少变量副本数,一般用于mapjoin spark sql map join的底层就是将小表广播出去
object Demo21Broadcast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("广播变量演示")
val context = new SparkContext(conf)
//====================================================
//使用Scala的方式读取学生数据文件,将其转换以学号作为键的map集合,属于在Driver端的一个变量
val studentsMap: Map[String, String] = Source.fromFile("spark/data/students.csv")
.getLines()
.toList
.map((line: String) => {
val infos: Array[String] = line.split(",")
val stuInfo: String = infos.mkString(",")
(infos(0), stuInfo)
}).toMap
val scoresRDD: RDD[String] = context.textFile("spark/data/score.txt")
/**
* 将studentsMap变成一个广播变量,让每一个将来需要执行关联的Executor中都有一份studentsMap数据
* 避免了每次Task任务拉取都要附带一个副本,拉取的速度变快了,执行速度也就变快了
*
* 广播大变量
*/
val studentsMapBroadcast: Broadcast[Map[String, String]] = context.broadcast(studentsMap)
/**
* 将Spark读取的分数RDD与外部变量学生Map集合进行关联
* 循环遍历scoresRDD,将学号一样的学生信息关联起来
*/
// val resMapRDD: RDD[(String, String)] = scoresRDD.map((score: String) => {
// val id: String = score.split(",")(0)
// //使用学号到学生map集合中获取学生信息
// val studentInfo: String = studentsMap.getOrElse(id, "无学生信息")
// (score, studentInfo)
// })
// resMapRDD.foreach(println)
/**
* 使用广播变量进行关联
*/
val resMapRDD: RDD[(String, String)] = scoresRDD.map((score: String) => {
val id: String = score.split(",")(0)
val stuMap: Map[String, String] = studentsMapBroadcast.value
//使用学号到学生map集合中获取学生信息
val studentInfo: String = stuMap.getOrElse(id, "无学生信息")
(score, studentInfo)
})
resMapRDD.foreach(println)
}
}
6、RDD持久化/缓存
- RDD的缓存有两种方式
- cache:默认情况是将数据缓存到内存中,cache的底层是调用persist方法
- persist:
- 缓存级别
- MEMORY_ONLY:
- MEMORY_AND_DISK_SER
- 当重复使用同一个RDD时,可以使用RDD缓存
object Demo16Catch {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Action算子演示")
val context = new SparkContext(conf)
//设置checkpoint路径,将来对应的是HDFS上的路径
context.setCheckpointDir("spark/data/checkpoint")
//====================================================
val linesRDD: RDD[String] = context.textFile("spark/data/students.csv")
val splitRDD: RDD[Array[String]] = linesRDD.map(_.split(","))
//处理数据
val studentsRDD: RDD[(String, String, String, String, String)] = splitRDD.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
//对studentsRDD进行缓存
/**
* 特点带来的问题:既然叫做缓存,所以在程序运行过程中无论是只放内存还是磁盘内存一起使用,一旦程序结束,缓存数据全部丢失。
*
* spark针对上面的场景提供了一个解决方案:可以将RDD运行时的数据永久持久化在HDFS上,这个方案叫做checkpoint,需要在spark环境中设置checkpoint的路径
*/
// studentsRDD.cache() //默认情况下,是将数据缓存在内存中
// studentsRDD.persist(StorageLevel.MEMORY_AND_DISK)
studentsRDD.checkpoint()
//统计每个班级的人数
val clazzKVRDD: RDD[(String, Int)] = studentsRDD.map {
case (_, _, _, _, clazz: String) => (clazz, 1)
}
val clazzNumRDD: RDD[(String, Int)] = clazzKVRDD.reduceByKey(_ + _)
clazzNumRDD.saveAsTextFile("spark/data/clazz_num")
//统计性别的人数
val genderKVRDD: RDD[(String, Int)] = studentsRDD.map {
case (_, _, _, gender: String, _) => (gender, 1)
}
val genderNumRDD: RDD[(String, Int)] = genderKVRDD.reduceByKey(_ + _)
genderNumRDD.saveAsTextFile("spark/data/gender_num")
//
// while (true){
//
// }
}
}
总结:
- RDD 持久化/缓存的目的是为了提高后续操作的速度
- 缓存的级别有很多,默认只存在内存中,开发中使用 memory_and_disk
- 只有执行 action 操作的时候才会真正将 RDD 数据进行持久化/缓存
- 实际开发中如果某一个 RDD 后续会被频繁的使用,可以将该 RDD 进行持久化/缓存
7、RDD容错机制Checkpoint
- 持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
问题解决:
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
SparkContext.setCheckpointDir("目录") //HDFS的目录
RDD.checkpoint
object Demo12Checkpoint {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("checkpoint演示")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
val sparkContext: SparkContext = sparkSession.sparkContext
sparkContext.setCheckpointDir("hdfs://master:9000/bigdata29/data")
val lineRDD: RDD[String] = sparkContext.textFile("spark/data/students.csv")
val clazzRDD: RDD[(String, Int)] = lineRDD.map(line => {
val split: Array[String] = line.split(",")
val clazz: String = split(4)
(clazz, 1)
})
val countRDD: RDD[(String, Int)] = clazzRDD.reduceByKey(_ + _)
countRDD.checkpoint()
countRDD.foreach(println)
}
}
总结:
- 开发中如何保证数据的安全性性及读取效率:可以对频繁使用且重要的数据,先做缓存/持久化,再做 checkpint 操作。
持久化和 Checkpoint 的区别:
- 位置:Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中) Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期:Cache 和 Persist 的 RDD 会在程序结束后会被清除或者手动调用 unpersist 方法 Checkpoint 的 RDD 在程序结束后依然存在,不会被删除。
8、DAG的生成以及Stage的划分
DAG(
Directed Acyclic Graph有向无环图):指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
DAG 的边界:
- 开始:通过 SparkContext 创建的 RDD;
- 结束:触发 Action,一旦触发 Action 就形成了一个完整的 DAG。
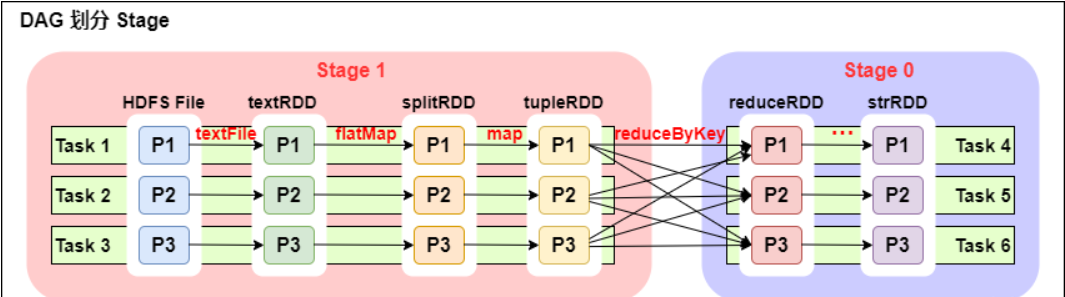
从上图可以看出:
- 一个 Spark 程序可以有多个 DAG(有几个 Action,就有几个 DAG,上图最后只有一个 Action(图中未表现),那么就是一个 DAG);
- 一个 DAG 可以有多个 Stage(根据宽依赖/shuffle 进行划分);
- 同一个 Stage 可以有多个 Task 并行执行(task 数=分区数,如上图,Stage1 中有三个分区 P1、P2、P3,对应的也有三个 Task);
- 可以看到这个 DAG 中只 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage;
- 在图中 Stage1 中,从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
9、资源调度和任务调度
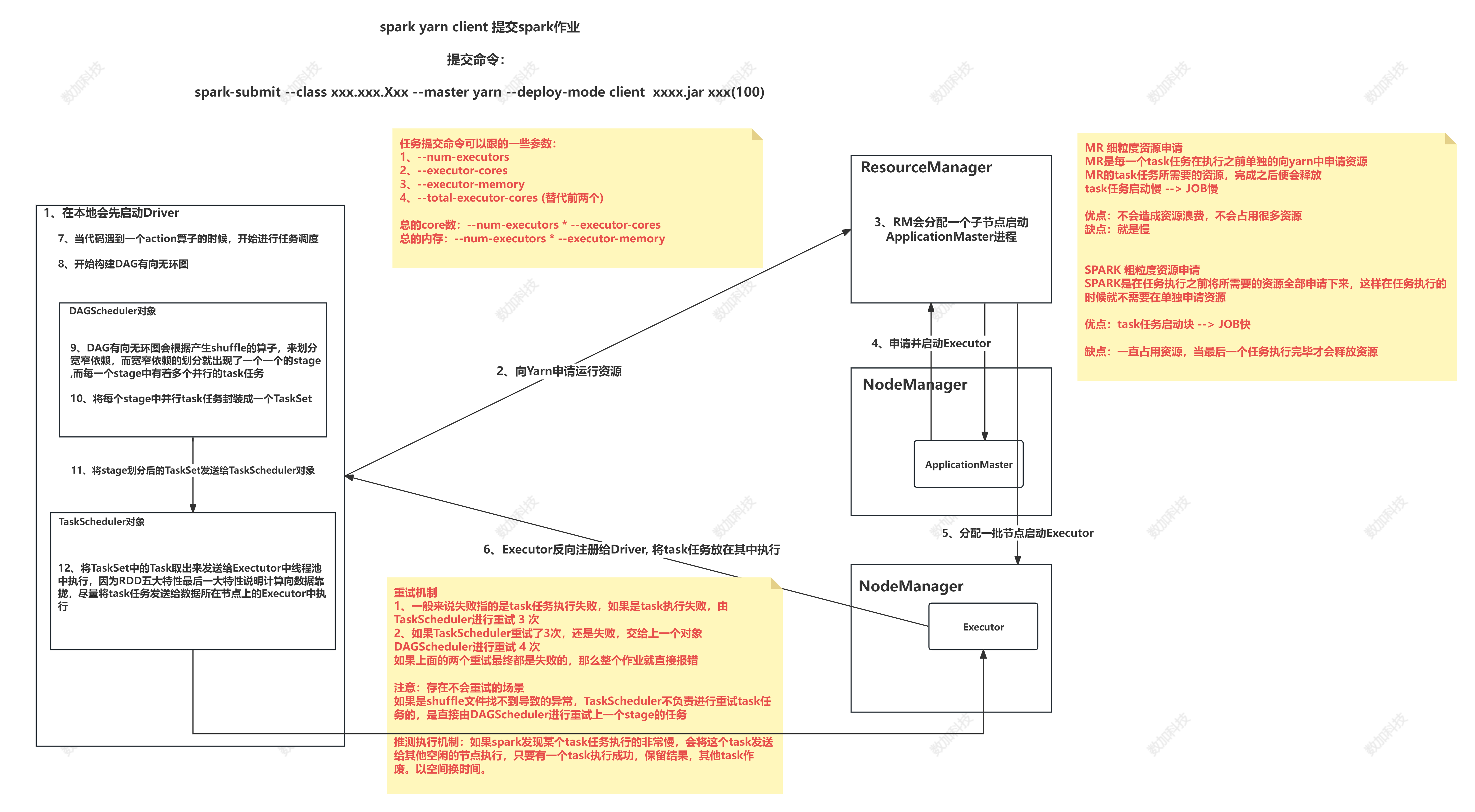
- 资源调度
yarn-client为例
1、在本地启动Driver
2、Driver向ResourceManager申请资源
3、RM分配一个节点启动ApplicationMaster
4、AM向RM申请启动Executor
5、RM随机分配一批节点启动Executor
6、Executor反向注册给Driver
- 任务调度
1、当遇到一个Action算子时,开始任务调度
2、构建DAG有向无环图
3、将DAG传递给DAGScheduler
4、DAGScheduler根据宽窄依赖切分Stage
5、DAGScheduler将Stage以taskSet的形式发送给TaskScheduler
6、TaskScheduler将task发送到Executor中执行,会尽量将task发送到数据所在的节点执行
四、Spark SQL
1、spark sql的API
通过统计单词的数量引入
def main(args: Array[String]): Unit = {
/**
* 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession
*/
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("wc spark sql")
.getOrCreate()
/**
* spark sql和spark core的核心数据类型不太一样
*
* 1、读取数据构建一个DataFrame,相当于一张表
*/
val linesDF: DataFrame = sparkSession.read
.format("csv") //指定读取数据的格式
.schema("line STRING") //指定列的名和列的类型,多个列之间使用,分割
.option("sep", "\n") //指定分割符,csv格式读取默认是英文逗号
.load("spark/data/words.txt") // 指定要读取数据的位置,可以使用相对路径
// println(linesDF)
// linesDF.show() //查看DF中的数据内容(表内容)
// linesDF.printSchema() //查看DF表结构
/**
* 2、DF本身是无法直接在上面写sql的,需要将DF注册成一个视图,才可以写sql数据分析
*/
linesDF.createOrReplaceTempView("lines") // 起一个表名,后面的sql语句可以做查询分析
/**
* 3、可以编写sql语句 (统计单词的数量)
* spark sql是完全兼容hive sql
*/
val resDF: DataFrame = sparkSession.sql(
"""
|select
|t1.word as word,
|count(1) as counts
|from
|(select
| explode(split(line,'\\|')) as word from lines) t1
| group by t1.word
|""".stripMargin)
/**
* 4、将计算的结果DF保存到HDFS上
*/
val resDS: Dataset[Row] = resDF.repartition(1)
resDS.write
.format("csv") //指定输出数据文件格式
.option("sep","\t") // 指定列之间的分隔符
.mode(SaveMode.Overwrite) // 使用SaveMode枚举类,设置为覆盖写
.save("spark/data/sqlout1") // 指定输出的文件夹
}
2、DSLAPI
/** * DSL: 类SQL语法 api 介于代码和纯sql之间的一种api * * spark在DSL语法api中,将纯sql中的函数都使用了隐式转换变成一个scala中的函数 * 如果想要在DSL语法中使用这些函数,需要导入隐式转换 * */ //导入Spark sql中所有的sql隐式转换函数 import org.apache.spark.sql.functions._ //导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理 import sparkSession.implicits._
def main(args: Array[String]): Unit = {
/**
* 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession
*/
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("dsl语法api演示")
.config("spark.sql.shuffle.partitions",1) //默认分区的数量是200个
.getOrCreate()
//导入Spark sql中所有的sql隐式转换函数
import org.apache.spark.sql.functions._
//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理
import sparkSession.implicits._
/**
* DSL api
*/
//新版本的读取方式,读取一个json数据,不需要手动指定列名
// val stuDF1: DataFrame = sparkSession.read
// .json("spark/data/students.json")
//以前版本读取方式,灵活度要高一些
val stuDF: DataFrame = sparkSession.read
.format("json")
.load("spark/data/students.json")
// stuDF2.show(100, truncate = false) //传入展示总条数,并完全显示数据内容
/**
* select 函数:选择数据【字段】,和纯sql语句中select意思基本是一样,在数据的前提上选择要留下的列
*
*/
//根据字段的名字选择要查询的字段
// stuDF.select("id","name","age").show(1)
// //根据字段的名字选择要查询的字段,selectExpr 可以传入表达式字符串形式
// stuDF.selectExpr("id","name","age","age + 1 as new_age").show()
//使用隐式转换中的$函数将字段变成一个对象
// stuDF.select($"id",$"name",$"age").show(10)
//使用对象做处理
// stuDF.select($"id",$"name",$"age" + 1 as "new_age").show(10)
//可以在select中使用sql的函数
//下面的操作等同于sql:select id,name,age+1 as new_age,substring(clazz,0,2) as km from lines;
// stuDF.select($"id",$"name",$"age" + 1 as "new_age",substring($"clazz",0,2) as "km").show(10)
/**
* where 函数:过滤数据
*/
//直接将sql中where语句以字符串的形式传参
// stuDF.where("gender='女' and age=23").show()
//使用$列对象的形式过滤
// =!= 不等于
// === 等于
// stuDF.where($"gender" === "女" and $"age" === 23).show()
// stuDF.where($"gender" =!= "男" and $"age" === 23).show()
//过滤文科的学生
// stuDF.where(substring($"clazz", 0, 2) === "文科").show()
/**
* groupBy 分组函数
* agg 聚合函数
* 分组聚合要在一起使用
* 分组聚合之后的结果DF中只会包含分组字段和聚合字段
* select中无法出现不是分组的字段
*/
//根据班级分组,求每个班级的人数和平均年龄
// stuDF.groupBy($"clazz")
// .agg(count($"clazz") as "number",round(avg($"age"),2) as "avg_age").show()
/**
* orderBy: 排序
*/
// stuDF.groupBy($"clazz")
// .agg(count($"clazz") as "number")
// .orderBy($"number").show()
/**
* join: 表关联
*/
val scoreDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
.schema("id STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
// scoreDF.show()
//关联场景1:所关联的字段名字不一样的时候
// stuDF.join(scoreDF, $"id" === $"sid", "inner").show()
//关联场景2:所关联的字段名字一样的时候
// stuDF.join(scoreDF,"id").show()
/**
* 开窗函数
* 统计每个班级总分前3的学生
*
* 开窗不会改变总条数的,会以新增一列的形式加上开窗的结果
* withColumn 新增一列
*/
val joinStuAndScoreWithIDDF: DataFrame = stuDF.join(scoreDF, "id")
joinStuAndScoreWithIDDF.groupBy($"id", $"clazz") //根据学号和班级一起分组
.agg(sum($"score") as "sumScore") //计算总分
.withColumn("rn", row_number() over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
//.select($"id", $"clazz", $"sumScore", row_number() over Window.partitionBy($"clazz").orderBy($"sumScore".desc) as "rn")
.where($"rn" <= 3)
.show()
}
3、Data SourceAPI
def main(args: Array[String]): Unit = {
/**
* 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession
*/
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("dsl语法api演示")
.config("spark.sql.shuffle.partitions",1) //默认分区的数量是200个
.getOrCreate()
//导入Spark sql中所有的sql隐式转换函数
import org.apache.spark.sql.functions._
//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理
import sparkSession.implicits._
/**
* 读取csv格式的数据,默认是以英文逗号分割的
*
*/
// val stuCsvDF: DataFrame = sparkSession.read
// .format("csv")
// .schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
// .option("sep", ",")
// .load("spark/data/students.csv")
// //求每个班级的人数,保存到文件中
// stuCsvDF.groupBy($"clazz")
// .agg(count($"clazz") as "number")
// .write
// .format("csv")
// .option("sep",",")
// .mode(SaveMode.Overwrite)
// .save("spark/data/souceout1")
/**
* 读取json数据格式,因为json数据有键值对。会自动地将键作为列名,值作为列值,不需要手动设置表结构
*/
val stuJsonDF: DataFrame = sparkSession.read
.format("json")
.load("spark/data/students2.json")
// //统计每个性别的人数
// stuJsonDF.groupBy($"gender")
// .agg(count($"gender") as "number")
// .write
// .format("json")
// .mode(SaveMode.Overwrite)
// .save("spark/data/jsonout1")
/**
* parquet
* 压缩的比例是由【信息熵】来决定的
*/
// stuJsonDF.write
// .format("parquet")
// .mode(SaveMode.Overwrite)
// .save("spark/data/parquetout2")
//读取parquet格式文件的时候,也是不需要手动指定表结构
// val stuParquetDF: DataFrame = sparkSession.read
// .format("parquet")
// .load("spark/data/parquetout1/part-00000-c5917bb6-172b-49bd-a90c-90b7f09b69d6-c000.snappy.parquet")
// stuParquetDF.show()
/**
* 读取数据库中的数据,mysql
*
*/
val jdDF: DataFrame = sparkSession.read
.format("jdbc")
.option("url", "jdbc:mysql://192.168.220.100:3306")
.option("dbtable", "bigdata29.jd_goods")
.option("user", "root")
.option("password", "123456")
.load()
jdDF.show(10,truncate = false)
}
4、RDD转DF
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("RDD To DF")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val studentRDD: RDD[String] = sparkSession.sparkContext.textFile("spark/data/students.csv")
val stuRDD: RDD[(String, String, String, String, String)] = studentRDD.map((s: String) => s.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
/**
* RDD转DF
*/
val studentDF: DataFrame = stuRDD.toDF("id", "name", "age", "gender", "clazz")
studentDF.groupBy("clazz")
.agg(count("id"))
.show
/**
* 在Row的数据类型中 所有整数类型统一为Long 小数类型统一为Double
* 转RDD
*/
val studentsRDD: RDD[Row] = studentDF.rdd
val clazzRDD: RDD[(String, String)] = studentsRDD.map {
case Row(id: String, _, _, _, clazz: String) =>
(id, clazz)
}
val clazzCountRDD: RDD[(String, Int)] = clazzRDD.groupBy(_._2)
.map((kv: (String, Iterable[(String, String)])) => (kv._1, kv._2.toList.size))
clazzCountRDD.foreach(println)
}
5、window
/**
* 开窗函数
* 聚合开窗函数:sum count avg min max
* 排序开窗函数:row_number rank desen_rank lag(向上取) lead(向后取)
*/
object Demo6Window {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
/**
* 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession
*/
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("开窗函数DSL API演示")
.config("spark.sql.shuffle.partitions", 1) //默认分区的数量是200个
.getOrCreate()
//导入Spark sql中所有的sql隐式转换函数
import org.apache.spark.sql.functions._
//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理,如果需要做RDD和DF之间的转换
import sparkSession.implicits._
//学生表
val studentsDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load("spark/data/students.csv")
//成绩表
val scoresDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
.schema("sid STRING,subject_id STRING,score INT")
.load("spark/data/score.txt")
//科目表
val subjectDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
.schema("subject_id STRING,subject_name STRING,subject_sum_score INT")
.load("spark/data/subject.csv")
//将学生数据与成绩数据进行关联
val joinDF: DataFrame = studentsDF.join(scoresDF, $"id" === $"sid")
// joinDF.show(10)
/**
* 1、统计总分年级排名前十学生各科的分数
*
* 未排序之前,是将开窗中所有数据一起聚合得到一个结果
* 若排序了,依次从上到下聚合得到一个结果
*
*/
joinDF
// sum(score) over(partition by id ) as sumScore
.withColumn("sumScore", sum($"score") over Window.partitionBy($"id"))
.orderBy($"sumScore".desc)
.limit(60)
//.show(60)
/**
* 3、统计每科都及格的学生
*/
scoresDF
.join(subjectDF, "subject_id")
.where($"score" >= $"subject_sum_score" * 0.6)
//统计学生及格的科目数
.withColumn("jiGeCounts", count($"sid") over Window.partitionBy($"sid"))
.where($"jiGeCounts" === 6)
// .show(100)
/**
* 2、统计总分大于年级平均分的学生
*/
joinDF
//计算每个学生的总分,新增一列
.withColumn("sumScore", sum($"score") over Window.partitionBy($"id"))
.withColumn("avgScore", avg($"sumScore") over Window.partitionBy(substring($"clazz", 0, 2)))
.where($"sumScore" > $"avgScore")
// .show(200)
/**
* 统计每个班级的每个名次之间的分数差
*
*/
joinDF
.groupBy($"id", $"clazz")
.agg(sum($"score") as "sumScore")
//开窗,班级开窗,总分降序排序,排个名次
.withColumn("rn", row_number() over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
//开窗,取出前一名的总分
.withColumn("front_score", lag($"sumScore",1,750) over Window.partitionBy($"clazz").orderBy($"sumScore".desc))
.withColumn("cha",$"front_score" - $"sumScore")
.show(100)
}
}
6、submit yarn
spark-submit --master yarn --deploy-mode client --class com.shujia.sql.Demo8SubmitYarn --conf spark.sql.shuffle.partitions=1 spark-1.0.jar
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
//提交到yarn上运行不需要设置master参数
// .master("local")
.config("spark.sql.shuffle.partitions", 1) //优先级:代码的参数 > 命令行提交的参数 > 配置文件
.appName("spark sql提交到Yarn演示")
.getOrCreate()
//导入Spark sql中所有的sql隐式转换函数
import org.apache.spark.sql.functions._
//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理
import sparkSession.implicits._
val studentsDF: DataFrame = sparkSession.read
.format("csv")
.schema("id STRING,name STRING,age Int,gender STRING,clazz STRING")
.option("sep", ",")
.load("/bigdata29/data/students.txt")
val genderDF: DataFrame = studentsDF.groupBy($"clazz")
.agg(count($"id") as "num")
genderDF.write
.format("csv")
.option("sep",",")
.mode(SaveMode.Overwrite)
.save("/bigdata29/sparkOut/out3")
//spark-submit --master yarn --deploy-mode client --class com.shujia.test.Demo1SubmitYarn --conf spark.sql.shuffle.partitions=1 spark-1.0.jar
}
7、行列转换
/**
* 1、行列转换
*
* 表1
* 姓名,科目,分数
* name,item,score
* 张三,数学,33
* 张三,英语,77
* 李四,数学,66
* 李四,英语,78
*
*
* 表2
* 姓名,数学,英语
* name,math,english
* 张三,数学,33,英语,77
* 李四,数学,66,英语78
*
* 1、将表1转化成表2
* 2、将表2转化成表1
*/
object Demo10RowAndColumn {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("行列转换演示")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val tb1DF: DataFrame = sparkSession.read
.format("csv")
.schema("name STRING,item STRING ,score STRING ")
.option("sep", ",")
.load("spark/data/tb1.txt")
tb1DF.groupBy($"name")
.agg(sum(when($"item"==="数学",$"score").otherwise(0)) as "math",sum(when($"item"==="英语",$"score").otherwise(0)) as "english")
.write
.format("csv")
.option("sep",",")
.mode(SaveMode.Overwrite)
.save("spark/data/tb1")
val tb2DF: DataFrame = sparkSession.read
.format("csv")
.schema("name STRING,math STRING,english STRING")
.option("sep", ",")
.load("spark/data/tb2.txt")
val m: Column = map(
expr("'数学'"), $"math",
expr("'英语'"), $"english"
)
tb2DF.select($"name",explode(m) as Array("item","score"))
.show()
}
}
8、UDF(自定义函数)
- DSL和SQL中的自定义函数
object Demo11UDF {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local")
.appName("udf函数演示")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
import sparkSession.implicits._
import org.apache.spark.sql.functions._
/**
* 1、在使用DSL的时候使用自定义函数
*/
val studentsDF: DataFrame = sparkSession.read
.format("csv")
.option("sep", ",")
.schema("id STRING,name STRING,age INT,gender STRING,clazz STRING")
.load("spark/data/students.csv")
// studentsDF.show()
//编写自定义函数
//udf中编写的是scala代码
val shujia_fun1: UserDefinedFunction = udf((str: String) => "数加:" + str)
// studentsDF.select(shujia_fun1($"clazz")).show()
/**
* 1、使用SQL语句中使用自定函数
*/
studentsDF.createOrReplaceTempView("students")
//将自定义的函数变量注册成一个函数
sparkSession.udf.register("shujia_str",shujia_fun1)
sparkSession.sql(
"""
|select clazz,shujia_str(clazz) as new_clazz from students
|""".stripMargin).show()
}
}
- spark-sql 客户端的自定义函数
/**
1、将类打包,放在linux中spark的jars目录下
2、进入spark-sql的客户端
3、使用上传的jar中的udf类来创建一个函数
create function shujia_str as ‘com.shujia.sql.Demo12ShuJiaStr’;
*/
class Demo12ShuJiaStr extends UDF {
def evaluate(str: String): String = {
"shujia: " + str
}
}
/**
* 1、将类打包,放在linux中spark的jars目录下
* 2、进入spark-sql的客户端
* 3、使用上传的jar中的udf类来创建一个函数
* create function shujia_str as 'com.shujia.sql.Demo12ShuJiaStr';
*/
9、mapjoin(广播变量)
基于广播变量(Broadcast Variable)实现。广播变量允许将小表的数据广播到集群中的每个节点,使得连接操作可以在每个节点上本地完成,而不需要在节点之间传输大量的数据。
在map端进行表关联,不会产生shuffle
-
自动广播(默认)
Spark SQL会自动广播小表,前提是小表的大小在配置的阈值以内(默认为10MB)。这个阈值可以通过配置参数
spark.sql.autoBroadcastJoinThreshold来调整:spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 10 * 1024 * 1024) // 设置阈值为10MB -
显示广播
你可以显式地将某个表标记为广播变量,确保使用Broadcast Join。使用
broadcast函数来实现:
import org.apache.spark.sql.functions.broadcast
val smallTable = spark.table("small_table")
val largeTable = spark.table("large_table")
val joinedTable = largeTable.join(broadcast(smallTable), "key")
配置参数
以下是一些与Broadcast Join相关的重要配置参数:
spark.sql.autoBroadcastJoinThreshold:自动广播表大小的阈值(默认10MB)。
spark.sql.broadcastTimeout:广播变量的超时时间(默认300秒)。
spark.sql.broadcast.hash.join.enabled:是否启用Broadcast Hash Join(默认启用)。
- spark-sql端
select /*+broadcast(a) */ * from
student as a
join
score as b
on
a.id=b.student_id
五、Spark Streaming
1、概述
Spark Streaming 是一个基于 Spark Core 之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

2、快速示例
假设我们要统计从监听 TCP 套接字的数据服务器接收到的文本数据中的单词数量
import org.apache.spark.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
//创建一个本地StreamingContext,它有两个工作线程,批处理间隔为1秒
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
使用此上下文,我们可以创建一个 DStream,表示来自 TCP 源的流数据,指定为主机名(例如 localhost)和端口(例如 9999)。
// 创建一个DStream连接到hostname:port,比如localhost:9999
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
此 lines DStream 表示将从数据服务器接收的数据流。此流中的每条记录都是一行文本。然后,我们要按空格将行拆分为单词。
// 将每行拆分为单词
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
flatMap 是一种 DStream 操作,它通过从源 DStream 中的每条记录生成多个新记录来创建一个新的 DStream。在这种情况下,每行将被拆分为多个单词,单词流表示为 words DStream。请注意,我们使用 FlatMapFunction 对象定义了转换。正如我们将在过程中发现的那样,Java API 中有许多这样的便利类可以帮助定义 DStream 转换。
接下来,我们要统计这些单词。
// 计算每个批次中的每个单词
JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
// 将DStream中生成的每个RDD的前10个元素打印到控制台
wordCounts.print();
words DStream 使用 PairFunction 对象进一步映射(一对一转换)到 (word, 1) 对的 DStream。然后,使用 Function2 对象对其进行 reduce 以获取每批数据中单词的频率。最后,wordCounts.print() 将每秒打印生成的几个计数。
请注意,执行这些行时,Spark Streaming 仅设置它在启动后将执行的计算,并且尚未开始实际处理。要在设置完所有转换后开始处理,我们最后调用 start 方法。
jssc.start(); // 开始计算
jssc.awaitTermination(); // 等待计算结束
jssc.stop(); // 手动结束
3、窗口
- 滑动动窗口
由窗口的大小和滑动的距离组成的,数据可能会出现重复
- 代码
让我们用一个例子来说明窗口操作。假设您想通过每 10 秒生成过去 30 秒数据的字数统计来扩展前面的例子。为此,我们必须对过去 30 秒数据的
(word, 1)对的pairsDStream 应用reduceByKey操作。这是使用操作reduceByKeyAndWindow完成的。
JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2, Durations.seconds(30), Durations.seconds(10));
- 一些常见的窗口操作如下。所有这些操作都采用上述两个参数 - windowLength 和 slideInterval。

4、有状态计算
每一次计算都会基于上一次计算的结果进行计算(有状态计算),状态(上一次的计算结果)
和checkpoints结合使用
- updateStateByKey 经典的状态计算
updateStateByKey是 Spark Streaming 中最早引入的状态计算算子之一。它允许用户通过指定一个更新函数来更新每个键的状态。这个算子背后的核心思想是在接收到新的数据时,将其与先前状态合并,从而得到更新后的状态。
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Durations, StreamingContext}
object Demo2UpdateStateByKey {
def main(args: Array[String]): Unit = {
/**
* spark core: SparkContext --> 核心数据类型 RDD
* spark sql: SparkSession --> 核心数据类型 DataFrame
* spark streaming: StreamingContext --> 核心数据类型 DStream(RDD)
*
* 创建SparkStreaming的环境需要使用StreamingContext对象
*/
//spark streaming依赖于spark core的环境
//因为spark streaming核心数据类型底层封装的是RDD
val conf = new SparkConf()
conf.setMaster("local[2]")
conf.setAppName("spark streaming 单词统计案例1")
val sparkContext = new SparkContext(conf)
// def this(sparkContext: SparkContext, batchDuration: Duration) //传入一个spark core 环境对象以及一个接收时间的范围
val streamingContext = new StreamingContext(sparkContext, Durations.seconds(5))
//设置checkpoint路径
streamingContext.checkpoint("spark/data/stream_state_wc_checkpoint")
/**
* 因为sparkstreaming是一个近实时的计算引擎,整个程序写完运行的状态,一直运行,一直接收数据,除非异常或者手动停止
*
* 1、目前在spark使用nc工具监控一个端口号中源源不断产生的数据
* 2、yum install -y nc 下载安装nc工具
* 3、nc -lk xxxx
*/
val lineDS: ReceiverInputDStream[String] = streamingContext.socketTextStream("master", 12345)
val flatMapDS: DStream[String] = lineDS.flatMap(_.split(" "))
val wordsKVDS: DStream[(String, Int)] = flatMapDS.map((_, 1))
/**
* 有状态的算子
* 使用当前批次的数据加上之前批次统计的结果,返回新的结果
*
* seq: 代表当前批次一个key对应的所有value值 (hello,1) seq:[1,1,1]
* Option: 之前批次统计的key对应的值,如果当前批次的key在历史批次中没有出现,那么Option就是None (hello,2) Option:2
*
*
* 有状态算子需要配合checkpoint一起使用,将上一次的结果持久化,为了下一批次可以读取到
*/
//def updateStateByKey[S: ClassTag](
// updateFunc: (Seq[V], Option[S]) => Option[S]
// ): DStream[(K, S)]
val result2DS: DStream[(String, Int)] = wordsKVDS.updateStateByKey((seq: Seq[Int], option: Option[Int]) => {
//将当前批次该key对应的所有value值加起来
val currentCount: Int = seq.sum // [1,1,1]->3
//获取上一批次的该key对应的value值
val count: Int = option.getOrElse(0) // 2
//将当前匹配的key对应的value值总和与上一次该key的value值相加,封装成一个Option
Option(currentCount + count)
})
//打印一下结果
result2DS.print()
/**
* Spark Streaming作业触发执行的方式和之前完全不一样
*/
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
}
}
- mapWithState 更灵活的状态计算
mapWithState是 Spark 1.6 版本中引入的一种更强大和灵活的状态计算算子。相对于updateStateByKey,mapWithState提供了更大的灵活性,允许用户定义更通用的状态更新函数,并提供了更多的状态管理选项。
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("updateByKeyDemo")
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint("file:///D:/checkpoint/")
val stream = ssc.socketTextStream("localhost", 1234)
val wordPairStream = stream
.flatMap(_.split(" "))
.map((_, 1))
// 使用mapWithState算子来实现状态管理
wordPairStream
.mapWithState(
StateSpec.function(mappingFunc _)
)
.print()
ssc.start()
ssc.awaitTermination()
// ------------------------------------------------
// 自定义的状态更新函数
def mappingFunc(word: String, value: Option[Int], state: State[Int]): (String, Int) = {
val count = value.getOrElse(0) + state.getOption().getOrElse(0)
state.update(count)
(word, count)
}
六、spark的优化
1、代码优化
- 避免创建重复的RDD
- 对多次使用的RDD进行持久化
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大, 可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避 免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作 ,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传 送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种 策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化 级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用 MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个 partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别 比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算 子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上, 如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 使用高性能算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map Transformation算子
使用foreachPartitions替代foreach Action算子
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操 作 代码
repartition:coalesce(numPartitions,true) 增多分区使用这个
coalesce(numPartitions,false) 减少分区 没有shuffle只是合并 partition
- 广播大变量
开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如 100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提 升性能
函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络 传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如 100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节 点的Executor中占用过多内存导致的频繁GC(垃圾回收),都会极大地影响性能
如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播 后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的 task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本 的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低 GC的频率
广播大变量发送方式:Executor一开始并没有广播变量,而是task运行需要用到广 播变量,会找executor的blockManager要,bloackManager找Driver里面的 blockManagerMaster要。
- 使用Kryo优化序列化性能
在Spark中,主要有三个地方涉及到了序列化:
在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输
将自定义的类型作为RDD的泛型类型时(比如JavaRDD,SXT是自定义类型),所有自 定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现 Serializable接口。
使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个 partition都序列化成一个大的字节数组。
Kryo序列化器介绍:
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,速度要快 ,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可 以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和 反序列化的性能。Spark默认使用的是Java的序列化机制,也就是 ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同 时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。 官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有 使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类 型,因此对于开发者来说,这种方式比较麻烦
- 优化数据结构
Java中,有三种类型比较耗费内存:
对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来 封装集合元素,比如Map.Entry。
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽 量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如 Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用 ,从而降低GC频率,提升性能。
- 使用高性能的库fastutil
fastutil是扩展了Java标准集合框架(Map、List、Set;HashMap、ArrayList、 HashSet)的类库,提供了特殊类型的map、set、list和queue;
fastutil能够提供更小的内存占用,更快的存取速度;我们使用fastutil提供的集合类,来 替代自己平时使用的JDK的原生的Map、List、Set,好处在于,fastutil集合类,可以减 小内存的占用,并且在进行集合的遍历、根据索引(或者key)获取元素的值和设置元素 的值的时候,提供更快的存取速度;
fastutil最新版本要求Java 7以及以上版本;
fastutil的每一种集合类型,都实现了对应的Java中的标准接口(比如fastutil的map,实 现了Java的Map接口),因此可以直接放入已有系统的任何代码中。
fastutil的每一种集合类型,都实现了对应的Java中的标准接口(比如fastutil的 map,实现了Java的Map接口),因此可以直接放入已有系统的任何代码中。
2、参数调优
- 数据本地化
Application任务执行流程:
• 在Spark Application提交后,Driver会根据action算子划分成一个个的job,然后对每一 个job划分成一个个的stage,stage内部实际上是由一系列并行计算的task组成的,然后 以TaskSet的形式提交给你TaskScheduler,TaskScheduler在进行分配之前都会计算出 每一个task最优计算位置。Spark的task的分配算法优先将task发布到数据所在的节点上 ,从而达到数据最优计算位置。数据本地化级别
PROCESS_LOCAL 进程本地化,数据和task任务在同一个Executor中执行,默认
NODE_LOCA 节点本地化 数据和task任务在同一个节点中不同的Executor中执行 跨Executor拉取数据
NO_PREF 第三方存储中间件得到数据,mysql clickhouse redis
RACK_LOCAL 机架本地化 task任务和数据在同一个机架不同的节点中执行 跨节点拉取数据
ANY 跨机架本地化 task任务和数据不在一个机架上配置参数
spark.locality.wait
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
- jvm调优
概述:
Spark task执行算子函数,可能会创建很多对象,这些对象,都是要放入JVM年轻代中
RDD的缓存数据也会放入到堆内存中配置
spark.storage.memoryFraction 默认是0.6
- shuffle调优
概述:
reduceByKey:要把分布在集群各个节点上的数据中的同一个key,对应的values,都给 集中到一个节点的一个executor的一个task中,对集合起来的value执行传入的函数进行 reduce操作,最后变成一个value配置
spark.shuffle.manager, 默认是sort
spark.shuffle.consolidateFiles,默认是false
spark.shuffle.file.buffer,默认是32k
spark.shuffle.memoryFraction,默认是0.2
- 调节Executor堆外内存
概述:
Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外 内存(netty是零拷贝),所以使用了堆外内存。问题原因:
Executor由于内存不足或者对外内存不足了,挂掉了,对应的Executor上面的block manager也挂掉了,找不到对应的shuffle map output文件,Reducer端不能够拉取数 据
Executor并没有挂掉,而是在拉取数据的过程出现了问题上述情况下,就可以去考虑调节一下executor的堆外内存。也许就可以避免报错;
解决办法:
yarn下:–conf spark.yarn.executor.memoryOverhead=2048 单位M
standlone下:–conf spark.executor.memoryOverhead=2048单位M默认情况下,这个堆外内存上限默认是每一个executor的内存大小的10%;真正处理大数据的时候, 这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G (1024M),甚至说2G、4G
调节等待时长
executor在进行shuffle write,优先从自己本地关联的BlockManager中获取某份数据如果本地 block manager没有的话,那么会通过TransferService,去远程连接其他节点上executor的block manager去获取,尝试建立远程的网络连接,并且去拉取数据频繁的让JVM堆内存满溢,进行垃圾回收。正好碰到那个exeuctor的JVM在垃圾回收。处于垃圾回 收过程中,所有的工作线程全部停止;相当于只要一旦进行垃圾回收,spark / executor停止工作, 无法提供响应,spark默认的网络连接的超时时长,是60s;如果卡住60s都无法建立连接的话,那 么这个task就失败了。
解决办法:
–conf spark.core.connection.ack.wait.timeout=300
3、数据倾斜
- 使用Hive ETL预处理数据
方案适用场景:如果导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个 key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表 执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对 数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是 原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么 在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子 ,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。 因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作 时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
- 过滤少数导致倾斜的key
方案适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很 适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导 致了数据倾斜。
方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别 重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤 掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时, 动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后 计算出每个key的数量,取数据量最多的key过滤掉即可。
方案实现原理:将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生 数据倾斜。
- 提高shuffle操作的并行度(分区)
方案实现思路:在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如 reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于 Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即 spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很 多场景来说都有点过小。
方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个 task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条 数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时 间都会变短了。具体原理如下图所示。
- 双重聚合
方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by 语句进行分组聚合时,比较适用这种方案。
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key 都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着 对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会 变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次 进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被 一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。 接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果
- 将reduce join转为map join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中 的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作, 进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过 collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD 执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每 一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式 连接起来。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉 取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的, 则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不 会发生shuffle操作,也就不会发生数据倾斜
- 采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五 ”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一 个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均 匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个 key的数量,计算出来数据量最大的是哪几个key。
然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以 内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数 据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个 RDD。
再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打 散成n份,分散到多个task中去进行join了。
而另外两个普通的RDD就照常join即可。
最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
- 使用随机前缀和扩容RDD进行join
方案适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没 什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:
该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成 数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。
然后将该RDD的每条数据都打上一个n以内的随机前缀。
同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一 个0~n的前缀。
最后将两个处理后的RDD进行join即可。方案实现原理:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的 “不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方 案六”的不同之处就在于,上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处 理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大 量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对 内存资源要求很高。
对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会 变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次 进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被 一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。 接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果
- 将reduce join转为map join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中 的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作, 进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过 collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD 执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每 一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式 连接起来。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉 取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的, 则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不 会发生shuffle操作,也就不会发生数据倾斜
- 采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五 ”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一 个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均 匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个 key的数量,计算出来数据量最大的是哪几个key。
然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以 内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数 据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个 RDD。
再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打 散成n份,分散到多个task中去进行join了。
而另外两个普通的RDD就照常join即可。
最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
- 使用随机前缀和扩容RDD进行join
方案适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没 什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:
该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成 数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。
然后将该RDD的每条数据都打上一个n以内的随机前缀。
同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一 个0~n的前缀。
最后将两个处理后的RDD进行join即可。方案实现原理:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的 “不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方 案六”的不同之处就在于,上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处 理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大 量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对 内存资源要求很高。
















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











